







一、cut 命令
cut 是 Linux/Unix 系统中一个高效的文本处理工具,用于按列(字段)提取数据。它通过指定分隔符或字符位置来切割文本行,特别适合处理结构化数据(如 CSV、日志、配置文件等)。
1、格式:cut [参数] [文件名]
2、常用参数:
| -b | 以字节为单位进行分割 |
|
| 指定字段分隔符(默认是制表符 |
|
| 选择要提取的字段(列),如 |
|
| 按字符位置提取(而非字段),如 |
|
| 抽取整个文本行,除了那些由 -c 或 -f 选项指定的文本 |
|
| 指定输出时的分隔符(默认与输入相同) |
3、示例:
(1)按分隔符提取字段:
文件 data.csv 内容为:
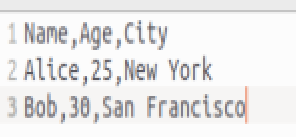
提取第一列:
cut -d',' -f1 data.csv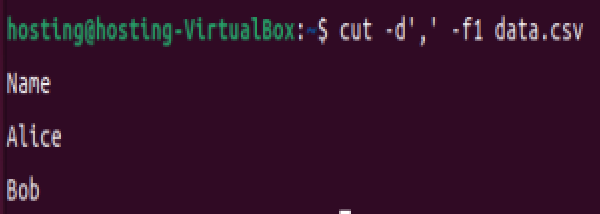
提取多列(Name和City):
cut -d',' -f1,3 data.csv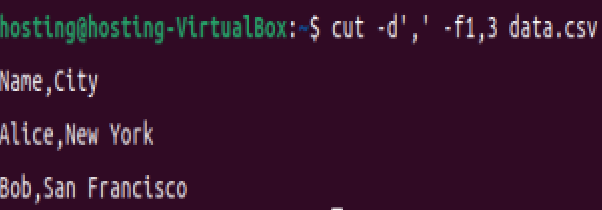
提取列范围(Age 到 City):
cut -d',' -f2-3 data.csv 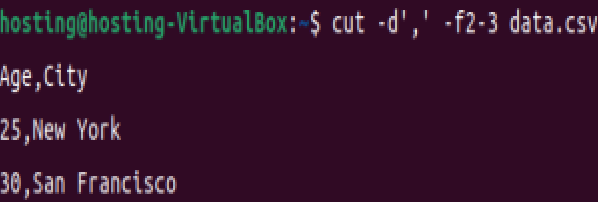
(2)按字符位置提取:
文件 lines.txt 内容为:
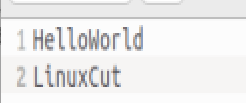
提取每行的第1到5个字符:
cut -c1-5 lines.txt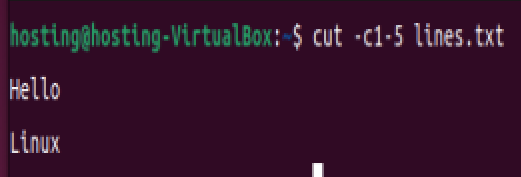
(3)补集模式(排除指定列):
排除第二列(Age):
cut -d',' --complement -f2 data.csv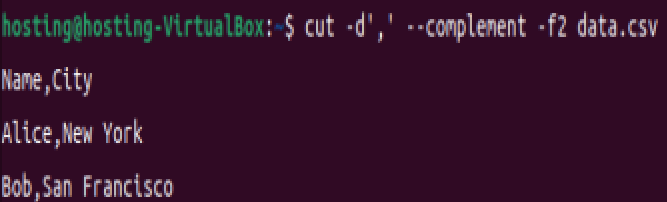
(4)修改输出分隔符
将逗号分隔符改为 |:
cut -d',' -f1,3 --output-delimiter='|' data.csv 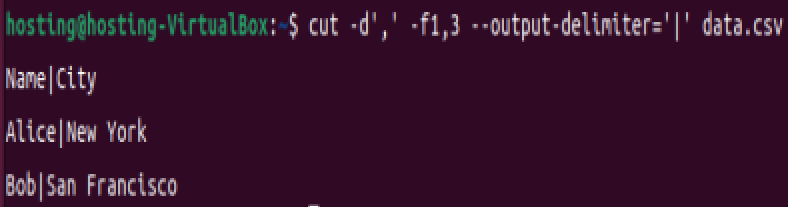
(5)进阶
结合其他命令:(提取正在运行的进程名)
ps aux | cut -d' ' -f11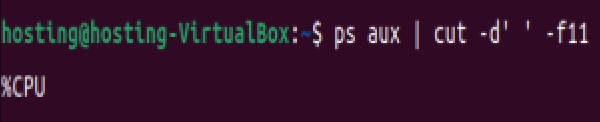
注意:此处 -d' ' 可能因空格数量不固定失效,更推荐用 awk '{print $11}'
处理多字符分隔符:cut 不支持多字符分隔符(如 ::),此时需用 awk -F'::'
(6)补充:
- 字段编号从1开始(不是0)。
- 默认行为:如果不指定
-d,cut会按制表符分隔字段。 - 空格分隔符:若需按空格分割,需显式指定
-d' '(但注意多个空格可能被视为单个分隔符)。 - 与
awk的区别:cut适合简单列提取,复杂逻辑(如条件过滤)建议用awk。
二、paste 命令
paste 是 Linux/Unix 系统中一个用于合并文本文件的实用工具,其功能可以看作是 cut 的逆操作。它通过读取多个文件或输入流,将它们的行按指定分隔符横向拼接(合并列),输出到标准输出。
1、格式:paste [参数] [文件名]
2、常用参数
-d | 指定合并时的分隔符(默认是制表符 \t) |
-s | 将文件内容按行串联(合并为单列,而非多列) |
3、示例:
文件 name.txt 内容为:
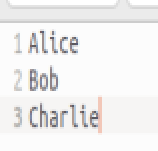
文件 ages.txt 内容为:

(1) 合并多个文件的列(如果文件列数不一致,paste 会以较短文件的最后一行重复填充):
默认合并(制表符分隔):
paste names.txt ages.txt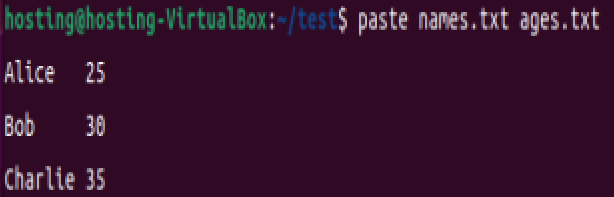
自定义分隔符(逗号):
paste -d',' names.txt ages.txt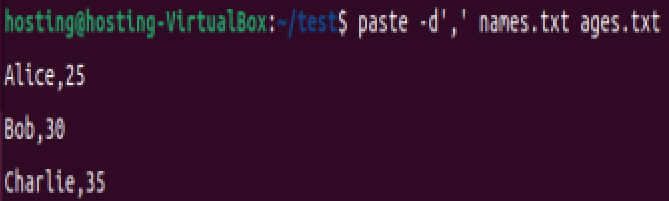
(2) 合并多个文件为单列(-s 选项)
将文件内容纵向拼接:
paste -s names.txt 
指定分隔符拼接:
paste -s -d';' names.txt 
(3)合并标准输入和文件
从管道和文件合并:
echo "USA" | paste - names.txt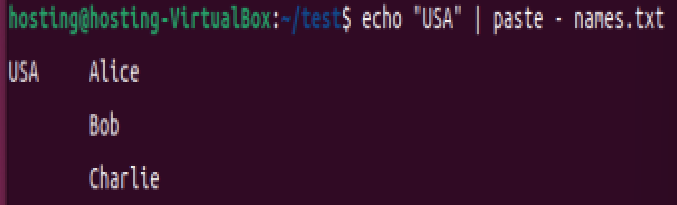
(4)进阶
结合 cut 和 paste:例如先提取列再合并:
cut -d',' -f1 data.csv | paste - names.txt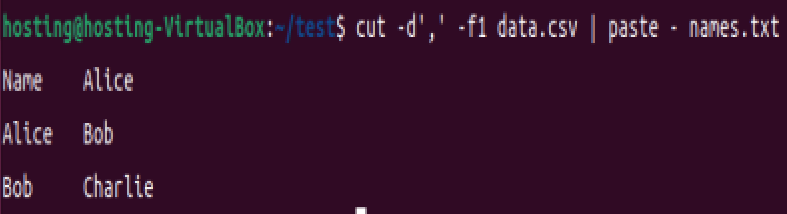
生成表格格式:通过指定分隔符美化输出:
paste -d'|' <(cut -d',' -f1 data.csv) <(cut -d',' -f3 data.csv) 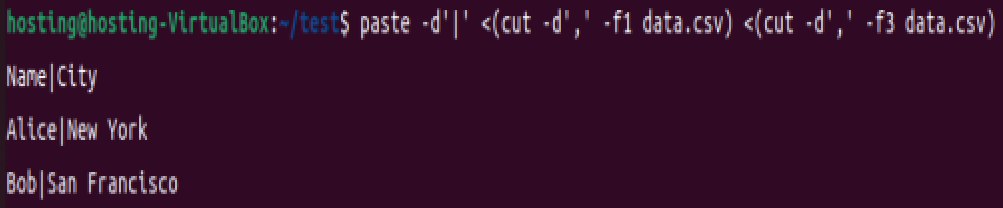
paste 适合快速合并结构化数据,尤其在需要将多个独立文件按列组合时非常高效。对于复杂合并逻辑(如基于键关联),建议使用 join 或 awk。
(5)补充:
默认分隔符:如果不指定 -d,paste 使用制表符 \t 分隔列。
文件行数不一致:行数较少的文件会在末尾重复其最后一行以匹配最长文件的行数。
与 join 的区别:paste 是简单横向拼接,而 join 会基于键(列值)关联文件。
三、tr 命令
tr 命令是 Linux/Unix 系统中用于字符转换和处理的强大工具,全称为 translate(转换)。
它通过标准输入(stdin)读取数据,对字符进行替换、删除或压缩,并将结果输出到标准输出(stdout)。
tr 的核心功能是基于字符的逐个操作,而非字符串或正则表达式,适合简单的字符级转换任务。
1、格式:tr [参数] SET1 SET2
- SET1:需要转换的字符集合。
- SET2:目标字符集合(与 SET1 一一对应)。
- 如果省略 SET2,
tr会删除 SET1 中的字符(或重复 SET1 的最后一个字符进行替换)。
2、常用参数
-d | 删除 SET1 中的字符(不替换) |
-s | 压缩重复的字符(将连续的重复字符替换为单个字符) |
-c | 补集模式(操作所有不在 SET1 中的字符) |
3、示例:
(1)字符替换:
将小写字母转换为大写:
echo "hello" | tr 'a-z' 'A-Z'
替换特定字符(如 a → @):
echo "banana" | tr 'a' '@'
(2)删除字符(-d 选项)
删除所有数字:
echo "a1b2c3" | tr -d '0-9' ![]()
删除所有空格和制表符:
echo "a b\tc" | tr -d ' \t'echo "a b c" | tr -d '[:blank:]'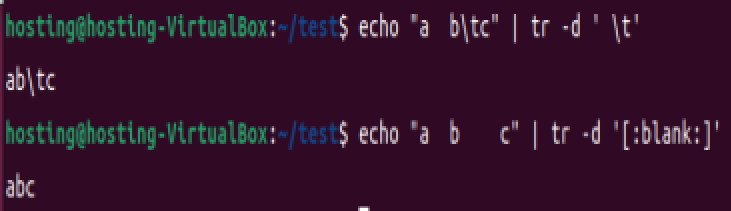
这里我使用第一个命令无法删除制表符,使用字符类命令实现。
问题原因
-
制表符输入方式不同:
-
制表符可能是 硬制表符(ASCII 9) 或 连续空格模拟的“软制表符”,后者无法被
\t匹配。
-
-
Shell解释差异:
-
某些Shell(如旧版本bash)可能未正确解析
\t为制表符。
-
(3) 压缩重复字符(-s 选项)
压缩连续的空格为单个空格:
echo "hello world" | tr -s ' '![]()
压缩连续的换行符(清理空行):
cat names.txt | tr -s '\n'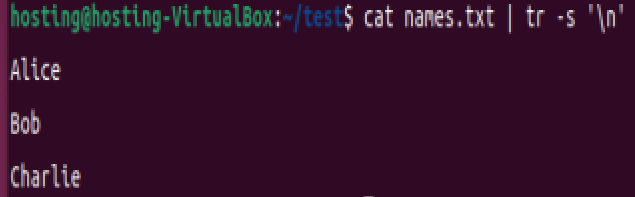
这里我增加了几个空格,结果删除空格成功!
(4)补集模式(-c 选项)
删除所有非字母字符:
echo "a1b!c" | tr -cd 'a-zA-Z'(5)其他命令
统计单词频率(先转换为小写):
echo "Hello World hello" | tr '[:upper:]' '[:lower:]' | tr ' ' '\n' | sort | uniq -c 
(6)字符集合的表示方法
直接字符列表:
tr 'abc' 'xyz' # a→x, b→y, c→z字符范围:
tr 'a-z' 'A-Z' # 小写转大写预定义字符类:
[:alnum:]:字母和数字。[:alpha:]:字母。[:digit:]:数字。[:space:]:空白字符(空格、制表符、换行符等)。[:upper:]:大写字母。[:lower:]:小写字母。
(7)补充:
SET1 和 SET2 的长度:
如果 SET2 比 SET1 短,tr 会重复 SET2 的最后一个字符。
如果 SET2 比 SET1 长,tr 会忽略 SET2 的多余部分。
与 sed 的区别:
tr 是字符级操作,不支持正则表达式或字符串替换。
sed 支持正则表达式和复杂的文本替换(如 sed 's/old/new/g')。
输入来源:
tr 只能通过标准输入(stdin)读取数据,无法直接操作文件。若需处理文件,需结合管道或重定向:

















 290
290

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









