







2 3 c 0.6
3 4 d 0.7
4 5 e 1.0
姓名 年龄 身高 体重 性别
0 nancy 26 100 150 男
从dataframe取出其中的第一行数据–series对象,Name=0(行索引),行标签为原来dataframe的列名
A 1
B a
C 0.5
Name: 0, dtype: object
从dataframe取出其中的第一列数据–series对象,Name=‘A’(列名),行标签为原来dataframe的行索引
0 1
1 2
2 3
3 4
4 5
Name: A, dtype: int64
5.2 三种类型之间的转换方式
(1)将多个dict,合并到一个dataframe对象中
column1 = {‘A’: [1, 2, 3, 4, 5]}
column2 = {‘B’: [‘a’, ‘b’, ‘c’, ‘d’, ‘e’]}
column3 = {‘C’: [0.5, 0.4, 0.6, 0.7, 1.0]}
方法一:dict单独转成dataframe后再进行合并
c1 = pd.DataFrame(column1)
c2 = pd.DataFrame(column2)
c3 = pd.DataFrame(column3)
df1 = pd.concat([c1, c2, c3], axis=1) # 按照列合并
print(“df1 如下:\n”, df1)
方法二:转换为series后,再置于list后进行集中转换
series1 = pd.Series(column1[‘A’], name=‘A’)
series2 = pd.Series(column2[‘B’], name=‘B’)
series3 = pd.Series(column3[‘C’], name=‘C’)
s_list = [series1,series2,series3]
info = []
for i in range(3):
info.append(s_list[i])
df = pd.DataFrame(info).T
print(“df 如下:\n”, df)
代码运行结果如下:
方法一输出结果>>>>>>>>>>>>>>>>
df1 如下:
A B C
0 1 a 0.5
1 2 b 0.4
2 3 c 0.6
3 4 d 0.7
4 5 e 1.0
方法二输出结果>>>>>>>>>>>>>>>>
df 如下:
A B C
0 1 a 0.5
1 2 b 0.4
2 3 c 0.6
3 4 d 0.7
4 5 e 1.0
(2)将一个dict/series对象合并到一个dataframe对象中(为data添加一行数据)
- add_row 为一个dict对象,key值与待合并的dataframe对象的列名相同
- 方法一种:index=[1]代表将给定的dict转化为一个dataframe,其中行向量的行索引属性为1 (可以为任意int值),此时列名为原dict的key值,第一行的数据为对应的value值
- 方法二中:to_frame()方法将Series对象转换为DataFrame对象,然后transpose()方法对该DataFrame对象进行转置操作,即将行和列进行互换。这样,原本作为Series对象中的数据将被转换为一个行向量,而列名将成为DataFrame的索引。
add_row = {“A”: 111, ‘B’: ‘f’, ‘C’: 0.9999}
方法一:dict直接转化为dataframe后进行合并
new_df = pd.DataFrame(add_row ,index=[1])
df1 = pd.concat([df1, new_df])
print(new_df)
print(df1)
方法二:dict转化为series后,再转化为dataframe进行合并
add_row = pd.Series(add_row)
print(add_row)
add_row = add_row.to_frame().transpose()
或者采用 add_row = add_row.to_frame().T
print(add_row)
df1 = pd.concat([df1, add_row])
print(df1)
代码结果如下:
- 很显然将dict转化为行数据添加到dataframe使用方法一更直接,此处笔者特意阐述方法二,旨在让读者同时也了解series合并到dataframe中的转换方式
方法一运行过程>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
dict直接转化一个dataframe对象
A B C
1 111 f 0.9999
将该行数据与原来的dataframe进行合并的结果
A B C
0 1 a 0.50
1 2 b 0.40
2 3 c 0.60
3 4 d 0.70
4 5 e 1.00
1 111 f 0.9999
方法二运行过程>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
# dict转化为series对象
A 111
B f
C 0.9999
dtype: object
series对象再转为dataframe对象
A B C
0 111 f 0.9999
最后进行dataframe合并
A B C
0 1 a 0.50
1 2 b 0.40
2 3 c 0.60
3 4 d 0.70
4 5 e 1.00
0 111 f 0.9999
(3)将dataframe转换为dict对象
- dataframe转换为dict对象本质为提取其中的某一行/或一列数据,其转换过程仍然是通过先得到series对象,再转换为dict对象
- 从dataframe提取行数据/列数据的方法和介绍详见第六节~
series_obj = df1.iloc[0] # 取dataframe中的第一行数据,得到的是series,行标签为列名
dict_obj = dict(series_obj) # series转化为dict,或者使用dict_obj = series_obj.to_dict()
print(dict_obj)
series_obj = df1.iloc[:,0] # 取dataframe中的第一列数据,得到的是series,行标签为int类型的索引位置
dict_obj = dict(series_obj) # series转化为dict,或者使用dict_obj = series_obj.to_dict()
print(dict_obj)
代码结果如下:
行向量转化为dict的结果,key为列名,value为值
{‘A’: 1, ‘B’: ‘a’, ‘C’: 0.5}
列向量转化为dict的结果,key为行索引,value为值
{0: 1, 1: 2, 2: 3, 3: 4, 4: 5}
六、数据提取、索引与筛选
使用pandas库筛选、分析数据的过程其实和使用office软件去处理excel数据是类似的,其区别主要在于前者将各种需要人工逐步点击的数据筛选、提取、过滤或者计算公式的操作全部通过代码实现了自动化处理。下文给出了笔者在进行数据提取或筛选时常用的一些方法和注意要点。
6.1 iloc[] 按照行/列位置索引获取数据
data.iloc[]常用于按照行/列索引来获取指定行、指定列的数据,得到一个新的dataframe对象或series对象,笔者常用的场景如下:
- 使用data.iloc[x,y]的方式即可获取dataframe中行索引为x行,列索引y列的某个值
- 使用data.iloc[x]的方式即可获取dataframe中行索引为x的行数据,返回的是series对象
- 使用data.iloc[:,y]的方式即可获取dataframe中第y列的列数据,返回的是series对象
- 使用data.iloc[x:y]的方式即可获取dataframe中行索引从x到y行的数据,返回的仍然为dataframe对象,这一点同列表的切片操作类似,是左闭右开的。
- 使用data.iloc[[x1,x2]:[y1,y2]]的方式即可获取dataframe中第x1x2行,y1y2列的数据,返回的仍然为dataframe对象,这一点同列表的切片操作类似,是左闭右开的。
注意>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
- 1)x和y均需要为int类型,否则会报错
- 2)x和y分别为dataframe中的行索引和列索引,但不完全等价于该数据在整个dataframe中的第x行和第y列(绝对位置),因为行索引index是可以修改的,故处理数据时,一定要注意整个列表的行索引是否是从0开始递增的,通常可以用data.reset_index(drop=True,inplace=True)来重置索引;其中当drop=False时,将自动生成一列(列名=index)用于记录重置索引前每一列数据的行索引
- 3)iloc[x,y]中的x和y必须是该dataframe内存在的行索引和列索引,否则会出现索引越界报错
data = pd.read_excel(“input_data.xlsx”) # 读取excel数据
item1 = data.iloc[0] # 取该DataFrame的第一行数据,返回对象为series格式,key为对应数据的列明,value为对应的值
item2 = data.iloc[-1] # 取该DataFrame的最后一行数据,返回对象为series格式,key为对应数据的列明,value为对应的值
item3 = data.iloc[0,0] # 取该DataFrame中第0行,第0列的数据(其中0行为除列名外的第一行)
data2 = data.iloc[1:5] # 取该DataFrame中第1行到第4行的数据,生成一份新的数据对应data2
6.2 loc[] 按照行/列标签索引来获取数据
data.loc[row_label,column_label] 方法常用于按照指定“标签”去提取数据,其中的row_label和column_label可以是单个标签、标签列表、布尔数组、切片等,分别用于指定行和指定列的位置;使用loc[]函数时,需要注意传入的行标签和列标签必须存在,否则会报错。具体的用法如下:
import pandas as pd
创建一个DataFrame
data = {‘Name’: [‘Alice’, ‘Bob’, ‘Charlie’, ‘David’],
‘Age’: [25, 30, 35, 40],
‘Gender’: [‘F’, ‘M’, ‘M’, ‘M’]}
df = pd.DataFrame(data)
使用loc[]提取指定行和列的数据
print(df.loc[1, ‘Name’]) # 提取第2行,Name列的数据,输出Bob
print(df.loc[1:2, [‘Name’, ‘Age’]]) # 提取第2行到第3行,Name和Age列的数据
笔者将自己使用loc[]提取数据的高频场景主要有以下两种,供小伙伴们参考:
1)用法一:批量修改某一字段下,符合指定条件的数据
- 当需要综合某一列/某几列的值,来改写另一列的值时,可通过如下方式进行批量修改:
根据"后工序"列的值,批量修改"集批后工序"列的值
底层逻辑为:利用loc[row_label,column_label]提取到对应的“单元格”,然后将其修改为“s1”
temp_data.loc[(temp_data[‘后工序’] == ‘S1’), ‘集批后工序’] = ‘s1’
根据"后工序"以及"镀层类型代码"列的值,批量修改"集批后工序"列的值
temp_data.loc[(temp_data[‘后工序’] == ‘D1’) & (temp_data[‘镀层类型代码’] == ‘ZF’), ‘集批后工序’] = ‘D1-ZF’
2)用法二:获取符合指定条件的行向量索引
- 当需要对比两份dataframe,相同元素的行索引是否一致时,可通过如下的方式进行判断:
def compare_sequence(self,algo_plan,formal_plan):
‘’’
对比algo_plan与formal_plan两份数据,判断其中相同MAT_NO的数据索引是否相同
‘’’
task_1 = algo_plan[algo_plan[‘MAT_NO’].isin(formal_plan[‘MAT_NO’])]
task_2 = formal_plan[formal_plan[‘MAT_NO’].isin(algo_plan[‘MAT_NO’])]
task_1.reset_index(drop=True,inplace=False)
task_2.reset_index(drop=True, inplace=False)
task1_list = list(task_1[‘MAT_NO’])
task2_list = list(task_2[‘MAT_NO’])
for i in range(task_1.shape[0]):
if task1_list[i] != task2_list[i]:
前提:每个元素(每一行数据)的MAT_NO标签是唯一的
indices = task_2.loc[task_2[‘MAT_NO’] == task1_list[i]].index[0]
if i < indices:
move = “>>>向后移动”
else:
move = “<<<向前移动”
- 需要注意的时,使用loc[]方法去提取数据时,通常返回一个dataframe对象,因此使用.index方法时,得到的为一个包含符合条件行的行索引列表(尽管可能只有1个元素),因此还需要用.index[0]的方式来取出所需的行索引
3)用法三:获取指定条件的行数据
- 用法三与用法二类似,均使用loc[]运算来提取满足指定条件下的dataframe对象
- 当我们需要基于某个唯一标识字段,去获取另一个dataframe对象中的行数据时,可采用如下的方法来获取到对应的一行数据(series格式)
- 在如下的代码中,通过data1.loc[]的方式,提取满足指定条件的dataframe对象,再利用iloc[0]的方式获得该dataframe中的首行数据,即可得到对应的series对象
- 使用该方法时,需要注意另一个被查询的dataframe对象中(data1),待查询标识(“MAT_NO”)必须是唯一的,否则可能无法取到唯一的那行期望数据
item_i = data1.loc[data1[‘MAT_NO’] == mat_no2].iloc[0] # 找到对应的行数据
6.3 使用[]运算符自定义筛选条件获取数据
- 使用[]方法提取指定条件的数据逻辑同我们使用excel中的“筛选”功能,并且更加的灵活和方便,代码如下:
ori_data为给定的源数据,假定该数据有“A”、“B”、“C”、“D”列
A列、B列为int格式,C列、D列为str格式
则通过下列语句可以筛选同时满足:1)A列值>=min_thick;2)B列值<=max_thick;3)C列值等于‘value’;4)D列的值属于require_material(列表)
temp_data = ori_data[(ori_data[‘A’] >= min_thick)
& (ori_data[‘B’] <= max_thick)
& (ori_data[‘C’] == ‘value’])
& (ori_data[‘D’].isin(require_materail))]
假如我们要提取data的第2、3行和从Price到Sales对应的列 (连续的列,用切片操作)
new_df = data[2:3,‘Price’:‘Sales’]
假如我们要选取所有的行和Fruits和Sales对应的列
new_df = data[:,‘Price’:‘Sales’]
注意>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>
- []中不同的条件表达式之间,表示“与”逻辑运算使用**“&”连接,表示“或”逻辑运算使用“|”**连接,若使用’and’或’or’会报错
- 使用data[‘column’].isin()的方法来筛选对应列中,值属于某几个枚举项的数据
- 切片操作与list的切片类似,但使用[]去提取对应行和列的数据时,为左闭右闭区间,同时列名“标签”之间必须是连续的
6.4 数据提取和筛选方法小结
- iloc[]利用行索引和列索引来提取指定数据,[]中只能为int类型,输入的行列索引之间用“,”分隔
- loc[]利用行标签和列标签来提取指定数据,[]中可以为标签/布尔判断语句
- 利用[]来自定义筛选数据的判断条件,并提取源数据的副本数据,且具有切片功能
- 提取数据和筛选数据可以灵活地结合上述三种方法来使用,但需要注意不同方法返回的对象格式,例如iloc[x]返回的是series,loc[“条件表达式”](仅对行数据进行筛选)返回的是dataframe对象,调试代码时建议多利用type()来确定自己真正得到了什么格式的对象
七、数据统计与排序
7.1 基础信息统计
pandas库中有内置函数可以帮助我们直接统计得到某一列数据的基础统计信息,以及对某列数据进行累计求和,非常便捷!
常用的统计方法如下:
data[‘columnA’].sum() # 求列名为‘columnA’的总和
data[‘columnB’].mean() # 求列名为‘columnB’的平均值
data[‘columnC’].max() # 求列名为‘columnC’的最大值
data[‘columnD’].max() # 求列名为‘columnD’的最小值
假若想要对某一列的数据进行累加求和,可使用cumsum()函数得到某一列值的累计求和值。并通过“[]”运算符对数据按照某个累计值进行截断处理,如下所示:
对某列数据进行累加求和统计,并按照指定值进行数据截断
temp_data[‘重量累计值’] = temp_data[‘重量’].cumsum()
temp_data[‘长度累计值’] = temp_data[‘长度’].cumsum()
temp_data = temp_data[(temp_data[‘重量累计值’] <= wt_max) & (temp_data[‘长度累计值’] <= km_max)]
7.2 自定义排序
pandas库中还有内置的排序函数,能够按照指定列,指定排序方式对数据进行快速排序,但需要注意的是,该排序函数分“拷贝排序”和“原地排序”两种情况,区别在于指定的inplace参数是否为True,具体用法如下所示:
- by=[]中填写的字段顺序代表了排序优先级,即下面代码中先根据x进行降序,在对x列相同值的行数据,按照y值进行降序排序
如下展示了两种对数据进行排序的方式,均实现了:将整个表格中的数据按照x,y列的值,进行降序、降序排序
第一种排序方式下,源数据并不会改变,而是生成了一个排序后的副本,将其重新赋值给了data
data = data.sort_values(by=[‘x’,‘y’],ascending=[False,False])
第二种排序方式下,源数据会发生改变,即进行了原地排序
data.sort_values(by=[‘x’,‘y’],ascending=[False,False],inplace=True)
注意:上述排序完毕后,数据的行索引也会跟着移动改变!
八、数据的聚类统计:groupby()函数的应用
在数据统计和分析过程中,聚类统计/提取数据往往是使用频率最高的处理方法,而pandas库中自带内置函数groupby(),可以帮助我们快速地对整个DataFrame按照某些字段和统计方法进行聚类分组统计,该函数的基础使用语法如下:
- data.groupby() 对dataframe对象进行分组,此时返回对象格式为“DataFrameGroupBy”
- 利用[]运算符对指定字段进行同组内的数值统计
- 当传入的分组标签唯一时,得到的结果为一个series对象,key为分组的枚举值,value为对应分组内的指标统计值;当传入的分组标签为一个[]时,得到的结果为一个dataframe对象
- 通过上述方式得到的分组统计结果,可使用iloc[]方式逐行进行遍历,但只能得到对应行的统计结果。若需要查询对应的分组标签和分组统计值,建议使用.reset_index()将其转换为dataframe对象,利用iloc[]获得各分组的series对象后,再查询对应的分组标签和分组统计量
将源数据根据列“A”进行分组
group_data = data.groupby(‘A’)
将源数据根据列“A”以及列“B”进行分组
group_data2 = data.groupby([‘A’,‘B’])
统计分组后C列数据之和
group_result1 = group_data[‘C’].sum() # group_result1为series对象,key为A列的值,value为根据A列字段分组后,不同分组的求和值
统计分组后D列数据的平均值
group_result2 = group_data[‘D’].mean() # group_result2为series对象,key为A列的值,value为根据A列字段分组后,不同分组的平均值
具体应用:根据集批后工序和排产小类将数据进行分组统计,并查询每一组的分组指标与对应统计量
data = pd.read_excel(“test_data.xlsx”)
group_df = data.groupby([‘集批后工序’,‘排产小类’])
print(group_df)
result_len = group_df [‘入口长’].max().reset_index()
for index,row in result_len .iterrows():
print(“index = {} 分组指标 = {} - {} 统计量 = {}”.format(index,row[‘集批后工序’],row[‘排产小类’],row[‘入口长’]))
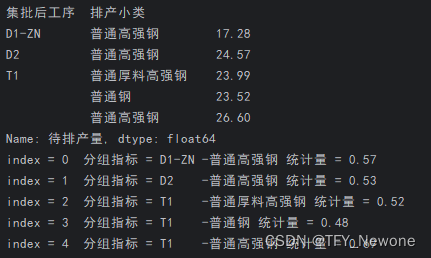
利用groupby函数对数据进行分组统计后的结果查询和输出
使用上述方法进行聚类统计的局限性在于:1)只能使用dataframe自带的内置函数对数据进行统计;2)不能同时对不同列按照不同的统计逻辑进行分组处理;3)返回dataframe对象中只带有一组统计量的值。若要使用自定函数同时对多列数据按照不同的统计方法进行分组统计或处理, 可使用聚类统计更为灵活的.agg()方法,代码如下:
根据集批后工序字段进行聚类分组,并对“待排产量”列的值进行求和
data1 = data.groupby([‘集批后工序’]).agg({“待排产量”: sum})
根据集批后工序字段进行聚类分组,并对“小类”列的字段用;进行合并
data2 = data.groupby(‘集批后工序’).agg({‘小类’: lambda x: ‘;’.join(x)})
根据集批后工序与排产小类字段进行聚类分组,对“待排产量”的值进行统计求和,对焊接分组字段按照自定义函数group_set进行统计处理
data3 = data.groupby([‘集批后工序’,‘排产小类’]).agg({“待排产量”: sum,‘焊接分组’:group_set})
自定义的数据整合函数
def group_set(column):
class_big = ‘-’.join(set(list(column)))
return class_big
- groupby可以传入一个包含多字段名的[],即可根据不同列的字段进行分组
- agg的入参为字典对象,key为需要分组/统计分析的列名,value为对指定列进行数据统计/处理的函数
- agg()中传入自定义函数时,函数接收的默认传参为该列的数据,即series对象,key值默认为源数据中的行索引,values值即对应列的值
- 需要注意:通过上述方式返回的对象data1,data2和data3均为dataframe对象,其中行索引为分组的条件值,列索引为对应统计的指标,建议使用.reset_index()对dataframe进行索引转换,具体的差别如下:

- 此时再利用如下代码,即可得到指定分组下的指标统计值的字典对象(方便用key值索引):
group_info = dict(zip(data[‘集批后工序’], data[‘待排产量’])) # key值为分组枚举值,value为对应分组下的指标统计值
九、数据的自定义处理函数:apply()函数的应用
apply()函数主要用于对dataframe的数据按照自定义函数进行批量处理和筛选,其基本的用法如下,其中func为自定义的函数,也可以采用lambda x: func 的方式对对应的行数据或列数据应用自定的函数进行批量处理。
对每一列应用函数,生成副本dataframe对象后,赋值给data
data = df.apply(func, axis=0)
对每一行应用函数,生成副本dataframe对象后,赋值给data
data = df.apply(func, axis=1)
具体应用:根据每一行的数据(一个series对象)来定义每一行对应的物料是否属于紧急催货物料,其中check_in_urgent为自定义函数
temp_data[‘是否属于紧急催货物料’] = temp_data.apply(check_in_urgent,axis=1)
笔者使用apply()函数较多的场景主要有以下两类需求:
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Python工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Python开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Python开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注Python)

最后
不知道你们用的什么环境,我一般都是用的Python3.6环境和pycharm解释器,没有软件,或者没有资料,没人解答问题,都可以免费领取(包括今天的代码),过几天我还会做个视频教程出来,有需要也可以领取~
给大家准备的学习资料包括但不限于:
Python 环境、pycharm编辑器/永久激活/翻译插件
python 零基础视频教程
Python 界面开发实战教程
Python 爬虫实战教程
Python 数据分析实战教程
python 游戏开发实战教程
Python 电子书100本
Python 学习路线规划

一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!

不限于:
Python 环境、pycharm编辑器/永久激活/翻译插件
python 零基础视频教程
Python 界面开发实战教程
Python 爬虫实战教程
Python 数据分析实战教程
python 游戏开发实战教程
Python 电子书100本
Python 学习路线规划
一个人可以走的很快,但一群人才能走的更远。不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎扫码加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
[外链图片转存中…(img-bNJuKgdh-1712599152114)]














 1419
1419











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









