






第 1 章 Hive 入门
1.1 什么是 Hive
1) Hive 简介
Hive是由Facebook开源,基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类SQL查询功能。
2) Hive 本质
Hive是一个Hadoop客户端,用于将HQL(Hive SQL)转化成MapReduce程序。
(1)Hive中每张表的数据存储在HDFS
(2)Hive分析数据底层的实现是MapReduce(也可配置为Spark或者Tez)
(3)执行程序运行在Yarn上
1.2 Hive 架构原理
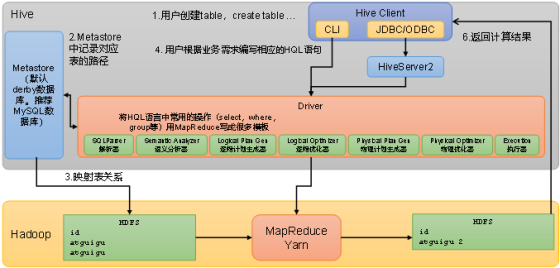
1) 用户接口: Client
CLI(command-line interface)、JDBC/ODBC。
2) 元数据: Metastore
元数据包括:数据库(默认是default)、表名、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等。
3) 驱动器: Driver
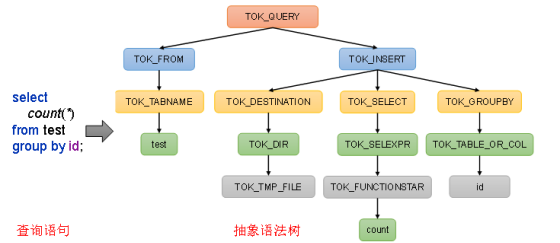
(1)解析器(SQLParser):将SQL字符串转换成抽象语法树(AST)
(2)语义分析(Semantic Analyzer):将AST进一步划分为QeuryBlock
(3)逻辑计划生成器(Logical Plan Gen):将语法树生成逻辑计划
(4)逻辑优化器(Logical Optimizer):对逻辑计划进行优化
(5)物理计划生成器(Physical Plan Gen):根据优化后的逻辑计划生成物理计划
(6)物理优化器(Physical Optimizer):对物理计划进行优化
(7)执行器(Execution):执行该计划,得到查询结果并返回给客户端
抽象语法树
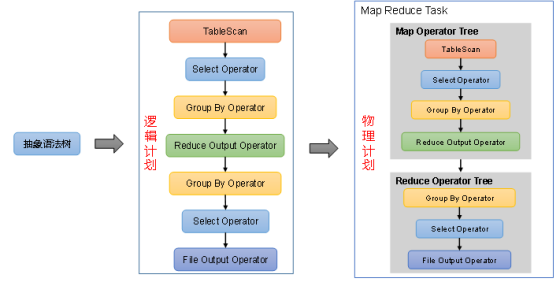
逻辑计划与物理计划
4) Hadoop
使用HDFS进行存储,可以选择MapReduce/Tez/Spark进行计算。
第 2 章 Hive 安装
不做过多了解
2.4 配置 Hive 元数据到Mysql
Hive元数据存储到Mysql

2.5 Hive 服务部署
2.5.1 hiveserver2 服务
Hive的hiveserver2服务的作用是提供jdbc/odbc接口,为用户提供远程访问Hive数据的功能,例如用户期望在个人电脑中访问远程服务中的Hive数据,就需要用到Hiveserver2。

1)用户说明
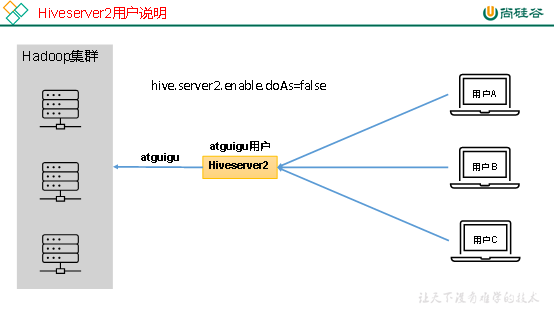
开启用户模拟功能:

生产环境,推荐开启用户模拟功能,因为开启后才能保证各用户之间的权限隔离。
2.5.2 metastore 服务
Hive的metastore服务的作用是为Hive CLI或者Hiveserver2提供元数据访问接口。
metastore有两种运行模式,分别为嵌入式模式和独立服务模式。下面分别对两种模式进行说明:
1.嵌入式模式

2.独立服务模式
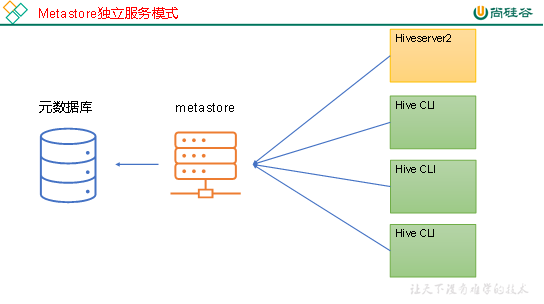
生产环境中,不推荐使用嵌入式模式。因为其存在以下两个问题:
(1)嵌入式模式下,每个Hive CLI都需要直接连接元数据库,当Hive CLI较多时,数据库压力会比较大。
(2)每个客户端都需要用户元数据库的读写权限,元数据库的安全得不到很好的保证。
griddate的介绍:
点击 + 号创建数据库:
里面的Host填写IP地址,如果电脑上的映射文件该好了,可以填写映射的映射名

这个console文件保存在这里:
2.6 Hive 使用技巧
2.6.1 Hive 常用交互命令
没进到交互式页面,如何使用交互式指令:
hive -e "insert into stu values(1,'aa');"

使用 hive -e 来使用交互式命令
使用hive -f 来使用交互式命令:
hive -f stu.sql
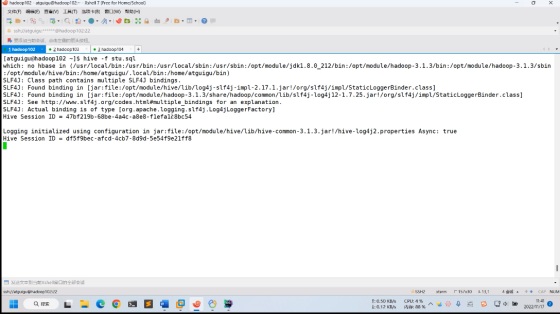
hive -f 是把Sql脚本命令保存到文件里进行使用
2.6.2 Hive 参数配置方式
参数配置的三种方式:
1) 配置文件方式:
2) 命令行参数方式:


3) 参数声明方式:

2.6.3 Hive 常见属性配置
1) Hive 客户端显示当前库和表头
(1) 在hive-site.xml中加入如下两个配置:
<property>
<name>hive.cli.print.header</name>
<value>true</value>
<description>Whether to print the names of the columns in query output.</description>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
<description>Whether to include the current database in the Hive prompt.</description>
</property>(2) hive 客户端在运行时可以显示当前使用的库和表头信息
hive (default)> select * from stu;
OK
stu.id stu.name
1 ss
Time taken: 1.874 seconds, Fetched: 1 row(s)
hive (default)>2) Hive 运行日志路径配置
(1) Hive 的 log 默认存放在/tmp/atguigu/hive.log 目录下 (当前用户名下)
[atguigu@hadoop102 atguigu]$ pwd
/tmp/atguigu
[atguigu@hadoop102 atguigu]$ ls
hive.log
hive.log.2022-06-27(2) 修改 Hive 的 log 存放日志到/opt/module/hive/logs
1修改$HIVE_HOME/conf/hive-log4j2.properties.template文件名称为
hive-log4j2.properties
[atguigu@hadoop102 conf]$ pwd
/opt/module/hive/conf
[atguigu@hadoop102 conf]$ mv hive-log4j2.properties.template hive-log4j2.properties2在hive-log4j2.properties文件中修改log存放位置
[atguigu@hadoop102 conf]$ vim hive-log4j2.properties修改配置如下
property.hive.log.dir=/opt/module/hive/logs3) Hive 的 JVM 堆内存设置
新版本的Hive启动的时候,默认申请的JVM堆内存大小为256M,JVM堆内存申请的太小,导致后期开启本地模式,执行复杂的SQL时经常会报错:java.lang.OutOfMemoryError: Java heap space,因此最好提前调整一下HADOOP_HEAPSIZE这个参数。
(1)修改$HIVE_HOME/conf下的hive-env.sh.template为hive-env.sh
[atguigu@hadoop102 conf]$ pwd
/opt/module/hive/conf
[atguigu@hadoop102 conf]$ mv hive-env.sh.template hive-env.sh(2)将hive-env.sh其中的参数 export HADOOP_HEAPSIZE修改为2048,重启Hive。
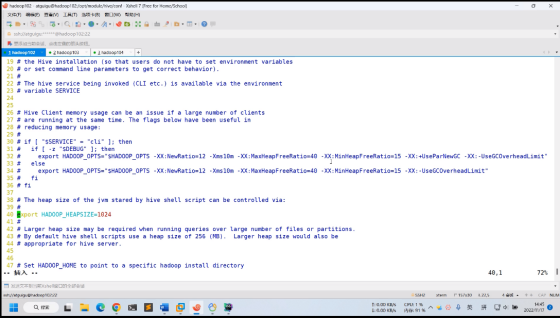
修改前
# The heap size of the jvm stared by hive shell script can be controlled via:
# export HADOOP_HEAPSIZE=1024修改后
# The heap size of the jvm stared by hive shell script can be controlled via:
export HADOOP_HEAPSIZE=2048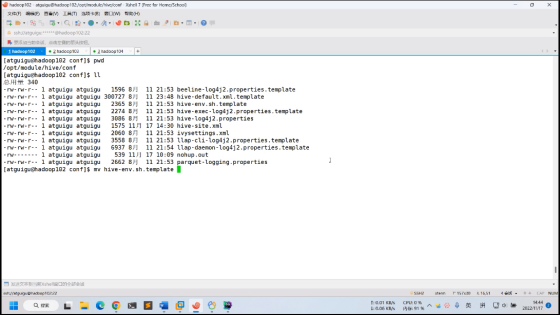
4) 关闭 Hadoop 虚拟内存检查
在yarn-site.xml中关闭虚拟内存检查(虚拟内存校验,如果已经关闭了,就不需要配了)。
(1)修改前记得先停Hadoop
[atguigu@hadoop102 hadoop]$ pwd
/opt/module/hadoop-3.1.3/etc/hadoop
[atguigu@hadoop102 hadoop]$ vim yarn-site.xml(2)添加如下配置
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>(3)修改完后记得分发yarn-site.xml,并重启yarn。
需要在yarn-site.xml里配置

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









