







目录
5.1 NoSuchElementException - 面试题
1. 元素定位
执行自动化测试, 我们需要先找到页面中的目标元素, 再对元素进行测试.
就比如我们在百度页面测试搜索功能时, 需要先定位到搜索框, 才能输入文字进行搜索.

在 Java 中, Selenium 提供了两个方法进行元素定位:
- By.xpath
- By.cssSelector
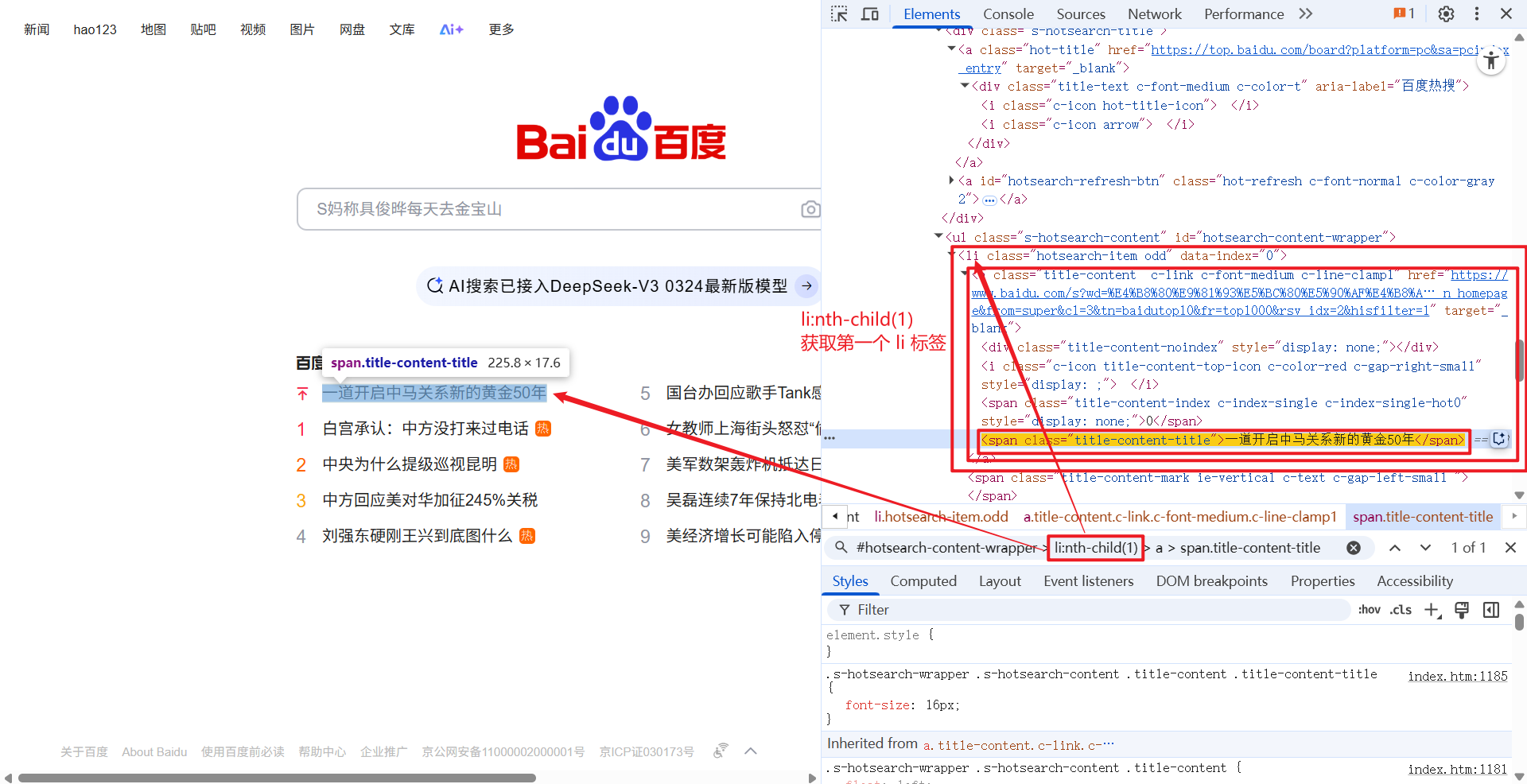
我们可以在开发者工具中, 选中目标元素后, 直接复制来获取该元素的 xpath 路径或选择器:
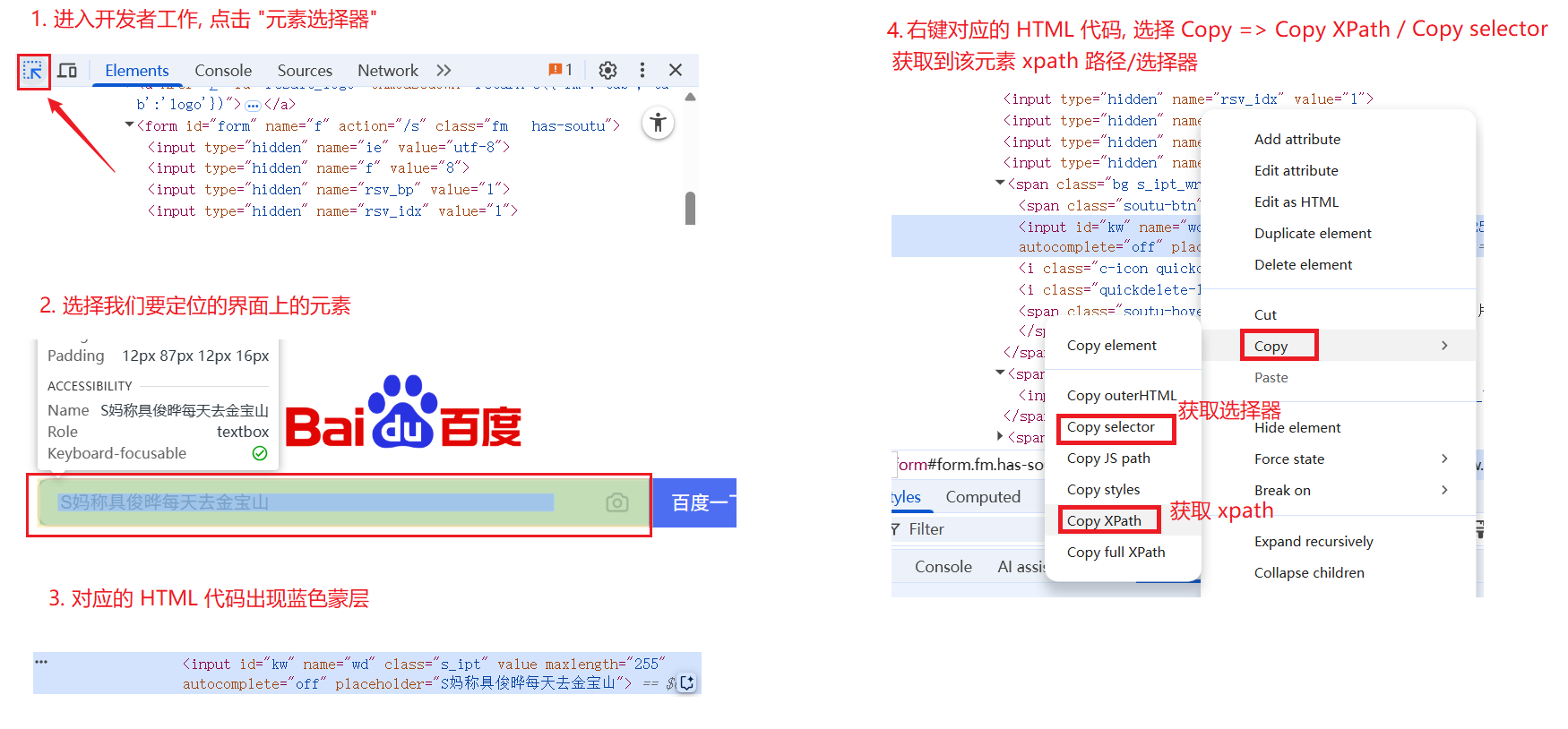
在前端代码区域 Ctrl + F, 弹出搜索框, 把我们得到的 xpath 路径/选择器复制上去, 就会查找到该 xpath 路径对应的 HTML 代码(高亮提示):
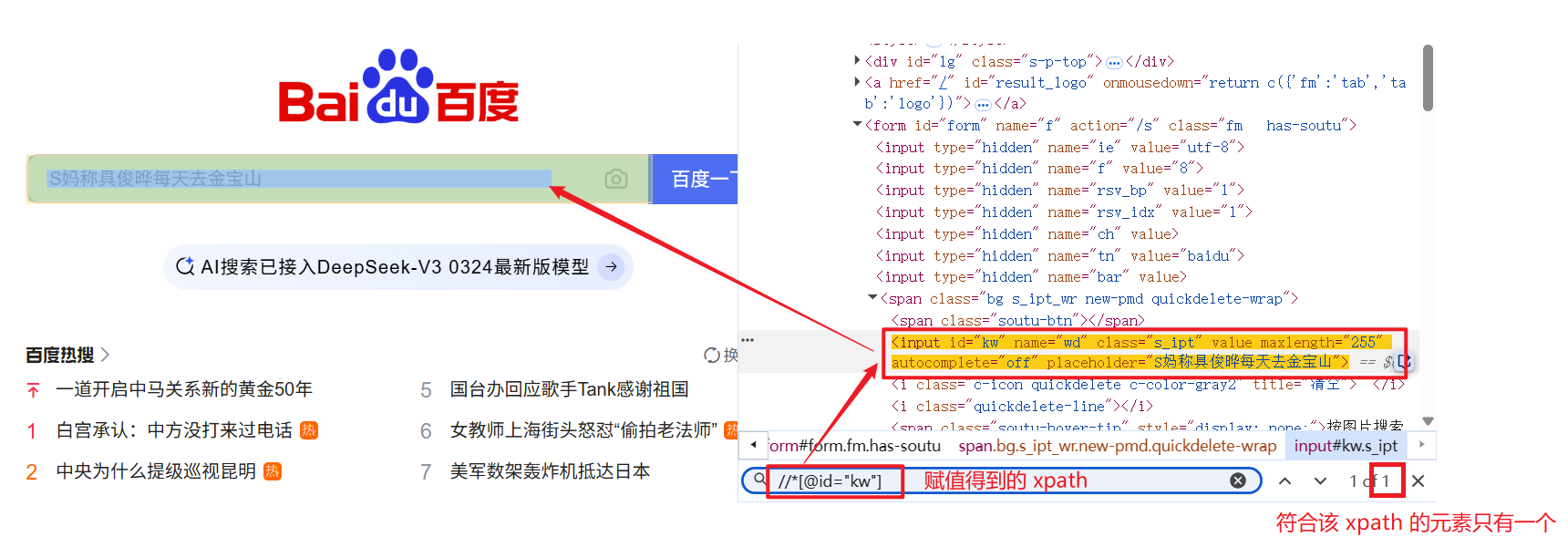
(这里演示的是 xpath, 选择器也是一样)
虽然我们可以通过开发者工具直接复制获取元素的 xpath 路径和选择器, 但是当元素为动态标签时, 他们的标签属性是会发动态变化的, 因此我们不能通过简单的复制解决问题.
我们还需要了解这些 xpath/选择器代表的含义, 以便手动完成对元素的定位.
1.1 By.xpath
XML 路径语言, 不仅可以在 XML 文件中查找信息, 还可以在HTMI中选取节点.

接下来解释 xpath 路径的含义.
1.1.1 //*
//* 意思是: 获取 HTML 页面中所有的元素(获取整个页面)
1.1.2 //[指定节点]
//[指定节点] 的意思是, 指定获取页面上的元素.
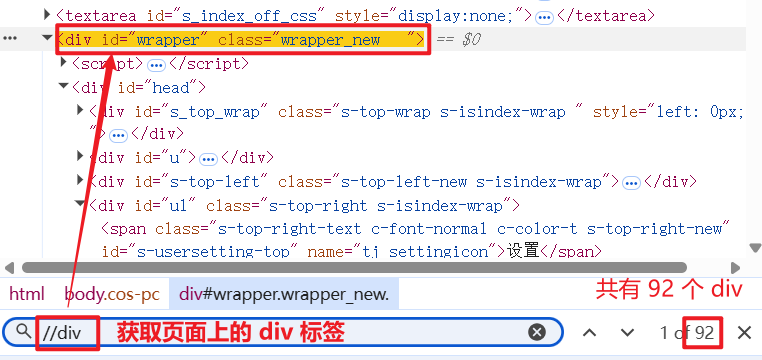
//div: 获取页面上的所有 div 标签
//input: 获取页面上的所有 input 标签
1.1.3 /
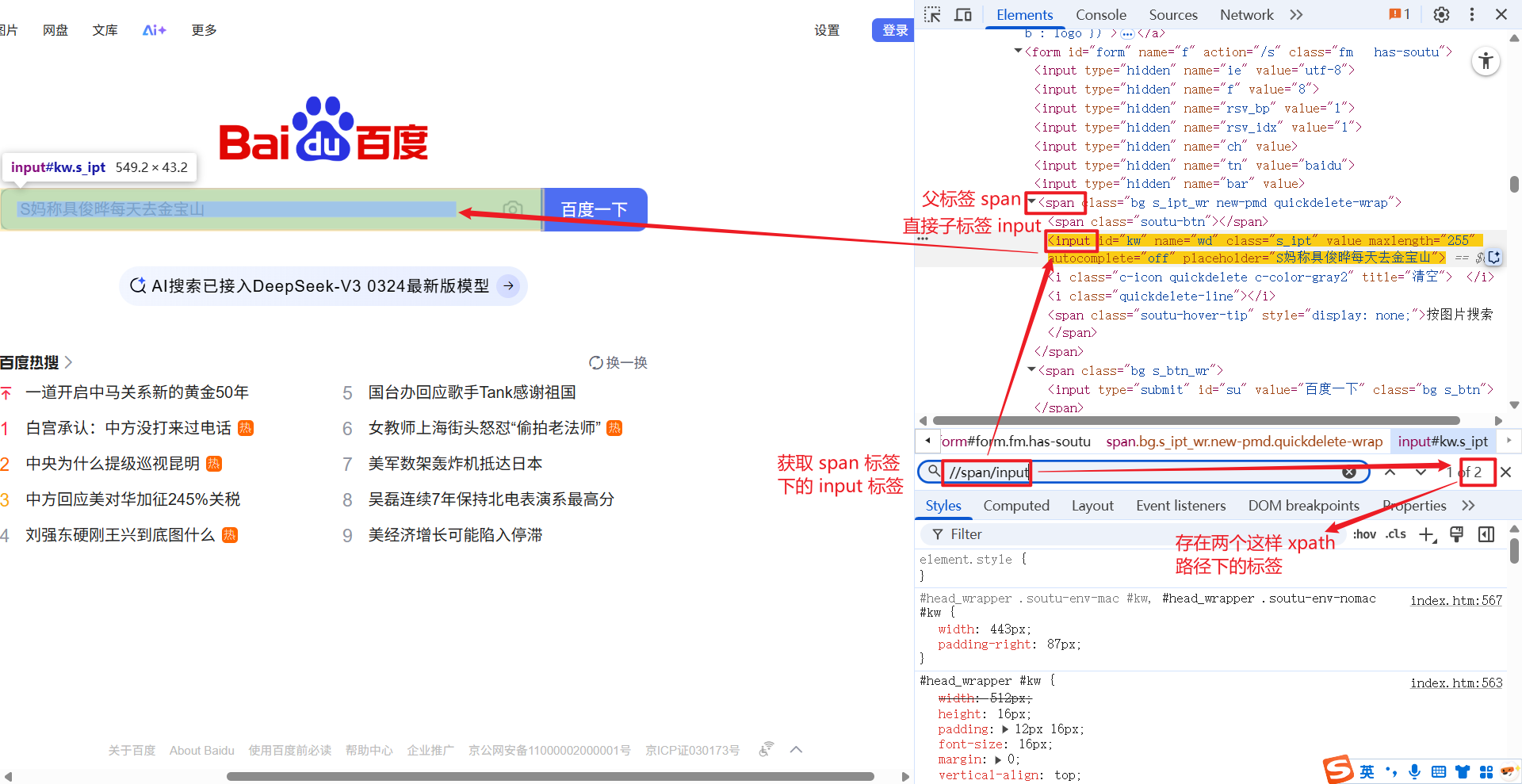
/ 的意思是, 获取一个节点中的直接子节点.
直接子节点的意思是, 获取到的节点, 只能是上个节点的 "儿子", 而不能是 "孙子".
1.1.4 /..
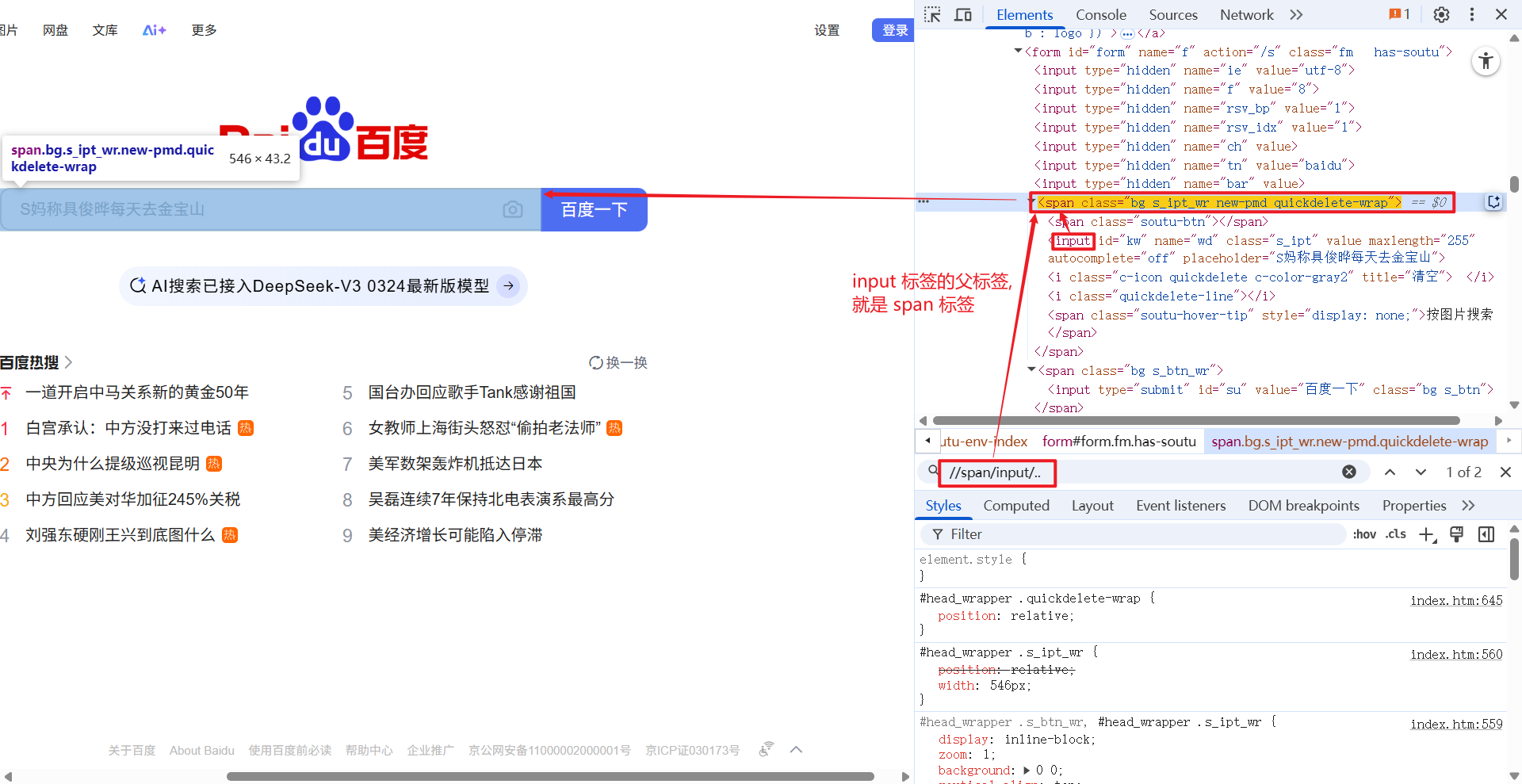
/.. 的意思是, 获取当前元素的父节点.
1.1.5 [@...]
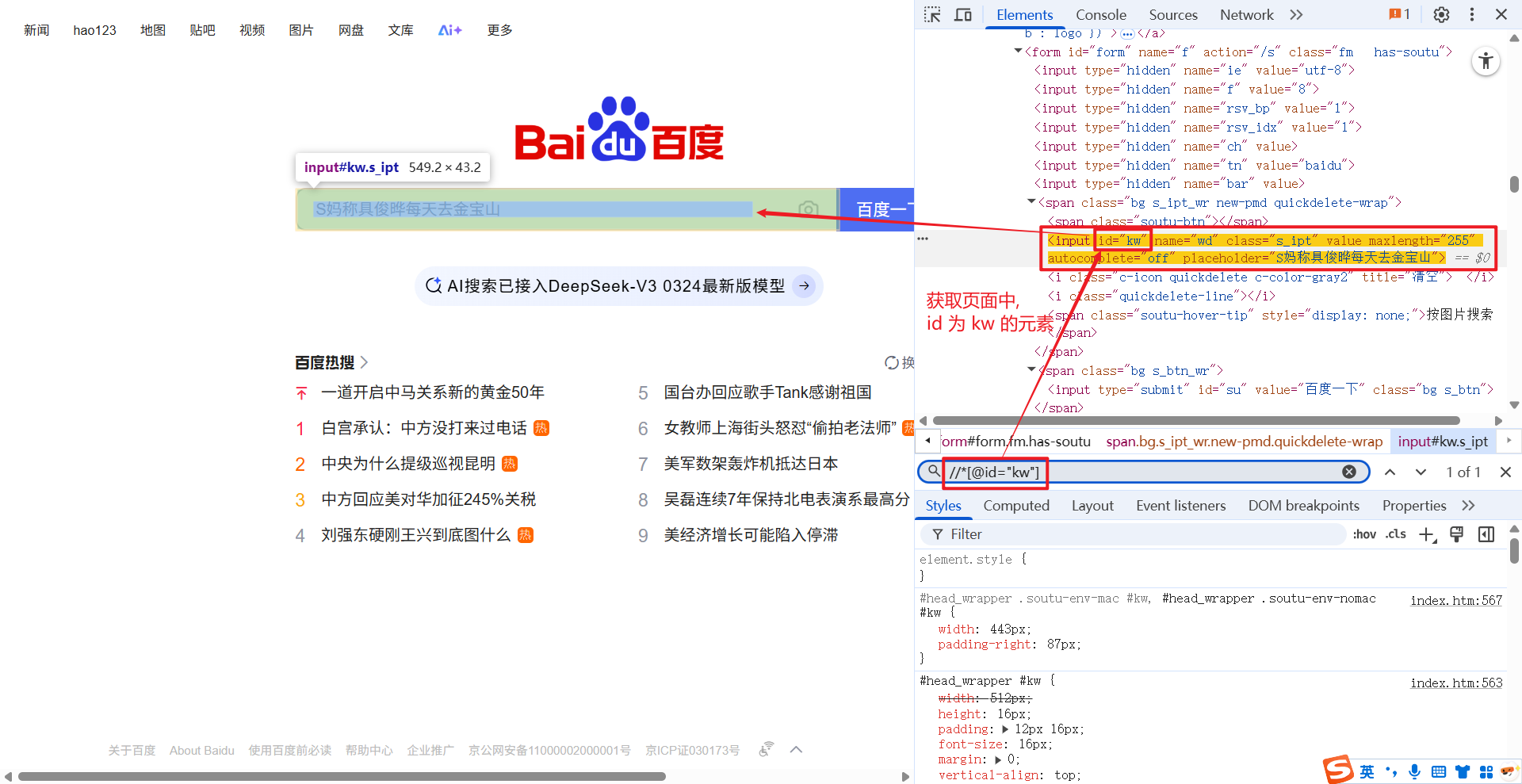
[@...] 的意思是, 获取对应的属性的元素.
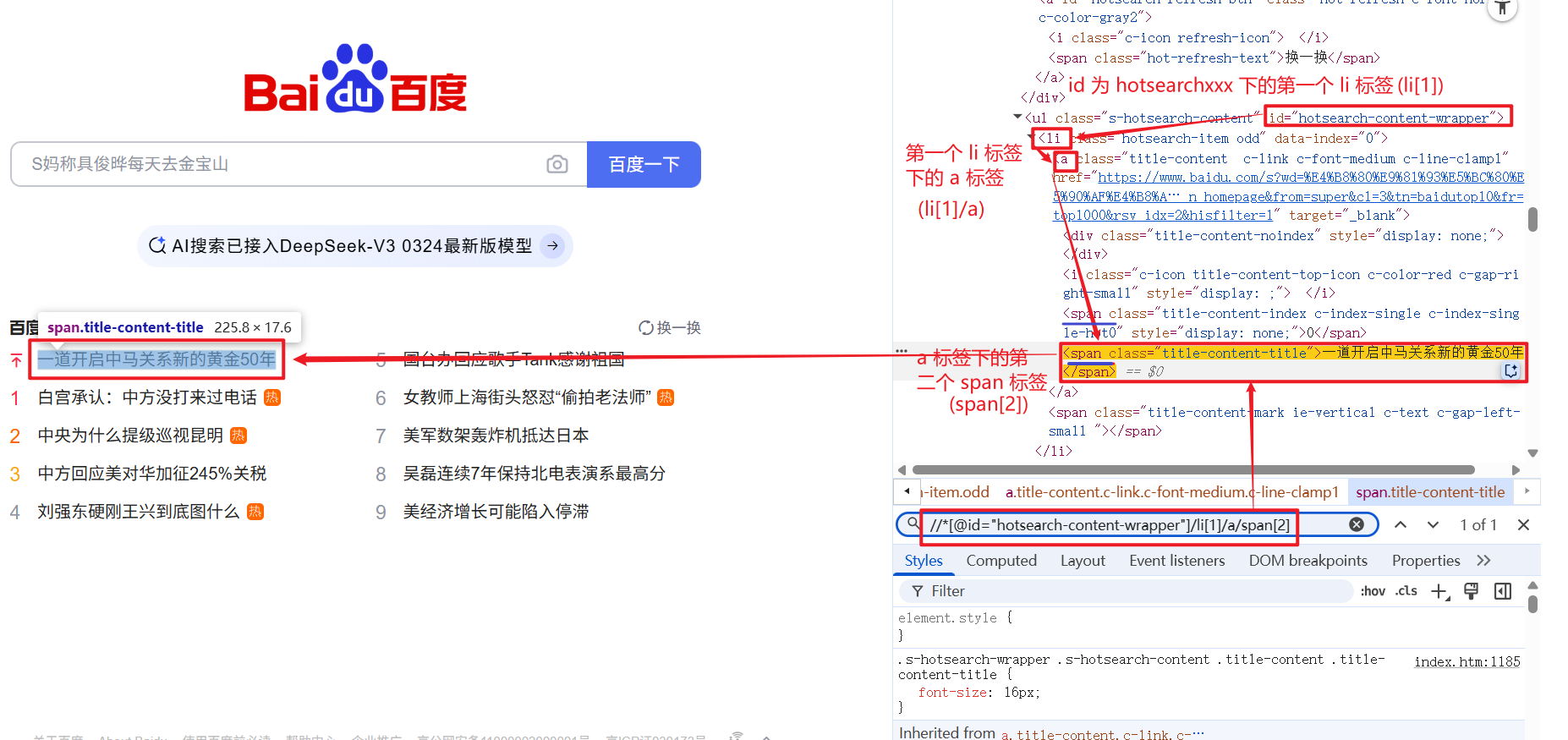
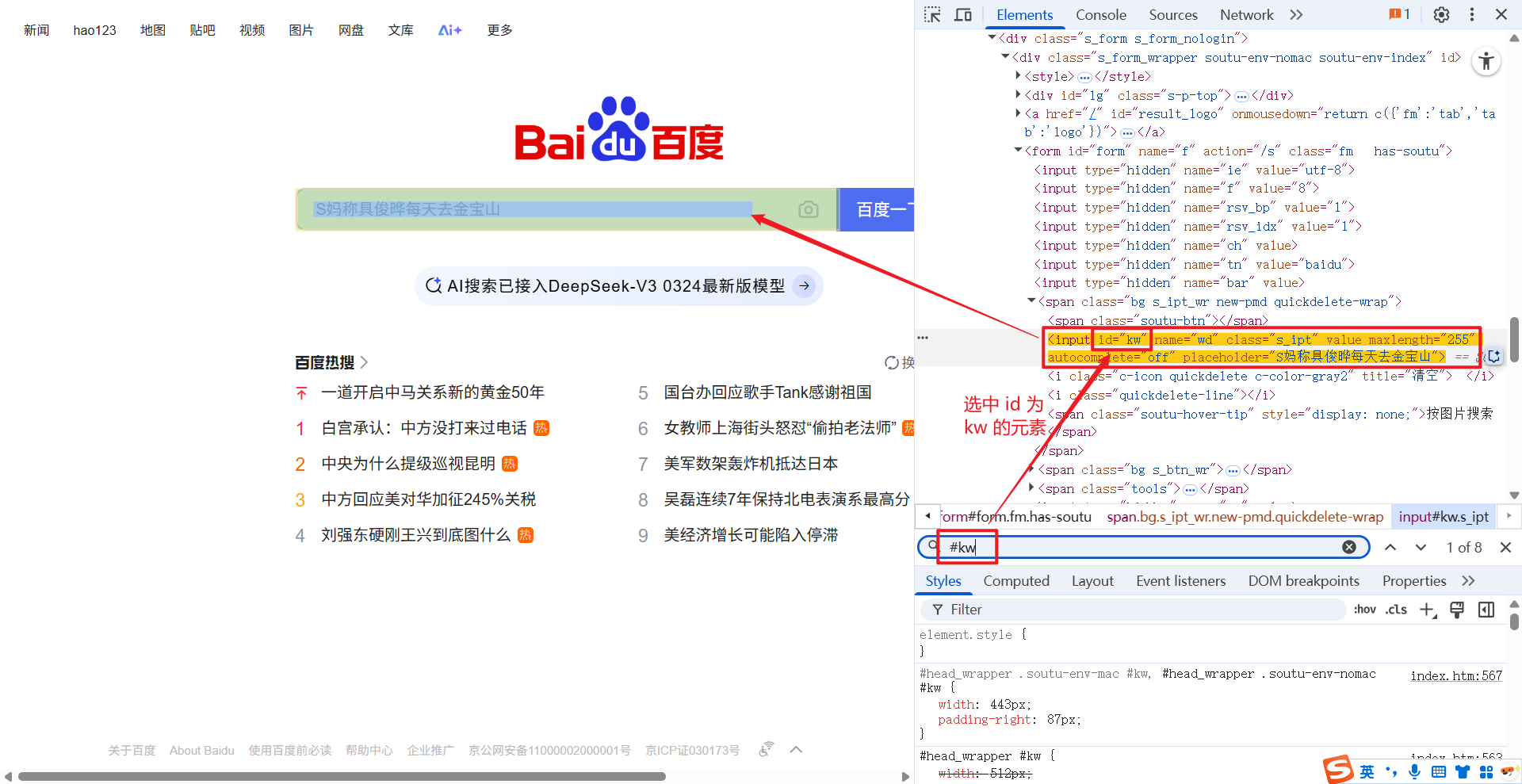
例如: //*[@id="kw"], 获取页面中 id 为 kw 的元素.
1.1.6 指定索引获取对应元素
例如: li[3] 就是获取第三个 li 标签.
注意: xpath 的是索引是从 1 开始的.
1.2 By.cssSelector
选择器的功能: 选中页面中指定的标签元素.
选择器的种类分为基础选择器和复合选择器, 常见的元素定位方式可以通过 id 选择器和子类选择器来进行定位.
1.2.1 #
# 为 id 选择器, 获取指定 id 的元素.
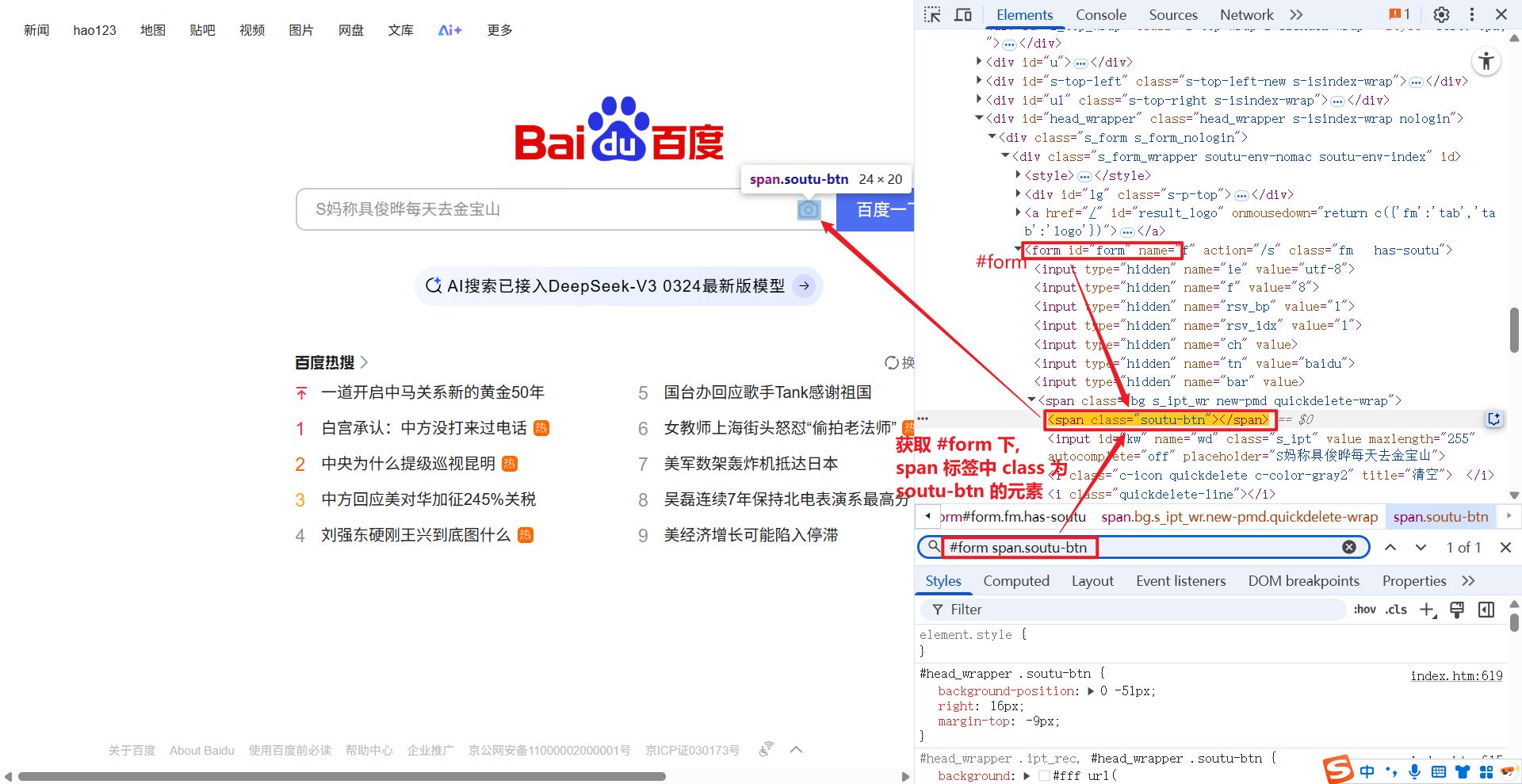
1.2.2 .
. 为 class 选择器, 获取指定 class 的元素
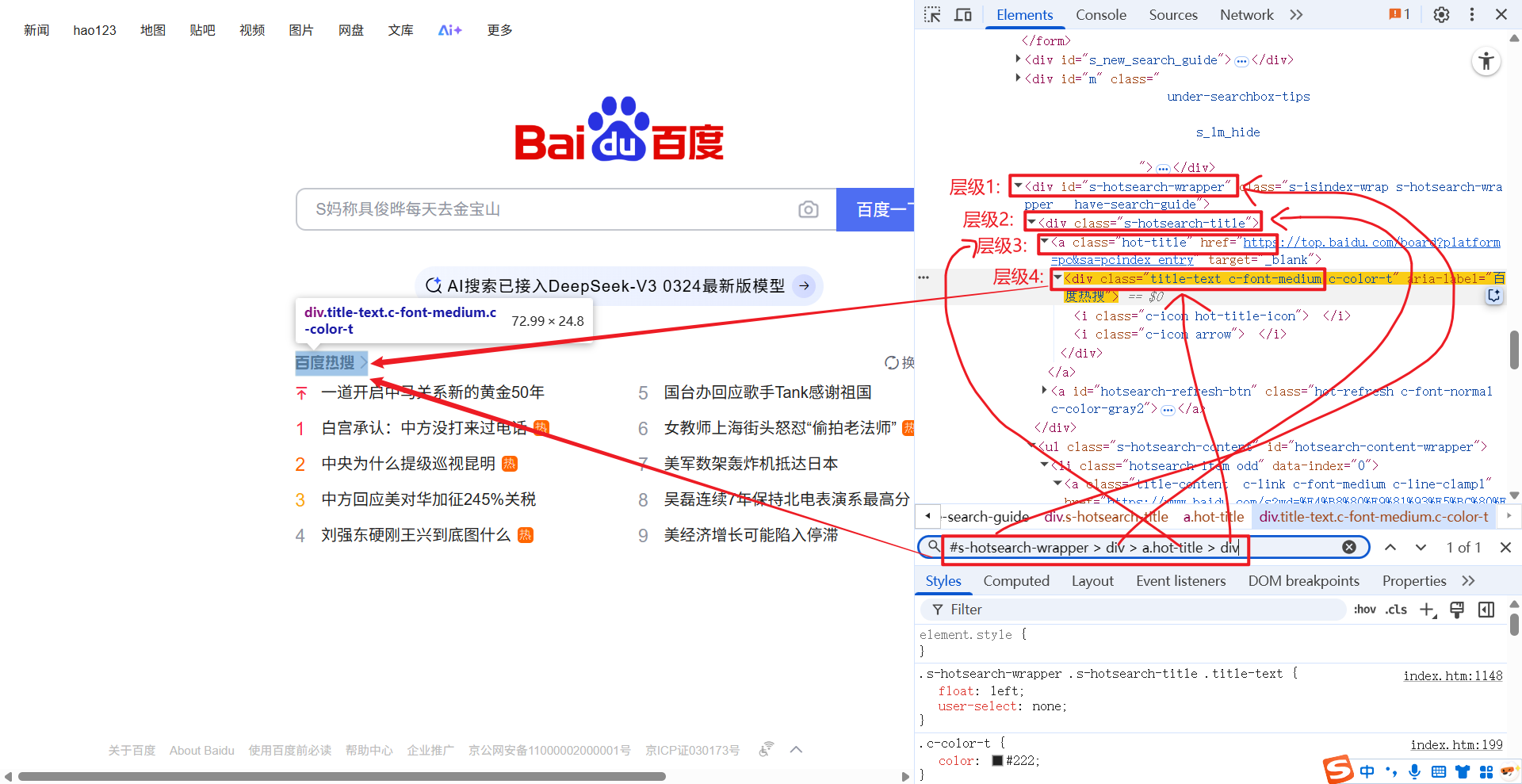
1.2.3 >
> 和 xpath 中的 / 是一个意思, 获取一个元素下的直接子节点.
1.2.4 标签名:nth-child(n)
标签名:nth-child(n) 和 xpath 中 li[n] 的意思相同, 都是通过索引获取指定元素
例如: li:nth-child(3) 就是获取第三个 li 标签

2. 获取元素
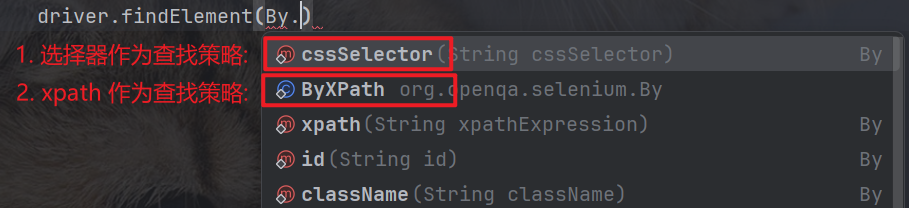
Selenium 提供了两个获取元素的方法:
- findElement
- findElements
这两个函数将定位策略(XPath/CSS Selector)作为参数, 并返回与该策略匹配的元素.

其中, findElement 返回定位到的第一个元素, findElements 返回定位到的所有元素.
如果找不到匹配的元素, 通常会抛出一个异常 (例如 NoSuchElementException).
2.1 findElement
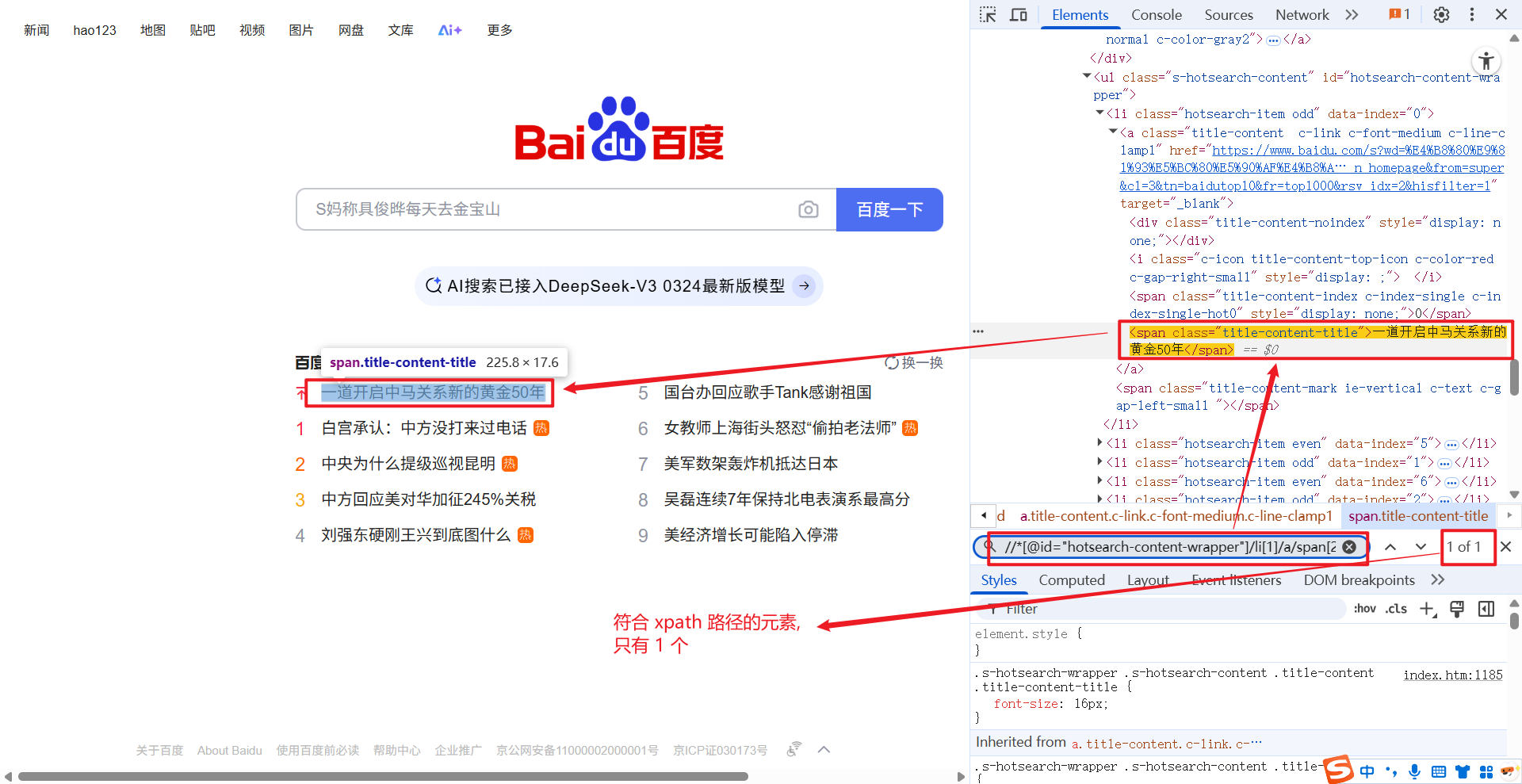
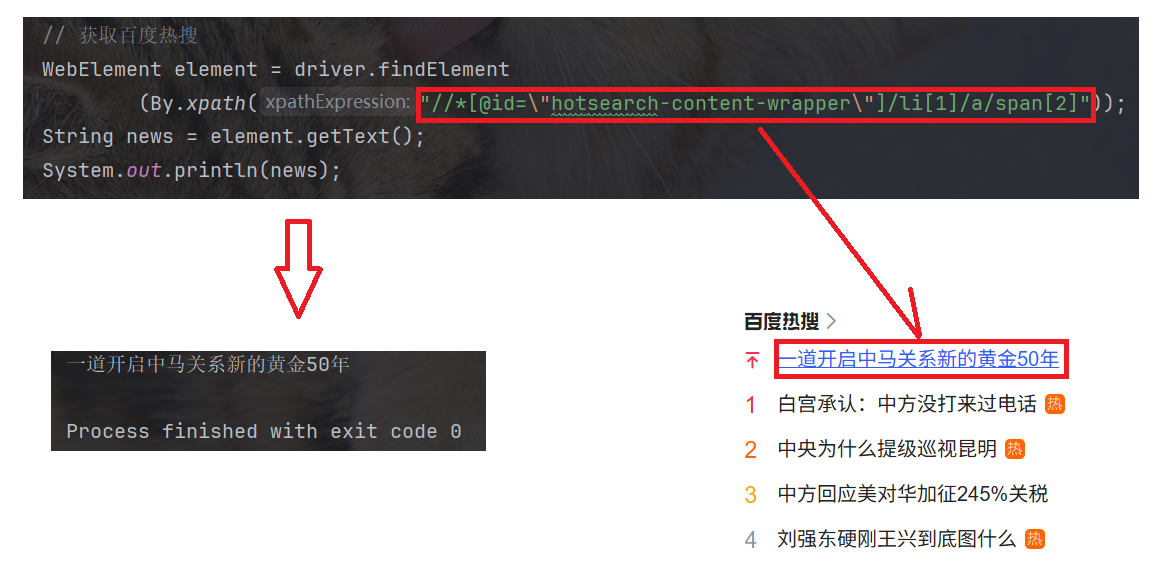
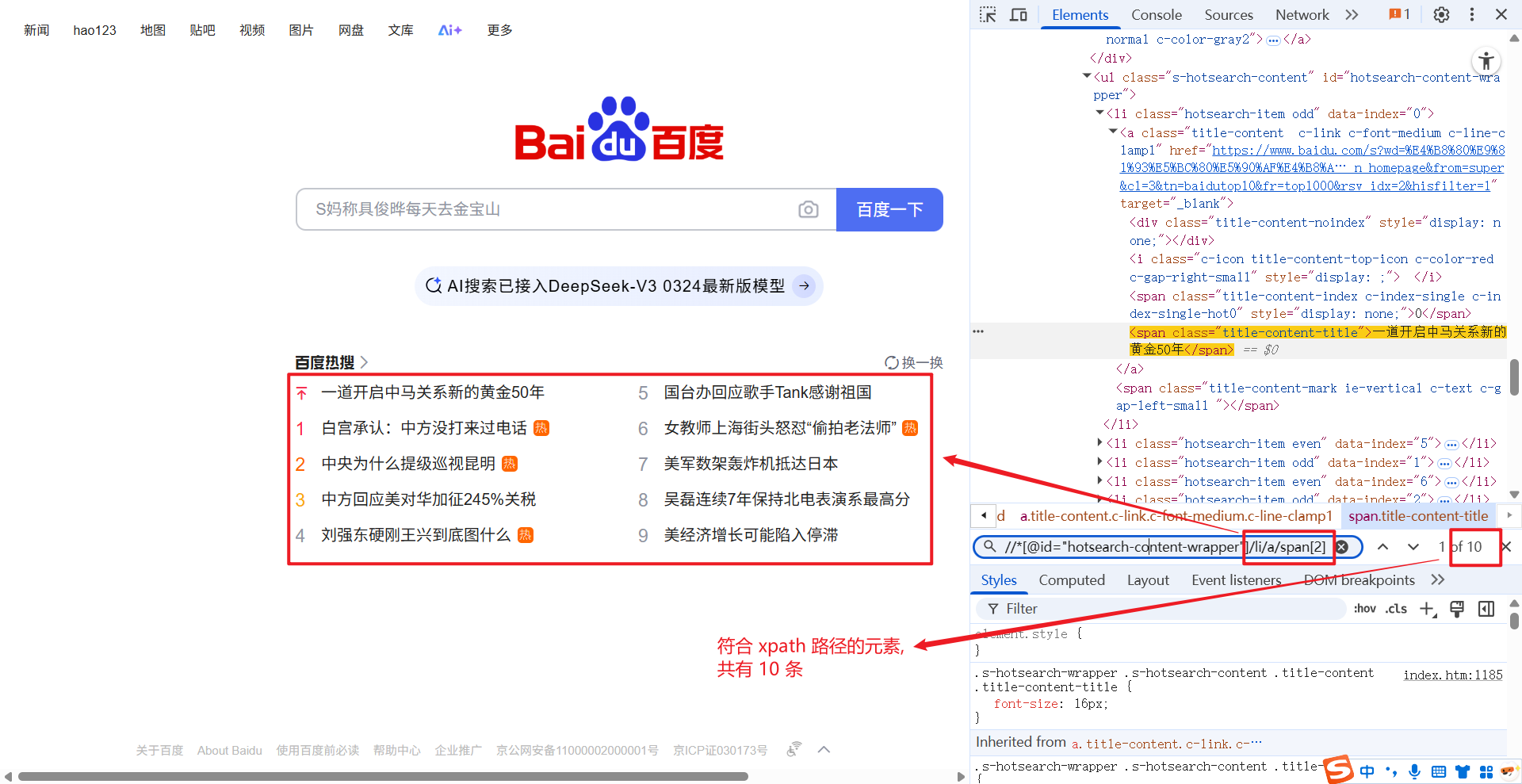
//*[@id="hotsearch-content-wrapper"]/li[1]/a/span[2] 这条 xpath 路径下, 只对应一个元素: 百度热搜第一条.
通过 Java 代码获取该元素:
2.2 findElements
我们将 xpath 中 li 标签的索引去掉后, 对应元素共有 10 条:
//*[@id="hotsearch-content-wrapper"]/li/a/span[2]
通过 Java 代码获取对应元素: 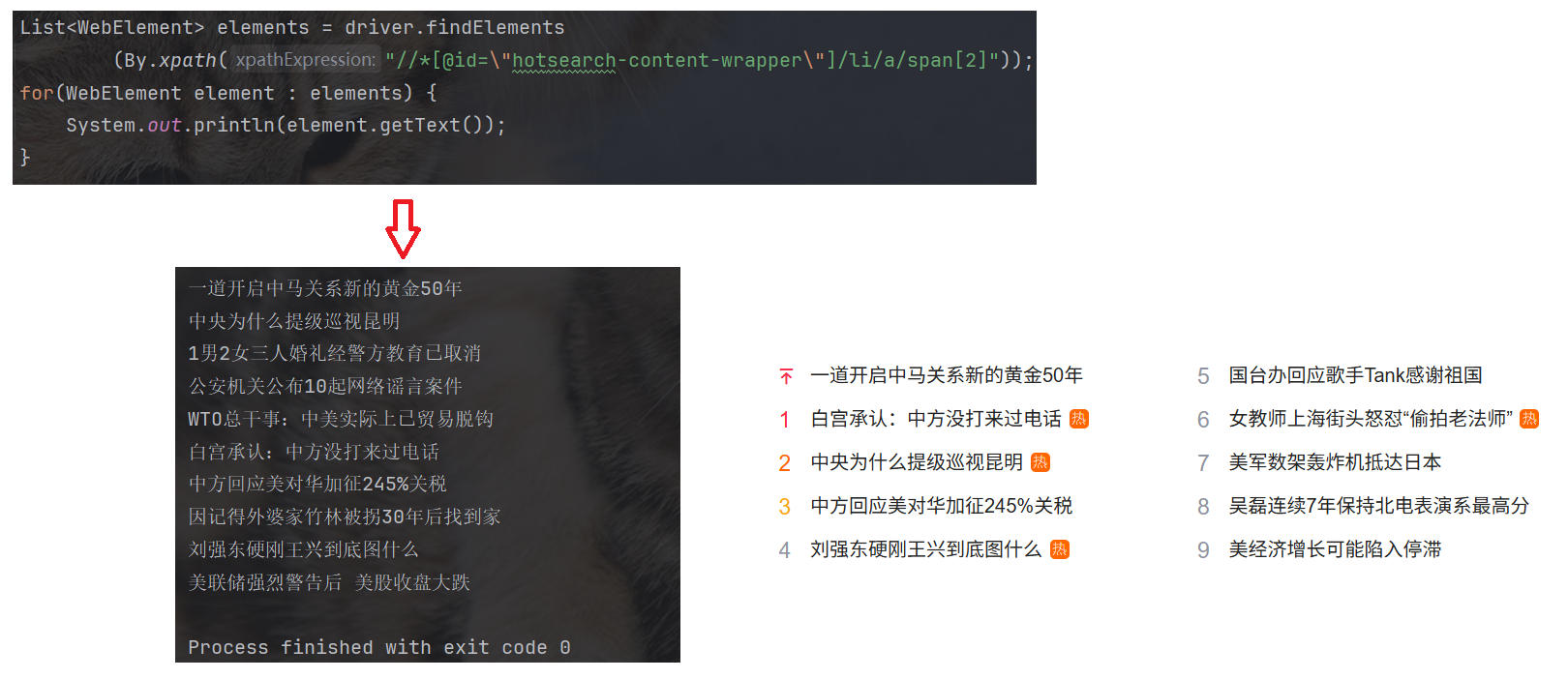
3. 操作测试对象
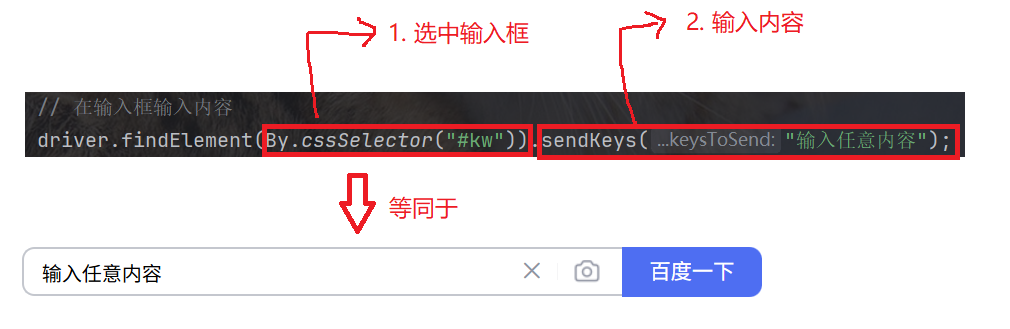
3.1 sendKeys 模拟按键输入
选中界面上的输入框后, 通过 sendKeys 方法, 输入任意内容:
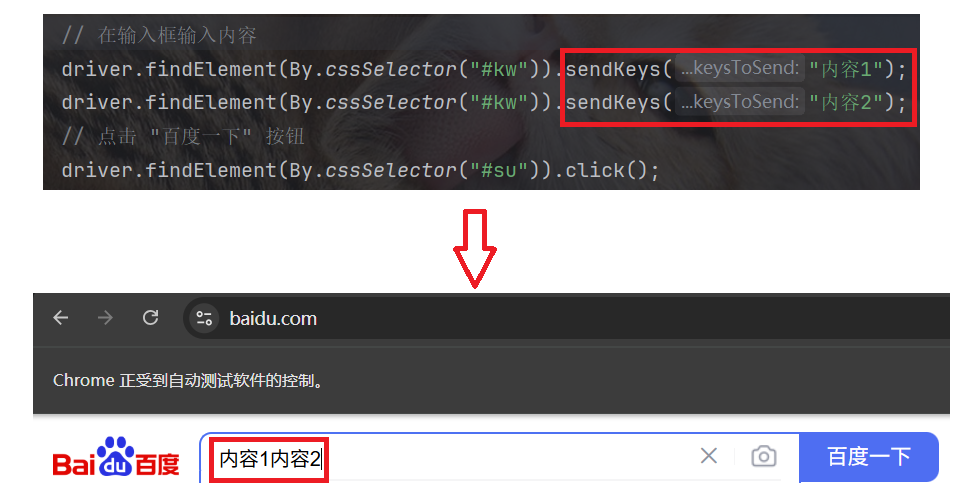
注意: 如果连续使用 sendKeys 进行输入, 后输入的内容会以追加的方式追加到前一个输入内容的后面:
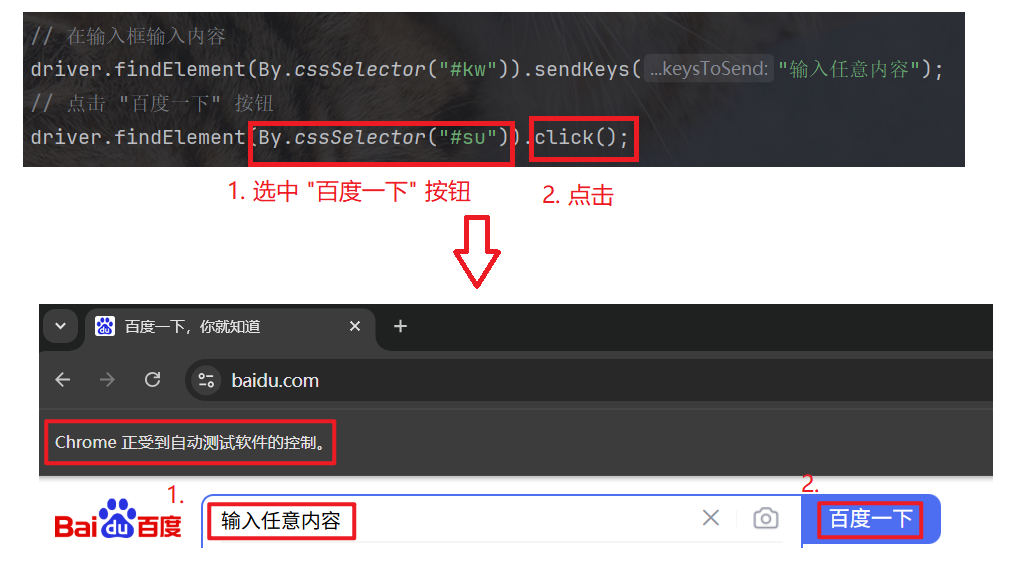
3.2 click 点击/提交对象
选中界面上的元素后, 调用 click 函数, 完成点击操作.
点击 "百度一下" 按钮:
点击百度热搜:

页面上的绝大多数元素都可以点击, 只有部分特殊元素无法点击 --- 隐藏的不可见标签无法点击, 点击会抛出异常:
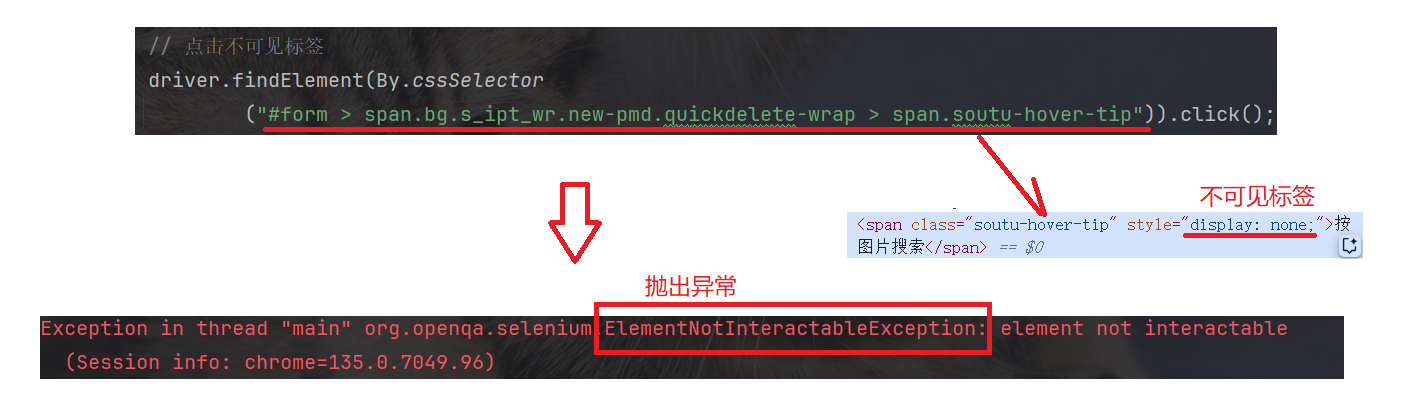
3.3 clear 清除文本内容
上文说到, sendKeys 是以追加的方式追加输入内容的.
如果我们想要清除之前输入的内容, 重新开始输入内容的话, 就可以使用 clear 清除之间的输入内容:
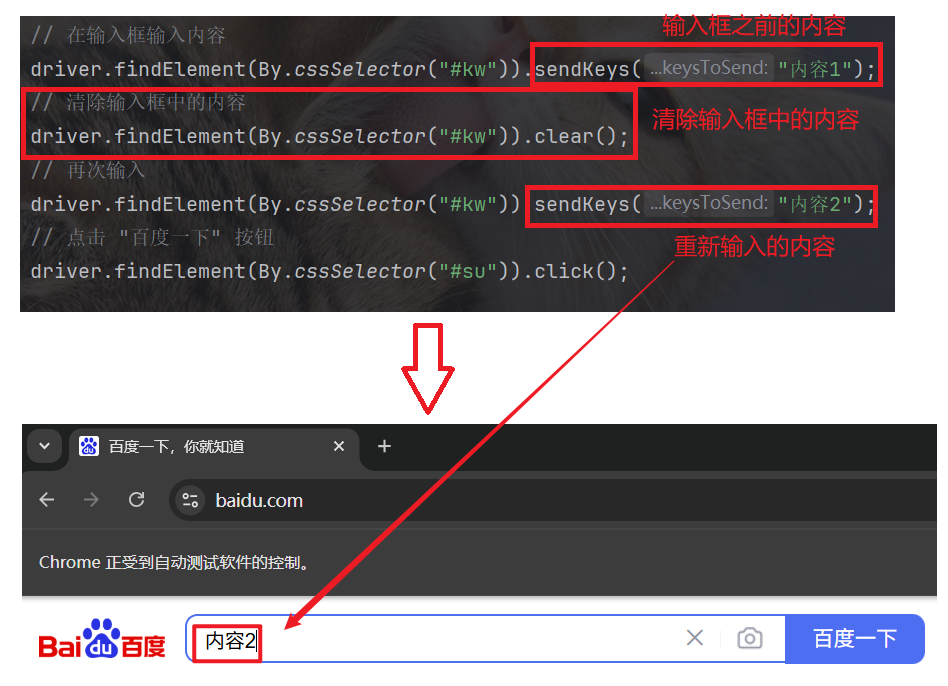
3.4 getText 获取文本信息
getText 可以获取 HTML 元素内部的可见文本内容.
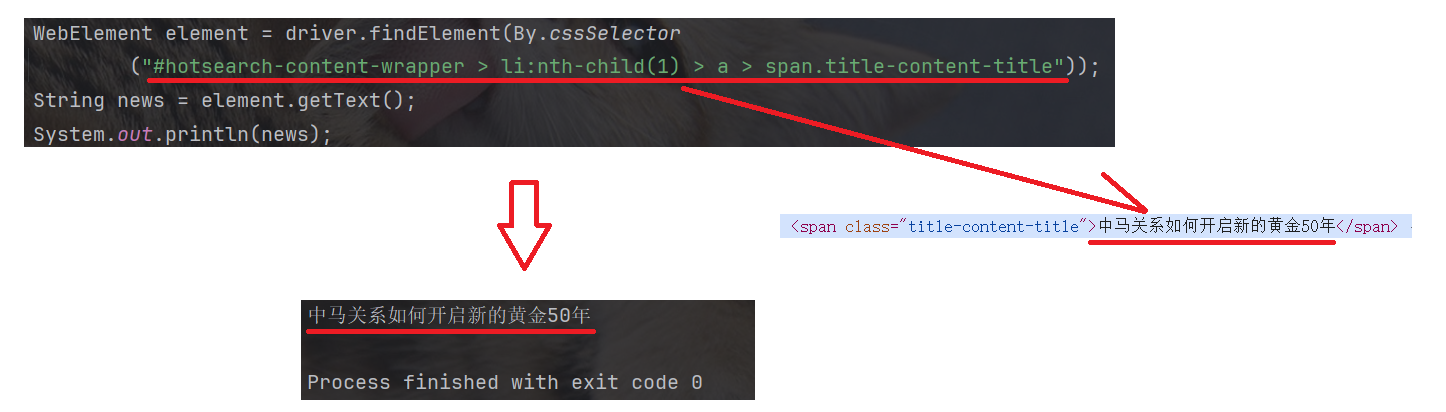
注意, getText 只能获取文本内容, 不能获取元素的属性值:
如下图所示, 我们本想获取 "百度一下" 这个文本字符串, 可以通过 getText 什么也没有获取到:
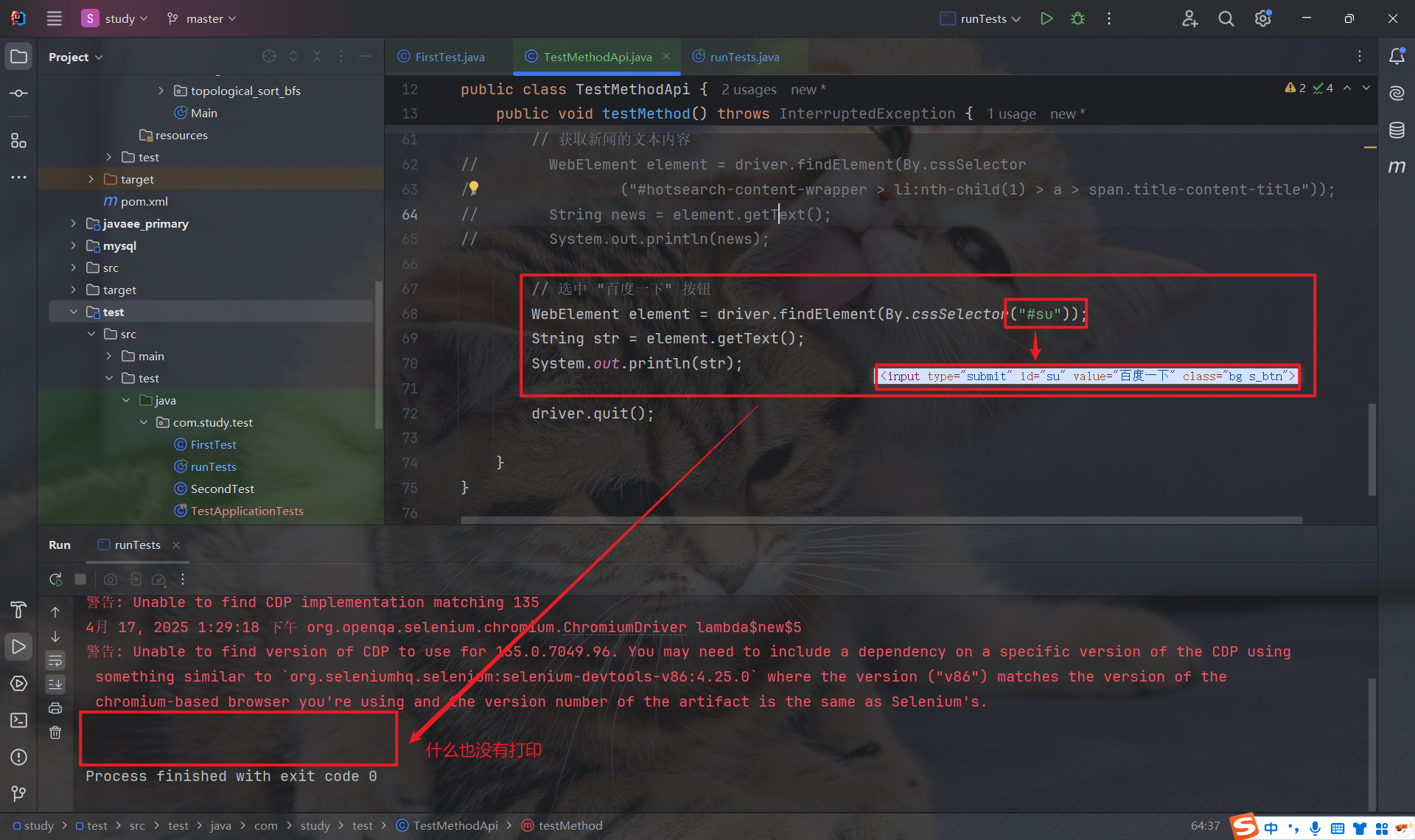
其实, 这个结果是符合预期的, 因为 getText 只能获取文本内容, 而 "百度一下" 是 input 标签中的 value 属性的属性值, 并非文本内容, 因此无法获取.
所以如果想要获取 "百度一下" , 就需要通过 getAttribute 获取 value 属性的属性值:
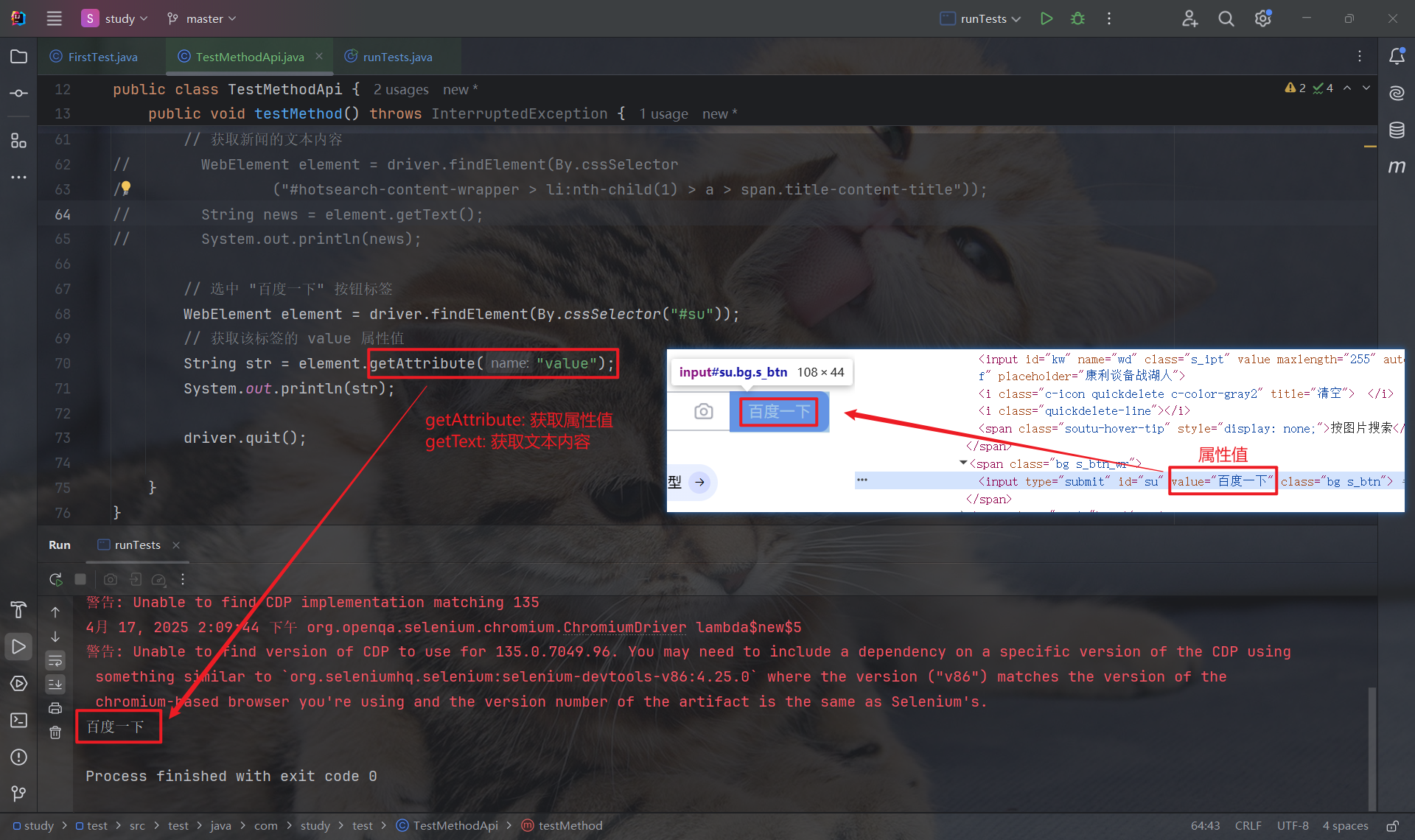
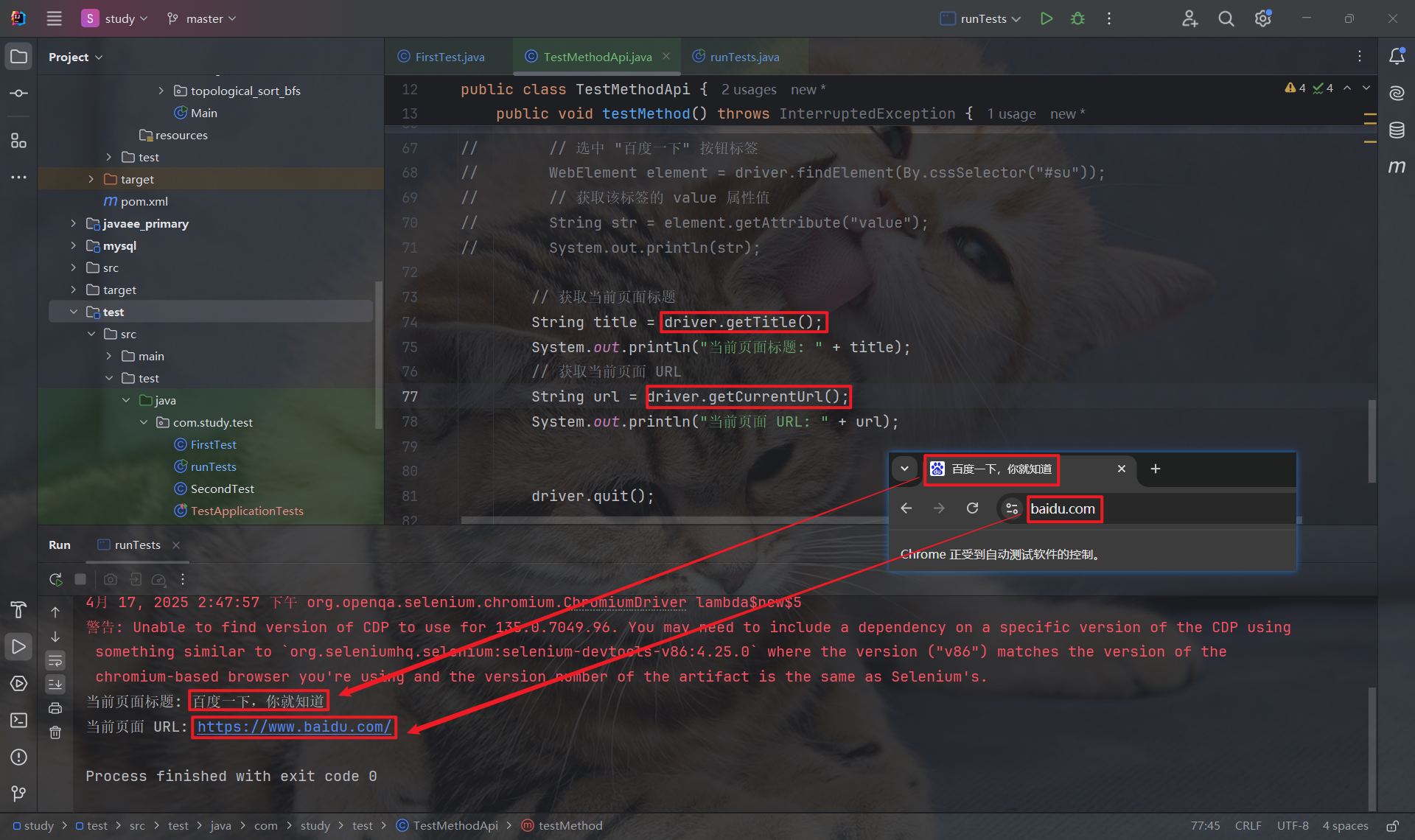
3.5 获取当前页面标题 & 获取当前页面 URL
- getTitle: 获取当前页面标题
- getCurrentUrl: 获取当前页面 URL
4. 窗口
4.1 窗口句柄
上文讲到 getTitle 和 getCurrentUrl 分别可以获取页面的标题和 URL, 我们对页面进行跳转操作后, 再次获取标题和 URL, 观察结果:
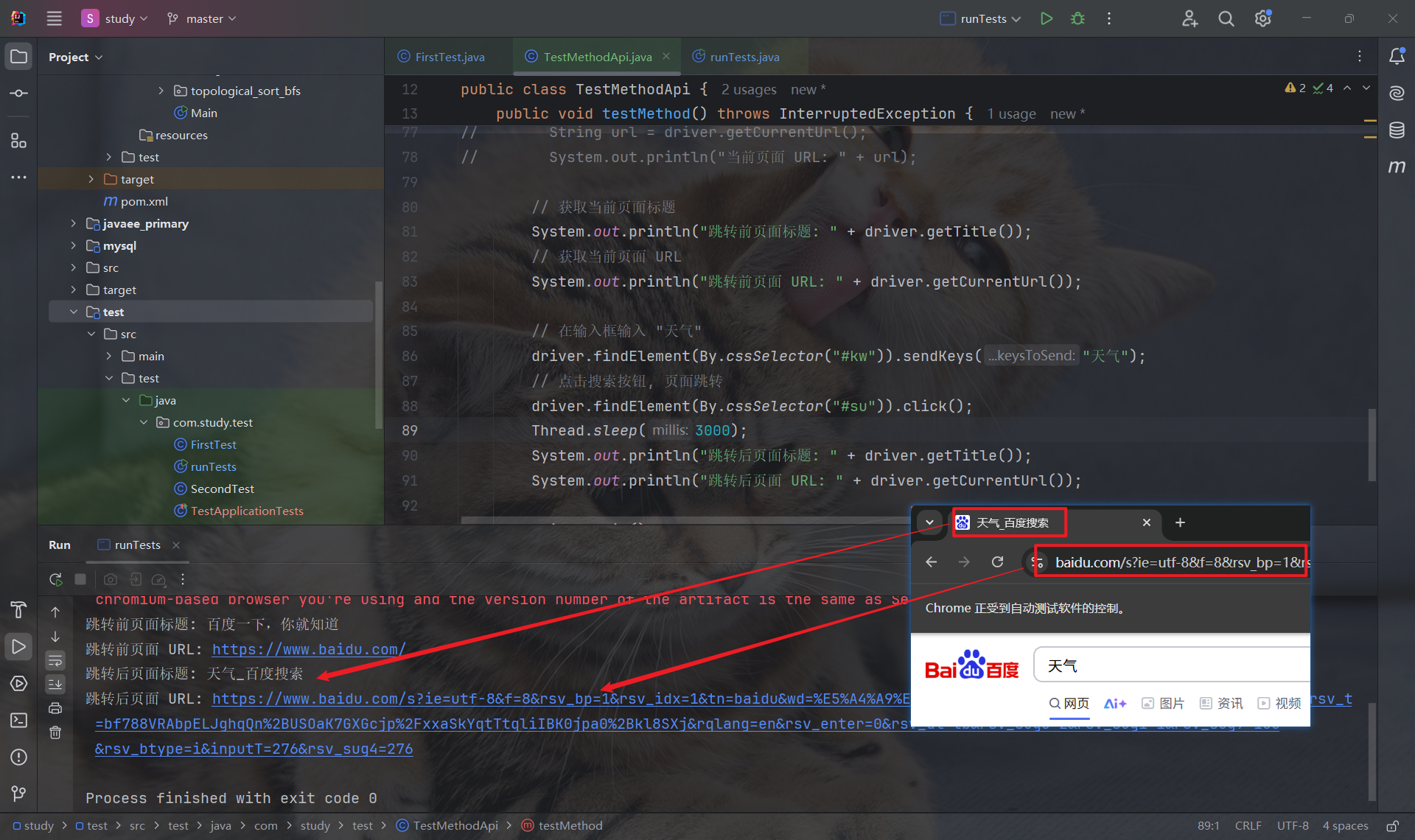
如上图所示, 我们也成功获取到了跳转后的标题和 URL.
但是, 当我们点击百度首页的超链接进行跳转时, 结果就和我们想的不太一样了:
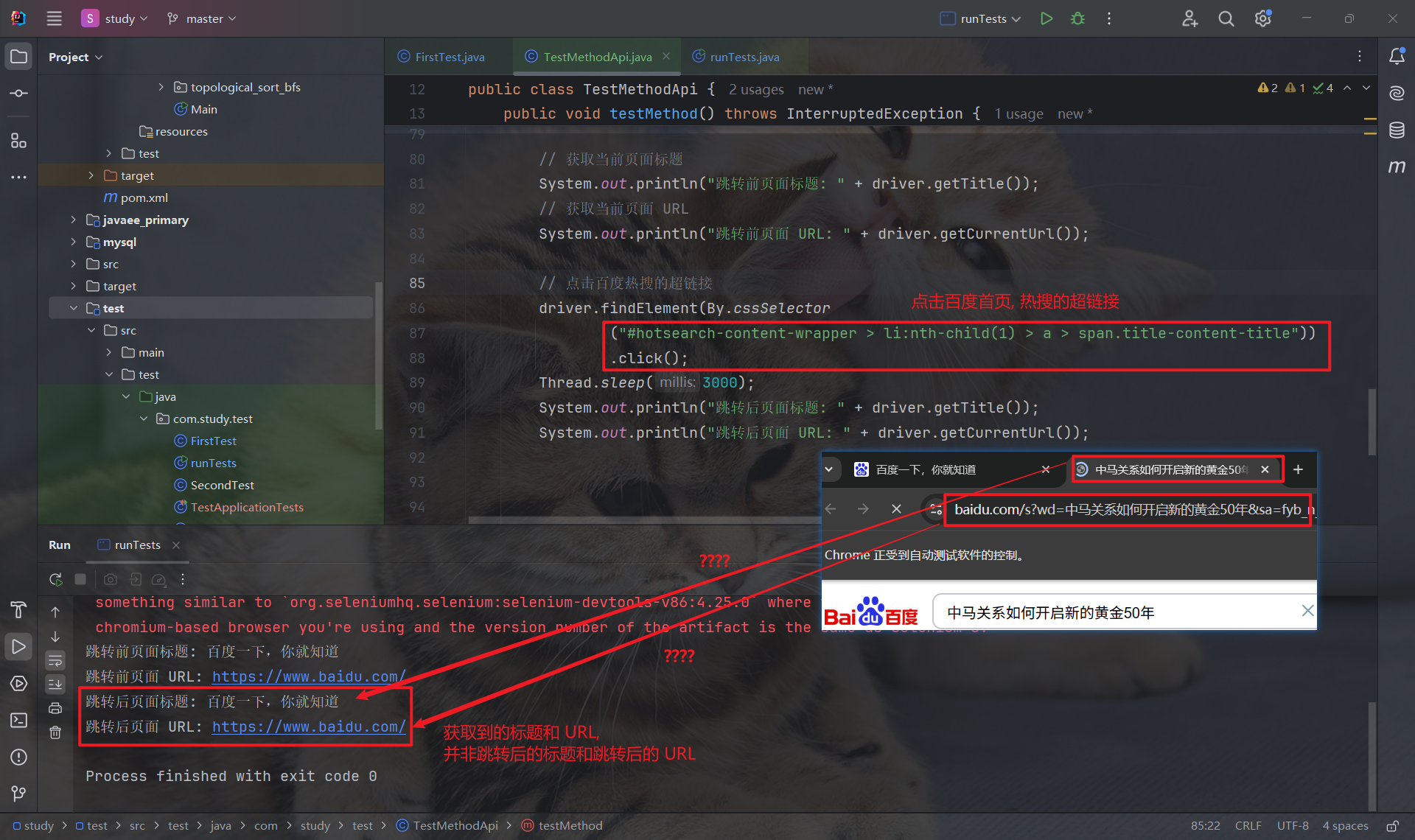
我们发现, 页面跳转后, 获取到的标题和 URL 并非跳转后的标题和 URL, 而仍然是百度首页的 URL 和超链接.
为啥以上两个跳转操作, 获取的结果不一样呢??
- 这是因为第一次的跳转操作, 原先的标签页进行了更新, 更新为跳转后的页面, driver 获取的也是跳转后的 title 和 URL.
- 而第二次的跳转操作, 标签页没有进行更新, 而是重新打开了一个新的标签页.
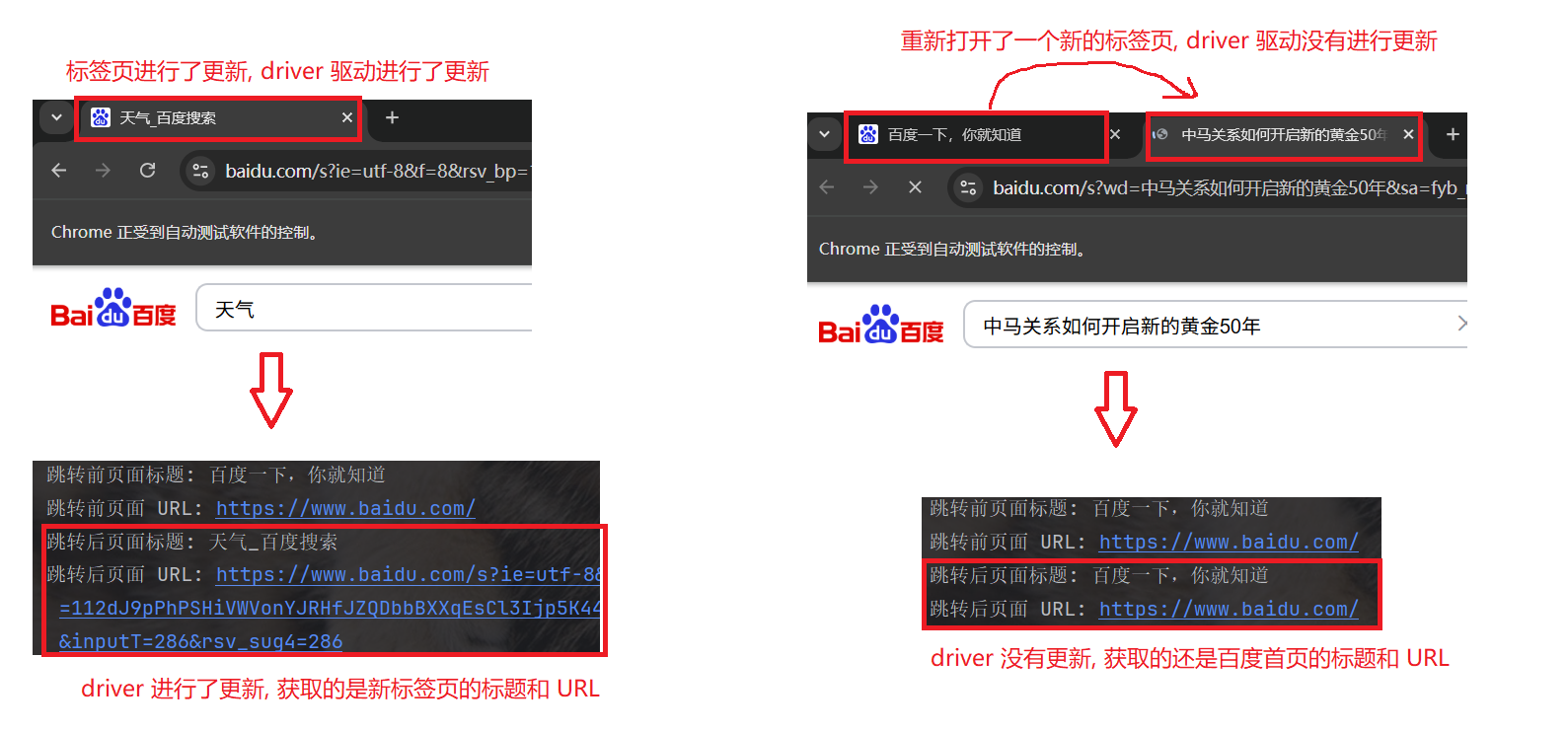
每一个标签页(窗口), 都有一个唯一的窗口句柄, 就像我们的身份证号一样, 作为身份标识.
如果我们跳转页面后, driver 没有更新为跳转后的页面, 我们可以通过句柄, 手动将 driver 进行更新.
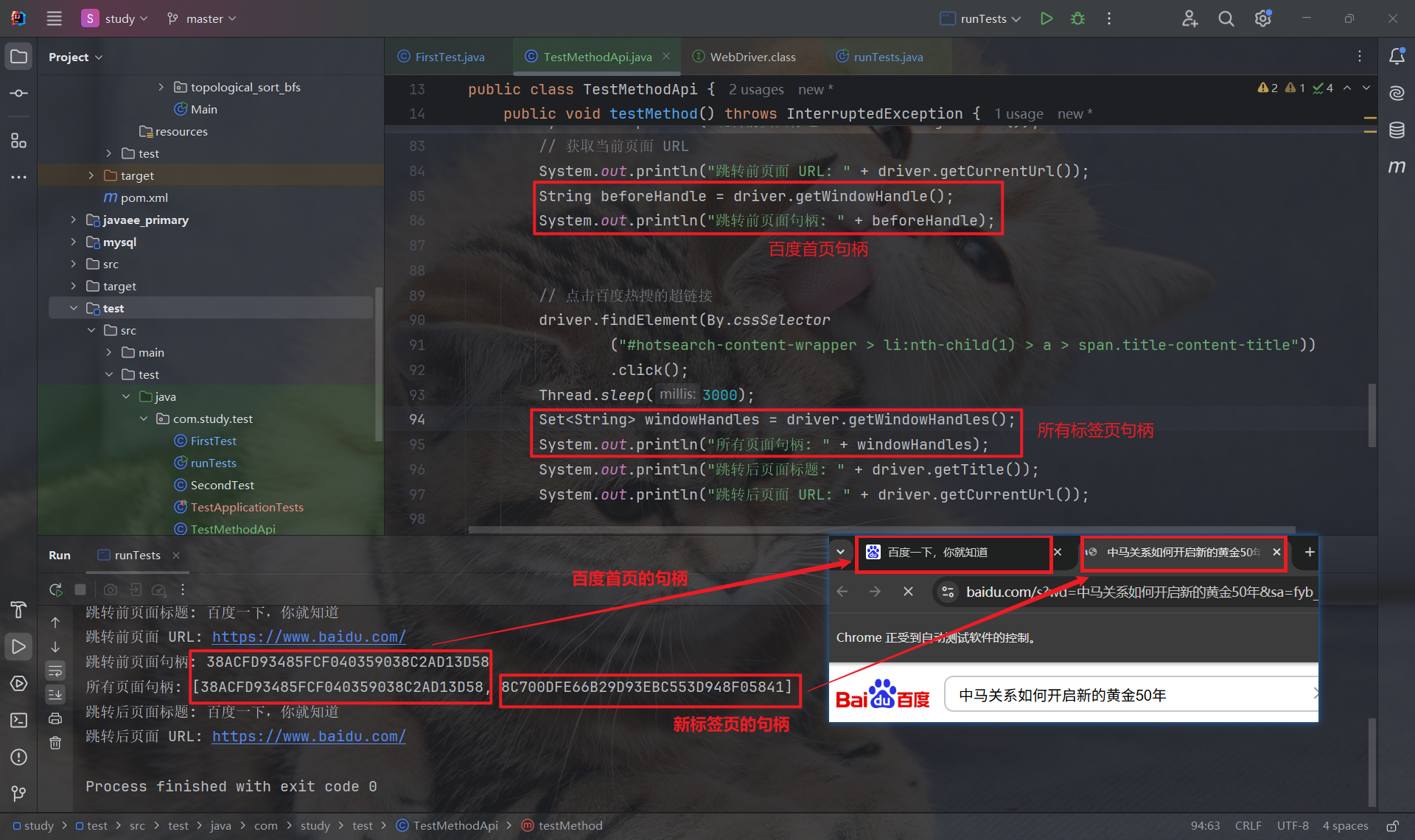
4.1.1 获取句柄
- driver.getWindowHandle: 获取当前页面的句柄
- driver.getWindowHandles: 获取所有窗口的句柄

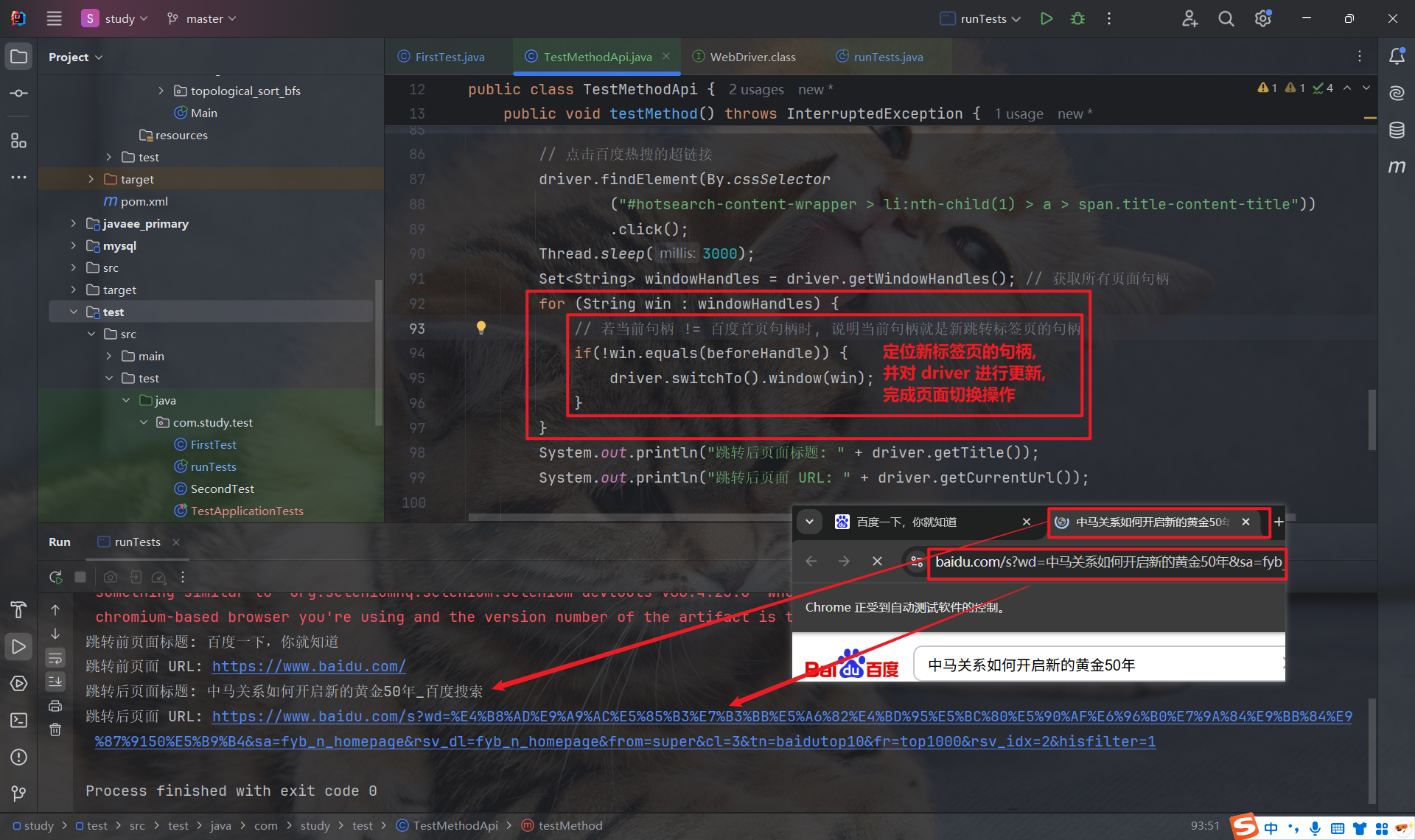
 4.1.2 切换窗口
4.1.2 切换窗口
获取到目标页面的句柄后, 我们可以通过 driver.switchTo().window(targetHandle) 来更新 driver, 完成页面切换操作:
其实在进行自动化测试时, 通常不会存在打开好几个页面的情况.
如果要对某个页面进行自动化测试, 我们直接 driver.get(URL) 打开对应的页面即可:

4.2 设置窗口大小
// 设置窗口全屏
driver.manage().window().fullscreen();
Thread.sleep(3000);
// 设置窗口最大化
driver.manage().window().maximize();
Thread.sleep(3000);
// 设置窗口最小化
driver.manage().window().minimize();
Thread.sleep(3000);
// 自定义窗口大小
driver.manage().window().setSize(new Dimension(1400, 975));
Thread.sleep(3000);4.3 窗口截图
自动化测试, 都是在后台自动执行的, 测试人员不会一直盯着屏幕看, 因此, 当程序出现报错时, 可以通过屏幕截图的方式, 将出现问题的窗口截图保存下来.
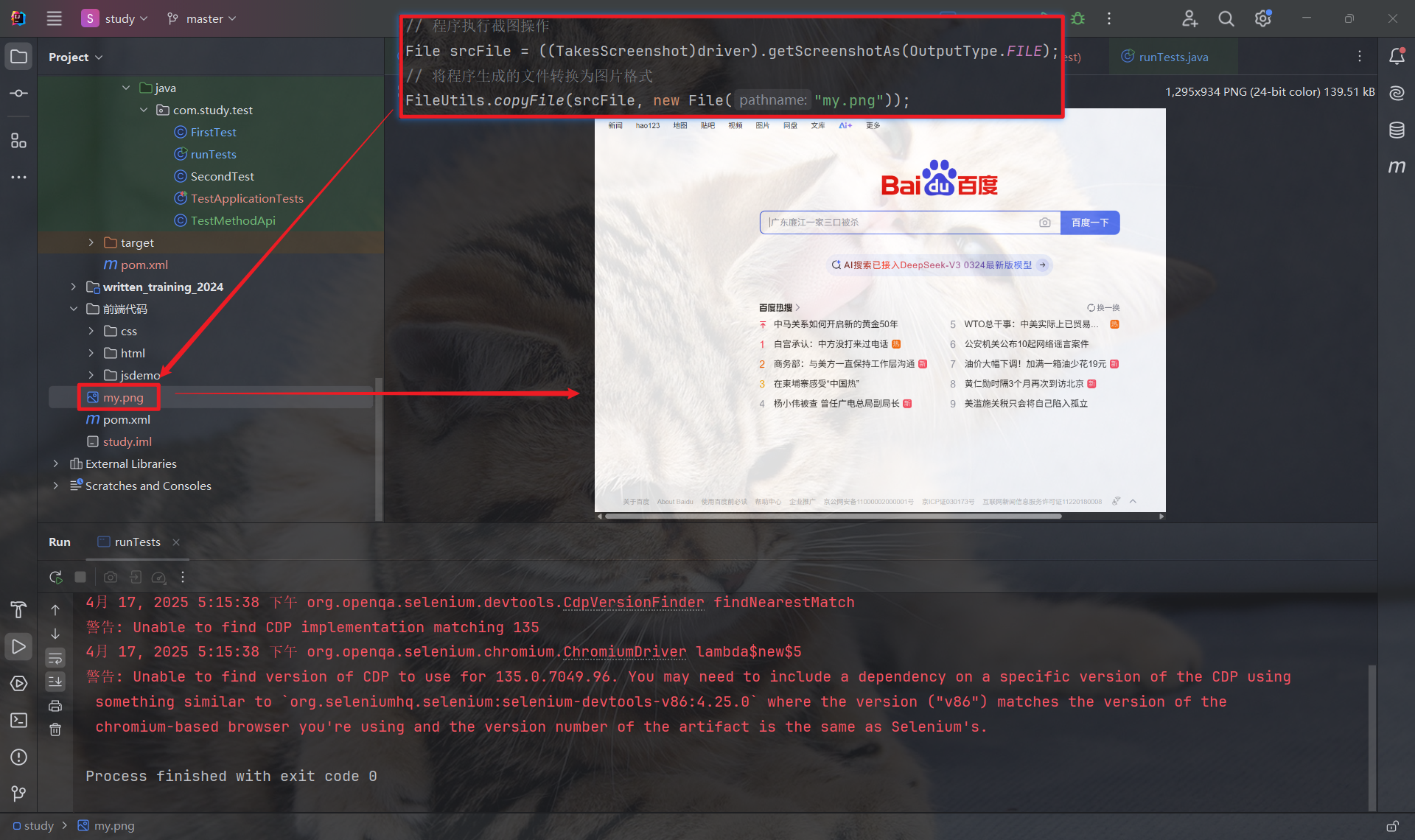
// 程序执行截图操作
File srcFile = ((TakesScreenshot)driver).getScreenshotAs(OutputType.FILE);
// 将截图下的文件进行保存
FileUtils.copyFile(srcFile, new File("my.png"));File srcFile = ((TakesScreenshot)driver).getScreenshotAs(OutputType.FILE); 这一行代码的作用是:
-
强制类型转换: 将 driver 对象转换为 TakesScreenshot 接口. 这是因为只有实现了 TakesScreenshot 接口的 WebDriver 才能进行截图操作.
-
调用 getScreenshotAs(OutputType.FILE): 调用 getScreenshotAs() 方法,并指定 OutputType.FILE 作为参数. 这告诉 WebDriver 将截图保存为一个临时文件. 关键点: 虽然叫做 "File", 但实际上 srcFile 代表的是一个临时文件(并没有保存在我们的项目中), 这个临时文件是一个图片格式的数据 (通常是 PNG).
FileUtils.copyFile(srcFile, new File("my.png")); 这一行代码的作用是:
-
FileUtils.copyFile(srcFile, new File("my.png")): 调用 FileUtils.copyFile() 方法, 将 srcFile (临时文件) 的内容复制到 new File("my.png") 指定的文件中进行保存.
-
new File("my.png"): 创建一个新的 File 对象, 参数是要保存文件的文件名和路径. 如果 只包含文件名, 则该文件将保存在当前工作目录下("my.png" 就只是个文件名, 因此只保存在当前项目路径下).
FileUtils 是第三方库提供的 api, 因此使用时需要引入依赖:
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>4.3.1 定义截图文件路径
在上文中, 简单演示了一下如何进行窗口截图.
但是存在一个问题, 所有截图下来的图片的文件名称都为 my.png , 那么新生成的图片就会覆盖上一次生成的文件.
为了避免生成的图片不会因为名称重复而覆盖, 我们可以根据 "时间戳" 来对文件进行命名, 这样就能保证生成的图片的名称是唯一的.
使用 SImpleDataFormat 来自定义时间格式:
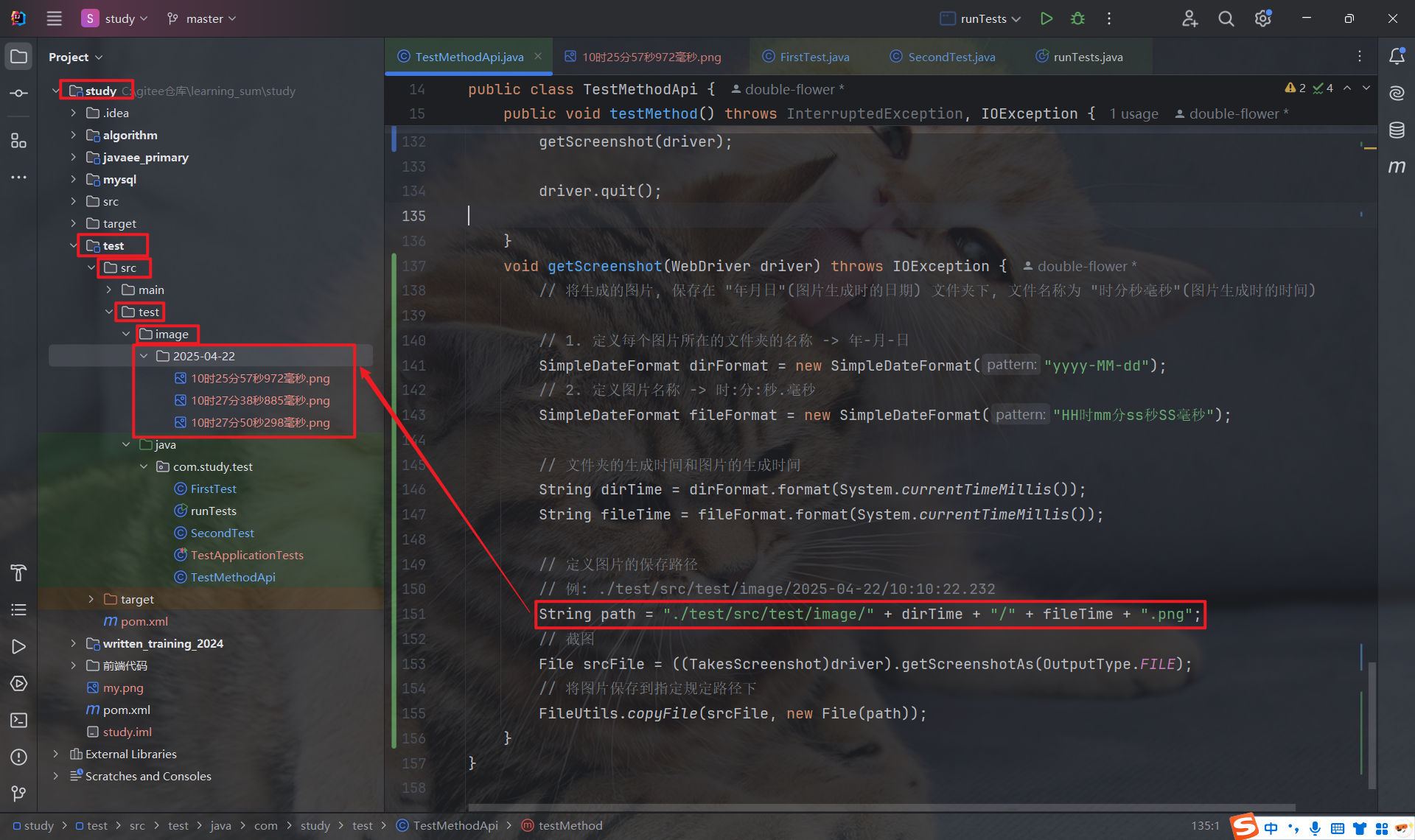
void getScreenshot(WebDriver driver) throws IOException {
// 将生成的图片, 保存在 "年月日"(图片生成时的日期) 文件夹下, 文件名称为 "时分秒毫秒"(图片生成时的时间)
// 1. 定义每个图片所在的文件夹的名称 -> 年-月-日
SimpleDateFormat dirFormat = new SimpleDateFormat("yyyy-MM-dd");
// 2. 定义图片名称 -> 时:分:秒.毫秒
SimpleDateFormat fileFormat = new SimpleDateFormat("HH时mm分ss秒SS毫秒");
// 文件夹的生成时间和图片的生成时间
String dirTime = dirFormat.format(System.currentTimeMillis());
String fileTime = fileFormat.format(System.currentTimeMillis());
// 定义图片的保存路径
// 例: ./test/src/test/image/2025-04-22/10:10:22.232
String path = "./test/src/test/image/" + dirTime + "/" + fileTime + ".png";
// 截图
File srcFile = ((TakesScreenshot)driver).getScreenshotAs(OutputType.FILE);
// 将图片保存到指定规定路径下
FileUtils.copyFile(srcFile, new File(path));
}这样, 我们就可以很好的区分出每张截图生成时的日期, 以及每张截图生成时的具体时间了.
4.4 关闭窗口
关闭窗口有两个方法:
- driver.quit
- driver.close
4.4.1 driver.quit
driver.quit, 关闭整个浏览器.
不管开启了多少个标签页, driver.quit 都会全部关闭, 即关闭整个浏览器.
4.4.2 driver.close
driver.close 只会关闭当前标签页.
使用 driver.close 后, 如果还需要使用 driver 对其他标签页进行操作, 那么需要重新定义 driver, 将 driver 指向一个新的标签页(driver.switchTo().window(新标签页句柄)).
因为虽然使用 driver.close 关闭了当前标签页, 但是 driver 的指向没有改变, 仍指向那个已经关闭的标签页, 此时 driver 为一个 "野指针".
在实际工作中, 我们通常使用 driver.quit 直接关闭浏览器就可以了. 很少使用 driver.close
5. 等待
5.1 NoSuchElementException - 面试题
为什么要进行 "等待" 呢??
我们先来看下面这个异常.
当我们使用自动化获取页面上的某个元素时, 出现了 NoSuchElementException 异常(在界面上找不到该元素):
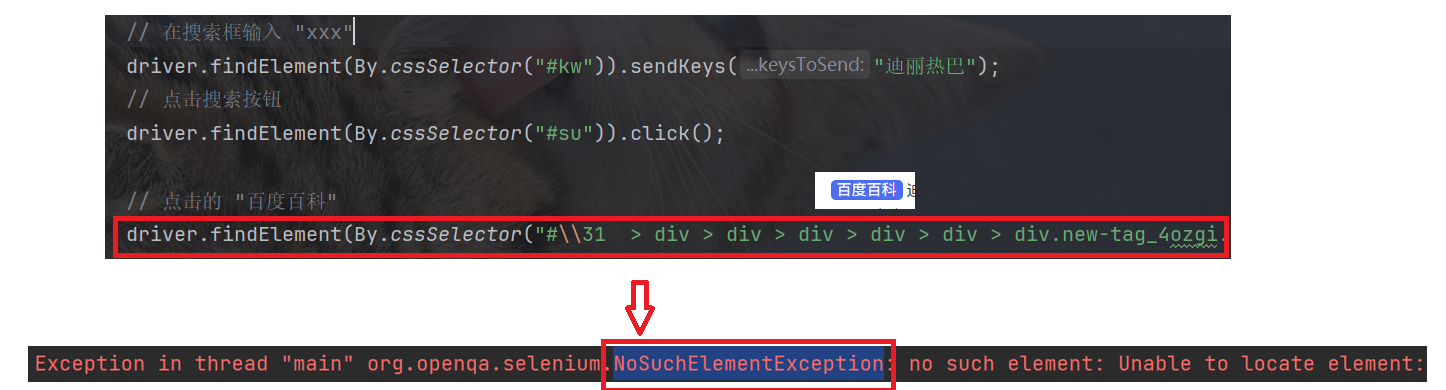
NoSuchElementException 异常可能是由以下几种原因导致的:
- 我们自己把 cssSelector/xpath 给写错了, 界面上确实没有这个元素
- 复制的是 xpath, 却用 By.cssSelector 查找; 复制的是 cssSelector, 却用 By.xpath 查找
- 自动化打开的页面和我们手动打卡的页面不一样(比如: 我们手工打开的页面, 可能是已经登陆的状态, 但是自动化打开的页面默认是未登录的状态, 登录和未登录的页面可能是不同的, 页面不用那么 cssSelector/xpath 自然也不同)
- 要查找的元素, 是动态元素. 该元素可能是动态元素, 页面每刷新一次, 元素的 id或者其他属性 就会发生变化.
- 代码执行的速度, 比页面加载/渲染的速度要快.
其中, 第五点就是我们要进行 "等待" 的原因 --- 代码执行的速度, 要比页面加载的速度快的多. 当代码执行 findElement 查找页面上的元素时, 页面可能还未加载完毕, 页面上的元素自然也查找不到.
因此, 回顾上文示例, 虽然我们在搜索框输入了内容, 并点击了搜索按钮, 但是搜索结果页面还未加载完毕, 而此时我们就使用了 findElement 去查找 "百度百科" 这个界面元素, 而 "百度百科" 这个页面元素还没有加载出来, 因此就出现了 NoSuchElementException 异常.
此时我们就需要进行 "等待", 等待页面元素完毕后, 再进行 findElement 查找元素.
5.2 等待分类
等待分为强制等待和智能等待两种:
- 强制等待 - Thread.sleep
- 智能等待 - 隐式等待, 显式等待
其中, 智能等待也分为两种:
- 隐式等待 - implicitlyWait()
- 显式等待 - new WebDriverWait(driver, Duration.ofSeconds(3)).until($express)
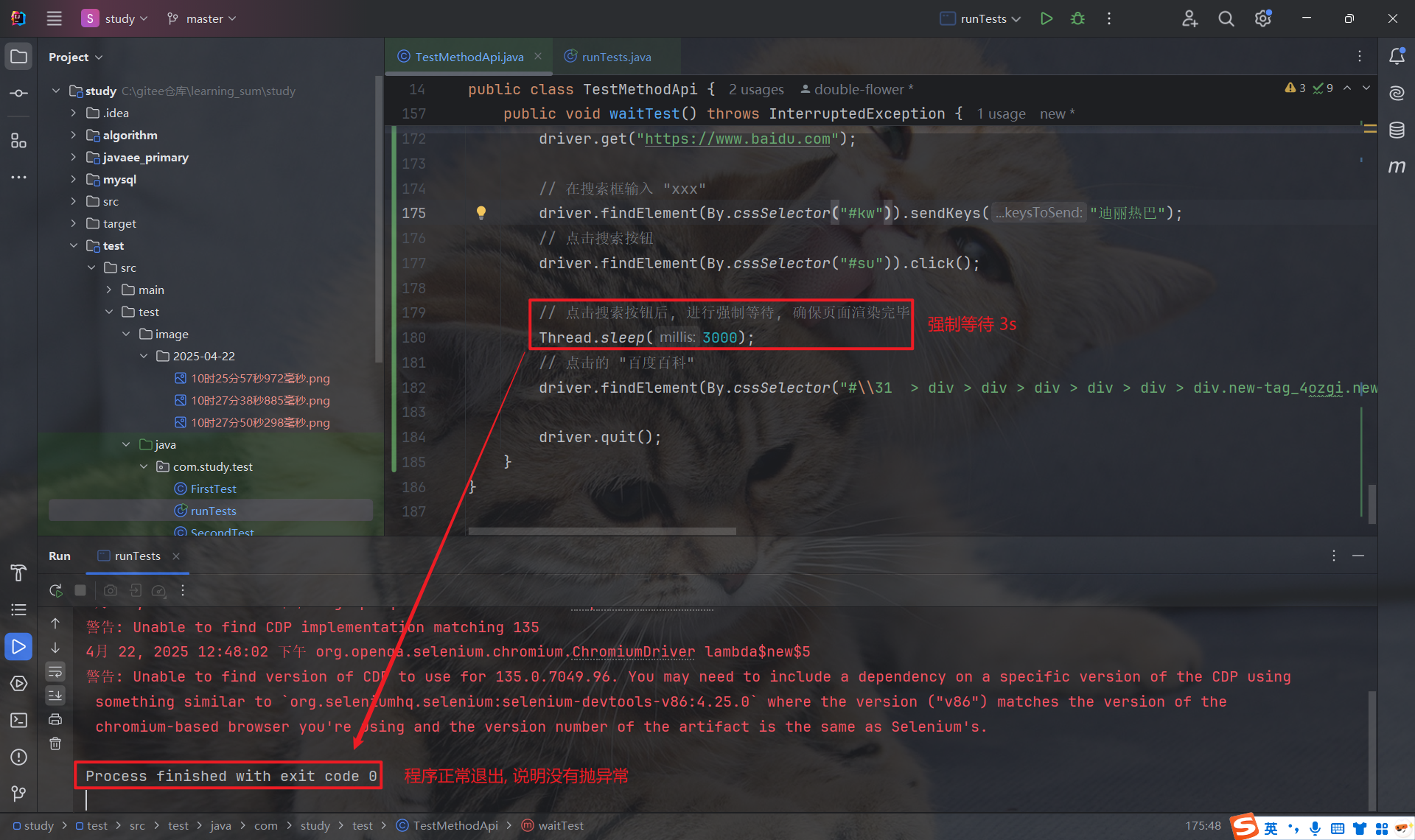
5.3 强制等待
我们之前用到的 Thread.sleep(毫秒), 就是强制等待.
强制等待, 就是执行到 Thread.sleep 时, 不论什么情况, 都会进行阻塞等待.
- 优点: 使用简单, 调试的时候比较有效
- 缺点: 影响运行效率, 浪费大量的时间
5.4 智能等待
5.4.1 隐式等待
使用 driver.mange().timeouts().implicitlyWait(Duration.xxx) 链式调用进行隐式等待.
注意: 隐式等待只能等待页面上的元素, 不能等待非页面上的元素

Duration 的使用有以下几种, 表示要等待的时间单位:
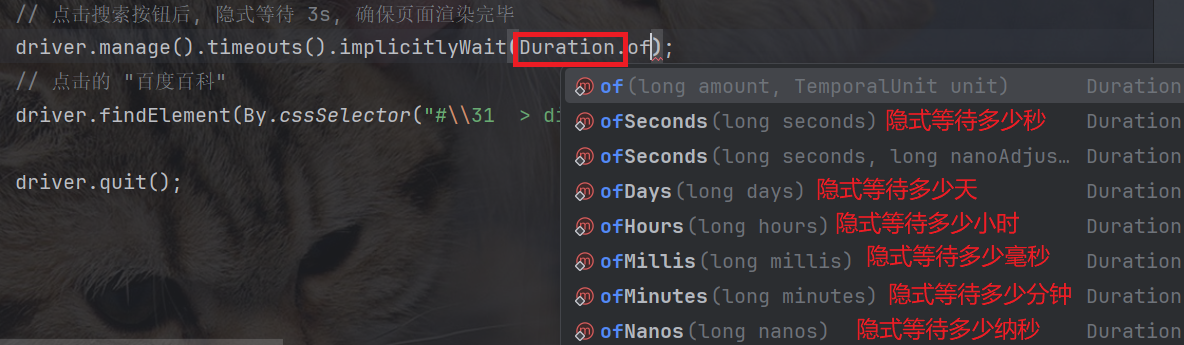
隐式等待, 会在 Duration 规定的时间内不断查找元素, 若在规定时间内查找到元素, 就会继续往下执行:
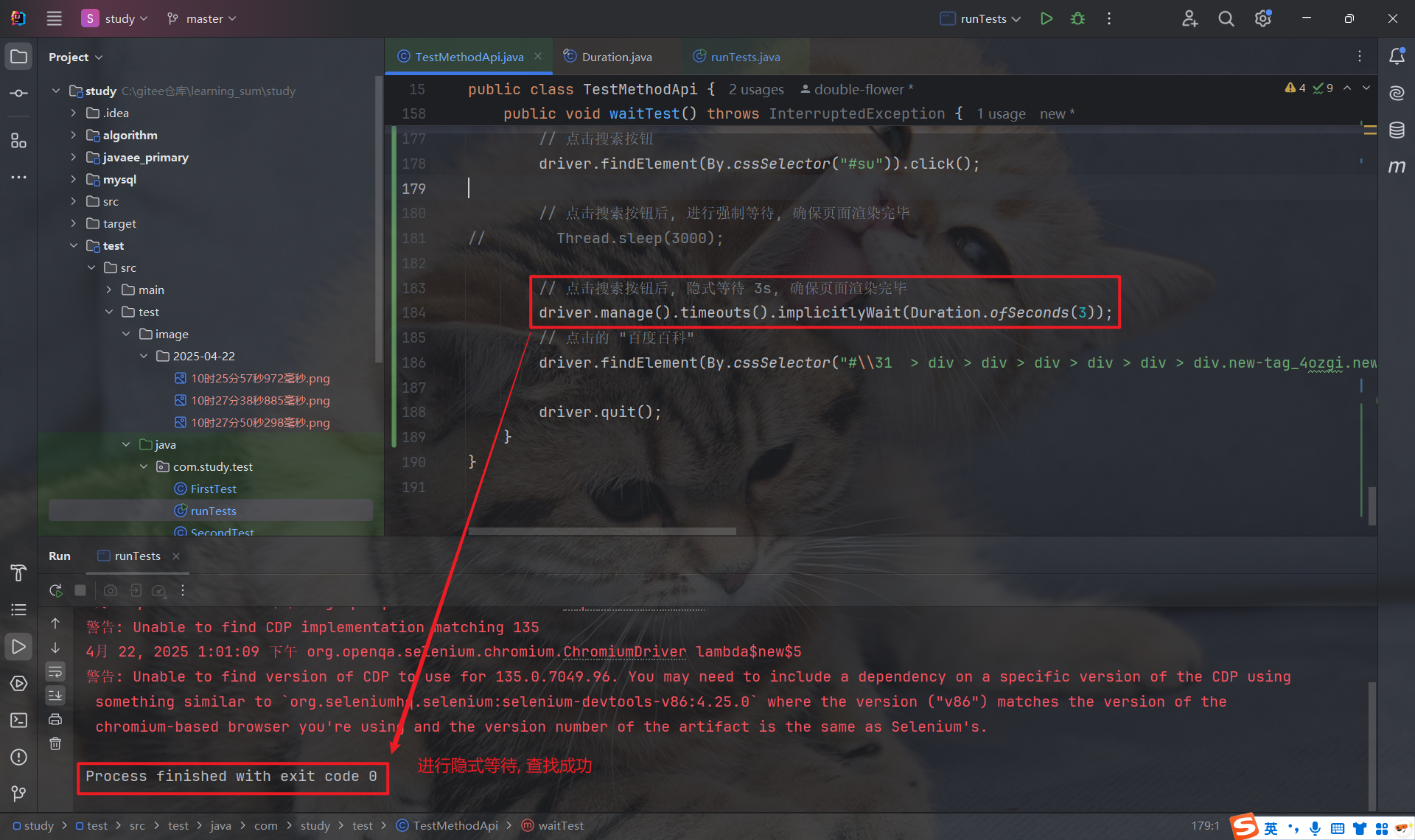
若超过规定时间还没有查找到元素, 就会抛出异常:
注意:
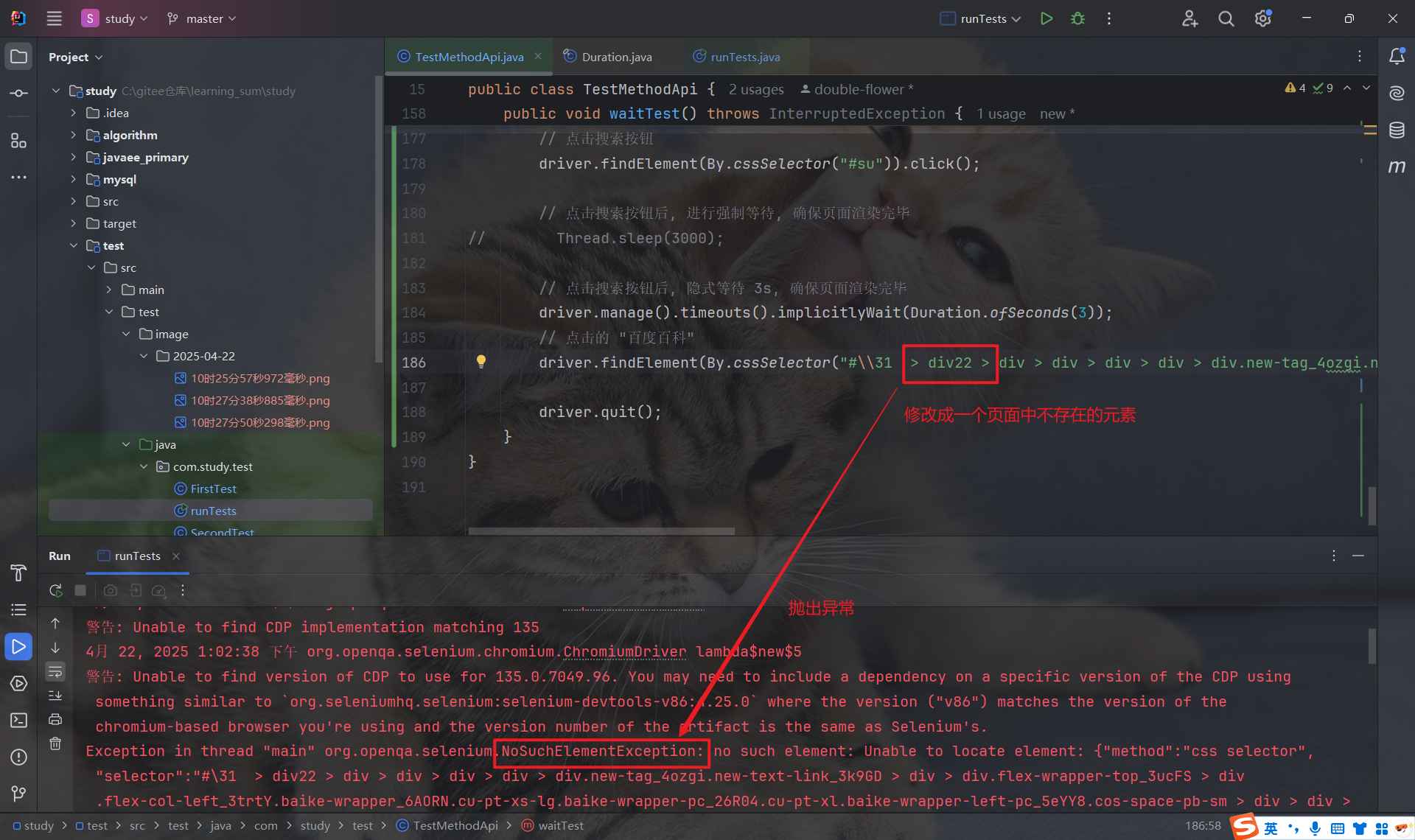
隐式等待是一个全局操作, 对后续的每次查找都起作用 , 也就是说, 每执行一次 findElement 来获取元素, 就会进行隐式等待, 等待元素加载好后才会继续往下执行.
注意: 隐式等待不是等待页面上所有元素加载完毕后再往下执行, 而是每次查找元素时, 对特定的元素的进行等待
因此, 我们只需设置一次隐式等待即可, 因为它是一个全局生效的配置, 对后续所有查找操作都有效.
5.4.2 显式等待
显示等待, 可以认为是隐式等待的升级版.
上文说到, 隐式等待是全局等待, 每进行一次元素查找操作都会进行等待, 而显示等待, 不仅可以指定页面上的元素进行等待, 也可以等待非页面元素, 比如: 前进, 后退, 弹窗....
显式等待不像隐式等待那样是全局性的, 而是 专门针对某个特定的条件 进行等待. 我们在代码中明确指定一个 最长等待时间 和一个 要等待的特定条件.
这个特定条件, 通过 ExpectedConditions 类来定义的, 比如元素变得可见、元素可点击、页面标题包含某个文本等等.
-
如果在规定的时间内, 这个 特定条件达成了(例如, 目标元素变得可点击了), 显式等待就会立即结束, 继续执行后续代码.
-
如果直到最长等待时间结束, 指定的 条件仍然没有达成, 显式等待就会 抛出 TimeoutException 异常。
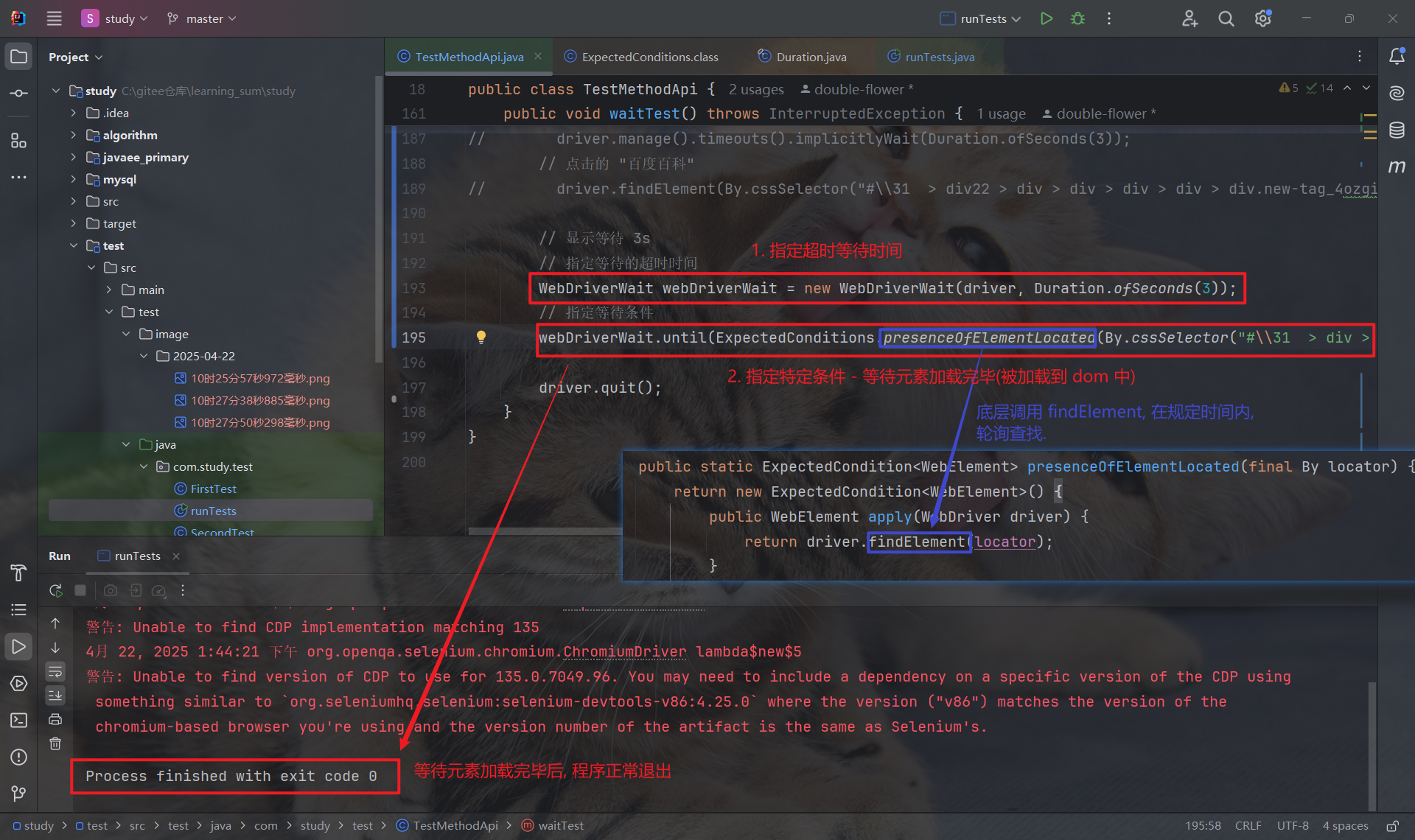
显示等待的链式调用为: new WebDriverWait(driver, Duration.ofSeconds(3)).until($express)
其中, 使用 ExpectedConditions 中的方法来定义特定条件, 常见的四个方法如下:
- elementToBeClickable(By locator): 等待元素不仅可以看见, 也能点击.
- presenceOfElementLocated(By locator): 等待元素被加载到了 dom 中.(只需元素加载到 dom 即可, 不必等页面渲染完毕)
- textToBe(By locator, String str): 检查元素的内容是否为指定内容.
- urlToBe(String url): 检查当前页面地址是否为指定 URL
- alertIsPresent(): 等待页面上出现弹窗
DOM 加载完毕 (DOM Ready):
浏览器把网页的 HTML 代码 读完一遍,并且把这个网页的 基本骨架或者目录结构 给搭好了.
在这个阶段,网页上的所有元素节点(<div>, <p>, <img>, <button> 等标签)都已经在内存里生成了对应的“对象”,形成了一棵树状结构(就是 DOM 树).
但这时候,可能网页里引用的大图片、视频、大的 CSS 文件、非关键的 JavaScript 文件等 外部资源 还没完全下载和处理完.
HTML 代码:
<html> <body> <h1>欢迎</h1> <p id="intro">这是一个段落。</p> <button>点击我</button> </body> </html>HTML 代码生成的 dom 树:
Document (整个页面) └── html ├── head (可能还有其他东西,这里简化了) └── body ├── h1 (文本: 欢迎) ├── p (ID: intro, 文本: 这是一个段落。) └── button (文本: 点击我)
页面完全渲染完成 (Page Load Complete):
这不仅仅是骨架搭好了, 而是指 所有 页面需要的资源(包括 HTML 解析完成、DOM 树构建完成、所有 CSS 文件下载并应用、所有图片加载完成、所有同步和异步的 JavaScript 代码执行完毕等)都 全部处理完成 了.
这时候,浏览器不仅仅搭好了骨架,还把所有的“装饰品”(样式、图片、脚本带来的动态内容)都放好了,页面呈现出最终的样子,用户可以看到并进行完整的交互.
若在超时时间内, 满足了特定条件, 程序就会往下继续执行:
若超出超时时间, 还未满足特定条件, 那么抛出异常:
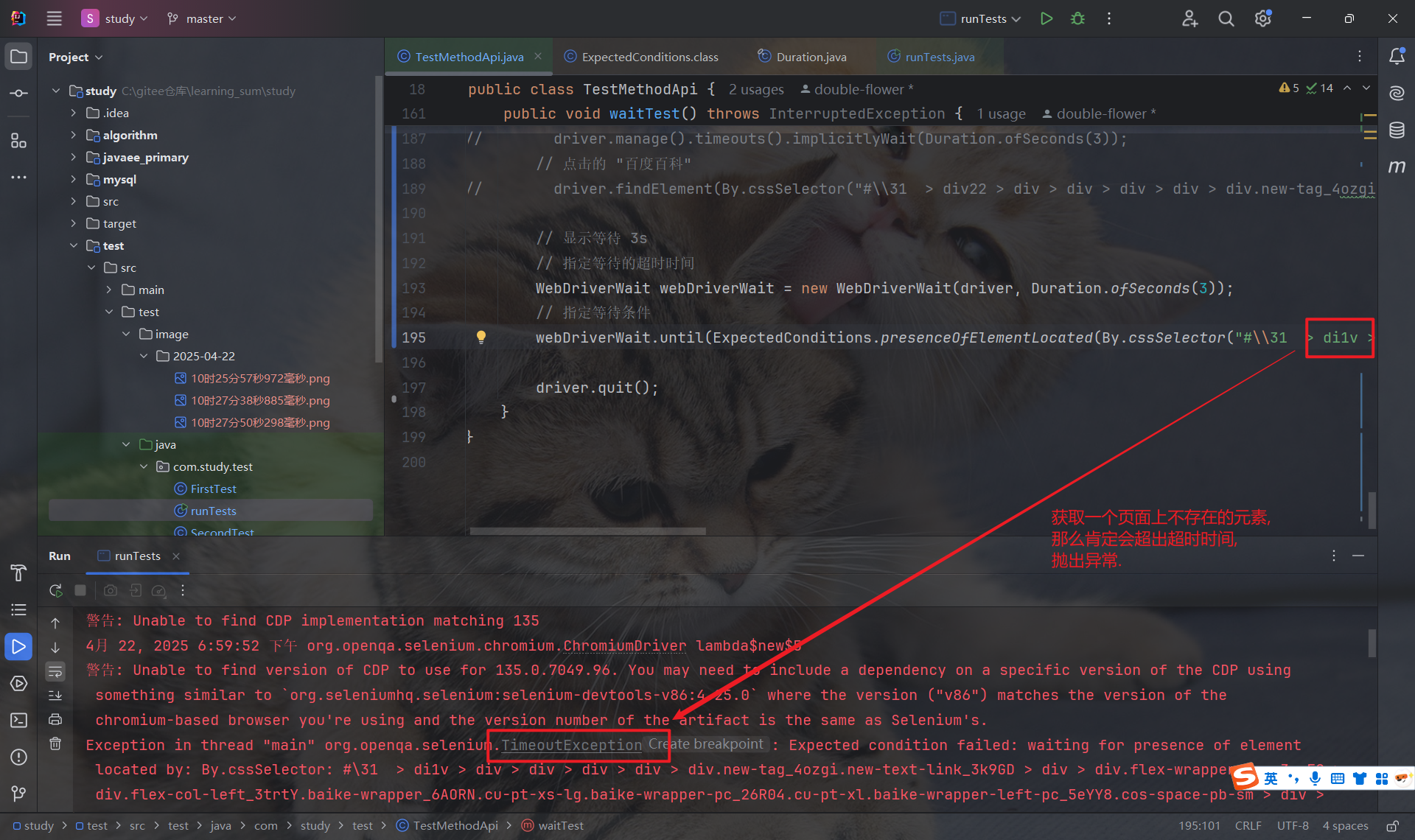
5.4.3 注意事项
注意: 隐式等待和显示等待可以配合使用, 但不要混合使用!!
配合使用, 是指使用 隐式等待 作用于页面元素, 使用 显示等待 作用于非页面元素.
混合使用, 是指 隐式等待 和 显示等待 都作用于页面元素.
如下图示例, 隐式和显示共同等待一个不存在的元素, 隐式等待 5s, 显示等待 10s, 理论上总等待时长应为 15s, 但最终结果为 11s.
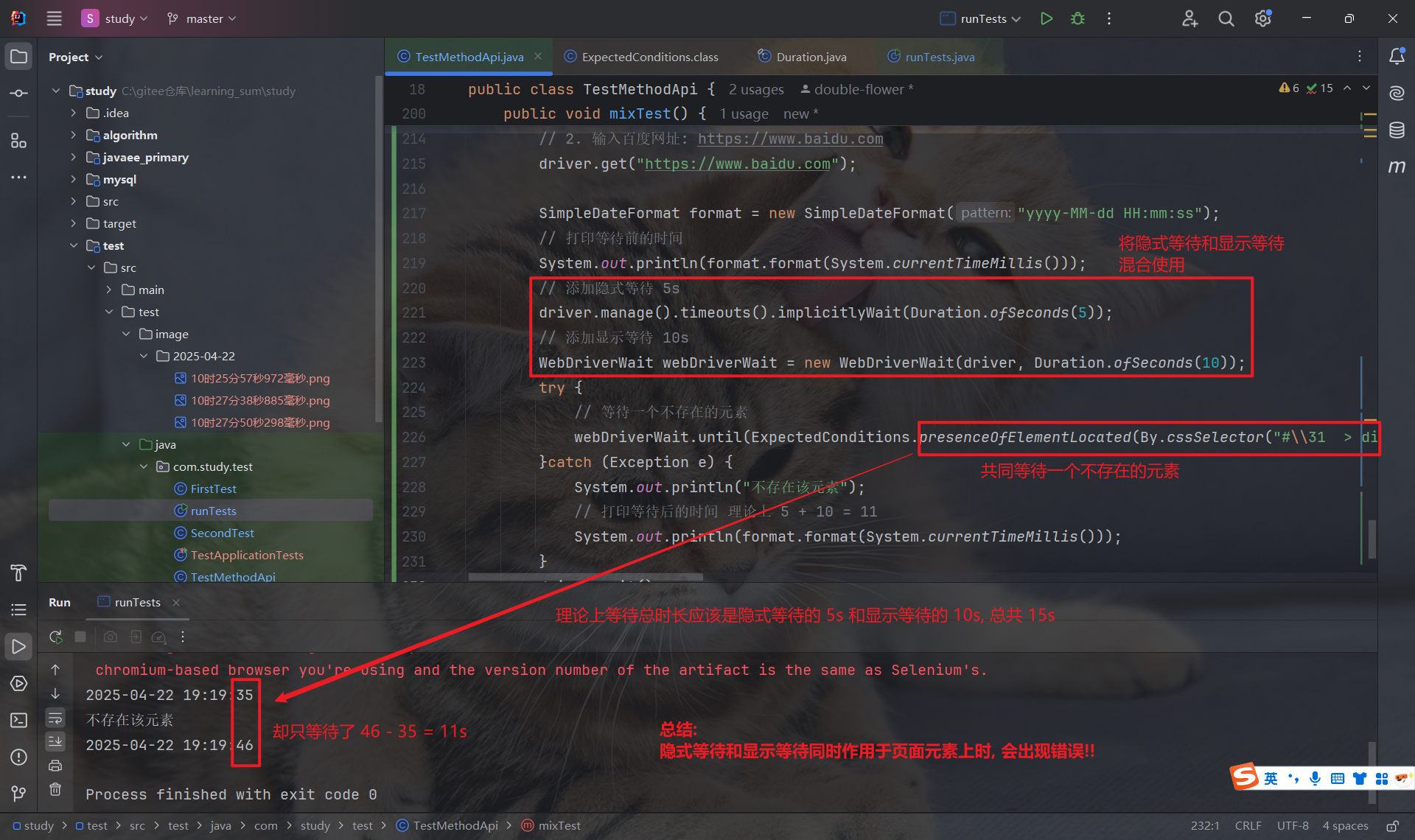
结论: 当隐式等待和显示等待混合使用时, 存在不确定和意外的行为, 会导致不可预测的等待时间.
6. 浏览器导航栏
在上文中, 我们都是对页面上的元素进行操作, 接下来学习如何操作浏览器导航栏.
Java 通过 driver.navigate() 来操作浏览器导航栏.
6.1 打开网址
打开网址有两种方式:
// 在浏览器地址栏, 输入网址 [复杂版]
driver.navigate().to("https://www.baidu.com");
// 在浏览器地址栏, 输入网址 [简化版]
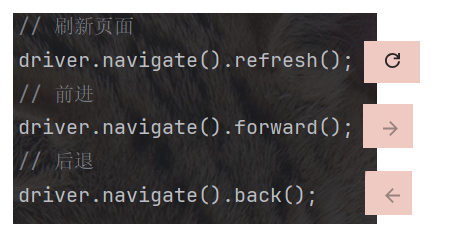
driver.get("https://www.baidu.com");6.2 刷新, 前进, 后退
// 刷新页面
driver.navigate().refresh();
// 前进
driver.navigate().forward();
// 后退
driver.navigate().back();7. 弹窗
弹窗分为以下几种:
- 警告弹窗

- 确认弹窗

- 提示弹窗
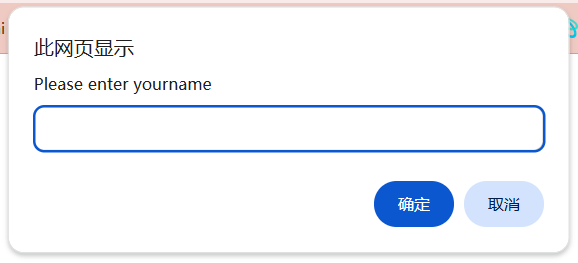
如上图所示, 对弹窗的操作主要有: 确认, 取消, 输入文本信息, 获取文本信息.
7.1 操作弹窗 - Alert
但是, 弹窗不属于页面上的元素, 当我们使用开发者工具时, 是捕捉不到弹窗的.
因此, 我们需要使用 Selenium 提供的 Alert 接口来操作弹窗.
当浏览器调起弹窗后, 使用 driver 获取 Alert 对象:
// 调起弹窗
driver.findElement(By.cssSelector("#tooltip")).click();
// 获取 Alert 对象
Alert alert = driver.switchTo().alert();注意: 必须等弹窗(Alert/Confirm/Prompt)实际出现在浏览器上之后, 才能成功使用 driver.switchTo().alert() 方法来获取它(否则会抛出 "找不到弹窗" 异常).
Alert 中, 提供了以下几种方法来操作弹窗:
- accept(): 点 "确定"
- dismiss(): 点 "取消" 或 "关闭"
- getText(): 获取弹窗里的文字
- sendKeys(String text): 在 Prompt 弹窗的输入框中里输入文字

7.2 警告(Alert)弹窗
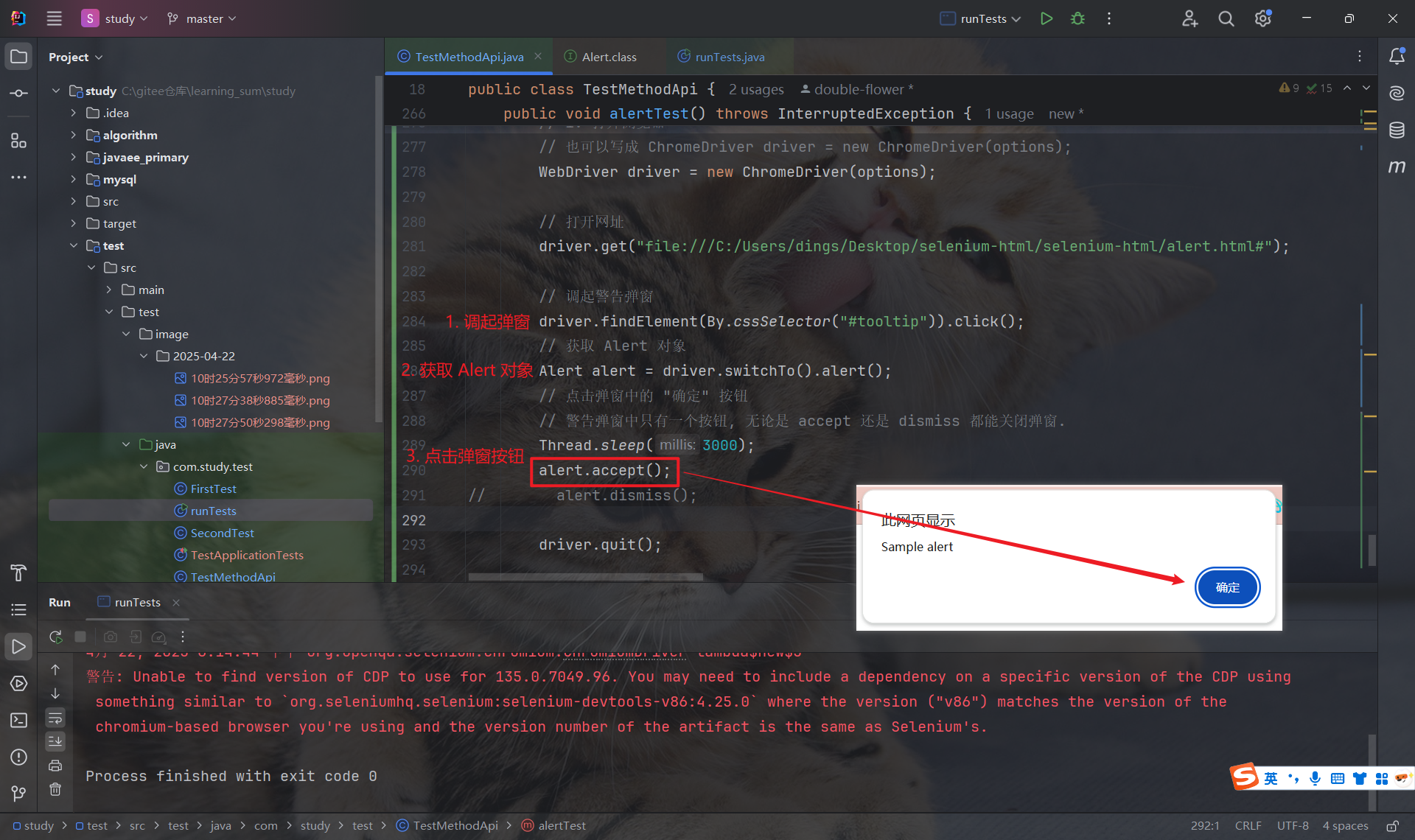
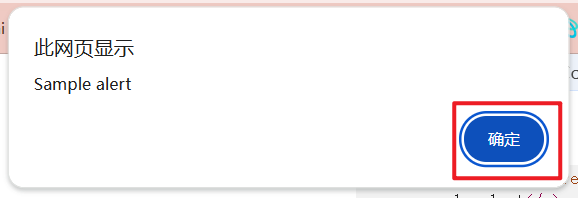
由于警告弹窗只提供了一个按钮, 因此, 无论是 Alert.accept 还是 Alert.dismiss 都能达到关闭弹窗的效果.(在警告弹窗中, 这两个方法的作用是相同的)
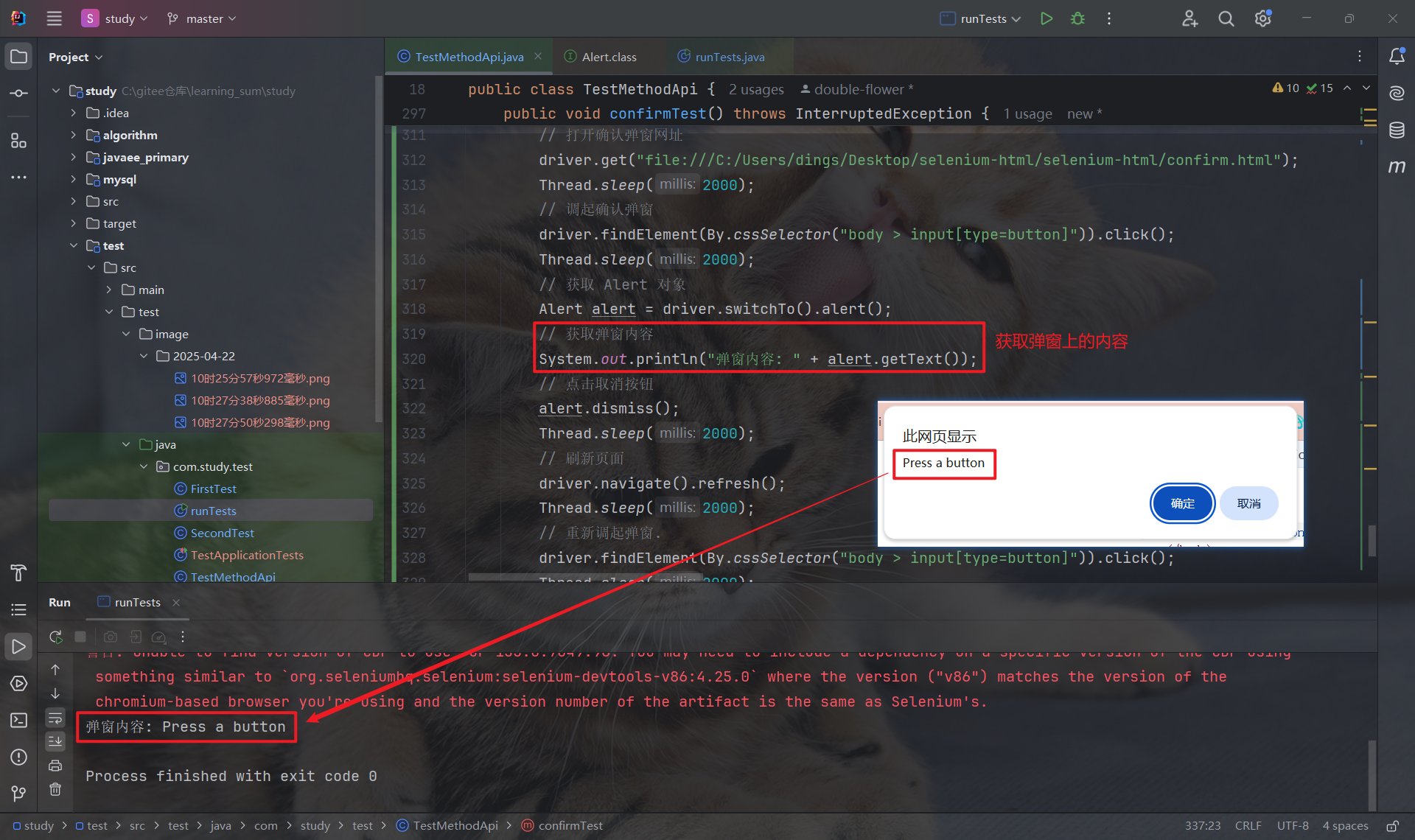
7.3 确认弹窗
确认弹窗中有 "确认" 和 "取消" 两个按钮, 因此需要区分使用 Alert.accept 和 Alert.dismiss(此时不可混用):

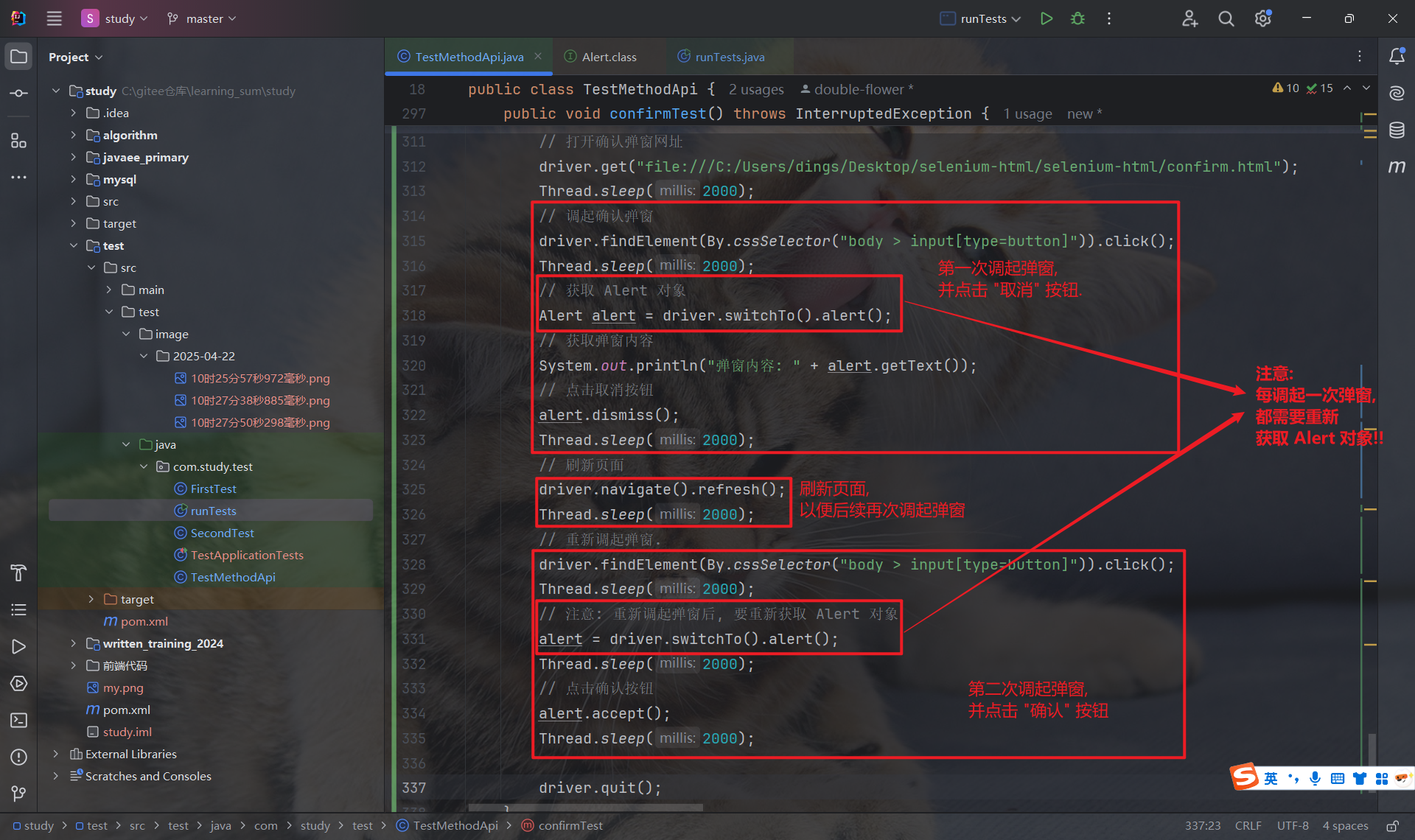
获取弹窗内容:
注意:
每弹出一个新的弹窗, 即使是同一个按钮触发的相同内容的弹窗, 都必须重新获取新的 Alert 对象!!
原因如下:
- driver.switchTo().alert() 方法的作用是 立即切换到当前浏览器中处于激活状态的那个弹窗, 并返回代表 那个特定弹窗实例 的 Alert 对象
- 一旦你对一个弹窗执行了 accept() 或 dismiss() 操作, 这个弹窗就会被 关闭
- 此时, 你之前获取的那个 Alert 对象就 失效了, 它不再代表一个当前存在的弹窗
- 如果你再次触发弹窗(比如再次点击同一个按钮), 浏览器会生成一个 全新的弹窗实例
你需要再次调用 driver.switchTo().alert(), 才能切换到这个 新的弹窗实例 并获取它的 Alert 对象.
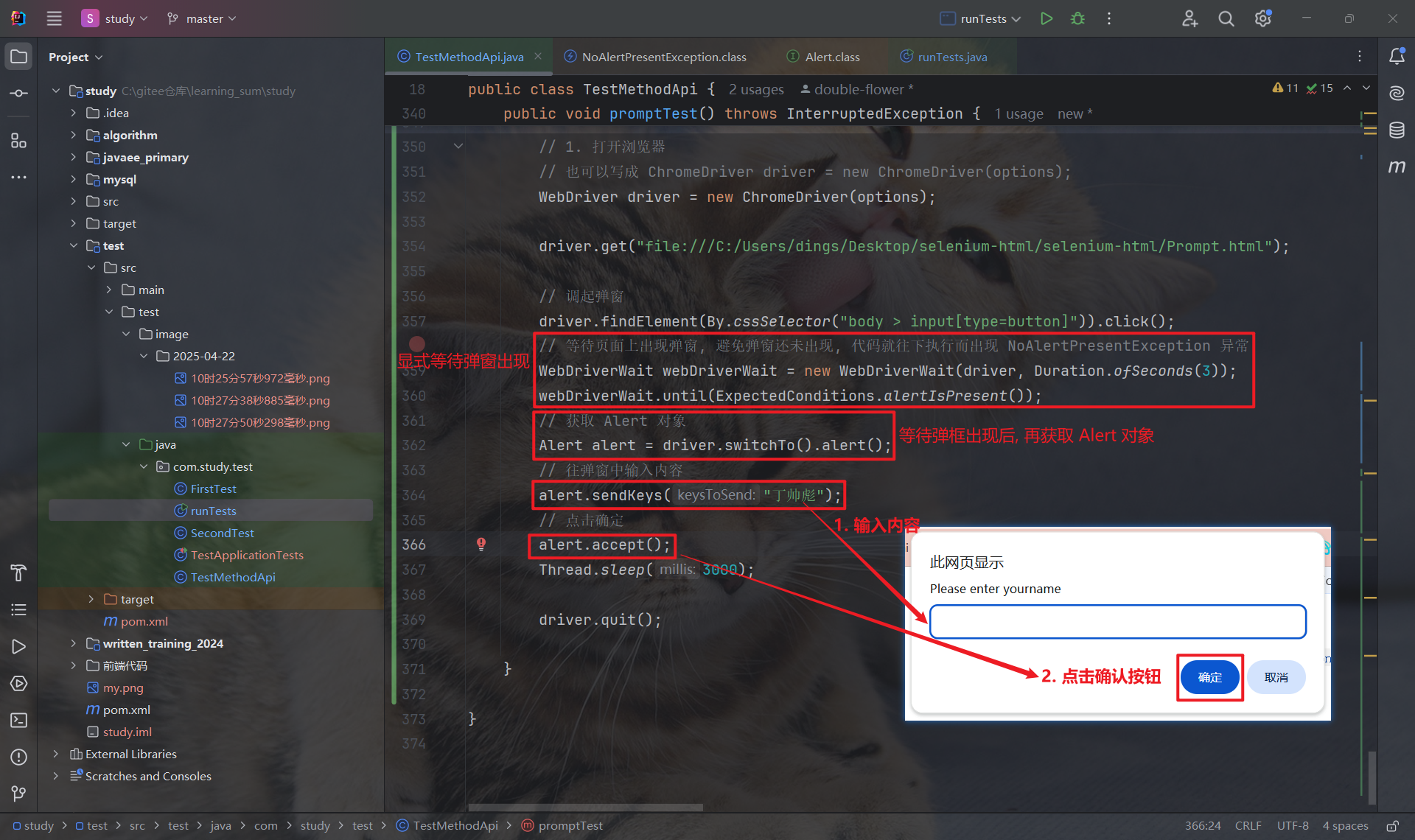
7.4 提示弹窗
在提示弹窗中, 我们可以使用 sendKeys 方法向弹窗的输入框中输入信息.
为了避免 NoAlertPresentException 异常, 我们可以采用显式等待的方式, 等待弹窗出现后, 再获取 Alert 对象.(上面两种弹窗也都可以)
7.5 注意事项
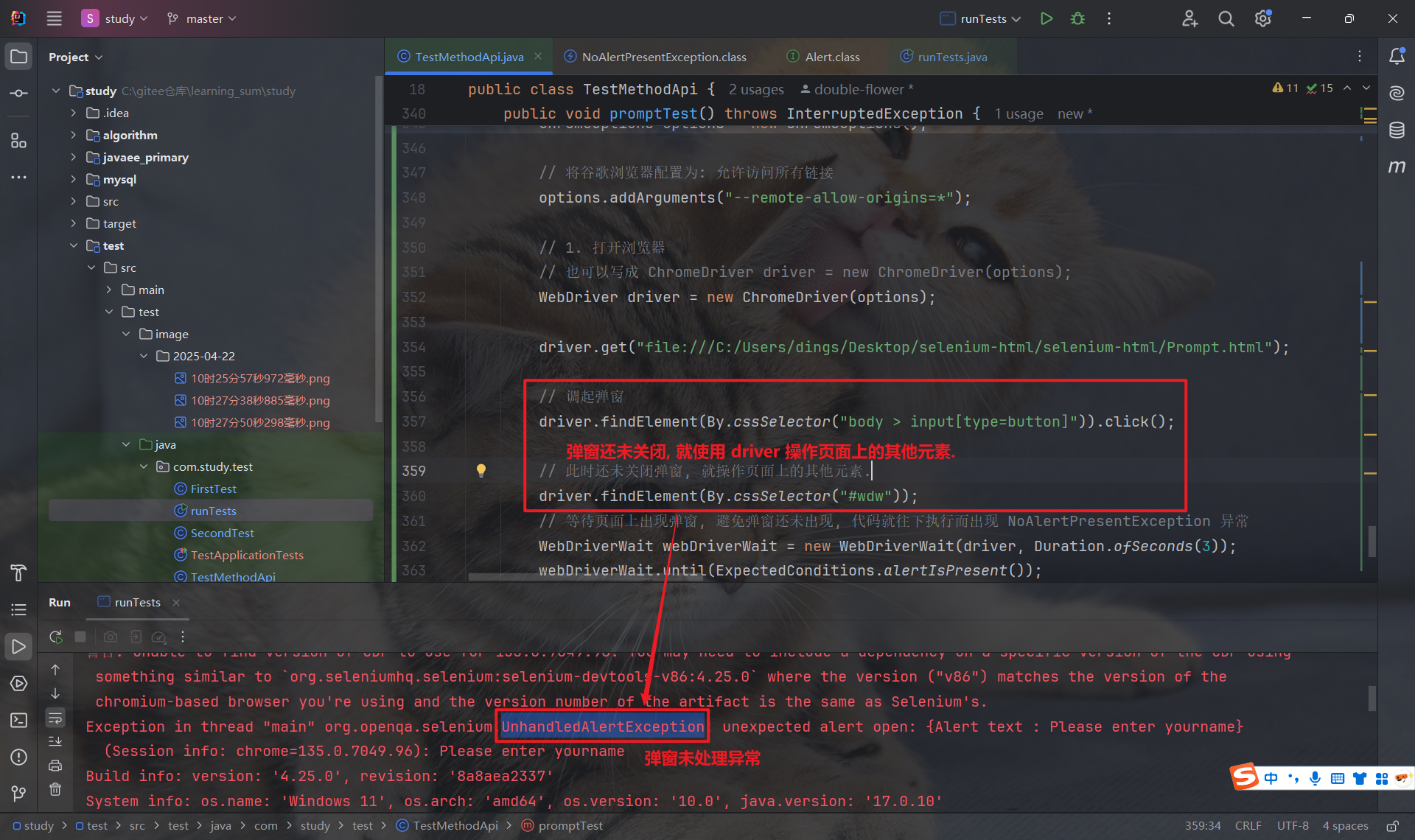
弹窗属于页面上的一个异常信息, 如果页面上有弹窗弹出, 那么 WebDriver 对主页面的操作会被 阻塞. 因此, 我们必须使用 accept 或者 dismiss 将弹窗关闭后, 才能对页面上的其他元素进行操作.
如果弹窗未关闭就操作页面上的其他元素, 就会抛出 UnhandledAlertException 异常:
8. 文件上传
当我们点击选择文件按钮后, 会弹出文件系统窗口, 让我们对文件进行选择.
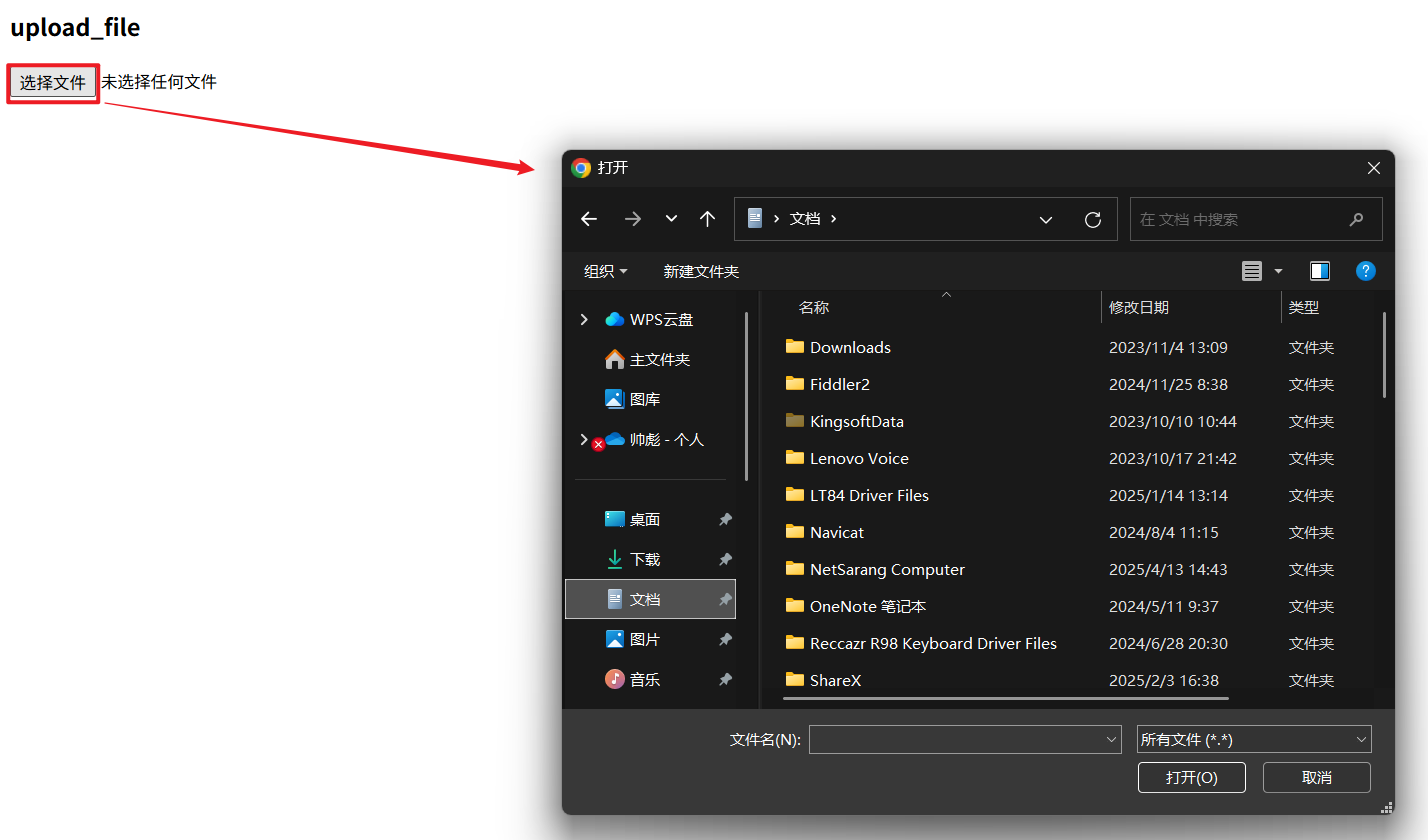
选择文件后, 页面上就会显示文件名称:

但是, 文件窗口不属于页面上的元素, 因此, 我们无法通过 Selenium 识别文件窗口.
因此, 我们可以使用 sendKeys 来上传指定路径的文件, 上传后, 文件名就会显示在页面上:
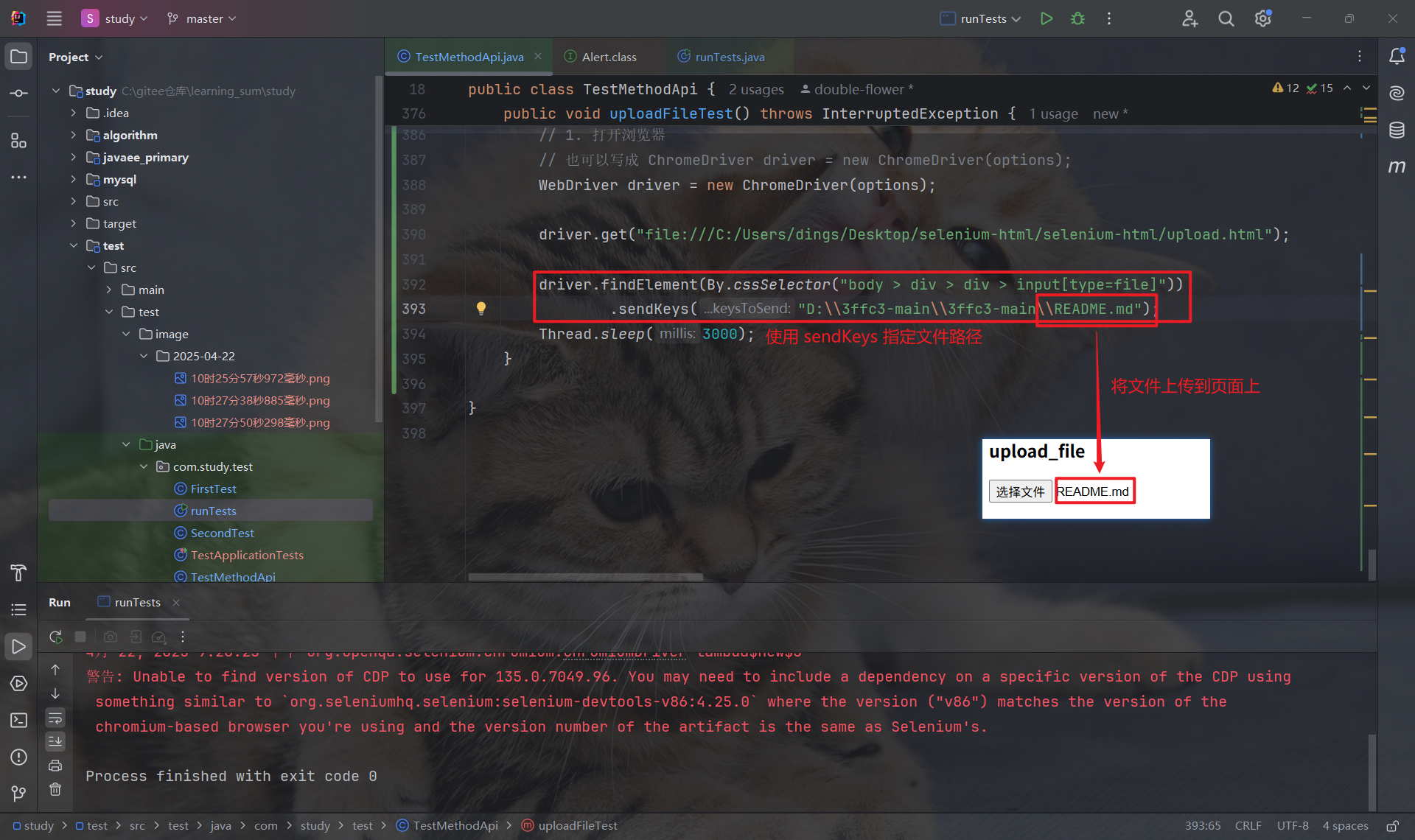
9. 浏览器参数设置
9.1 设置无头模式
无头模式, 就是在运行自动化脚本时, 不会打开实际的、你看得见的浏览器窗口. 所有的操作(比如打开网页、查找元素、点击、输入等)都在后台静默地进行.
浏览器默认情况下, 是有头模式, 即自动化执行的过程, 会展示在我们的屏幕上.
将浏览器设置为无头模式:
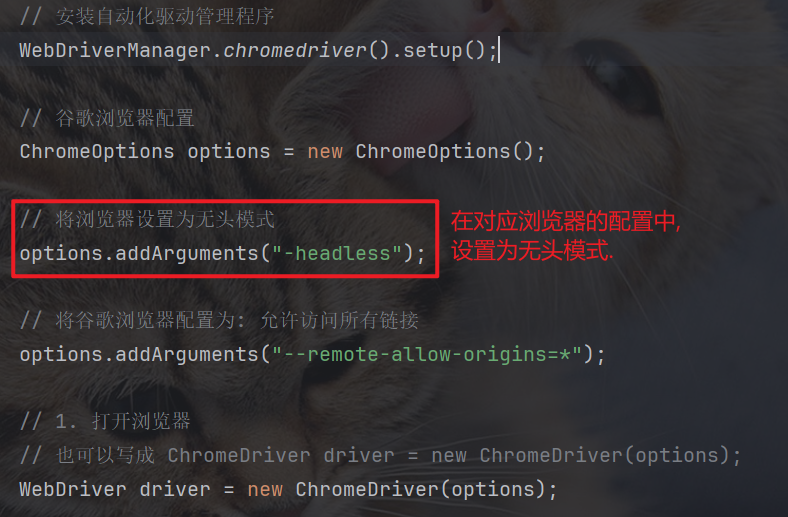
// 谷歌浏览器配置
ChromeOptions options = new ChromeOptions();
// 将浏览器设置为无头模式
options.addArguments("-headless");9.3 浏览器加载策略
9.3.1 什么是浏览器加载策略
加载策略是指, Selenium 在发出 driver.get(url) 命令后, 需要等待页面加载到哪一个状态才认为导航完成, 并让 driver.get() 方法返回(取消 WebDriver 的阻塞状态, 使得 driver 可往下执行).
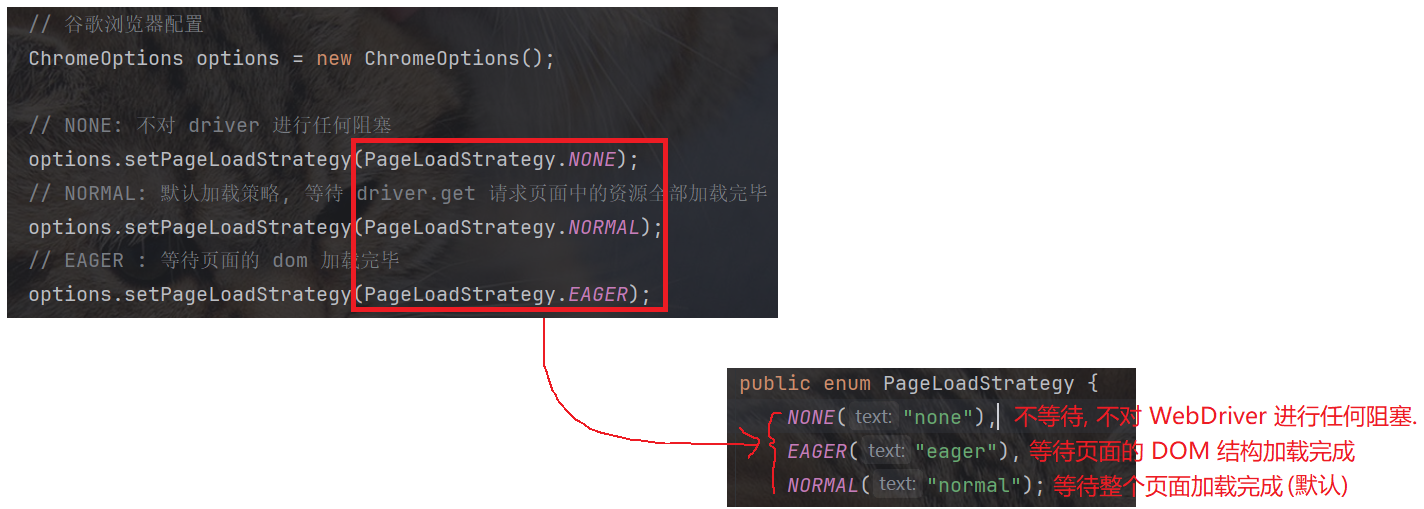
-
normal: 等待页面上所有资源全部加载完成, 再往下执行.
-
eager: 只要基本结构(dom) 加载完成, 即使其他资源(如: 图像)没有记载完毕, 也会继续往下执行.
-
none: 不会进行任何等待, 只要 driver.get 发送请求, 就会往下执行(不管请求是否成功, 不管页面是否加载完毕, 只要请求发送就继续往下执行).
请注意区分 显式/隐式 等待和 浏览器加载策略中 "等待" 的区别:
- 浏览器加载策略中的 "等待", 等待的是 driver.get(url) 方法中指定的那个 url 页面, 等待这个页面的加载状态是否符合我们设定的加载策略. 如果符合, 则释放 driver, 程序继续往下执行; 否则阻塞 driver, 直至网页的状态满足策略的要求为止.
- 隐式/显示 等待, 等待的是具体的某个元素的状态, 而非页面的加载状态.
核心区别:
pageLoadStrategy 关注的是整个页面的初期加载完成度(何时认为初始页面加载好了)
隐式/显式等待关注的是页面上的某个具体部分(通常是元素)是否准备好(是否可以进行下一步操作)
两者是互补的, 通常的流程是:
使用 driver.get(url) 加载页面, pageLoadStrategy 会等待页面加载到设定的状态
driver.get() 返回后, 表示初始页面加载策略的等待已结束.
然后你可能会使用隐式等待(全局设置, 自动应用于查找元素)或显式等待(针对特定操作设置)来确保你要交互的具体元素已经加载、可见或可点击.
注意:
- 浏览器加载策略(pageLoadStrategy)只对 driver.get(url) 这个方法中的 url 页面生效, 一旦 driver.get() 方法返回, pageLoadStrategy 对 driver 的直接控制作用就结束了.
- 如果在这个页面上后续发生了跳转(例如: 用户点击链接、提交表单...), Selenium 都不会对这个跳转后的页面执行 driver.get(url) 时设定的 pageLoadStrategy 加载策略, 因为这个加载策略, 只针对 driver.get(url) 中的那个 url 生效!!
9.3.2 设置浏览器加载策略
由于浏览器的默认加载策略为 normal, 这意味着必须等待页面中的所有资源全部加载完毕后, 才能释放 driver, 才能继续往下执行.
当我们请求的是一个资源非常多的页面时, driver.get 就需要等待很长的时间.
而在实际工作中, 我们存在这样一个请求: 当页面的主要框架(dom)加载完毕后, 就继续往下执行, 而不必等待所有资源加载完毕.
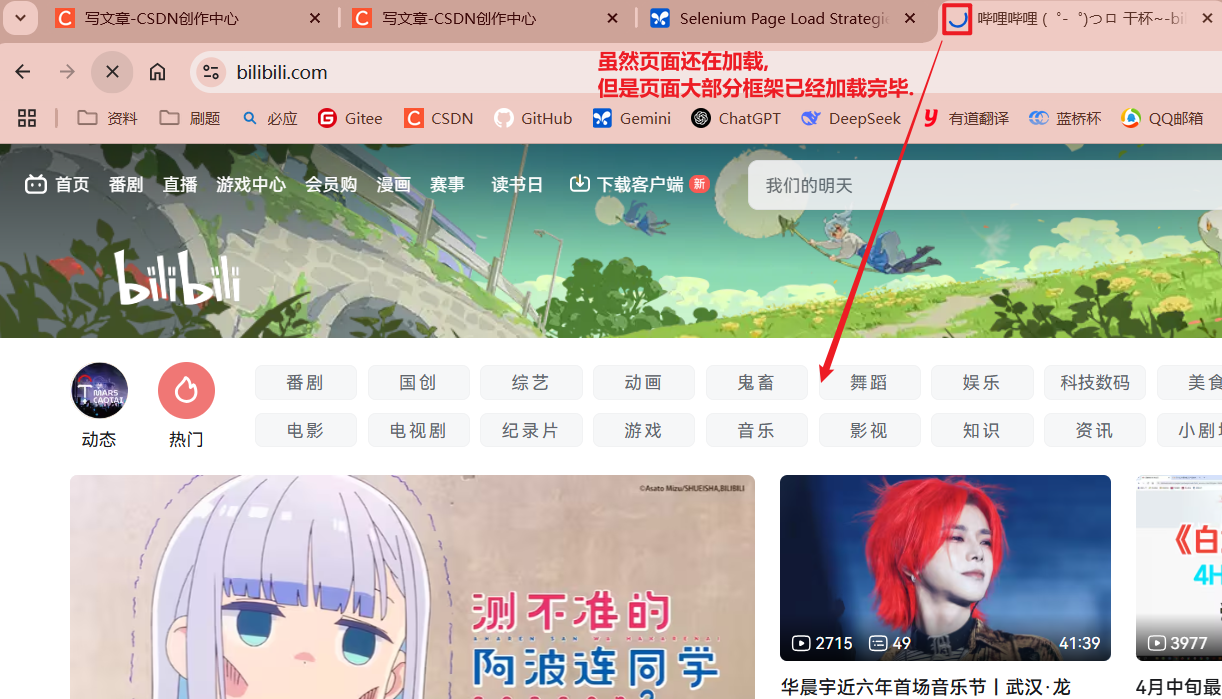
因此, 我们需要将浏览器的加载策略设置为 eager. 通过 options.setPageLoadStrategy 来设置加载策略:
// 安装自动化驱动管理程序
WebDriverManager.chromedriver().setup();
// 谷歌浏览器配置
ChromeOptions options = new ChromeOptions();
// NONE: 不对 driver 进行任何阻塞
options.setPageLoadStrategy(PageLoadStrategy.NONE);
// NORMAL: 默认加载策略, 等待 driver.get 请求页面中的资源全部加载完毕
options.setPageLoadStrategy(PageLoadStrategy.NORMAL);
// EAGER : 等待页面的 dom 加载完毕
options.setPageLoadStrategy(PageLoadStrategy.EAGER);
// 将谷歌浏览器配置为: 允许访问所有链接
options.addArguments("--remote-allow-origins=*");
// 1. 打开浏览器
WebDriver driver = new ChromeDriver(options);END


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









