







 本文详细介绍了在复杂业务场景下,如何利用开源数据采集工具Filebeat进行高效、稳定的监控,包括工具对比、工作原理、数据保障机制以及性能特性的讲解。同时提到了如何从零开始搭建大规模的分布式智能运维(AIOps)系统,特别强调了Linux系统管理和数据监控的重要性。
本文详细介绍了在复杂业务场景下,如何利用开源数据采集工具Filebeat进行高效、稳定的监控,包括工具对比、工作原理、数据保障机制以及性能特性的讲解。同时提到了如何从零开始搭建大规模的分布式智能运维(AIOps)系统,特别强调了Linux系统管理和数据监控的重要性。
2.4 复杂业务模型下的政障定位


第三章、开源数据采集技术
对业务指标的监控本质上是对数据的监控,所以说智能运维是建立在数据基础之上的。
3.1 数据采集工具对比
数据是监控报警的基石,我们在实现海量数据的分析监控前 。

Logstash 虽然功能更加强大,但是占用系统资源较多,而 Filebeat 则更加轻量级,占用系统资源较少。
3 .2 轻量级采集工具Filebeat

3.2.1 Filebeat 工作原理

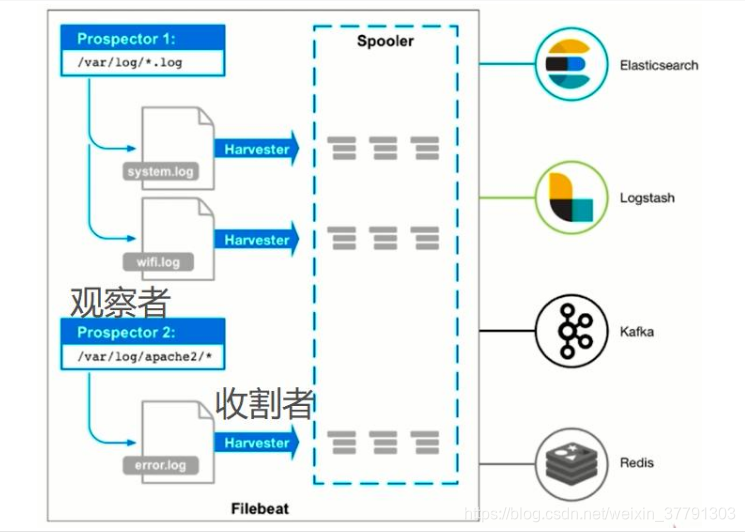
Prospector 负责管理 Harvester 并发现所有可读的数据。如果输入的文件类型是log 那么Prospector 在磁盘上找出所有匹配指定全局路径的所有文件, 为每个文件启动一个 Harvester。
filebeat.prospectors :
- type : log
paths :
- "/ var/log/origin- \*"
- "/ var/log/error.log"

2. Harvester

3. Filebeat如何保持文件状态
Filebeat 通过固定周期将文件状态存储在磁盘 Registry文件中来记录每个文件的状态。
该状态就是 Harvester 读取的文件内容 ,井确保所有内容都被发送 时记录的是最后一行的偏移量,如果 Output Elasticsearch 或者 Kafka 等变得不可用时, Filebeat 将跟踪最后一次发送的状态,直到 Output 恢复可用时才会继续读取文件。文件状态信息被每个 Pros ctor 保存在内容中, 出现异常导致 Filebeat 退出或者需 新启动 Filebeat时,文件状态信息将从 Registry件中读取到内存中, Harvest 就知道从哪里开始收集文件中的内容了。
Filebeat 每个文件都会通过一个唯一标识来识别其是否己经被 Harvester 收集过。
通过clean_removed和clean_inactive 这两个参数来控制 Registry文件的大小。
4. Filebeat如何确保数据不丢失

5.性能特性
- 稳定可靠
Filebeat 会记录每次读取日志的 offset 值,如果出现异常导致进程中断,那么恢复后,Filebeat 可以从中断前的位置继续读取,从而保证数据不会丢失。 - 自动流控
当 Filbeat Kafka 或者 lasticsearc 等接收端写入数据时,如果接收端处理数据缓慢, Filebeat 将自动减缓读取日志的速度,以免造成日志拥堵。当接收端恢复正常后, Filebeat 将继续读取日志并发送给 Kafka 或者 Elasticsearch 等接收端.
智能运维从0搭建大规模分布式AIOps系统

最全的Linux教程,Linux从入门到精通
======================
-
linux从入门到精通(第2版)
-
Linux系统移植
-
Linux驱动开发入门与实战
-
LINUX 系统移植 第2版
-
Linux开源网络全栈详解 从DPDK到OpenFlow

第一份《Linux从入门到精通》466页
====================
内容简介
====
本书是获得了很多读者好评的Linux经典畅销书**《Linux从入门到精通》的第2版**。本书第1版出版后曾经多次印刷,并被51CTO读书频道评为“最受读者喜爱的原创IT技术图书奖”。本书第﹖版以最新的Ubuntu 12.04为版本,循序渐进地向读者介绍了Linux 的基础应用、系统管理、网络应用、娱乐和办公、程序开发、服务器配置、系统安全等。本书附带1张光盘,内容为本书配套多媒体教学视频。另外,本书还为读者提供了大量的Linux学习资料和Ubuntu安装镜像文件,供读者免费下载。

本书适合广大Linux初中级用户、开源软件爱好者和大专院校的学生阅读,同时也非常适合准备从事Linux平台开发的各类人员。
需要《Linux入门到精通》、《linux系统移植》、《Linux驱动开发入门实战》、《Linux开源网络全栈》电子书籍及教程的工程师朋友们劳烦您转发+评论
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









