






Spark是一种基于内存的快速、通用、可拓展的大数据分析计算引擎。
- 起源阶段
- Spark 最初是在 2009 年由加州大学伯克利分校的 AMP 实验室开发。当时,Hadoop 在大数据处理领域占据主导地位,但 MapReduce 在某些复杂计算场景下,如迭代计算和交互式数据挖掘,效率较低。Spark 的设计目标就是为了解决这些问题,提供一个更高效、灵活的大数据处理框架。
- 早期版本发布
- 2010 年,Spark 发布了第一个版本。这个阶段,Spark 主要聚焦于内存计算的优化。与 Hadoop 的 MapReduce 相比,Spark 的核心创新在于其弹性分布式数据集(RDD - Resilient Distributed Dataset)的概念。RDD 允许数据在内存中进行缓存和重用,大大提高了数据处理的速度,尤其是在迭代计算任务中,例如机器学习中的梯度下降算法等。
- 生态系统扩展阶段
- 从 2013 年开始,Spark 不断扩展其生态系统。Spark SQL 发布,它为处理结构化数据提供了类似于 SQL 的接口,使得熟悉 SQL 的用户可以方便地使用 Spark 进行数据分析。Spark SQL 能够将 SQL 查询转换为 Spark 的执行计划,并且可以与多种数据源进行交互,如 Hive 表、JSON 文件等。
- 同时,Spark Streaming 也应运而生,它支持对实时数据流进行处理。Spark Streaming 将实时数据切分成小的时间批次,然后利用 Spark 的计算引擎进行处理,能够在保证低延迟的情况下处理大量的实时数据,例如实时日志分析、实时监控数据处理等场景。
- 机器学习和图计算集成阶段
- 2014 - 2015 年,Spark MLlib(机器学习库)和 GraphX(图计算库)得到了进一步发展。MLlib 提供了大量的机器学习算法,包括分类、回归、聚类等算法,方便数据科学家在大数据集上进行模型训练和预测。GraphX 则提供了图数据结构和图计算算法,用于处理社交网络、知识图谱等图数据相关的应用场景。
- 成熟与广泛应用阶段
- 随着时间的推移,Spark 逐渐成熟并被广泛应用于各个行业。许多企业将 Spark 用于数据仓库构建、数据挖掘、用户行为分析等众多大数据应用场景。它能够与各种大数据存储系统集成,如 Hadoop 分布式文件系统(HDFS)、亚马逊 S3 等,并且可以在不同的集群管理系统上运行,如 YARN 和 Mesos 等。其社区也在不断壮大,有大量的开发者为其贡献代码、优化性能和修复漏洞。
Spark 诞生主要是为了解决 Hadoop MapReduce 在迭代计算以及交互式数据处理时面临的性能瓶颈问题。
在 Hadoop MapReduce 时代,数据处理主要基于磁盘,每次计算都需要频繁读写磁盘,这在面对需要多次迭代的算法,如机器学习中的梯度下降算法时,效率极其低下,导致大规模数据的迭代分析可能耗费数小时之久。而 Spark 创新性地采用基于内存计算的模式,使得数据在内存中能够被快速访问与处理,极大地缩短了计算时间,让大规模数据的迭代分析能够在秒级或分钟级完成,从而大幅提升了数据处理的效率,满足了诸如实时性要求较高的交互式数据处理等场景需求。 例如,在进行实时数据分析以支持即时决策的业务场景中,Spark 能够快速给出结果,而 Hadoop MapReduce 则因性能问题难以胜任。
(二)spark框架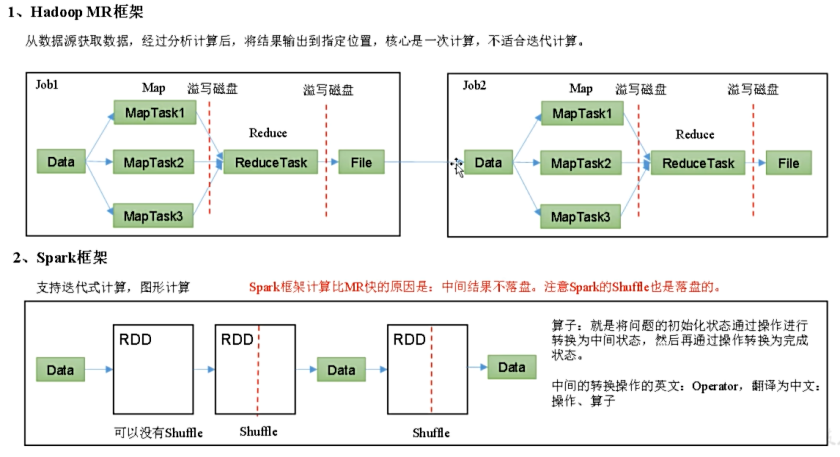
(二)Spark内置模块
spark Core:实现了Spark的基本功能,包含任务调度,内存管理,错误恢复,存储系统交互等模块。
spark SQL: 是Spark用来操作结构化数据的程序包。通过Spark SQL,我们可以使用SQL或者Apache Hive 版本的HQL来查询数据。
实时计算:spark是基于MR的,而MR是离线的。(实时的延迟是以ms为单位的)。
机器学习和图计算:需要有比较强的数学功底。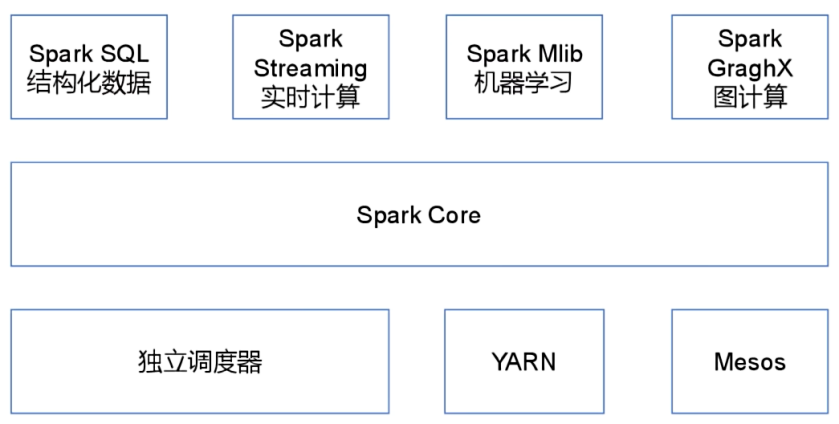
(三)Spark的特点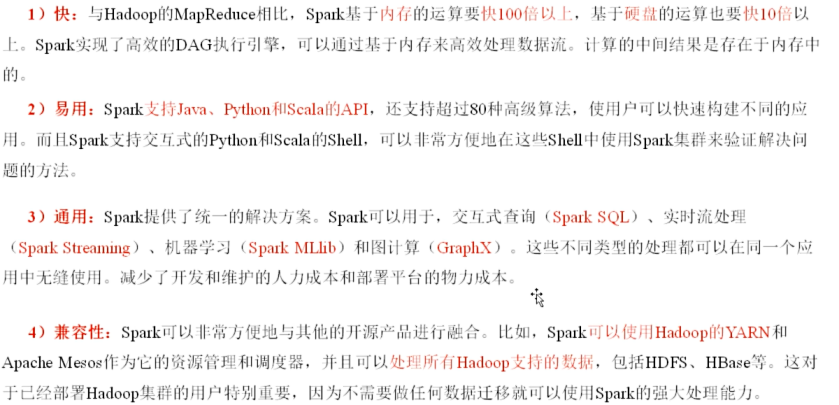
(四) Spark的运行模式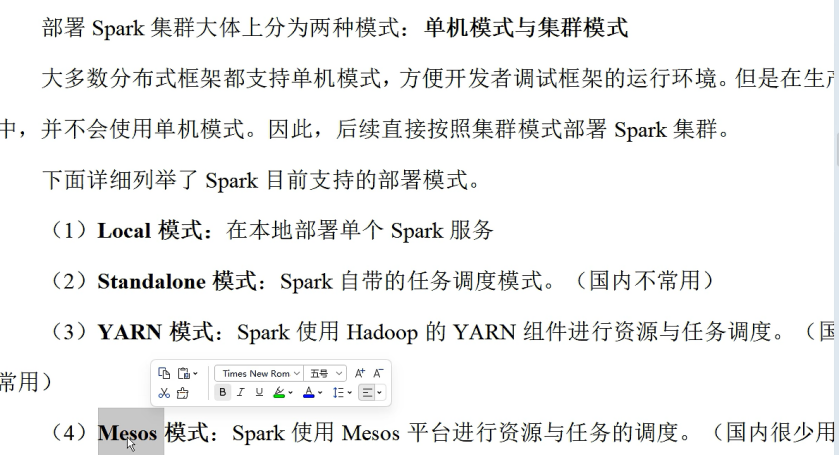
部署:将软件安装到什么位置,就称之为部署。
把spark计算逻辑在谁提供的资源中执行。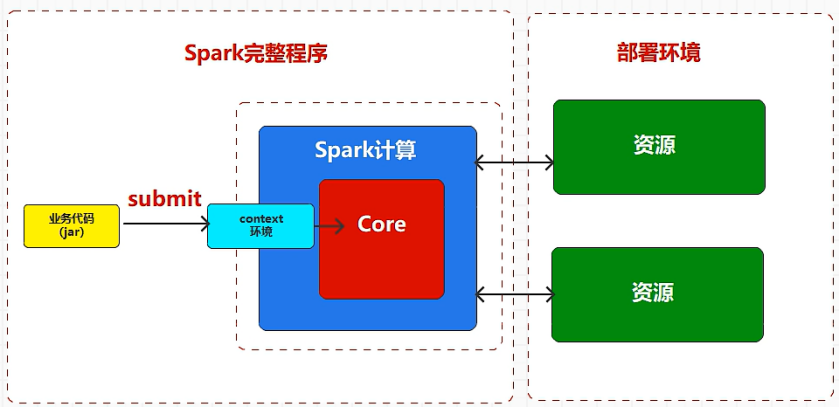
如果资源是当前单节点提供的,那么称之为单机模式。
如果资源是当前多节点提供的,那么称之为分布式模式。
hadoop: MR计算和资源管理耦合在一起的。
hadoop:2.x => Yarn版本(也叫资源调度),将资源和计算进行解耦合。
Yarn(管理资源)+MR(计算),(Spark,Flink)。
Spark 自己也有资源调度 + 计算。
如果资源是Spark提供的,那么就称之为Spark部署环境:Standzone
在工资生产环境中,主要采用Yarn+Spark的方式,也称之为Spark on Yarn。
HelloWorld.spark

















 9089
9089

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









