







“User-Agent”: “Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.99 Safari/537.36”,
“Host”: “mp.weixin.qq.com”,
“Referer”: “https://mp.weixin.qq.com/cgi-bin/appmsg?t=media/appmsg_edit&action=edit&type=10&isMul=1&isNew=1&lang=zh_CN&token=1862390040”,
“Cookie”: “自己获取信息时的cookie”
}
def getInfo():
for i in range(80):
token random 需要要自己的 begin:参数传入
url = “https://mp.weixin.qq.com/cgi-bin/appmsg?token=1904193044&lang=zh_CN&f=json&ajax=1&random=0.9468236563826882&action=list_ex&begin={}&count=5&query=&fakeid=MzI4MzkzMTc3OA%3D%3D&type=9”.format(str(i * 5))
response = requests.get(url, headers = headers)
jsonRes = response.json()
titleList = jsonpath.jsonpath(jsonRes, “$…title”)
coverList = jsonpath.jsonpath(jsonRes, “$…cover”)
urlList = jsonpath.jsonpath(jsonRes, “$…link”)
遍历 构造可存储字符串
for index in range(len(titleList)):
title = titleList[index]
cover = coverList[index]
url = urlList[index]
scvStr = “%s,%s, %s,\n” % (title, cover, url)
with open(“info.csv”, “a+”, encoding=“gbk”, newline=‘’) as f:
f.write(scvStr)
获取结果(成功):

通过对单篇视频文章分析,我找到了这个链接:
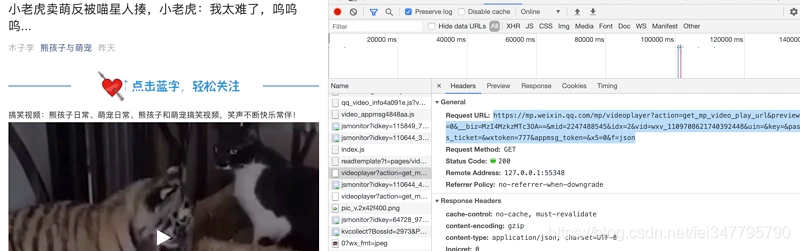
通过网页打开发现,是视频的网页下载链接:

哎,好像有点意思了,找到了视频的网页纯下载链接,那就开始吧。
发现链接里的有一个关键参数vid 不知道哪来的?
和获取到的其他信息也没有关系,那就只能硬来了。
通过对单文章的url请求信息里发现了这个参数,然后进行获取。
response = requests.get(url_wxv, headers=headers)
我用的是正则,也可以使用xpath
jsonRes = response.text # 匹配:wxv_1105179750743556096
dirRe = r"wxv_.{19}"
result = re.search(dirRe, jsonRes)
wxv = result.group(0)
print(wxv)
视频下载:
def getVideo(video_title, url_wxv):
video_path = ‘./videoFiles/’ + video_title + “.mp4”
页面可下载形式
video_url_temp = “https://mp.weixin.qq.com/mp/videoplayer?action=get_mp_video_play_url&preview=0&__biz=MzI4MzkzMTc3OA==&mid=2247488495&idx=4&vid=” + wxv
response = requests.get(video_url_temp, headers=headers)
content = response.content.decode()
content = json.loads(content)
url_info = content.get(“url_info”)
video_url2 = url_info[0].get(“url”)
print(video_url2)
请求要下载的url地址
html = requests.get(video_url2)
content返回的是bytes型也就是二进制的数据。
html = html.content
with open(video_path, ‘wb’) as f:
f.write(html)
那么所有信息就都完成了,进行code组装。
a、获取公众号信息
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以扫码获取!!!(备注Python)
9.png)
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以扫码获取!!!(备注Python)
















 7923
7923











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









