







def dx_relu(x):
“”“relu函数的导数”“”
temp = np.zeros_like(x)
if_bigger_equal_zero = (x >= temp)
return if_bigger_equal_zero * np.ones_like(x)
return np.where(x < 0, 0, 1)
---------------------------------------------
if name == ‘main’:
x = np.arange(-10, 10, 0.01)
fx = relu(x)
dx_fx = dx_relu(x)
plt.subplot(1, 2, 1)
ax = plt.gca() # 得到图像的Axes对象
ax.spines[‘right’].set_color(‘none’) # 将图像右边的轴设为透明
ax.spines[‘top’].set_color(‘none’) # 将图像上面的轴设为透明
ax.xaxis.set_ticks_position(‘bottom’) # 将x轴刻度设在下面的坐标轴上
ax.yaxis.set_ticks_position(‘left’) # 将y轴刻度设在左边的坐标轴上
ax.spines[‘bottom’].set_position((‘data’, 0)) # 将两个坐标轴的位置设在数据点原点
ax.spines[‘left’].set_position((‘data’, 0))
plt.title(‘Relu函数’)
plt.xlabel(‘x’)
plt.ylabel(‘fx’)
plt.plot(x, fx)
plt.subplot(1, 2, 2)
ax = plt.gca() # 得到图像的Axes对象
ax.spines[‘right’].set_color(‘none’) # 将图像右边的轴设为透明
ax.spines[‘top’].set_color(‘none’) # 将图像上面的轴设为透明
ax.xaxis.set_ticks_position(‘bottom’) # 将x轴刻度设在下面的坐标轴上
ax.yaxis.set_ticks_position(‘left’) # 将y轴刻度设在左边的坐标轴上
ax.spines[‘bottom’].set_position((‘data’, 0)) # 将两个坐标轴的位置设在数据点原点
ax.spines[‘left’].set_position((‘data’, 0))
plt.title(‘Relu函数的导数’)
plt.xlabel(‘x’)
plt.ylabel(‘dx_fx’)
plt.plot(x, dx_fx)
plt.show()
- Leaky ReLU函数(PReLU)
函数的定义为: f ( x ) = m a x ( a x , x ) f(x)=max(ax,x) f(x)=max(ax,x)。函数图像如下:

导数: f ′ ( x ) = { 1 i f x > 0 0.01 i f x < = 0 {f}'(x)=\left\{\begin{matrix} 1 & if x>0 & \\ 0.01& if x<=0 & \end{matrix}\right. f′(x)={10.01ifx>0ifx<=0函数图像如下:

特点:与 ReLu 相比 ,leak 给所有负值赋予一个非零斜率, leak是一个很小的常数 a i \large a_{i} ai,这样保留了一些负轴的值,使得负轴的信息不会全部丢失。
函数及导数代码:
from matplotlib import pyplot as plt
import numpy as np
解决中文显示问题
plt.rcParams[‘font.sans-serif’] = [‘SimHei’]
plt.rcParams[‘axes.unicode_minus’] = False
def leaky_relu(x):
“”“leaky relu函数”“”
return np.where(x<0,0.01*x,x)
def dx_leaky_relu(x):
“”“leaky relu函数的导数”“”
return np.where(x < 0, 0.01, 1)
---------------------------------------------
if name == ‘main’:
x = np.arange(-10, 10, 0.01)
fx = leaky_relu(x)
dx_fx = dx_leaky_relu(x)
plt.subplot(1, 2, 1)
ax = plt.gca() # 得到图像的Axes对象
ax.spines[‘right’].set_color(‘none’) # 将图像右边的轴设为透明
ax.spines[‘top’].set_color(‘none’) # 将图像上面的轴设为透明
ax.xaxis.set_ticks_position(‘bottom’) # 将x轴刻度设在下面的坐标轴上
ax.yaxis.set_ticks_position(‘left’) # 将y轴刻度设在左边的坐标轴上
ax.spines[‘bottom’].set_position((‘data’, 0)) # 将两个坐标轴的位置设在数据点原点
ax.spines[‘left’].set_position((‘data’, 0))
plt.title(‘Leaky ReLu函数’)
plt.xlabel(‘x’)
plt.ylabel(‘fx’)
plt.plot(x, fx)
plt.subplot(1, 2, 2)
ax = plt.gca() # 得到图像的Axes对象
ax.spines[‘right’].set_color(‘none’) # 将图像右边的轴设为透明
ax.spines[‘top’].set_color(‘none’) # 将图像上面的轴设为透明
ax.xaxis.set_ticks_position(‘bottom’) # 将x轴刻度设在下面的坐标轴上
ax.yaxis.set_ticks_position(‘left’) # 将y轴刻度设在左边的坐标轴上
ax.spines[‘bottom’].set_position((‘data’, 0)) # 将两个坐标轴的位置设在数据点原点
ax.spines[‘left’].set_position((‘data’, 0))
plt.title(‘Leaky Relu函数的导数’)
plt.xlabel(‘x’)
plt.ylabel(‘dx_fx’)
plt.plot(x, dx_fx)
plt.show()
与Leaky ReLU相似的还有PReLU和RReLU,下图是他们的比较:
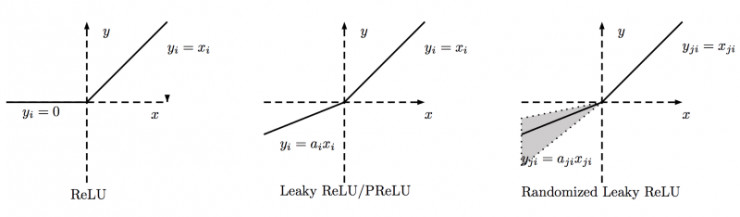
PReLU中的 a i a_{i} ai是根据数据变化的;
Leaky ReLU中的 a i a_{i} ai是固定的;
RReLU中的 a j i a_{ji} aji是一个在一个给定的范围内随机抽取的值,这个值在测试环节就会固定下来。
- ELU激活函数
函数定义: f ( x ) = { x , i f x ≥ 0 a ( e x − 1 ) , i f x < 0 f(x)=\left\{\begin{matrix} x,&if & x\geq 0\\ a(e^{x}-1), &if &x< 0 \end{matrix}\right. f(x)={x,a(ex−1),ififx≥0x<0
函数图像如下:

导数: f ′ = { 1 i f x ≥ 0 f ( x ) + a i f x < 0 {f}'=\left\{\begin{matrix} 1 &if & x\geq 0\\ f(x)+a &if &x< 0 \end{matrix}\right. f′={1f(x)+aififx≥0x<0
函数图像如下:

特点:
-
融合了sigmoid和ReLU,左侧具有软饱和性,右侧无饱和性。
-
右侧线性部分使得ELU能够缓解梯度消失,而左侧软饱能够让ELU对输入变化或噪声更鲁棒。
-
ELU的输出均值接近于零,所以收敛速度更快。
-
在 ImageNet上,不加 Batch Normalization 30 层以上的 ReLU 网络会无法收敛,PReLU网络在MSRA的Fan-in (caffe )初始化下会发散,而 ELU 网络在Fan-in/Fan-out下都能收敛。
函数及导数代码:
from matplotlib import pyplot as plt
import numpy as np
解决中文显示问题
plt.rcParams[‘font.sans-serif’] = [‘SimHei’]
plt.rcParams[‘axes.unicode_minus’] = False
def ELU(x):
“”“ELU函数”“”
return np.where(x<0,np.exp(x)-1,x)
def dx_ELU(x):
“”“ELU函数的导数”“”
return np.where(x < 0, np.exp(x), 1)
---------------------------------------------
if name == ‘main’:
x = np.arange(-10, 10, 0.01)
fx = ELU(x)
dx_fx = dx_ELU(x)
plt.subplot(1, 2, 1)
ax = plt.gca() # 得到图像的Axes对象
ax.spines[‘right’].set_color(‘none’) # 将图像右边的轴设为透明
ax.spines[‘top’].set_color(‘none’) # 将图像上面的轴设为透明
ax.xaxis.set_ticks_position(‘bottom’) # 将x轴刻度设在下面的坐标轴上
ax.yaxis.set_ticks_position(‘left’) # 将y轴刻度设在左边的坐标轴上
ax.spines[‘bottom’].set_position((‘data’, 0)) # 将两个坐标轴的位置设在数据点原点
ax.spines[‘left’].set_position((‘data’, 0))
plt.title(‘ELU函数’)
plt.xlabel(‘x’)
plt.ylabel(‘fx’)
plt.plot(x, fx)
plt.subplot(1, 2, 2)
ax = plt.gca() # 得到图像的Axes对象
ax.spines[‘right’].set_color(‘none’) # 将图像右边的轴设为透明
ax.spines[‘top’].set_color(‘none’) # 将图像上面的轴设为透明
ax.xaxis.set_ticks_position(‘bottom’) # 将x轴刻度设在下面的坐标轴上
ax.yaxis.set_ticks_position(‘left’) # 将y轴刻度设在左边的坐标轴上
ax.spines[‘bottom’].set_position((‘data’, 0)) # 将两个坐标轴的位置设在数据点原点
ax.spines[‘left’].set_position((‘data’, 0))
plt.title(‘ELU函数的导数’)
plt.xlabel(‘x’)
plt.ylabel(‘dx_fx’)
plt.plot(x, dx_fx)
plt.show()
- Mish激活函数
函数定义: f ( x ) = x ∗ t a n h ( l n ( 1 + e x ) ) f(x)=x*tanh(ln(1+e^{x})) f(x)=x∗tanh(ln(1+ex)),函数图像如下:

导数:
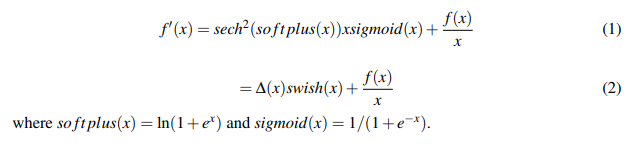
函数图像如下:

特点:
特点:无上界(unbounded above)、有下界(bounded below)、平滑(smooth)和非单调(nonmonotonic)。
无上界:可以防止网络饱和,即梯度消失。
有下界:提升网络的正则化效果。
平滑:首先在0值点连续相比ReLU可以减少一些不可预料的问题,其次可以使网络更容易优化并且提高泛化性能。
非单调:可以使一些小的负输入也被保留为负输出,提高网络的可解释能力和梯度流
优点:平滑、非单调、上无界、有下界
缺点:引入了指数函数,增加了计算量
函数及导数代码:
from matplotlib import pyplot as plt
import numpy as np
解决中文显示问题
plt.rcParams[‘font.sans-serif’] = [‘SimHei’]
plt.rcParams[‘axes.unicode_minus’] = False
def sech(x):
“”“sech函数”“”
return 2 / (np.exp(x) + np.exp(-x))
def sigmoid(x):
“”“sigmoid函数”“”
return 1 / (1 + np.exp(-x))
def softplus(x):
“”“softplus函数”“”
return np.log10(1+np.exp(x))
def tanh(x):
“”“tanh函数”“”
return ((np.exp(x) - np.exp(-x)) / (np.exp(x) + np.exp(-x)))
if name == ‘main’:
x = np.arange(-10, 10, 0.01)
fx = x * tanh(softplus(x))
dx_fx = sech(softplus(x))*sech(softplus(x))xsigmoid(x)+fx/x
plt.subplot(1, 2, 1)
ax = plt.gca() # 得到图像的Axes对象
ax.spines[‘right’].set_color(‘none’) # 将图像右边的轴设为透明
ax.spines[‘top’].set_color(‘none’) # 将图像上面的轴设为透明
ax.xaxis.set_ticks_position(‘bottom’) # 将x轴刻度设在下面的坐标轴上
ax.yaxis.set_ticks_position(‘left’) # 将y轴刻度设在左边的坐标轴上
ax.spines[‘bottom’].set_position((‘data’, 0)) # 将两个坐标轴的位置设在数据点原点
ax.spines[‘left’].set_position((‘data’, 0))
plt.title(‘Mish函数’)
plt.xlabel(‘x’)
plt.ylabel(‘fx’)
plt.plot(x, fx)
plt.subplot(1, 2, 2)
ax = plt.gca() # 得到图像的Axes对象
ax.spines[‘right’].set_color(‘none’) # 将图像右边的轴设为透明
ax.spines[‘top’].set_color(‘none’) # 将图像上面的轴设为透明
ax.xaxis.set_ticks_position(‘bottom’) # 将x轴刻度设在下面的坐标轴上
ax.yaxis.set_ticks_position(‘left’) # 将y轴刻度设在左边的坐标轴上
ax.spines[‘bottom’].set_position((‘data’, 0)) # 将两个坐标轴的位置设在数据点原点
ax.spines[‘left’].set_position((‘data’, 0))
plt.title(‘Mish函数的导数’)
plt.xlabel(‘x’)
plt.ylabel(‘dx_fx’)
plt.plot(x, dx_fx)
plt.show()
- Swish 激活函数
函数定义为: f ( x ) = x ∗ s i g m o i d ( β x ) f(x) = x*sigmoid(\beta x) f(x)=x∗sigmoid(βx),其函数图像如下:
其导数:
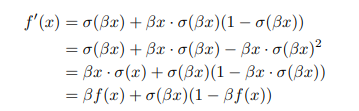 [外链图
[外链图
函数图像如下:

特点:
特点:Swish 具备无上界有下界、平滑、非单调的特性。
优点:ReLU有无上界和有下界的特点,而Swish相比ReLU又增加了平滑和非单调的特点,这使得其在ImageNet上的效果更好。
缺点:引入了指数函数,增加了计算量
函数及导数代码:
from matplotlib import pyplot as plt
import numpy as np
解决中文显示问题
plt.rcParams[‘font.sans-serif’] = [‘SimHei’]
plt.rcParams[‘axes.unicode_minus’] = False
def sech(x):
“”“sech函数”“”
return 2 / (np.exp(x) + np.exp(-x))
def sigmoid(x):
“”“sigmoid函数”“”
return 1 / (1 + np.exp(-x))
def s(x):
“”“sigmoid函数”“”
return 1 / (1 + np.exp(-b*x))
if name == ‘main’:
x = np.arange(-10, 10, 0.01)
b = 1
fx = x / (1 + np.exp(-b * x))
dx_fx = b * fx + s(x) * (1 - b * fx)
plt.subplot(1, 2, 1)
ax = plt.gca() # 得到图像的Axes对象
ax.spines[‘right’].set_color(‘none’) # 将图像右边的轴设为透明
ax.spines[‘top’].set_color(‘none’) # 将图像上面的轴设为透明
ax.xaxis.set_ticks_position(‘bottom’) # 将x轴刻度设在下面的坐标轴上
ax.yaxis.set_ticks_position(‘left’) # 将y轴刻度设在左边的坐标轴上
ax.spines[‘bottom’].set_position((‘data’, 0)) # 将两个坐标轴的位置设在数据点原点
ax.spines[‘left’].set_position((‘data’, 0))
plt.title(‘Swish函数’)
plt.xlabel(‘x’)
plt.ylabel(‘fx’)
plt.plot(x, fx)
plt.subplot(1, 2, 2)
ax = plt.gca() # 得到图像的Axes对象
ax.spines[‘right’].set_color(‘none’) # 将图像右边的轴设为透明
ax.spines[‘top’].set_color(‘none’) # 将图像上面的轴设为透明
ax.xaxis.set_ticks_position(‘bottom’) # 将x轴刻度设在下面的坐标轴上
ax.yaxis.set_ticks_position(‘left’) # 将y轴刻度设在左边的坐标轴上
ax.spines[‘bottom’].set_position((‘data’, 0)) # 将两个坐标轴的位置设在数据点原点
ax.spines[‘left’].set_position((‘data’, 0))
plt.title(‘Swish函数的导数’)
plt.xlabel(‘x’)
plt.ylabel(‘dx_fx’)
plt.plot(x, dx_fx)
plt.show()
- SiLU激活函数
函数定义为: f ( x ) = x ⋅ s i g m o i d ( x ) f(x)=x\cdot sigmoid (x) f(x)=x⋅sigmoid(x),其函数图形如下:
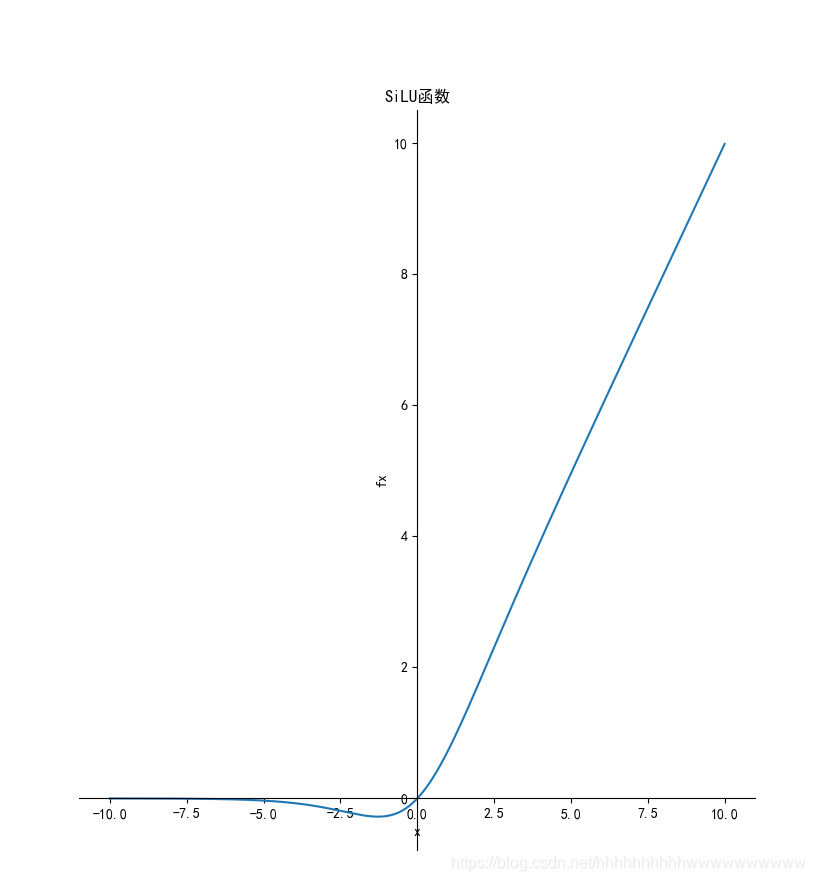
导数为: f ′ ( x ) = f ( x ) + s i g m o i d ( x ) ( 1 − f ( x ) ) {f}'(x)=f(x)+sigmoid (x)(1-f(x)) f′(x)=f(x)+sigmoid(x)(1−f(x)),其函数图像如下:
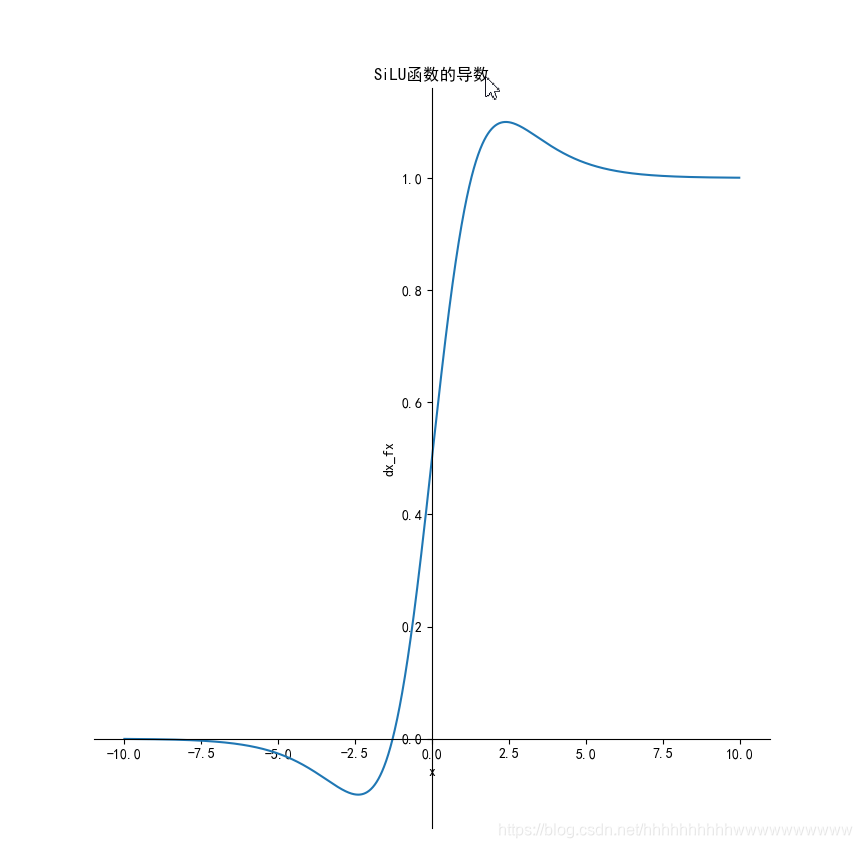
函数及导数代码:
from matplotlib import pyplot as plt
import numpy as np
解决中文显示问题
plt.rcParams[‘font.sans-serif’] = [‘SimHei’]
plt.rcParams[‘axes.unicode_minus’] = False
def sigmoid(x):
y = 1 / (1 + np.exp(-x))
return y
def silu(x):
return x*sigmoid(x)
def dx_silu(x):
return silu(x)+sigmoid(x)*(1-silu(x))
if name == ‘main’:
x = np.arange(-10, 10, 0.01)
b = 1
fx = silu(x)
dx=dx_silu(x)
plt.subplot(1, 2, 1)
ax = plt.gca() # 得到图像的Axes对象
ax.spines[‘right’].set_color(‘none’) # 将图像右边的轴设为透明
ax.spines[‘top’].set_color(‘none’) # 将图像上面的轴设为透明
ax.xaxis.set_ticks_position(‘bottom’) # 将x轴刻度设在下面的坐标轴上
ax.yaxis.set_ticks_position(‘left’) # 将y轴刻度设在左边的坐标轴上
ax.spines[‘bottom’].set_position((‘data’, 0)) # 将两个坐标轴的位置设在数据点原点
ax.spines[‘left’].set_position((‘data’, 0))
plt.title(‘SiLU函数’)
plt.xlabel(‘x’)
plt.ylabel(‘fx’)
plt.plot(x, fx)
plt.subplot(1, 2, 2)
ax = plt.gca() # 得到图像的Axes对象
ax.spines[‘right’].set_color(‘none’) # 将图像右边的轴设为透明
ax.spines[‘top’].set_color(‘none’) # 将图像上面的轴设为透明
ax.xaxis.set_ticks_position(‘bottom’) # 将x轴刻度设在下面的坐标轴上
ax.yaxis.set_ticks_position(‘left’) # 将y轴刻度设在左边的坐标轴上
ax.spines[‘bottom’].set_position((‘data’, 0)) # 将两个坐标轴的位置设在数据点原点
ax.spines[‘left’].set_position((‘data’, 0))
plt.title(‘SiLU函数的导数’)
plt.xlabel(‘x’)
plt.ylabel(‘dx_fx’)
plt.plot(x, dx)
plt.show()
-
非线性: 当激活函数是非线性的,一个两层的神经网络就可以基本上逼近所有的函数。但如果激活函数是恒等激活函数的时候,即 f ( x ) = x f(x)=x f(x)=x,就不满足这个性质,而且如果 MLP 使用的是恒等激活函数,那么其实整个网络跟单层神经网络是等价的;
-
可微性: 当优化方法是基于梯度的时候,就体现了该性质;
-
单调性: 当激活函数是单调的时候,单层网络能够保证是凸函数;
-
f ( x ) ≈ x f(x)≈x f(x)≈x: 当激活函数满足这个性质的时候,如果参数的初始化是随机的较小值,那么神经网络的训练将会很高效;如果不满足这个性质,那么就需要详细地去设置初始值;
-
输出值的范围: 当激活函数输出值是有限的时候,基于梯度的优化方法会更加稳定,因为特征的表示受有限权值的影响更显著;当激活函数的输出是无限的时候,模型的训练会更加高效,不过在这种情况下,一般需要更小的 Learning Rate。
选择一个适合的激活函数并不容易,需要考虑很多因素,通常的做法是,如果不确定哪一个激活函数效果更好,可以把它们都试试,然后在验证集或者测试集上进行评价。然后看哪一种表现的更好,就去使用它。
以下是常见的选择情况:
-
如果输出是 0、1 值(二分类问题),则输出层选择 sigmoid 函数,然后其它的所有单元都选择 Relu 函数。
-
如果在隐藏层上不确定使用哪个激活函数,那么通常会使用 Relu 激活函数。有时,也会使用 tanh 激活函数,但 Relu 的一个优点是:当是负值的时候,导数等于 0。
-
sigmoid 激活函数:除了输出层是一个二分类问题基本不会用它。
-
tanh 激活函数:tanh 是非常优秀的,几乎适合所有场合。
-
ReLu 激活函数:最常用的默认函数,如果不确定用哪个激活函数,就使用 ReLu 或者 Leaky ReLu,再去尝试其他的激活函数。
-
如果遇到了一些死的神经元,我们可以使用 Leaky ReLU 函数。
-
在区间变动很大的情况下,ReLu 激活函数的导数或者激活函数的斜率都会远大于 0,在程序实现就是一个 if-else 语句,而 sigmoid 函数需要进行浮点四则运算,在实践中,使用 ReLu 激活函数神经网络通常会比使用 sigmoid 或者 tanh 激活函数学习的更快。
-
sigmoid 和 tanh 函数的导数在正负饱和区的梯度都会接近于 0,这会造成梯度弥散,而 Relu 和Leaky ReLu 函数大于 0 部分都为常数,不会产生梯度弥散现象。
-
需注意,Relu 进入负半区的时候,梯度为 0,神经元此时不会训练,产生所谓的稀疏性,而 Leaky ReLu 不会产生这个问题。
-
输出层,大多使用线性激活函数。
-
在隐含层可能会使用一些线性激活函数。
-
一般用到的线性激活函数很少。
Relu 激活函数图像如下:
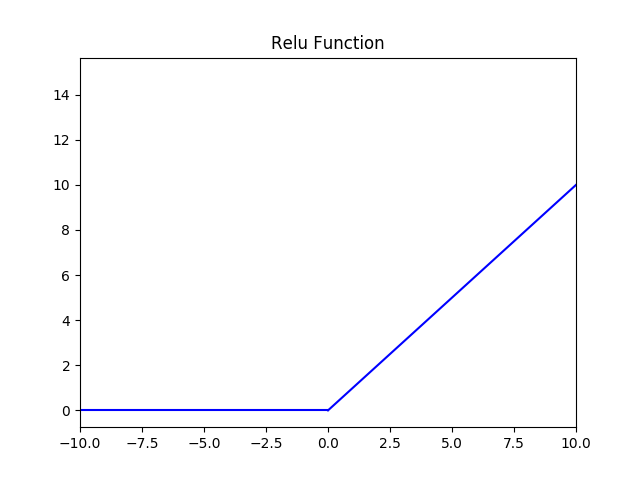
根据图像可看出具有如下特点:
-
单侧抑制;
-
相对宽阔的兴奋边界;
-
稀疏激活性;
ReLU 函数从图像上看,是一个分段线性函数,把所有的负值都变为 0,而正值不变,这样就成为单侧抑制。
因为有了这单侧抑制,才使得神经网络中的神经元也具有了稀疏激活性。
稀疏激活性:从信号方面来看,即神经元同时只对输入信号的少部分选择性响应,大量信号被刻意的屏蔽了,这样可以提高学习的精度,更好更快地提取稀疏特征。当 x < 0 x<0 x<0时,ReLU 硬饱和,而当 x > 0 x>0 x>0时,则不存在饱和问题。ReLU 能够在 x > 0 x>0 x>0时保持梯度不衰减,从而缓解梯度消失问题。
Softmax 是一种形如下式的函数:
P ( i ) = e x p ( θ i T x ) ∑ k = 1 K e x p ( θ i T x ) P(i) = \frac{exp(\theta_i^T x)}{\sum_{k=1}^{K} exp(\theta_i^T x)} P(i)=∑k=1Kexp(θiTx)exp(θiTx)
其中, θ i \theta_i θi和 x x x是列向量, θ i T x \theta_i^T x θiTx可能被换成函数关于 x x x的函数 f i ( x ) f_i(x) fi(x)
通过 softmax 函数,可以使得 P ( i ) P(i) P(i)的范围在 [ 0 , 1 ] [0,1] [0,1]之间。在回归和分类问题中,通常 θ \theta θ是待求参数,通过寻找使得 P ( i ) P(i) P(i)最大的 θ i \theta_i θi作为最佳参数。
但是,使得范围在 [ 0 , 1 ] [0,1] [0,1] 之间的方法有很多,为啥要在前面加上以 e e e的幂函数的形式呢?参考 logistic 函数:
P ( i ) = 1 1 + e x p ( − θ i T x ) P(i) = \frac{1}{1+exp(-\theta_i^T x)} P(i)=1+exp(−θiTx)1
这个函数的作用就是使得 P ( i ) P(i) P(i)在负无穷到 0 的区间趋向于 0, 在 0 到正无穷的区间趋向 1,。同样 softmax 函数加入了 e e e的幂函数正是为了两极化:正样本的结果将趋近于 1,而负样本的结果趋近于 0。这样为多类别提供了方便(可以把 P ( i ) P(i) P(i)看做是样本属于类别的概率)。可以说,Softmax 函数是 logistic 函数的一种泛化。
softmax 函数可以把它的输入,通常被称为 logits 或者 logit scores,处理成 0 到 1 之间,并且能够把输出归一化到和为 1。这意味着 softmax 函数与分类的概率分布等价。它是一个网络预测多酚类问题的最佳输出激活函数。
softmax 用于多分类过程中,它将多个神经元的输出,映射到 ( 0 , 1 ) (0,1) (0,1)区间内,可以看成概率来理解,从而来进行多分类!
假设我们有一个数组, V i V_i Vi表示 V V V 中的第 i i i个元素,那么这个元素的 softmax 值就是
S i = e V i ∑ j e V j S_i = \frac{e^{V_i}}{\sum_j e^{V_j}} Si=∑jeVjeVi
从下图看,神经网络中包含了输入层,然后通过两个特征层处理,最后通过 softmax 分析器就能得到不同条件下的概率,这里需要分成三个类别,最终会得到 y = 0 , y = 1 , y = 2 y=0, y=1, y=2 y=0,y=1,y=2的概率值。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6BbtnCB6-1628659360507)(https://gitee.com/wanghao1090220084/images/raw/master/img/3.4.9.1.png)]
继续看下面的图,三个输入通过 softmax 后得到一个数组 [ 0.05 , 0.10 , 0.85 ] [0.05 , 0.10 , 0.85] [0.05,0.10,0.85],这就是 soft 的功能。
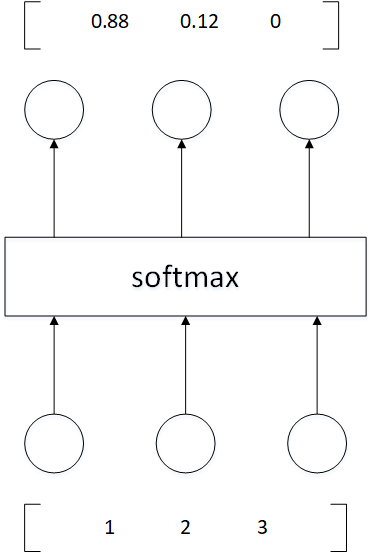
更形象的映射过程如下图所示:
softmax 直白来说就是将原来输出是 3 , 1 , − 3 3,1,-3 3,1,−3通过 softmax 函数一作用,就映射成为 ( 0 , 1 ) (0,1) (0,1)的值,而这些值的累和为 1 1 1(满足概率的性质),那么我们就可以将它理解成概率,在最后选取输出结点的时候,我们就可以选取概率最大(也就是值对应最大的)结点,作为我们的预测目标!
神经元的输出就是 a = σ(z),其中 z = ∑ w j i j + b z=\sum w_{j}i_{j}+b z=∑wjij+b是输⼊的带权和。
C = − 1 n ∑ [ y l n a + ( 1 − y ) l n ( 1 − a ) ] C=-\frac{1}{n}\sum[ylna+(1-y)ln(1-a)] C=−n1∑[ylna+(1−y)ln(1−a)]
其中 n 是训练数据的总数,求和是在所有的训练输⼊ x 上进⾏的, y 是对应的⽬标输出。
表达式是否解决学习缓慢的问题并不明显。实际上,甚⾄将这个定义看做是代价函数也不是显⽽易⻅的!在解决学习缓慢前,我们来看看交叉熵为何能够解释成⼀个代价函数。
将交叉熵看做是代价函数有两点原因。
第⼀,它是⾮负的, C > 0。可以看出:式子中的求和中的所有独⽴的项都是负数的,因为对数函数的定义域是 (0,1),并且求和前⾯有⼀个负号,所以结果是非负。
第⼆,如果对于所有的训练输⼊ x,神经元实际的输出接近⽬标值,那么交叉熵将接近 0。
假设在这个例⼦中, y = 0 ⽽ a ≈ 0。这是我们想到得到的结果。我们看到公式中第⼀个项就消去了,因为 y = 0,⽽第⼆项实际上就是 − ln(1 − a) ≈ 0。反之, y = 1 ⽽ a ≈ 1。所以在实际输出和⽬标输出之间的差距越⼩,最终的交叉熵的值就越低了。(这里假设输出结果不是0,就是1,实际分类也是这样的)
综上所述,交叉熵是⾮负的,在神经元达到很好的正确率的时候会接近 0。这些其实就是我们想要的代价函数的特性。其实这些特性也是⼆次代价函数具备的。所以,交叉熵就是很好的选择了。但是交叉熵代价函数有⼀个⽐⼆次代价函数更好的特性就是它避免了学习速度下降的问题。为了弄清楚这个情况,我们来算算交叉熵函数关于权重的偏导数。我们将 a = ς ( z ) a={\varsigma}(z) a=ς(z)代⼊到 公式中应⽤两次链式法则,得到:
KaTeX parse error: No such environment: eqnarray at position 7: \begin{̲e̲q̲n̲a̲r̲r̲a̲y̲}̲\frac{\partial …
根据 ς ( z ) = 1 1 + e − z \varsigma(z)=\frac{1}{1+e^{-z}} ς(z)=1+e−z1的定义,和⼀些运算,我们可以得到 ς ′ ( z ) = ς ( z ) ( 1 − ς ( z ) ) {\varsigma}'(z)=\varsigma(z)(1-\varsigma(z)) ς′(z)=ς(z)(1−ς(z))。化简后可得:
∂ C ∂ w j = 1 n ∑ x j ( ς ( z ) − y ) \frac{\partial C}{\partial w_{j}}=\frac{1}{n}\sum x_{j}({\varsigma}(z)-y) ∂wj∂C=n1∑xj(ς(z)−y)
这是⼀个优美的公式。它告诉我们权重学习的速度受到 ς ( z ) − y \varsigma(z)-y ς(z)−y,也就是输出中的误差的控制。更⼤的误差,更快的学习速度。这是我们直觉上期待的结果。特别地,这个代价函数还避免了像在⼆次代价函数中类似⽅程中 ς ′ ( z ) {\varsigma}‘(z) ς′(z)导致的学习缓慢。当我们使⽤交叉熵的时候, ς ′ ( z ) {\varsigma}’(z) ς′(z)被约掉了,所以我们不再需要关⼼它是不是变得很⼩。这种约除就是交叉熵带来的特效。实际上,这也并不是⾮常奇迹的事情。我们在后⾯可以看到,交叉熵其实只是满⾜这种特性的⼀种选择罢了。
根据类似的⽅法,我们可以计算出关于偏置的偏导数。我这⾥不再给出详细的过程,你可以轻易验证得到:
∂ C ∂ b = 1 n ∑ ( ς ( z ) − y ) \frac{\partial C}{\partial b}=\frac{1}{n}\sum ({\varsigma}(z)-y) ∂b∂C=n1∑(ς(z)−y)
再⼀次, 这避免了⼆次代价函数中类似 ς ′ ( z ) {\varsigma}'(z) ς′(z)项导致的学习缓慢。
首先看如下两个函数的求导:
t a n h , ( x ) = 1 − t a n h ( x ) 2 ∈ ( 0 , 1 ) tanh{,}(x)=1-tanh(x){2}\in (0,1) tanh,(x)=1−tanh(x)2∈(0,1)
s , ( x ) = s ( x ) ∗ ( 1 − s ( x ) ) ∈ ( 0 , 1 4 ] s^{,}(x)=s(x)*(1-s(x))\in (0,\frac{1}{4}] s,(x)=s(x)∗(1−s(x))∈(0,41]
由上面两个公式可知tanh(x)梯度消失的问题比sigmoid轻,所以Tanh收敛速度比Sigmoid快。
注:梯度消失(gradient vanishing)或者爆炸(gradient explosion)是激活函数以及当前权重耦合产生的综合结果:
设任意激活函数为 σ ( ⋅ ) \sigma(\cdot) σ(⋅),k+1层网络输出为 f k + 1 = σ ( W f k ) f_{k+1}=\sigma(Wf_k) fk+1=σ(Wfk),求导得到 ∂ h t + 1 ∂ h t = d i a g ( σ ′ ( W h t ) ) W \frac {\partial h_{t+1}}{\partial h_t}=diag(\sigma’(Wh_t))W ∂ht∂ht+1=diag(σ′(Wht))W。可见求导结果同时会受到权重 W W W和激活函数的导数 σ ′ ( ⋅ ) \sigma’(\cdot) σ′(⋅)的影响,以sigmoid函数 σ ( X ) = 1 1 + e − x \sigma(X)=\frac {1}{1+e^{-x}} σ(X)=1+e−x1为例,其导数为 σ ′ ( x ) = 1 1 + e − x ( 1 − 1 1 + e − x ) \sigma’(x)=\frac{1}{1+e{-x}}(1-\frac{1}{1+e{-x}}) σ′(x)=1+e−x1(1−1+e−x1),其值恒大于零小于1,用链式法则求梯度回传时连续相乘使得结果趋于0,但是如果权重 W W W是较大的数值,使得 ∂ f t + 1 ∂ f t \frac {\partial f_{t+1}}{\partial f_t} ∂ft∂ft+1相乘结果大于1,则梯度回传时连续相乘则不会发生梯度消失。
综上,在讨论激活函数收敛速度或与梯度消失或者爆炸相关时,应同时考虑当前权重 W W W数值的影响。
========================================================================
Batch一般被翻译为批量,设置batch_size的目的让模型在训练过程中每次选择批量的数据来进行处理。一般机器学习或者深度学习训练过程中的目标函数可以简单理解为在每个训练集样本上得到的目标函数值的求和,然后根据目标函数的值进行权重值的调整,大部分时候是根据梯度下降法来进行参数更新的。
Batch Size的直观理解就是一次训练所选取的样本数。
Batch Size的大小影响模型的优化程度和速度。同时其直接影响到GPU内存的使用情况,假如你GPU内存不大,该数值最好设置小一点。
在没有使用Batch Size之前,这意味着网络在训练时,是一次把所有的数据(整个数据库)输入网络中,然后计算它们的梯度进行反向传播,由于在计算梯度时使用了整个数据库,所以计算得到的梯度方向更为准确。但在这情况下,计算得到不同梯度值差别巨大,难以使用一个全局的学习率,所以这时一般使用Rprop这种基于梯度符号的训练算法,单独进行梯度更新。
在小样本数的数据库中,不使用Batch Size是可行的,而且效果也很好。但是一旦是大型的数据库,一次性把所有数据输进网络,肯定会引起内存的爆炸。所以就提出Batch Size的概念。
假如每次只训练一个样本,即 Batch_Size = 1。线性神经元在均方误差代价函数的错误面是一个抛物面,横截面是椭圆。对于多层神经元、非线性网络,在局部依然近似是抛物面。此时,每次修正方向以各自样本的梯度方向修正,横冲直撞各自为政,难以达到收敛。
既然 Batch_Size 为全数据集或者Batch_Size = 1都有各自缺点,那么如何设置一个合适的BatchSize呢? 这个和样本还有一定的关系,样本量少的时候会带来很大的方差,而这个大方差恰好会导致我们在梯度下降到很差的局部最优点(只是微微凸下去的最优点)和鞍点的时候不稳定,一不小心就因为一个大噪声的到来导致炸出了局部最优点。
与之相反的,当样本量很多时,方差很小,对梯度的估计要准确和稳定的多,因此反而在差劲的局部最优点和鞍点时反而容易自信的呆着不走了,从而导致神经网络收敛到很差的点上,跟出了bug一样的差劲。
batch的size设置的不能太大也不能太小,因此实际工程中最常用的就是mini-batch,一般size设置为几十或者几百。
对于二阶优化算法,减小batch换来的收敛速度提升远不如引入大量噪声导致的性能下降,因此在使用二阶优化算法时,往往要采用大batch哦。此时往往batch设置成几千甚至一两万才能发挥出最佳性能。
所以设置BatchSize要注意一下几点:
1)batch数太小,而类别又比较多的时候,真的可能会导致loss函数震荡而不收敛,尤其是在你的网络比较复杂的时候。
2)随着batchsize增大,处理相同的数据量的速度越快。
3)随着batchsize增大,达到相同精度所需要的epoch数量越来越多。
4)由于上述两种因素的矛盾, Batch_Size 增大到某个时候,达到时间上的最优。
5)由于最终收敛精度会陷入不同的局部极值,因此 Batch_Size 增大到某些时候,达到最终收敛精度上的最优。
6)过大的batchsize的结果是网络很容易收敛到一些不好的局部最优点。同样太小的batch也存在一些问题,比如训练速度很慢,训练不容易收敛等。
7)具体的batch size的选取和训练集的样本数目相关。
8)GPU对2的幂次的batch可以发挥更佳的性能,因此设置成16、32、64、128…时往往要比设置为整10、整100的倍数时表现更优
我在设置BatchSize的时候,首先选择大点的BatchSize把GPU占满,观察Loss收敛的情况,如果不收敛,或者收敛效果不好则降低BatchSize,一般常用16,32,64等。
内存利用率提高了,大矩阵乘法的并行化效率提高。
跑完一次 epoch(全数据集)所需的迭代次数减少,对于相同数据量的处理速度进一步加快。
在一定范围内,一般来说 Batch_Size 越大,其确定的下降方向越准,引起训练震荡越小。
内存利用率提高了,但是内存容量可能撑不住了。
跑完一次 epoch(全数据集)所需的迭代次数减少,要想达到相同的精度,其所花费的时间大大增加了,从而对参数的修正也就显得更加缓慢。
Batch_Size 增大到一定程度,其确定的下降方向已经基本不再变化。
5.6 调节 Batch_Size 对训练效果影响到底如何?
Batch_Size 太小,模型表现效果极其糟糕(error飙升)。
随着 Batch_Size 增大,处理相同数据量的速度越快。
随着 Batch_Size 增大,达到相同精度所需要的 epoch 数量越来越多。
由于上述两种因素的矛盾, Batch_Size 增大到某个时候,达到时间上的最优。
由于最终收敛精度会陷入不同的局部极值,因此 Batch_Size 增大到某些时候,达到最终收敛精度上的最优。
================================================================
-
归纳统一样本的统计分布性。归一化在 0 − 1 0-1 0−1之间是统计的概率分布,归一化在 − 1 − − + 1 -1–+1 −1−−+1之间是统计的坐标分布。
-
无论是为了建模还是为了计算,首先基本度量单位要同一,神经网络是以样本在事件中的统计分别几率来进行训练(概率计算)和预测,且 sigmoid 函数的取值是 0 到 1 之间的,网络最后一个节点的输出也是如此,所以经常要对样本的输出归一化处理。
-
归一化是统一在 0 − 1 0-1 0−1之间的统计概率分布,当所有样本的输入信号都为正值时,与第一隐含层神经元相连的权值只能同时增加或减小,从而导致学习速度很慢。
-
另外在数据中常存在奇异样本数据,奇异样本数据存在所引起的网络训练时间增加,并可能引起网络无法收敛。为了避免出现这种情况及后面数据处理的方便,加快网络学习速度,可以对输入信号进行归一化,使得所有样本的输入信号其均值接近于 0 或与其均方差相比很小。
-
为了后面数据处理的方便,归一化的确可以避免一些不必要的数值问题。
-
为了程序运行时收敛加快。
-
同一量纲。样本数据的评价标准不一样,需要对其量纲化,统一评价标准。这算是应用层面的需求。
-
避免神经元饱和。啥意思?就是当神经元的激活在接近 0 或者 1 时会饱和,在这些区域,梯度几乎为 0,这样,在反向传播过程中,局部梯度就会接近 0,这会有效地“杀死”梯度。
-
保证输出数据中数值小的不被吞食。
-
有可能提高精度。一些分类器需要计算样本之间的距离(如欧氏距离),例如KNN。如果一个特征值域范围非常大,那么距离计算就主要取决于这个特征,从而与实际情况相悖(比如这时实际情况是值域范围小的特征更重要)。
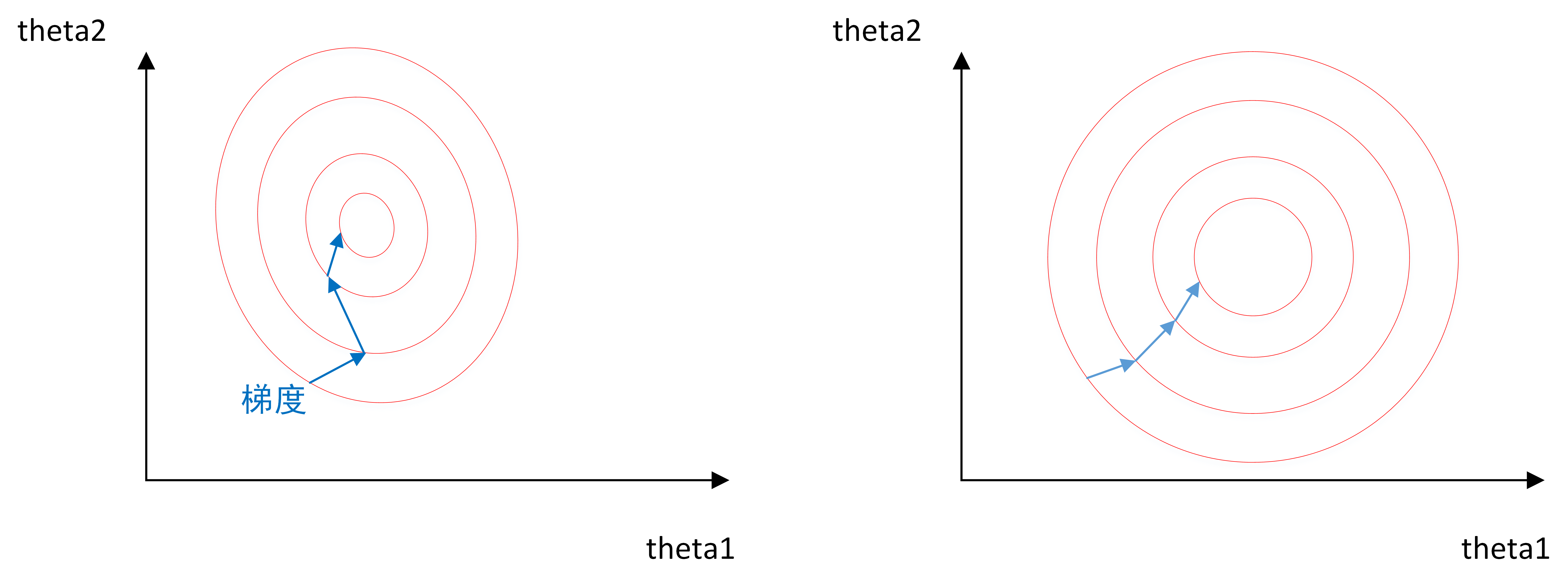
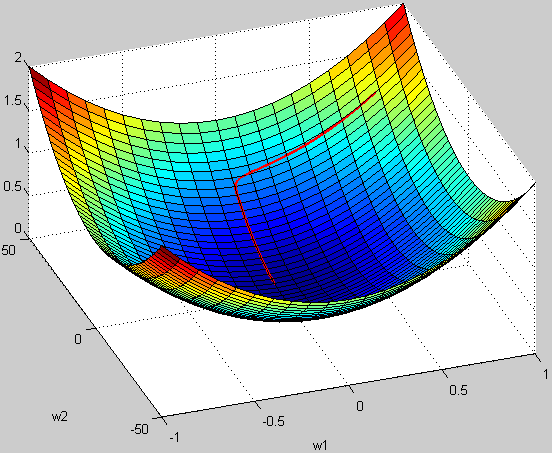
上图是代表数据是否均一化的最优解寻解过程(圆圈可以理解为等高线)。左图表示未经归一化操作的寻解过程,右图表示经过归一化后的寻解过程。
当使用梯度下降法寻求最优解时,很有可能走“之字型”路线(垂直等高线走),从而导致需要迭代很多次才能收敛;而右图对两个原始特征进行了归一化,其对应的等高线显得很圆,在梯度下降进行求解时能较快的收敛。
因此如果机器学习模型使用梯度下降法求最优解时,归一化往往非常有必要,否则很难收敛甚至不能收敛。
例子:
假设 w 1 w1 w1的范围在 [ − 10 , 10 ] [-10, 10] [−10,10],而 w 2 w2 w2的范围在 [ − 100 , 100 ] [-100, 100] [−100,100],梯度每次都前进 1 单位,那么在 w 1 w1 w1方向上每次相当于前进了 1 / 20 1/20 1/20,而在 w 2 w2 w2上只相当于 1 / 200 1/200 1/200!某种意义上来说,在 w 2 w2 w2上前进的步长更小一些,而 w 1 w1 w1在搜索过程中会比 w 2 w2 w2“走”得更快。
这样会导致,在搜索过程中更偏向于 w 1 w1 w1的方向。走出了“L”形状,或者成为“之”字形。
- 线性归一化
x ′ = x − m i n ( x ) m a x ( x ) − m i n ( x ) x^{\prime} = \frac{x-min(x)}{max(x) - min(x)} x′=max(x)−min(x)x−min(x)
适用范围:比较适用在数值比较集中的情况。
缺点:如果 max 和 min 不稳定,很容易使得归一化结果不稳定,使得后续使用效果也不稳定。
- 标准差标准化
x ′ = x − μ σ x^{\prime} = \frac{x-\mu}{\sigma} x′=σx−μ
含义:经过处理的数据符合标准正态分布,即均值为 0,标准差为 1 其中 μ \mu μ为所有样本数据的均值, σ \sigma σ为所有样本数据的标准差。
- 非线性归一化
适用范围:经常用在数据分化比较大的场景,有些数值很大,有些很小。通过一些数学函数,将原始值进行映射。该方法包括 l o g log log、指数,正切等。
LRN 是一种提高深度学习准确度的技术方法。LRN 一般是在激活、池化函数后的一种方法。
在 ALexNet 中,提出了 LRN 层,对局部神经元的活动创建竞争机制,使其中响应比较大对值变得相对更大,并抑制其他反馈较小的神经元,增强了模型的泛化能力。
局部响应归一化原理是仿造生物学上活跃的神经元对相邻神经元的抑制现象(侧抑制),其公式如下:
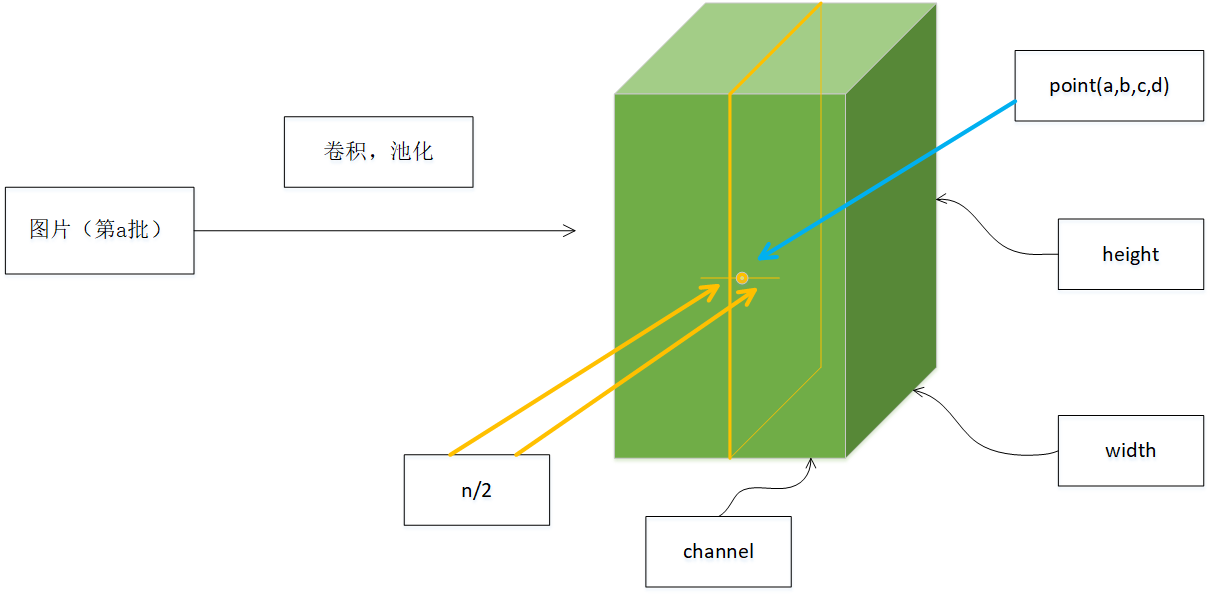
b x , y i = a x , y i / ( k + α ∑ j = m a x ( 0 , i − n / 2 ) m i n ( N − 1 , i + n / 2 ) ( a x , y j ) 2 ) β b_{x,y}^i = a_{x,y}^i / (k + \alpha \sum_{j=max(0, i-n/2)}^{min(N-1, i+n/2)}(a_{x,y}j)2 )^\beta bx,yi=ax,yi/(k+αj=max(0,i−n/2)∑min(N−1,i+n/2)(ax,yj)2)β
其中,
- a a a:表示卷积层(包括卷积操作和池化操作)后的输出结果,是一个四维数组[batch,height,width,channel]。
-
batch:批次数(每一批为一张图片)。
-
height:图片高度。
-
width:图片宽度。
-
channel:通道数。可以理解成一批图片中的某一个图片经过卷积操作后输出的神经元个数,或理解为处理后的图片深度。
-
a x , y i a_{x,y}^i ax,yi表示在这个输出结构中的一个位置 [ a , b , c , d ] [a,b,c,d] [a,b,c,d],可以理解成在某一张图中的某一个通道下的某个高度和某个宽度位置的点,即第 a a a张图的第 d d d个通道下的高度为b宽度为c的点。
-
N N N:论文公式中的 N N N表示通道数 (channel)。
-
a a a, n / 2 n/2 n/2, k k k分别表示函数中的 input,depth_radius,bias。参数 k , n , α , β k, n, \alpha, \beta k,n,α,β都是超参数,一般设置 k = 2 , n = 5 , α = 1 ∗ e − 4 , β = 0.75 k=2, n=5, \alpha=1*e-4, \beta=0.75 k=2,n=5,α=1∗e−4,β=0.75
-
∑ \sum ∑: ∑ \sum ∑叠加的方向是沿着通道方向的,即每个点值的平方和是沿着 a a a中的第 3 维 channel 方向的,也就是一个点同方向的前面 n / 2 n/2 n/2个通道(最小为第 0 0 0个通道)和后 n / 2 n/2 n/2个通道(最大为第 d − 1 d-1 d−1个通道)的点的平方和(共 n + 1 n+1 n+1个点)。而函数的英文注解中也说明了把 input 当成是 d d d个 3 维的矩阵,说白了就是把 input 的通道数当作 3 维矩阵的个数,叠加的方向也是在通道方向。
简单的示意图如下:
6.8 什么是批归一化(Batch Normalization)
以前在神经网络训练中,只是对输入层数据进行归一化处理,却没有在中间层进行归一化处理。要知道,虽然我们对输入数据进行了归一化处理,但是输入数据经过 σ ( W X + b ) \sigma(WX+b) σ(WX+b)这样的矩阵乘法以及非线性运算之后,其数据分布很可能被改变,而随着深度网络的多层运算之后,数据分布的变化将越来越大。如果我们能在网络的中间也进行归一化处理,是否对网络的训练起到改进作用呢?答案是肯定的。
这种在神经网络中间层也进行归一化处理,使训练效果更好的方法,就是批归一化Batch Normalization(BN)。
下面我们来说一下BN算法的优点:
-
减少了人为选择参数。在某些情况下可以取消 dropout 和 L2 正则项参数,或者采取更小的 L2 正则项约束参数;
-
减少了对学习率的要求。现在我们可以使用初始很大的学习率或者选择了较小的学习率,算法也能够快速训练收敛;
-
可以不再使用局部响应归一化。BN 本身就是归一化网络(局部响应归一化在 AlexNet 网络中存在)
-
破坏原来的数据分布,一定程度上缓解过拟合(防止每批训练中某一个样本经常被挑选到,文献说这个可以提高 1% 的精度)。
-
减少梯度消失,加快收敛速度,提高训练精度。
下面给出 BN 算法在训练时的过程
输入:上一层输出结果 X = x 1 , x 2 , . . . , x m X = {x_1, x_2, …, x_m} X=x1,x2,…,xm,学习参数 γ , β \gamma, \beta γ,β
算法流程:
- 计算上一层输出数据的均值
μ β = 1 m ∑ i = 1 m ( x i ) \mu_{\beta} = \frac{1}{m} \sum_{i=1}^m(x_i) μβ=m1i=1∑m(xi)
其中, m m m是此次训练样本 batch 的大小。
- 计算上一层输出数据的标准差
σ β 2 = 1 m ∑ i = 1 m ( x i − μ β ) 2 \sigma_{\beta}^2 = \frac{1}{m} \sum_{i=1}^m (x_i - \mu_{\beta})^2 σβ2=m1i=1∑m(xi−μβ)2
- 归一化处理,得到
x ^ i = x i + μ β σ β 2 + ϵ \hat x_i = \frac{x_i + \mu_{\beta}}{\sqrt{\sigma_{\beta}^2} + \epsilon} x^i=σβ2 +ϵxi+μβ
其中 ϵ \epsilon ϵ是为了避免分母为 0 而加进去的接近于 0 的很小值
- 重构,对经过上面归一化处理得到的数据进行重构,得到
y i = γ x ^ i + β y_i = \gamma \hat x_i + \beta yi=γx^i+β
其中, γ , β \gamma, \beta γ,β为可学习参数。
注:上述是 BN 训练时的过程,但是当在投入使用时,往往只是输入一个样本,没有所谓的均值 μ β \mu_{\beta} μβ和标准差 σ β 2 \sigma_{\beta}^2 σβ2。此时,均值 μ β \mu_{\beta} μβ是计算所有 batch μ β \mu_{\beta} μβ值的平均值得到,标准差 σ β 2 \sigma_{\beta}^2 σβ2采用每个batch σ β 2 \sigma_{\beta}^2 σβ2 的无偏估计得到。
| 名称 | 特点 |
| — | :-- |
| 批量归一化(Batch Normalization,以下简称 BN) | 可让各种网络并行训练。但是,批量维度进行归一化会带来一些问题——批量统计估算不准确导致批量变小时,BN 的误差会迅速增加。在训练大型网络和将特征转移到计算机视觉任务中(包括检测、分割和视频),内存消耗限制了只能使用小批量的 BN。 |
| 群组归一化 Group Normalization (简称 GN) | GN 将通道分成组,并在每组内计算归一化的均值和方差。GN 的计算与批量大小无关,并且其准确度在各种批量大小下都很稳定。 |
| 比较 | 在 ImageNet 上训练的 ResNet-50上,GN 使用批量大小为 2 时的错误率比 BN 的错误率低 10.6% ;当使用典型的批量时,GN 与 BN 相当,并且优于其他标归一化变体。而且,GN 可以自然地从预训练迁移到微调。在进行 COCO 中的目标检测和分割以及 Kinetics 中的视频分类比赛中,GN 可以胜过其竞争对手,表明 GN 可以在各种任务中有效地取代强大的 BN。 |
6.12 Weight Normalization和Batch Normalization比较
Weight Normalization 和 Batch Normalization 都属于参数重写(Reparameterization)的方法,只是采用的方式不同。
Weight Normalization 是对网络权值$ W$进行 normalization,因此也称为 Weight Normalization;
Batch Normalization 是对网络某一层输入数据进行 normalization。
Weight Normalization相比Batch Normalization有以下三点优势:
-
Weight Normalization 通过重写深度学习网络的权重W的方式来加速深度学习网络参数收敛,没有引入 minbatch 的依赖,适用于 RNN(LSTM)网络(Batch Normalization 不能直接用于RNN,进行 normalization 操作,原因在于:1) RNN 处理的 Sequence 是变长的;2) RNN 是基于 time step 计算,如果直接使用 Batch Normalization 处理,需要保存每个 time step 下,mini btach 的均值和方差,效率低且占内存)。
-
Batch Normalization 基于一个 mini batch 的数据计算均值和方差,而不是基于整个 Training set 来做,相当于进行梯度计算式引入噪声。因此,Batch Normalization 不适用于对噪声敏感的强化学习、生成模型(Generative model:GAN,VAE)使用。相反,Weight Normalization 对通过标量 g g g和向量 v v v对权重 W W W进行重写,重写向量 v v v是固定的,因此,基于 Weight Normalization 的 Normalization 可以看做比 Batch Normalization 引入更少的噪声。
-
不需要额外的存储空间来保存 mini batch 的均值和方差,同时实现 Weight Normalization 时,对深度学习网络进行正向信号传播和反向梯度计算带来的额外计算开销也很小。因此,要比采用 Batch Normalization 进行 normalization 操作时,速度快。 但是 Weight Normalization 不具备 Batch Normalization 把网络每一层的输出 Y 固定在一个变化范围的作用。因此,采用 Weight Normalization 进行 Normalization 时需要特别注意参数初始值的选择。
6.13 Batch Normalization在什么时候用比较合适?
(贡献者:黄钦建-华南理工大学)
在CNN中,BN应作用在非线性映射前。在神经网络训练时遇到收敛速度很慢,或梯度爆炸等无法训练的状况时可以尝试BN来解决。另外,在一般使用情况下也可以加入BN来加快训练速度,提高模型精度。
BN比较适用的场景是:每个mini-batch比较大,数据分布比较接近。在进行训练之前,要做好充分的shuffle,否则效果会差很多。另外,由于BN需要在运行过程中统计每个mini-batch的一阶统计量和二阶统计量,因此不适用于动态的网络结构和RNN网络。
====================================================================
偏差初始化陷阱: 都初始化为 0。
产生陷阱原因:因为并不知道在训练神经网络中每一个权重最后的值,但是如果进行了恰当的数据归一化后,我们可以有理由认为有一半的权重是正的,另一半是负的。令所有权重都初始化为 0,如果神经网络计算出来的输出值是一样的,神经网络在进行反向传播算法计算出来的梯度值也一样,并且参数更新值也一样。更一般地说,如果权重初始化为同一个值,网络就是对称的。
形象化理解:在神经网络中考虑梯度下降的时候,设想你在爬山,但身处直线形的山谷中,两边是对称的山峰。由于对称性,你所在之处的梯度只能沿着山谷的方向,不会指向山峰;你走了一步之后,情况依然不变。结果就是你只能收敛到山谷中的一个极大值,而走不到山峰上去。
偏差初始化陷阱: 都初始化为一样的值。
以一个三层网络为例:
首先看下结构
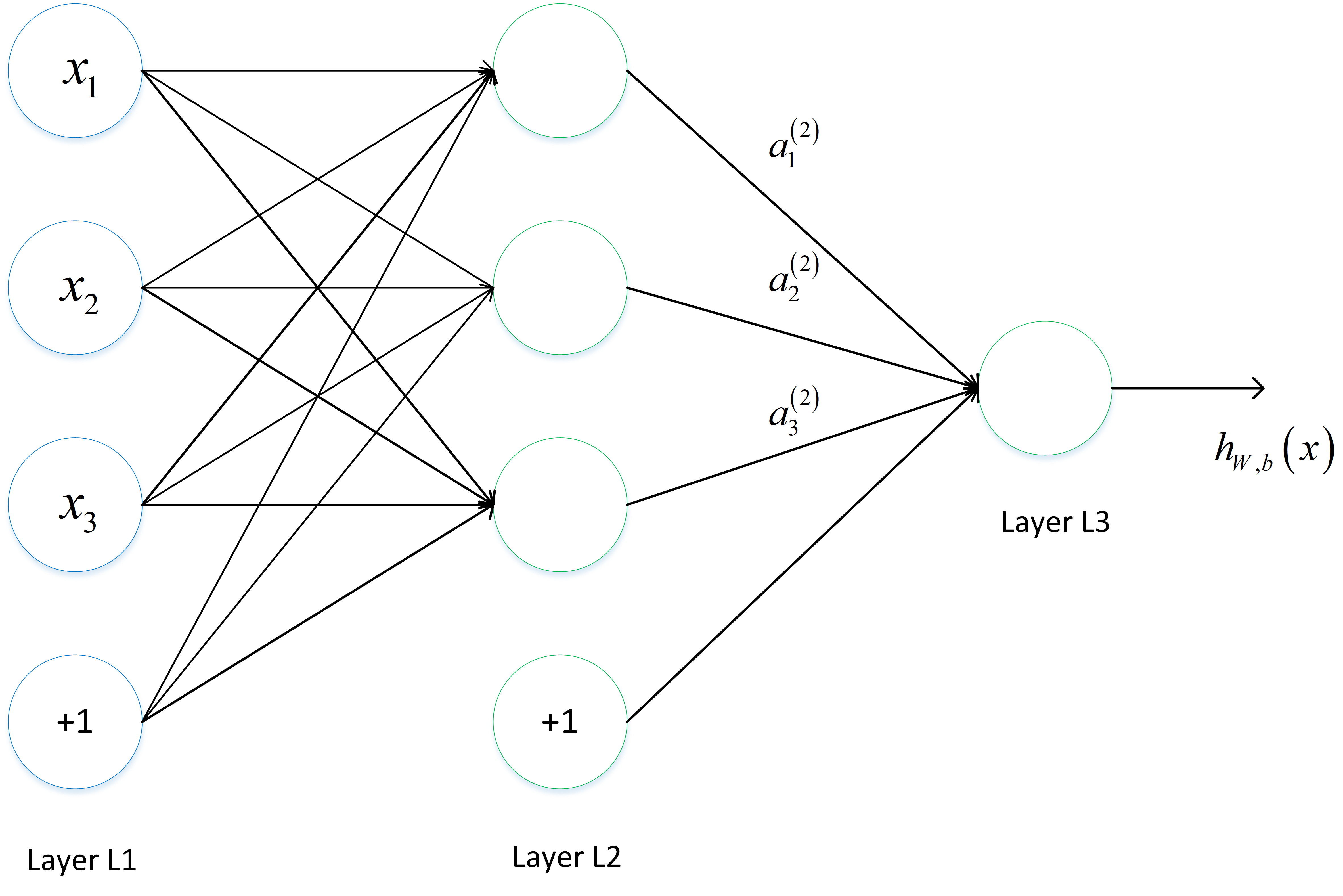
它的表达式为:
a 1 ( 2 ) = f ( W 11 ( 1 ) x 1 + W 12 ( 1 ) x 2 + W 13 ( 1 ) x 3 + b 1 ( 1 ) ) a_1^{(2)} = f(W_{11}^{(1)} x_1 + W_{12}^{(1)} x_2 + W_{13}^{(1)} x_3 + b_1^{(1)}) a1(2)=f(W11(1)x1+W12(1)x2+W13(1)x3+b1(1))
a 2 ( 2 ) = f ( W 21 ( 1 ) x 1 + W 22 ( 1 ) x 2 + W 23 ( 1 ) x 3 + b 2 ( 1 ) ) a_2^{(2)} = f(W_{21}^{(1)} x_1 + W_{22}^{(1)} x_2 + W_{23}^{(1)} x_3 + b_2^{(1)}) a2(2)=f(W21(1)x1+W22(1)x2+W23(1)x3+b2(1))
a 3 ( 2 ) = f ( W 31 ( 1 ) x 1 + W 32 ( 1 ) x 2 + W 33 ( 1 ) x 3 + b 3 ( 1 ) ) a_3^{(2)} = f(W_{31}^{(1)} x_1 + W_{32}^{(1)} x_2 + W_{33}^{(1)} x_3 + b_3^{(1)}) a3(2)=f(W31(1)x1+W32(1)x2+W33(1)x3+b3(1))
h W , b ( x ) = a 1 ( 3 ) = f ( W 11 ( 2 ) a 1 ( 2 ) + W 12 ( 2 ) a 2 ( 2 ) + W 13 ( 2 ) a 3 ( 2 ) + b 1 ( 2 ) ) h_{W,b}(x) = a_1^{(3)} = f(W_{11}^{(2)} a_1^{(2)} + W_{12}^{(2)} a_2^{(2)} + W_{13}^{(2)} a_3^{(2)} + b_1^{(2)}) hW,b(x)=a1(3)=f(W11(2)a1(2)+W12(2)a2(2)+W13(2)a3(2)+b1(2))
x a 1 ( 2 ) = f ( W 11 ( 1 ) x 1 + W 12 ( 1 ) x 2 + W 13 ( 1 ) x 3 + b 1 ( 1 ) ) a 2 ( 2 ) = f ( W 21 ( 1 ) x 1 + W 22 ( 1 ) x 2 + W 23 ( 1 ) x 3 + xa_1^{(2)} = f(W_{11}^{(1)} x_1 + W_{12}^{(1)} x_2 + W_{13}^{(1)} x_3 + b_1{(1)})a_2{(2)} = f(W_{21}^{(1)} x_1 + W_{22}^{(1)} x_2 + W_{23}^{(1)} x_3 + xa1(2)=f(W11(1)x1+W12(1)x2+W13(1)x3+b1(1))a2(2)=f(W21(1)x1+W22(1)x2+W23(1)x3+
最后
🍅 硬核资料:关注即可领取PPT模板、简历模板、行业经典书籍PDF。
🍅 技术互助:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。
🍅 面试题库:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。
🍅 知识体系:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。
小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数初中级Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python爬虫全套学习资料》送给大家,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频
如果你觉得这些内容对你有帮助,可以添加下面V无偿领取!(备注:python)

{21}^{(1)} x_1 + W_{22}^{(1)} x_2 + W_{23}^{(1)} x_3 + b_2^{(1)}) a2(2)=f(W21(1)x1+W22(1)x2+W23(1)x3+b2(1))
a 3 ( 2 ) = f ( W 31 ( 1 ) x 1 + W 32 ( 1 ) x 2 + W 33 ( 1 ) x 3 + b 3 ( 1 ) ) a_3^{(2)} = f(W_{31}^{(1)} x_1 + W_{32}^{(1)} x_2 + W_{33}^{(1)} x_3 + b_3^{(1)}) a3(2)=f(W31(1)x1+W32(1)x2+W33(1)x3+b3(1))
h W , b ( x ) = a 1 ( 3 ) = f ( W 11 ( 2 ) a 1 ( 2 ) + W 12 ( 2 ) a 2 ( 2 ) + W 13 ( 2 ) a 3 ( 2 ) + b 1 ( 2 ) ) h_{W,b}(x) = a_1^{(3)} = f(W_{11}^{(2)} a_1^{(2)} + W_{12}^{(2)} a_2^{(2)} + W_{13}^{(2)} a_3^{(2)} + b_1^{(2)}) hW,b(x)=a1(3)=f(W11(2)a1(2)+W12(2)a2(2)+W13(2)a3(2)+b1(2))
x a 1 ( 2 ) = f ( W 11 ( 1 ) x 1 + W 12 ( 1 ) x 2 + W 13 ( 1 ) x 3 + b 1 ( 1 ) ) a 2 ( 2 ) = f ( W 21 ( 1 ) x 1 + W 22 ( 1 ) x 2 + W 23 ( 1 ) x 3 + xa_1^{(2)} = f(W_{11}^{(1)} x_1 + W_{12}^{(1)} x_2 + W_{13}^{(1)} x_3 + b_1{(1)})a_2{(2)} = f(W_{21}^{(1)} x_1 + W_{22}^{(1)} x_2 + W_{23}^{(1)} x_3 + xa1(2)=f(W11(1)x1+W12(1)x2+W13(1)x3+b1(1))a2(2)=f(W21(1)x1+W22(1)x2+W23(1)x3+
最后
🍅 硬核资料:关注即可领取PPT模板、简历模板、行业经典书籍PDF。
🍅 技术互助:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。
🍅 面试题库:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。
🍅 知识体系:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。
小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数初中级Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python爬虫全套学习资料》送给大家,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频
如果你觉得这些内容对你有帮助,可以添加下面V无偿领取!(备注:python)
[外链图片转存中…(img-NysQ5SzJ-1711209874876)]















 821
821











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









