







为了做好运维面试路上的助攻手,特整理了上百道 【运维技术栈面试题集锦】 ,让你面试不慌心不跳,高薪offer怀里抱!
这次整理的面试题,小到shell、MySQL,大到K8s等云原生技术栈,不仅适合运维新人入行面试需要,还适用于想提升进阶跳槽加薪的运维朋友。

本份面试集锦涵盖了
- 174 道运维工程师面试题
- 128道k8s面试题
- 108道shell脚本面试题
- 200道Linux面试题
- 51道docker面试题
- 35道Jenkis面试题
- 78道MongoDB面试题
- 17道ansible面试题
- 60道dubbo面试题
- 53道kafka面试
- 18道mysql面试题
- 40道nginx面试题
- 77道redis面试题
- 28道zookeeper
总计 1000+ 道面试题, 内容 又全含金量又高
- 174道运维工程师面试题
1、什么是运维?
2、在工作中,运维人员经常需要跟运营人员打交道,请问运营人员是做什么工作的?
3、现在给你三百台服务器,你怎么对他们进行管理?
4、简述raid0 raid1raid5二种工作模式的工作原理及特点
5、LVS、Nginx、HAproxy有什么区别?工作中你怎么选择?
6、Squid、Varinsh和Nginx有什么区别,工作中你怎么选择?
7、Tomcat和Resin有什么区别,工作中你怎么选择?
8、什么是中间件?什么是jdk?
9、讲述一下Tomcat8005、8009、8080三个端口的含义?
10、什么叫CDN?
11、什么叫网站灰度发布?
12、简述DNS进行域名解析的过程?
13、RabbitMQ是什么东西?
14、讲一下Keepalived的工作原理?
15、讲述一下LVS三种模式的工作过程?
16、mysql的innodb如何定位锁问题,mysql如何减少主从复制延迟?
17、如何重置mysql root密码?
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 0.62 21.68 1.92 225046 19972
选项:
-c:仅显示CPU使用情况;
-d:仅显示设备利用率;
-k:显示状态以千字节每秒为单位,而不使用块每秒;
-m:显示状态以兆字节每秒为单位;
-p:仅显示块设备和所有被使用的其他分区的状态;
-t:显示每个报告产生时的时间;
-V:显示版号并退出;
-x:显示扩展状态。
详细说明:
第一行是系统信息和监测时间
第二行和第三行显示CPU使用情况(具体内容和mpstat命令相同)
第四行:
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
sda 3.56 74.96 16.91 767153 173074
tps:该设备每秒的传输次数
kB_read/s:每秒从设备(drive expressed)读取的数据量;
kB_wrtn/s:每秒向设备(drive expressed)写入的数据量;
kB_read:读取的总数据量;
kB_wrtn:写入的总数量数据量;
**6.sar**
(System Activity Reporter 系统活动情况报告)是目前 Linux上最为全面的系统性能分析工具之一,可以从多方面对系统的活动进行报告,包括:文件的读写情况、系统调用的使用情况、磁盘I/O、CPU效率、内存使用状况、进程活动及IPC有关的活动等。
选项:
-t为采样间隔,n为采样次数,默认值是1;
-o file表示将命令结果以二进制格式存放在文件中,file 是文件名。
options 为命令行选项,sar命令常用选项如下:
-A:所有报告的总和
-u:输出CPU使用情况的统计信息
-v:输出inode、文件和其他内核表的统计信息
-d:输出每一个块设备的活动信息
-r:输出内存和交换空间的统计信息
-b:显示I/O和传送速率的统计信息
-a:文件读写情况
-c:输出进程统计信息,每秒创建的进程数
-R:输出内存页面的统计信息
-y:终端设备活动情况
-w:输出系统交换活动信息
**实例:**
**(1)CPU资源监控**
每2秒采样一次,连续采样3次,观察CPU 的使用情况,结果保存到test文件(二进制)
[root@localhost ~]# sar -u -o test 2 3
Linux 3.10.0-514.el7.x86_64 (localhost.localdomain) 2022年10月25日 x86_64(1 CPU)
07时09分26秒 CPU %user %nice %system %iowait %steal %idle
07时09分28秒 all 0.00 0.00 0.00 0.00 0.00 100.00
07时09分30秒 all 0.00 0.00 0.50 0.00 0.00 99.50
07时09分32秒 all 0.00 0.00 0.00 0.00 0.00 100.00
平均时间: all 0.00 0.00 0.17 0.00 0.00 99.83
05:49:41 PM CPU %user %nice %system %iowait %steal %idle
CPU:all 表示统计信息为所有 CPU 的平均值。
%user:显示在用户级别(application)运行使用 CPU 总时间的百分比。
%nice:显示在用户级别,用于nice操作,所占用 CPU 总时间的百分比。
%system:在核心级别(kernel)运行所使用 CPU 总时间的百分比。
%iowait:显示用于等待I/O操作占用 CPU 总时间的百分比。
%steal:管理程序(hypervisor)为另一个虚拟进程提供服务而等待虚拟CPU 的百分比。
%idle:显示 CPU 空闲时间占用 CPU 总时间的百分比。
注:
%iowait 的值过高,表示硬盘存在I/O瓶颈
%idle 的值高但系统响应慢时,有可能是 CPU 等待分配内存,此时应加大内存容量
%idle 的值持续低于1,则系统的CPU处理能力相对较低,表明系统中最需要解决的资源是CPU
sar -u -f test 查看二进制文件内容
[root@localhost ~]# sar -u -f test
Linux 3.10.0-514.el7.x86_64 (localhost.localdomain) 2022年10月25日 x86_64(1 CPU)
07时09分26秒 CPU %user %nice %system %iowait %steal %idle
07时09分28秒 all 0.00 0.00 0.00 0.00 0.00 100.00
07时09分30秒 all 0.00 0.00 0.50 0.00 0.00 99.50
07时09分32秒 all 0.00 0.00 0.00 0.00 0.00 100.00
平均时间: all 0.00 0.00 0.17 0.00 0.00 99.83
**(2)inode、文件和其他内核表监控**
每10秒采样一次,连续采样3次,观察核心表的状态
sar -v 10 3
dentunusd:目录高速缓存中未被使用的条目数量
file-nr:文件句柄(file handle)的使用数量
inode-nr:索引节点句柄(inode handle)的使用数量
pty-nr:使用的pty数量
**(3)内存和交换空间监控**
每10秒采样一次,连续采样3次,监控内存分页
sar -r 10 3
kbmemfree kbmemused %memused kbbuffers kbcached kbcommit %commit kbactive kbinact kbdirty
424292 1603612 79.08 1116 793024 3963588 96.09 913084 404904 0
kbmemfree:这个值和free命令中的free值基本一致,所以它不包括buffer和cache的空间.
kbmemused:这个值和free命令中的used值基本一致,所以它包括buffer和cache的空间.
%memused:这个值是kbmemused和内存总量(不包括swap)的一个百分比.
kbbuffers和kbcached:这两个值就是free命令中的buffer和cache.
kbcommit:保证当前系统所需要的内存,即为了确保不溢出而需要的内存(RAM+swap).
%commit:这个值是kbcommit与内存总量(包括swap)的一个百分比.
kbactive: 活跃内存(经常使用不回收的内存,只有在必须被需要时回收)
kbinact: 不活跃内存(最近不经常使用, 更有可能回收给其他进程使用)
kbdirty: 等待被写会硬盘的内存
**(4)内存分页监控**
每10秒采样一次,连续采样3次,监控内存分页:
sar -B 10 3
pgpgin/s pgpgout/s fault/s majflt/s pgfree/s pgscank/s pgscand/s pgsteal/s %vmeff
0.00 0.00 7.40 0.00 22.70 0.00 0.00 0.00 0.00
pgpgin/s:表示每秒从磁盘或SWAP置换到内存的字节数(KB)
pgpgout/s:表示每秒从内存置换到磁盘或SWAP的字节数(KB)
fault/s:每秒钟系统产生的缺页数,即主缺页与次缺页之和(major +minor)
majflt/s:每秒钟产生的主缺页数.
pgfree/s:每秒被放入空闲队列中的页个数
pgscank/s:每秒被kswapd扫描的页个数
pgscand/s:每秒直接被扫描的页个数
pgsteal/s:每秒钟从cache中被清除来满足内存需要的页个数
%vmeff:每秒清除的页(pgsteal)占总扫描页(pgscank+pgscand)的百分比
**(5)I/O和传送速率监控**
每10秒采样一次,连续采样3次,报告缓冲区的使用情况
sar -b 10 3
tps rtps wtps bread/s bwrtn/s
0.00 0.00 0.00 0.00 0.00
tps:每秒钟物理设备的 I/O 传输总量
rtps:每秒钟从物理设备读入的数据总量
wtps:每秒钟向物理设备写入的数据总量
bread/s:每秒钟从物理设备读入的数据量,单位为 块/s
bwrtn/s:每秒钟向物理设备写入的数据量,单位为 块/s
**(6)、进程队列长度和平均负载状态监控**
每10秒采样一次,连续采样3次,监控进程队列长度和平均负载状态:
sar -q 10 3
runq-sz plist-sz ldavg-1 ldavg-5 ldavg-15 blocked
0 144 0.00 0.01 0.05 0
runq-sz:运行队列的长度(等待运行的进程数)
plist-sz:进程列表中进程(processes)和线程(threads)的数量
ldavg-1:最后1分钟的系统平均负载(System load average)
ldavg-5:过去5分钟的系统平均负载
ldavg-15:过去15分钟的系统平均负载
**(7)系统交换活动信息监控**
每10秒采样一次,连续采样3次,监控系统交换活动信息:
sar - W 10 3
pswpin/s pswpout/s
0.00 0.00
pswpin/s:每秒系统换入的交换页面(swap page)数量
pswpout/s:每秒系统换出的交换页面(swap page)数量
**(8)设备使用情况监控**
每10秒采样一次,连续采样3次,报告设备使用情况,需键入如下命令:
sar -d 10 3 –p
DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
sda 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
参数-p可以打印出sda,hdc等磁盘设备名称,如果不用参数-p,设备节点则
有可能是dev8-0,dev22-0
tps:每秒从物理磁盘I/O的次数.多个逻辑请求会被合并为一个I/O磁盘请
求,一次传输的大小是不确定的.
rd_sec/s:每秒读扇区的次数.
wr_sec/s:每秒写扇区的次数.
avgrq-sz:平均每次设备I/O操作的数据大小(扇区).
avgqu-sz:磁盘请求队列的平均长度.
await:从请求磁盘操作到系统完成处理,每次请求的平均消耗时间,包括
请求队列等待时间,单位是毫秒(1秒=1000毫秒).
svctm:系统处理每次请求的平均时间,不包括在请求队列中消耗的时间.
%util:I/O请求占CPU的百分比,比率越大,说明越饱和.
>
> 注意:
> avgqu-sz 的值较低时,设备的利用率较高。
> 当%util的值接近 1 时,表示设备带宽已经占满。
>
>
> 总结:
> 要判断系统瓶颈问题,有时需几个 sar 命令选项结合起来
> 怀疑CPU存在瓶颈,可用 sar -u 和 sar -q 等来查看
> 怀疑内存存在瓶颈,可用 sar -B、sar -r 和 sar -W 等来查看
> 怀疑I/O存在瓶颈,可用 sar -b、sar -u 和 sar -d 等来查看
>
>
>
**7、iotop**
用来监视磁盘I/O使用状况的top类工具,实时观察磁盘io情况,可以观察到哪个进程占用I/O
yum install iotop
**iotop 参数:**
-o:只显示有io操作的进程
-b:批量显示,无交互,主要用作记录到文件。
-n NUM:显示NUM次,主要用于非交互式模式。
-d SEC:间隔SEC秒显示一次。
-p PID:监控的进程pid。
-u USER:监控的进程用户。
**iotop常用快捷键:**
(1)左右箭头:改变排序方式,默认是按IO排序。
(2) r:改变排序顺序。
(3) o:只显示有IO输出的进程。
(4) p:进程/线程的显示方式的切换。
(5) a:显示累积使用量。
(6) q:退出
**8、htop**
Htop类似于top命令,但可以让你在垂直和水平方向上滚动,所以你可以看到系统上所有运行的进程,以及它们完整的命令行。可以不输入进程的PID就可以对此进程进行相关的操作(kill)。Htop是Linux系统中的一个互动的进程查看器,一个文本模式的应用程序(在控制台orX终端中),需要ncurses。与Linux传统的top相比,htop更加人性化。它可以让用户交互式操作,支持颜色主题,可横向或者纵向滚动浏览进程列表,并支持鼠标操作。
**与top相比,htop有以下优点:**
可以横向或纵向滚动浏览进程列表,以便看到所有的进程和完整命令行;
在启动时,比top要快;
杀进程时不需要输入进程号;
htop支持鼠标操作;
wget -O /etc/yum.repos.d/epel.repo http://mirrors.aliyun.com/repo/epel-7.repo
yum -y install htop
>
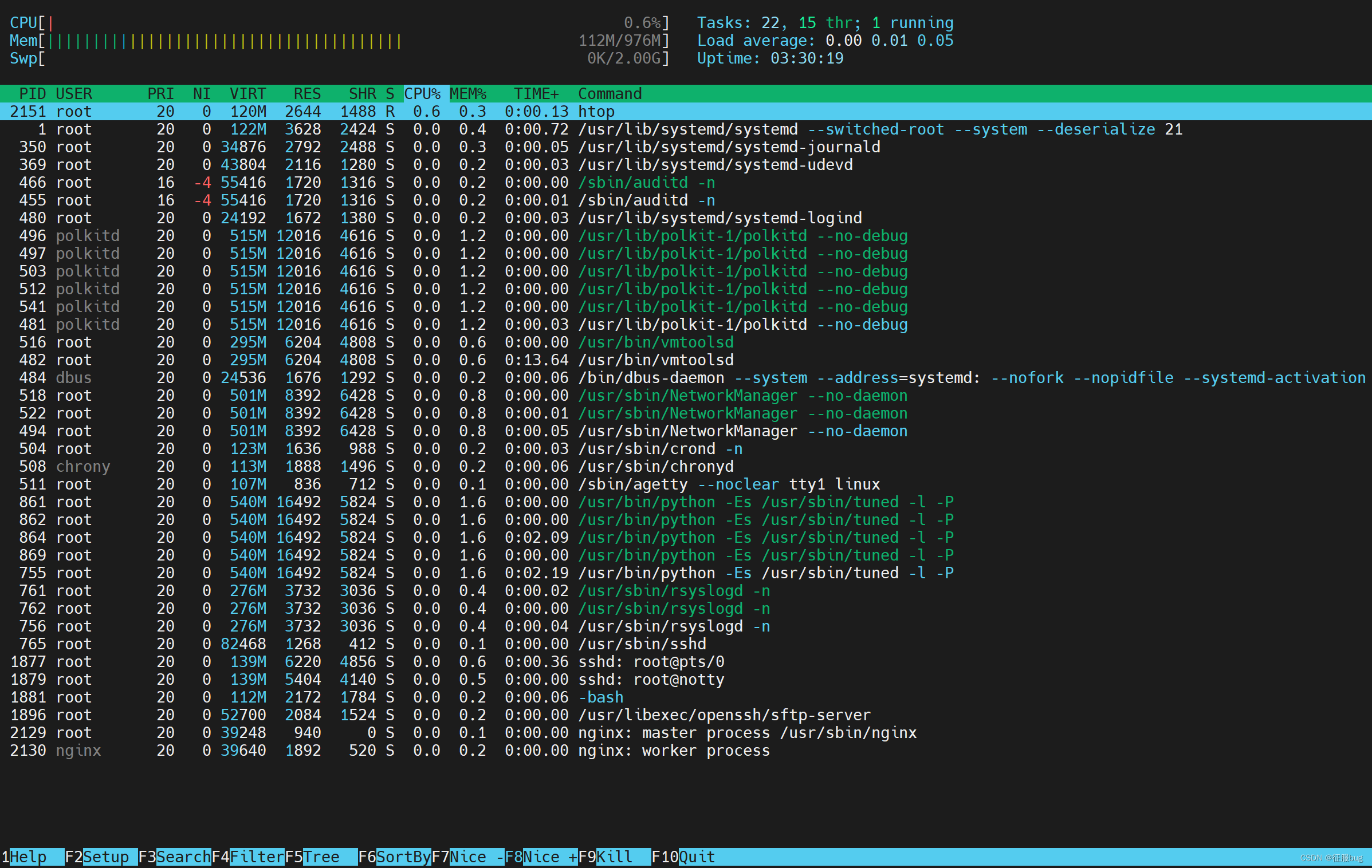
> 
>
>
>
> htop区域
> 区域1:CPU使用率、内存以及交换空间使用率;
> 区域2:1/5/15分钟的平均负载以及开机时间等;
> 区域3:当前系统中运行的进程;
> 区域4:功能键;
>
>
>
> 在区域3中,代表当前系统中运行的进程。各项说明如下:
>
>
>
>
> ```
> 1.PID:进程标志号,是非零正整数
> 2.USER:进程所有者的用户名
> 3.PR:进程的优先级别
> 4.NI:进程的优先级别数值
> 5.VIRT:进程占用的虚拟内存值
> 6.RES:进程占用的物理内存值
> 7.SHR:进程使用的共享内存值
> 8.S:进程的状态,其中S代表休眠,R代表正在运行,Z表示僵死状态,N代表该进程优先级是负数
> 9.%CPU:该进程占用的cpu使用率
> 10.%MEM:该进程占用的物理内存和总内存的百分比
> 11.TIME+:该进程启动后占用的总的CPU时间
> 12.COMMAND:进程启动的启动命令名称
>
> -C --no-color 使用一个单色的配色方案
> -d --delay=DELAY 设置延迟更新时间,单位秒
> -h --help 显示htop 命令帮助信息
> -u --user=USERNAME 只显示一个给定的用户的过程
> -p --pid=PID,PID… 只显示给定的PIDs
> -s --sort-key COLUMN 依此列来排序
> -v –version 显示版本信息
> 交互式命令(INTERACTIVE COMMANDS)
> 上下键或PgUP, PgDn 选定想要的进程,左右键或Home, End 移动字段,当然也可以直接用鼠标选定进程;
> Space 标记/取消标记一个进程。命令可以作用于多个进程,例如 "kill",将应用于所有已标记的进程
> U 取消标记所有进程
> s 选择某一进程,按s:用strace追踪进程的系统调用
> l 显示进程打开的文件: 如果安装了lsof,按此键可以显示进程所打开的文件
> I 倒转排序顺序,如果排序是正序的,则反转成倒序的,反之亦然
> +, - When in tree view mode, expand or collapse subtree. When a subtree is collapsed a "+" sign shows to the left of the process name.
> a (在有多处理器的机器上) 设置 CPU affinity: 标记一个进程允许使用哪些CPU
> u 显示特定用户进程
> M 按Memory 使用排序
> P 按CPU 使用排序
> T 按Time+ 使用排序
> F 跟踪进程: 如果排序顺序引起选定的进程在列表上到处移动,让选定条跟随该进程。这对监视一个进程非常有用:通过这种方式,你可以让一个进程在屏幕上一直可见。使用方向键会停止该功能。
> K 显示/隐藏内核线程
> H 显示/隐藏用户线程
> Ctrl-L 刷新
> Numbers PID 查找: 输入PID,光标将移动到相应的进程上
>
> F1 帮助
> F2 设定
> F3 搜索
> F4 过滤
> F5 显示树形结构,类似pstree
> F6 选择排序方式
> F7 调低nice值
> F8 调高nice值
> F9 杀死进程
> q 退出
> ```
>
>
**9、glances**
>
> glances是一个基于python语言开发,可以为linux或者UNIX性能提供监视和分析性能数据的功能。glances在用户的终端上显示重要的系统信息,并动态的进行更新,让管理员实时掌握系统资源的使用情况,而动态监控并不会消耗大量的系统资源,比如CPU资源,通常消耗小于2%,glances默认每两秒更新一次数据。同时glances还可以将相同的数据捕获到一个文件,便于以后对报告进行分析和图形绘制,支持的文件格式有.csv电子表格格式和和html格式。
>
>
> glances可以分析系统的:
> CPU使用率
> 内存使用率
> 内核统计信息和运行队列信息
> 磁盘I/O速度、传输和读/写比率
> 磁盘适配器
> 网络I/O速度、传输和读/写比率
> 页面监控
> 进程监控-消耗资源最多的进程
> 计算机信息和系统资源
>
>
>
**(1)安装**
yum -y install glances
glances 工作界面的说明 :
在图 的上部是 CPU 、Load(负载)、Mem(内存使用)、 Swap(交换分区)的使用情况。
在图的中上部是网络接口、Processes(进程)的使用情况。
**通常包括如下字段:**
%CPU:该进程占用的 CPU 使用率
%MEM:该进程占用的物理内存和总内存的百分比
VIRT: 虚拟内存大小
RES: 进程占用的物理内存值
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
yum -y install glances
glances 工作界面的说明 :
在图 的上部是 CPU 、Load(负载)、Mem(内存使用)、 Swap(交换分区)的使用情况。
在图的中上部是网络接口、Processes(进程)的使用情况。
**通常包括如下字段:**
%CPU:该进程占用的 CPU 使用率
%MEM:该进程占用的物理内存和总内存的百分比
VIRT: 虚拟内存大小
RES: 进程占用的物理内存值
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









