







最后的话
最近很多小伙伴找我要Linux学习资料,于是我翻箱倒柜,整理了一些优质资源,涵盖视频、电子书、PPT等共享给大家!
资料预览
给大家整理的视频资料:
给大家整理的电子书资料:

如果本文对你有帮助,欢迎点赞、收藏、转发给朋友,让我有持续创作的动力!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
model.add(Dense(1))
model.add(Activation(‘sigmoid’))
model.compile(loss=‘binary_crossentropy’,optimizer=‘rmsprop’)
Pad sequence where sequences are case insensitive characters encoded to integers from 0 to number of valid characters
X_train=sequence.pad_sequences(X_train,maxlen=75)
Train where y_train is 0-1
model.fit(X_train, y_train,batch_size=batch_size, nb_epoch=1)
多分类:
from keras.preprocessing import pad_sequences
from keras.models import Sequential
from keras.layers.core import Dense
from keras.layers.core import Dropout
from keras.layers.core import Activation
from keras.layers.embeddings import Embedding
from keras.layers.recurrent import LSTM
model=Sequential()
model.add(Embedding(max_features,128,input_length=75))
model.add(LSTM(128))
model.add(Dropout(0.5))
nb_classes is the number of classes in the training set
model.add(Dense(nb_classes))
model.add(Activation(‘softmax’))
model.compile(loss=‘categorical_crossentropy’,optimizer=‘rmsprop’)
Pad sequence where sequences are case insensitive characters encoded to integers from 0 to number of valid characters
X_train=sequence.pad_sequences(X_train,maxlen=75)
Train where y_train is one-hot encoded for each class
model.fit(X_train, y_train,batch_size=batch_size, nb_epoch=1)
###### CMU Model
基于工作:Tweet2vec: Character-based distributed representations for social media [4](#fn4)
结构:Bi-directional LSTM
main_input = Input(shape=(75, ), dtype=‘int32’, name=‘main_input’)
embedding = Embedding(input_dim=128, output_dim=128,input_length=75)
bi_lstm = Bidirectional(layer=LSTM(64,return_sequences=False),merge_mode=‘concat’)
output = Dense(1, activation=‘sigmoid’)
model = Model(inputs=main_input, outputs=output)
model.compile(loss=‘binary_crossentropy’, optimizer=‘adam’)
###### 原文延申
`以下为笔者补充认为原文引文中有参考价值的材料,本文为社交网络语言分析项目,主要思考该模型可迁移至DGA检测领域的合理性,对神经网络基本架构及原理熟悉的丹师可跳过。`
《Tweet2vec: Character-based distributed representations for social media》
**摘要**:主要解决非正式网络用语、拼写错误、缩写、特殊字符(表情)带来的相关问题,比如OOV、基于单词级字典存储空间过大等。
**介绍**:
开源地址:https://github.com/bdhingra/tweet2vec
简述了NLP脉络,以及将推文的hashtags用作文本有监督学习表示的合理性(学习到的词嵌入可以应用在其他任务中,并取得不错的效果)。
**模型**:GRU
**结论**:对比基线(1.预处理统一删除了tag、字母替换为小写、将用户名与url替换为特殊字符、删除数据集中的转发贴 2.空格进行分词token),该模型对常见词文本的预测性能略好,而罕见词文本预测可以涨12~15个点,代价则是GRU基于字符级的序列更长,增加了训练时间。
##### 2.基于CNN
###### NYU Model
基于工作:Character-level Convolutional Networks for Text Classification [5](#fn5)
结构:CNN
main_input = Input(shape=(75, ), dtype=‘int32’, name=‘main_input’)
embedding = Embedding(input_dim=128, output_dim=128,input_length=75)
conv1 = Conv1D(filters=128, kernel_size=3, padding=‘same’, strides=1)
thresh1 = ThresholdedReLU(1e-6)
max_pool1 = MaxPooling1D(pool_size=2, padding=‘same’)
#最大值池化,训练更深层网络
conv2 = Conv1D(filters=128, kernel_size=2, padding=‘same’, strides=1)
thresh2 = ThresholdedReLU(1e-6)
max_pool2 = MaxPooling1D(pool_size=2, padding=‘same’)
flatten = Flatten()
fc = Dense(64)
thresh_fc = ThresholdedReLU(1e-6)
drop = Dropout(0.5)
output = Dense(1, activation=‘sigmoid’)
model = Model(inputs=main_input, outputs=output)
model.compile(loss=‘binary_crossentropy’, optimizer=‘adam’)
###### 原文延申
`以下为笔者补充认为原文引文中有参考价值的材料,本文为文本分类任务模型对比文章,主要思考该模型可迁移至DGA检测领域的合理性,对神经网络基本架构及原理熟悉的丹师可跳过。`
《Character-level Convolutional Networks for Text Classification》
**摘要**:文章工作将ConvNets(character-level CNN)的文本分类表现与BOW、n-grams、TFIDF变体、word-level RNN进行对比实验。
**模型**:character-level CNN
**样本侧数据增强**:使用同义词替换的方法做了数据增强,具体选词用了WordNet对同义词排名,得出同义程度由高至低的索引
i
i
i ,并使用几何分部概率进行选取
P
(
w
o
r
d
i
)
∼
q
i
P(word\_i)\sim q^i
P(wordi)∼qi,则索引越后,替换词与原词越不同义,被选作替换的可能性越小。总体步骤为:
1.从原句中提取所有可以用同义词进行替换的单词(数据来源:[LibreOffice Project mytheas component——English sysnonyms thesaurus]( ))
2.从全部可替换词中随机选取
r
r
r个,同样使用几何分部概率确定该词是否要保留原词,
P
(
N
u
m
b
e
r
r
)
∼
q
r
P(Number\_r)\sim q^r
P(Numberr)∼qr。(此处应有更多流程细节,如
r
r
r在不同句子同义词替换取值范围情况,但原文没有详细说明)
3.进行同义替换。
>
> 此处稍微吐槽一下原文Sogou news corpus数据集中:“Although this is a dataset in Chinese, we used pypinyin package combined with jieba Chinese segmentation system to produce Pinyin – a phonetic romanization of Chinese.The models for English can then be applied to this dataset without change. ”
> 原来pinyin和英语没有domain gap,就emmmm,看到这差点弃了。虽然说文章不是验证某种语言任务看似无伤大雅,但也不能过于泛化。
> 最后这篇文章的结论,推导出的结论个人感觉不要严谨没有抓住想说明问题的核心,部分陈述没有太大价值,此处就省略了,数据集也不做介绍了,原文自建了8个数据集,来得出关于ConvNets的优势/解释性。
>
>
>
###### Invincea Model
基于工作:eXpose: A character-level convolutional neural network with embeddings for detecting malicious urls, file paths and registry keys [6](#fn6)
结构:CNN
def getconvmodel(self, kernel_size, filters):
model = Sequential()
model.add(Conv1D(filters=filters, input_shape=(128,128), kernel_size=kernel_size,padding=’same’,activation=’relu’,strides=1))
model.add(Lambda(lambda x: K.sum(x, axis=1),output_shape=(filters, )))
model.add(Dropout(0.5))
return model
main_input = Input(shape=(75, ), dtype=‘int32’, name=‘main_input’)
embedding = Embedding(input_dim=128, output_dim=128,input_length=75)
conv1 = getconvmodel(2, 256)
conv2 = getconvmodel(3, 256)
conv3 = getconvmodel(4, 256)
conv4 = getconvmodel(5, 256)
merged = Concatenate()([conv1, conv2, conv3, conv4])
middle = Dense(1024, activation=‘relu’)
middle = Dropout(0.5)
middle = Dense(1024, activation=‘relu’)
middle = Dropout(0.5)
output = Dense(1, activation=‘sigmoid’)
model = Model(inputs=main_input, outputs=output)
model.compile(loss=‘binary_crossentropy’, optimizer=‘adam’)
###### 原文延申
`以下为笔者补充认为原文引文中有参考价值的材料,本文为文本分类任务模型对比文章,主要思考该模型可迁移至DGA检测领域的合理性,对神经网络基本架构及原理熟悉的丹师可跳过。`
《eXpose: A character-level convolutional neural network with embeddings for detecting malicious urls, file paths and registry keys》
**简介**:作者使用CNN架构,直接输入字符串使用模型自动学习特征,来检测恶意URL、文件路径、注册表键名。其中恶意URL直接检测,若不附带额外的信息(网站注册、网页内容、网络信誉等额外成本),笔者看来还是明显存在如:[ATLAS——对抗性机器学习威胁矩阵<案例研究一>]( )中出现的问题,易于绕过。但笔者认同作者提到的一个观点:该模型能力与传统手工特征/上下文/情报模型是正交互补的。用两种不同方式提取特征进行能力的覆盖,DL提取特征可更快速检出自动化程序生成的恶意资源名称并更快部署,手动方式拥有很好的物理解释给推理结果溯源,而如何去检验当两种模型结果出现冲突时,发现误报并提升人工确认的效率也很值得思考。
| 类型 | 数据样例 | 有效字符数 | dropout参数 |
| --- | --- | --- | --- |
| 恶意URL | http:\0fx8o.841240.cc\201610\18\content\_23312\svchost.exehttp:\31.14.136.202\secure.apple.id.login\Apple\login.phphttp:\1stopmoney.com\paypal-login-secure\websc.php | 87 | 0.5 |
| 恶意文件路径 | C:\Temp\702D97503A79B0EC69\JUEGOS/Call of Duty 4+KeygenC:\Temp\svchost.vbsC:\DOCUME1\BASANT1\LOCALS~1\Temp\WzEC.tmp\fax.doc.exe | 100 | 0.5 |
| 恶意注册表键名 | HKCU\Software\Microsoft\Windows\CurrentVersion\Run Alpha AntivirusHKCR\Applications\WEBCAM HACKER 1.0.0.4.EXEHKCR\AppID\bccicabecccag.exe | 100 | 0.2 |

图八 原文模型框架
##### 3.基于CNN/RNN混合结构
###### MIT Model
基于工作:Tweet2vec: Learning tweet embeddings using character-level cnn-lstm encoder-decoder [7](#fn7)
结构:CNN-LSTM
该模型是基于NYU model的拓展改造,其中原文的实现叠套了多层CNN,而在DGA的检测中仅保留了一层,并也接入了一层LSTM进行实现,查看效果。
main_input = Input(shape=(75, ), dtype=‘int32’, name=‘main_input’)
embedding = Embedding(input_dim=128, output_dim=128,input_length=75)
conv = Conv1D(filters=128, kernel_size=3, padding=‘same’, activation=‘relu’, strides=1)
max_pool = MaxPooling1D(pool_size=2, padding=‘same’)
encode = LSTM(64, return_sequences=False)
output = Dense(1, activation=‘sigmoid’)
model = Model(inputs=main_input, outputs=output)
model.compile(loss=‘binary_crossentropy’, optimizer=‘adam’)
###### 原文延申
`以下为笔者补充认为原文引文中有参考价值的材料,本文为文本分类任务模型对比文章,主要思考该模型可迁移至DGA检测领域的合理性,对神经网络基本架构及原理熟悉的丹师可跳过。`
《Tweet2vec: Learning tweet embeddings using character-level cnn-lstm encoder-decoder 》
**模型**:CNN\_LSTM
encoder:卷积层-提取特征;LSTM层-编码
decoder:两个LSTM层-解码,用于预测
字符集数量:70个;数据集推文数量:300万条;
流程:输入
一维卷积——4层;参数:滑动窗口大小l,过滤器
w
∈
R
l
w \in R^l
w∈Rl
一维最大池化——一层;参数:pooling size,过滤器数量n;作用:缩小特征表达的大小,过滤去除琐碎的特征,如不必要的字母组合。
经过最后一层卷积后,得到10\*512输出,作为lstm输入。最后lstm编码结果输出表示全部推文,大小为row \*256。最终输入解码器,得到t时刻的字母预测值。

图九 原文模型框架
**样本侧数据增强**:复数推文-复制一遍原文,并使用同义词替换当中可被替换的词语。(WordNet,增强方法同NYU Model,不赘述,其中两个几何分布参数选取:p=0.5,r=0.5)
**实验**:
语义相似分类任务(竞赛):SemEval 2015-Task 1:Paraphrase and Semantic Similarity in Twitter;输入:一组推文;输出:是否相似(二分类)。数据集:训练-18000推文对,测试-1000推文对;其中35%为释义对,65%为非释义对。过程:讲推文对输入tweet2vet模型,得到一组向量表示r,s,计算点积r·s以及绝对差|r-s|,并拼接两个结果作为这一组推文对的表示。最后进行逻辑回归和交叉验证优化参数。结论:与该竞赛前4名模型相比,该模型f1得分最高。
情感分类任务(竞赛):SemEval 2015-Task10B:Twitter Message Polarity Classification;输入:一条推文;输出:积极、消极、中立(三分类)。数据集:训练-9520,测试-2380(样本标签比例相同:积极-38%,消极-15%,中立47%)。竞赛评分特殊性:该任务得分仍为判断消极与积极两类的准确性,实际是二分类作为模型的评分标准,仍使用f1得分衡量。结论:与该竞赛前4名模型相比,该模型f1得分最高。
**模型后续优化方向**:1.数据增强方面,打乱样本的语序来增强鲁棒性。2.增加注意力机制来改进解码过程中推文单词对齐问题(笔者也将在后续补充注意力机制模型应用与DGA检测的文章阅读整理与实验)。
>
> 笔者总结:文章的总体工作为实验性综述,并将已有的模型调优,统一环境进行实验对比总结得出**核心结论**。第二部分背景中最后提到了**GANs**做**数据增强**,然后应用到分类模型中,确实是值得继续深入的方向。
> 其实DGA的逻辑有很多种,使用机器学习方法最易检出非基于字典类型的不正常域名,但仅从文本信息中,却难以发现生成算法本身逻辑是否是与时间相关/有确定性的,如Bedep以欧洲中央银行每天发布的外汇参考汇率作为种子,Torpig用Twitter的关键词作为种子,只有在确定时间窗口内注册域名才能生效。此外基于字典的DGA检测难度大,如matsnu由于样本数量少即使是lstm架构也无法检出,但是训练样本大于matsnu20倍的suppobox却可以做出一定的判断。所以基于词典的DGA,理论上数据集收集越多,覆盖词典越全越接近DGA结果的真实生成域名分布,那么准确率也将得到更多提升。
> 我们需要进一步思考,针对不同的DGA,哪些可以完全脱离人工提权特征进行检测,哪些仍然需要上下文及其他信息补充。如果这样实现了防御,作为攻击者不能完全绕过检测,开发DGA时是否可以通过利用特征分析/模型retrain等的时间差、使用一些花指令等恶意软件开发上的技巧扩大存活时间来增强攻击影响。作为防御方,考虑DGA家族之间的联系(如Conficker, Murofet, Bobax,Sinowal.)来进一步完善数据集,合理增加一些额外信息也有不错的效果。
>
>
>
>
> ~~些许头秃~~ 心路历程:开始觉得一共8页文章,会比上一篇案例更快读完,结果五个模型介绍细节都高度概括,虽然对熟悉各种神经网络架构的老丹师so easy,但还是想让博文脉络更全面一些。挖下去后,每个references原文有十几页hhh,果然填坑还是要做好心理建设。
>
>
>
## 绕过实验复现
靶环境项目指路:<https://github.com/matthoffman/degas>
>
> 笔者由于工作原因,投入时间较少,复现简单粗糙,不严谨之处欢迎指正。
>
>
>
### 部署使用
该项目信息与功能非常全面,也易于部署实验。先根据提供的requirements.txt建立conda-env,激活切换至该环境。执行download-data指令,下载数据集。
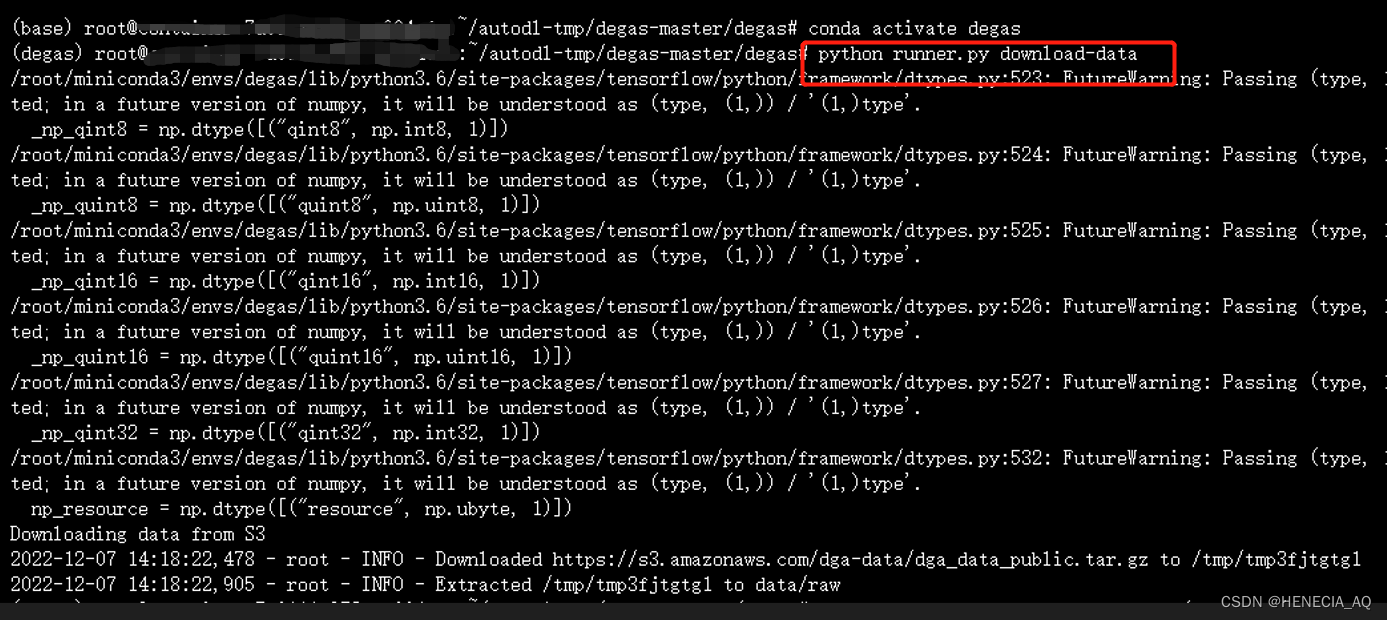
图十 开源数据集文件
下载完毕后,执行数据集处理
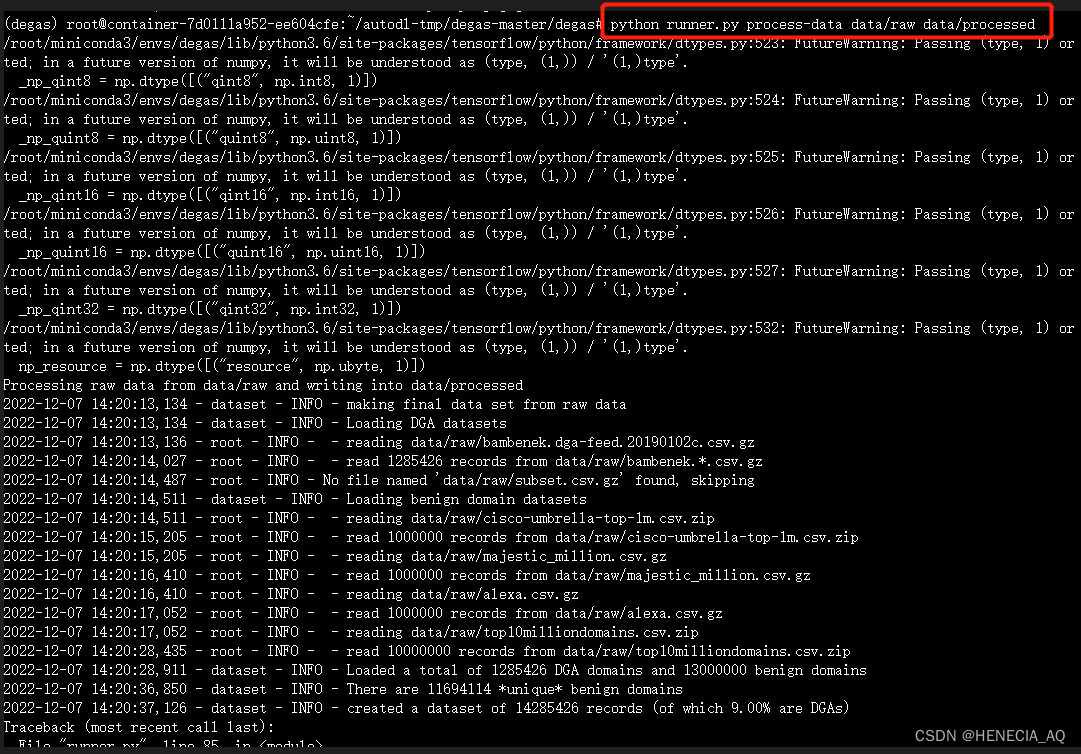
处理完后,数据统一标记标签,1-恶意,0-正常。

图十一 开源数据集汇总处理文件
开始训练,不调节默认参数是num\_epochs=100, kfold\_splits=2, batch\_size=256, max\_length=75。
#### 服务器端
##### docker+mac m1无法部署
执行指令:
docker run -p 8501:8501 \
–mount type=bind,source=【文件路径】/degas/models/degas,target=/models/degas
-e MODEL_NAME=degas -t tensorflow/serving
报错:
[libprotobuf ERROR external/com_google_protobuf/src/google/protobuf/descriptor_database.cc:560] Invalid file descriptor data passed to EncodedDescriptorDatabase::Add().
[libprotobuf FATAL external/com_google_protobuf/src/google/protobuf/descriptor.cc:1986] CHECK failed: GeneratedDatabase()->Add(encoded_file_descriptor, size):
找到靶环境对应版本:
tensorflow 1.12 --------------- protobuf 3.6
mac更新protobuf 3.6
pip install protobuf==3.6
仍然报错,执行查看protoc版本,发现libprotoc==3.18:
which protoc
protoc --version
修改为统一版本,仍然报错,出现qemu: uncaught target signal 6 (Aborted) - core dumped。它是我们用于在 M1 芯片上运行英特尔容器的上游组件,这个issue 尚未解决。由于部分源码函数制定版本tf才有,所以无法用此方法部署。
##### docker+ubuntu18.04部署
##### 云环境
把docker装好后直接跑服务。

图十二 服务器端
重新启动后遇到`docker: Error response from daemon: driver failed programming external connectivity` 问题,直接重启`systemctl restart docker`解决。
#### 客户端
模拟请求,返回推理结果。
刚开始以为直接post域名就可以预测,结果报错:

图十三 请求报错
说输入string不行,支持int32,又试了试以为直接输入到字典转换的domain\_to\_ints(domain: str) ,就可以正确输出,结果也是报错,仔细看一下后面的报错原因,[n,1,128]的size,找到helper里面的prep\_data(data: np.ndarray, max\_length=75)填充到128。
结果如下可以试一试,进行推理预测,可见大部分正确及恶意域名还是得以识别的。

图十四 www.baidu.com预测结果

图十五 fghjygsuhbjiusfjwj.cn(笔者随便造的)预测结果
补充的转换脚本如下,大家可以加入到项目的./degas/degas/model目录中。
import degas.model.helpers as helper
import numpy as np
result1=str(helper.prep_data([“www.baidu.com”])).replace(" “,”,")
result2=str(helper.prep_data([“fghjygsuhbjiusfjwj.cn”]))#逗号替换replace根据数据调整
### 源码解析
#### runner.py
下载部分:从默认网址下下来,存到默认raw路径里。
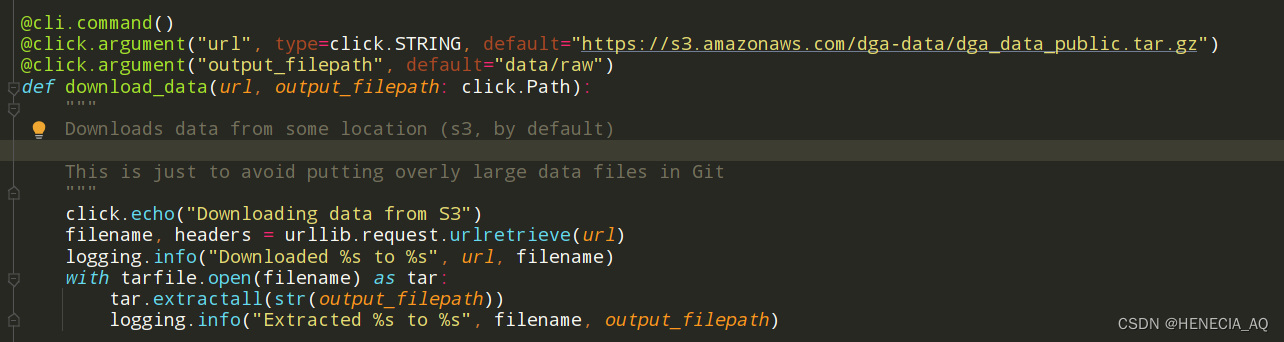
处理部分:然后开始处理成统一格式,默认从raw路径里面拿,处理完丢processed里。

调用训练模型部分:数据集默认从process中取,epochs默认100,kfold默认3。

服务部分:可以设置默认端口,service里面有简单的flask,使用方法可以看看tensorflow的官网,指路:[Tensorflow Serving]( )。(官网版本可能更新,链接失效可直接搜索关键词)

#### train.py
模型原理和详情见上文提及的基于CNN的NYU Model。

回调函数,早停防止过拟合,保存模型,监控loss降低学习率。

单独把fit封装为一个函数,没有直接写进run里。

主要三步是,build->fit->export。

逻辑流程:

图十六 train.py流程
#### predict.py
读取模型版本及其路径如图所示,然后进行预测。

#### helpers.py
数据预处理的部分,域名输入后统一转换成小写,然后根据字典转换成int32。


#### api.py
docker服务端起起来后,可以根据这个路径验证相应的问题。常见遇到:访问/v1返回not found、访问/v1/models/degas/1

### 攻击思路
ATLAS说用到对抗变异算法,所以没指明该攻击方法的隐蔽性。
我们从整体模型构建、采集数据、训练、部署的大阶段思路开始。dga生成模块嵌入对抗式模型,进行绕过。以该模型为例,数据集采用开源数据集,使用相同数据集做基础的对抗训练,是一种思路。
但具体应该如何设计呢?若模型输出了将数据集中label为0的正常数据集是无法作为恶意域名实现解析目的的,会在攻击模型输出时进行过滤,则若模型输出了label为1的实际也是需要被过滤掉的。若传统的生成方法可以绕过基于情报等检测的安全设备,那么如何训练一个输出结果不在现有域名中,又要生成像label=0不像label=1的模型?
绕过的域名形式,显然生成得越正常越好。任务是:“请帮我生成一个看似正常实际不存在的域名”,我想现在大模型的方式也可以做,如果恶意软件能联网的话,我想也能有较大几率绕过此类离线更新的模型(也变成了迭代博弈)。
### 攻击结果
基于词典生成的方式,还是很好绕过的。下面是apple123.cn(笔者随手写的,访问一下发现打码内容,嗯)的预测结果,基本接近于0判断为良性。

图十七 apple123.cn成功绕过
## 后话
### 应用落地分享
恰好笔者工作隔壁组,将LSTM+Attention架构的DGA检测模型落地,并真实地部署在了产品中,在各个客户现场得到应用。本文拓展地分享一下和隔壁组大佬学习交流的一些相关知识。
参考文献:**Attention-based LSTM for Aspect-level Sentiment Classification**
起初看到使用这个架构的时候,第一反应是,为什么LSTM后面要加注意力机制?加了涨点幅度有多大?对于该模型迁移至DGA检测场景究竟有多契合,如何解释?像atlas.mitre提出的案例所示,其实用上文提到的一些模型就已经能达到比较高的准确性,处于什么样的考虑?真正在客户现场的表现如何?产品侧又是怎样设计来使用这个检出功能,来使模型的应用更加合理?
案例一也留了一个坑,那案例二也开个坑,继续总结LSTM-Attention架构。如果大家想了解可以交流,后面再出一篇总结梳理。
>
> 上述材料仅供学习,请不要攻击实际生产的AI系统!
> 练习请自行搭建AI靶场。
>
>
>
>
> 最后给大家安利一个租卡平台:
> autoDL:<https://www.autodl.com>
> 一个非常好上手的平台,易用性高,帮助文档也非常详细,小白也可以快速搭建起环境,然后开始快乐炼丹。客服也非常有耐心解答相关问题。
> 各位老板也可以填一下我的邀请码:<https://www.autodl.com/register?code=4bacd9d2-d4bf-4baf-82c9-7b935986a34d>,可以获得十元代金卷试用。(也可以让我薅薅AutoDL羊毛,btw:诚心非广,本菜狗还不配)
>
>
>
---
1. [Case Studies]( ) [↩︎](#fnref1)
2. [degas]( ) [↩︎](#fnref2)
3. [Predicting domain generation algorithms with long short-term memory networks]( ) [↩︎](#fnref3)
4. [Tweet2vec: Character-based distributed representations for social media]( ) [↩︎](#fnref4)
5. [Character-level Convolutional Networks for Text Classification]( ) [↩︎](#fnref5)
6. [eXpose: A character-level convolutional neural network with embeddings for detecting malicious urls, file paths and registry keys]( ) [↩︎](#fnref6)
7. [Tweet2vec: Learning tweet embeddings using character-level cnn-lstm encoder-decoder]( ) [↩︎](#fnref7)
为了做好运维面试路上的助攻手,特整理了上百道 **【运维技术栈面试题集锦】** ,让你面试不慌心不跳,高薪offer怀里抱!
这次整理的面试题,**小到shell、MySQL,大到K8s等云原生技术栈,不仅适合运维新人入行面试需要,还适用于想提升进阶跳槽加薪的运维朋友。**

本份面试集锦涵盖了
* **174 道运维工程师面试题**
* **128道k8s面试题**
* **108道shell脚本面试题**
* **200道Linux面试题**
* **51道docker面试题**
* **35道Jenkis面试题**
* **78道MongoDB面试题**
* **17道ansible面试题**
* **60道dubbo面试题**
* **53道kafka面试**
* **18道mysql面试题**
* **40道nginx面试题**
* **77道redis面试题**
* **28道zookeeper**
**总计 1000+ 道面试题, 内容 又全含金量又高**
* **174道运维工程师面试题**
> 1、什么是运维?
> 2、在工作中,运维人员经常需要跟运营人员打交道,请问运营人员是做什么工作的?
> 3、现在给你三百台服务器,你怎么对他们进行管理?
> 4、简述raid0 raid1raid5二种工作模式的工作原理及特点
> 5、LVS、Nginx、HAproxy有什么区别?工作中你怎么选择?
> 6、Squid、Varinsh和Nginx有什么区别,工作中你怎么选择?
> 7、Tomcat和Resin有什么区别,工作中你怎么选择?
> 8、什么是中间件?什么是jdk?
> 9、讲述一下Tomcat8005、8009、8080三个端口的含义?
> 10、什么叫CDN?
> 11、什么叫网站灰度发布?
> 12、简述DNS进行域名解析的过程?
> 13、RabbitMQ是什么东西?
> 14、讲一下Keepalived的工作原理?
> 15、讲述一下LVS三种模式的工作过程?
> 16、mysql的innodb如何定位锁问题,mysql如何减少主从复制延迟?
> 17、如何重置mysql root密码?
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以点击这里获取!](https://bbs.csdn.net/topics/618635766)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
+ 道面试题, 内容 又全含金量又高**
* **174道运维工程师面试题**
> 1、什么是运维?
> 2、在工作中,运维人员经常需要跟运营人员打交道,请问运营人员是做什么工作的?
> 3、现在给你三百台服务器,你怎么对他们进行管理?
> 4、简述raid0 raid1raid5二种工作模式的工作原理及特点
> 5、LVS、Nginx、HAproxy有什么区别?工作中你怎么选择?
> 6、Squid、Varinsh和Nginx有什么区别,工作中你怎么选择?
> 7、Tomcat和Resin有什么区别,工作中你怎么选择?
> 8、什么是中间件?什么是jdk?
> 9、讲述一下Tomcat8005、8009、8080三个端口的含义?
> 10、什么叫CDN?
> 11、什么叫网站灰度发布?
> 12、简述DNS进行域名解析的过程?
> 13、RabbitMQ是什么东西?
> 14、讲一下Keepalived的工作原理?
> 15、讲述一下LVS三种模式的工作过程?
> 16、mysql的innodb如何定位锁问题,mysql如何减少主从复制延迟?
> 17、如何重置mysql root密码?
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化的资料的朋友,可以点击这里获取!](https://bbs.csdn.net/topics/618635766)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 569
569











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









