







 本文介绍了Pipcook平台,其简单易用的Pipeline系统,支持本地和远程的Pipeline运行,以及内置的各类任务插件。着重讲解了如何开发和使用插件,包括NPM包扩展和Python生态集成。PipApp为前端工程师提供了简化机器学习应用的工具,旨在降低入门门槛并提高开发效率。
本文介绍了Pipcook平台,其简单易用的Pipeline系统,支持本地和远程的Pipeline运行,以及内置的各类任务插件。着重讲解了如何开发和使用插件,包括NPM包扩展和Python生态集成。PipApp为前端工程师提供了简化机器学习应用的工具,旨在降低入门门槛并提高开发效率。
}
}
}
从上图可以看到 Pipeline 十分简单,只需要按照预先定义的字段配置你需要的插件及参数即可,然后再通过 Pipcook Tools 来运行它就行了:
$ pipcook run https://foobar.xzz/mobilenet-classification.json
Pipcook Tools 支持运行本地和远程的 Pipeline,这意味着开发者可以通过 CDN、GitHub 或者任意 HTTP 服务来分享你的 Pipeline。
在经过一定时间的训练之后,就会在当前目录下的 output 文件夹下看到生成的模型文件和相关的 JavaScript 库了:

生成的模型包
生成后的使用方式也十分简单:
$ cd ./output && npm install
$ node -e “require(‘./output’)(‘input data’)”
除此之外,你也可以通过 Pipboard 随时下载历史的训练结果,如下图所示:

Pipboard
为了方便开发者使用,Pipcook 已经内置了一些任务类型的 Pipeline:
-
文本类
-
- 文本分类:text-bayes-classification(基于朴素贝叶斯的分类)、fasttext-classification(基于 FastText 的文本分类)
-
文本创作:chinese-poem-creation(生成中国诗歌)
-
视觉类
-
- 图片分类:mobilenet-image-classification(基于 mobilenet 的图片分类)
-
目标检测:object-detection(基于 detectron2 开发的目标检测)
-
图片风格迁移:image-generation-cycle-gan(基于 CycleGAN 的图片生成)
如何开发插件
通过上面的介绍,读者基本已经了解了 Pipcook 主要的使用场景了,对,那就是 —— Pipeline,但要说到 Pipeline 却离不开插件,我们为 Pipcook 的 Pipeline 生态构建了一套开放的插件机制,通过这套机制,任何开发者都可以随时随地基于 Node.js 为 Pipcook 拓展插件。
首先,一个插件,也是一个 NPM 包,在 NPM 包的基础上,Pipcook 增加了一些拓展字段,即在 package.json 中增加了一些额外的定义,下面就是一个简单的定义:
{
“name”: “my-own-pipcook-plugin”,
“version”: “1.0.0”,
“description”: “my own pipcook plugin”,
“dependencies”: {
“@pipcook/pipcook-core”: “^0.5.0”
},
“pipcook”: {
“category”: “dataCollect”,
“datatype”: “image”
},
“conda”: {
“python”: “3.7”,
“dependencies”: {
“tensorflow”: “2.2.0”
}
}
}
首先,每个插件都必须依赖 @pipcook/pipcook-core,它包含了实际定义插件所依赖的类型定义和一些工具函数。然后是 “pipcook” 节点,它定义了插件的基本信息,比如类别和数据类型,它用于 Pipcook 对插件本身做归类和整理,接下来就是 “conda” 节点(可选),如果插件依赖 Python 环境,那么开发者可以通过这个字段配置 Python 的依赖,比如上述就表示插件依赖 Python 版 tensorflow@2.2.0,在 Pipcook 安装插件时就会自动进行安装。
定义好这些基本信息后,就可以开始写具体的插件代码了,还记得前面在说明 Pipeline 流程时的那张图吗?每一种插件类型的写法都是不一样的,比如一个简单的 data collect 插件如下:
const collectTextline: DataCollectType = async (args: ArgsType): Promise => {
const { uri, dataDir } = args;
await fs.copy(uri, dataDir + ‘/my-own-dataset.csv’);
return null;
};
export default collectTextline;
插件的输入是 ArgsType,输出是 void,那么来看看 data process 插件:
const doubleSize: DataProcessType = async (sample: Sample, metadata: Metadata, args?: ArgsType): Promise => {
// double the data
sample.data = sample.data * 2;
};
export default doubleSize;
看,无论是输入的参数还是函数返回值,都不一样了。但读者也不需要害怕,Pipcook 中的插件类型都是固定的,并且每一种插件的写法和类型定义也都定义好了,具体可以阅读 Pipcook 的插件规范文档。
另外,正如在开篇所说的,Pipcook 通过 Boa 提供了无缝接入 Python 生态的能力,也正因为这种能力,才帮助 JavaScript 社区解决了机器学习生态成熟度和前沿技术使用的问题,那么究竟如何开始使用 Boa 呢?
首先,在 package.json 中的依赖中添加 @pipcook/boa 及对应版本,另外在 “conda.dependencies” 中添加依赖的 Python 包,然后就能在插件中使用了:
const boa = require(‘@pipcook/boa’);
const tensorflow = boa.import(‘tensorflow’);
PipApp(实验功能)
Pipcook 开发团队一直在思考什么样的编程方式,能让前端工程师更容易地使用机器学习,未来机器学习究竟会在前端领域是什么样的呢?因此我们开发了 PipApp,为开发者屏蔽掉了更多技术细节,让开发者只需要关注机器学习的“业务逻辑”。
下面我们来看看一个 PipApp 长什么样:
import { createLearnable, nlp } from ‘@pipcook/app’;
const isCooking = createLearnable(async function(sentence: string) {
return (await nlp.classify(sentence));
});
const isBooking = createLearnable(async function(sentence: string) {
return (await nlp.classify(sentence));
});
(async () => {
console.log(await isCooking(‘test’));
console.log(await isBooking(‘booking test’));
})();
上面的例子,首先通过 createLearnable 创建了一个机器学习上下文,你可以把它理解成一种特殊的 async function,只有在 Learnable 函数块中才能使用 PipApp 提供的机器学习 API。上面的例子,分别创建了两个机器学习流程,在其中都使用了 nlp.classify 来完成一个文本分类的任务。
与运行 Pipeline 不同,PipApp 需要创建一个完整的项目目录,因此在开始之前,我们需要从初始化一个 Node.js 项目开始。
$ npm init
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数前端工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Web前端开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

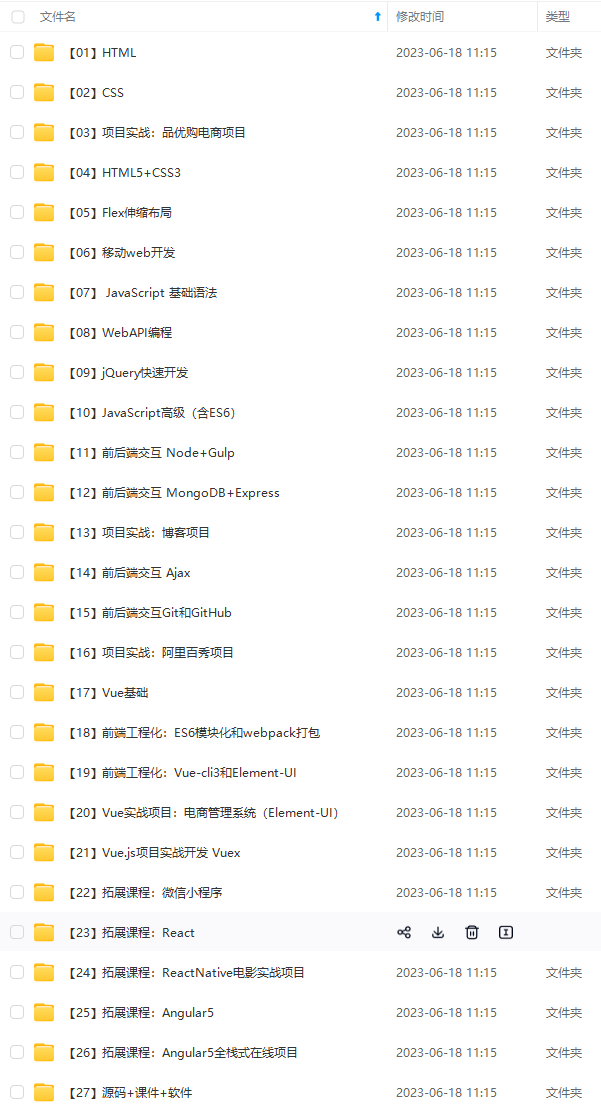
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上前端开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024c (备注前端)

最后
文章到这里就结束了,如果觉得对你有帮助可以点个赞哦
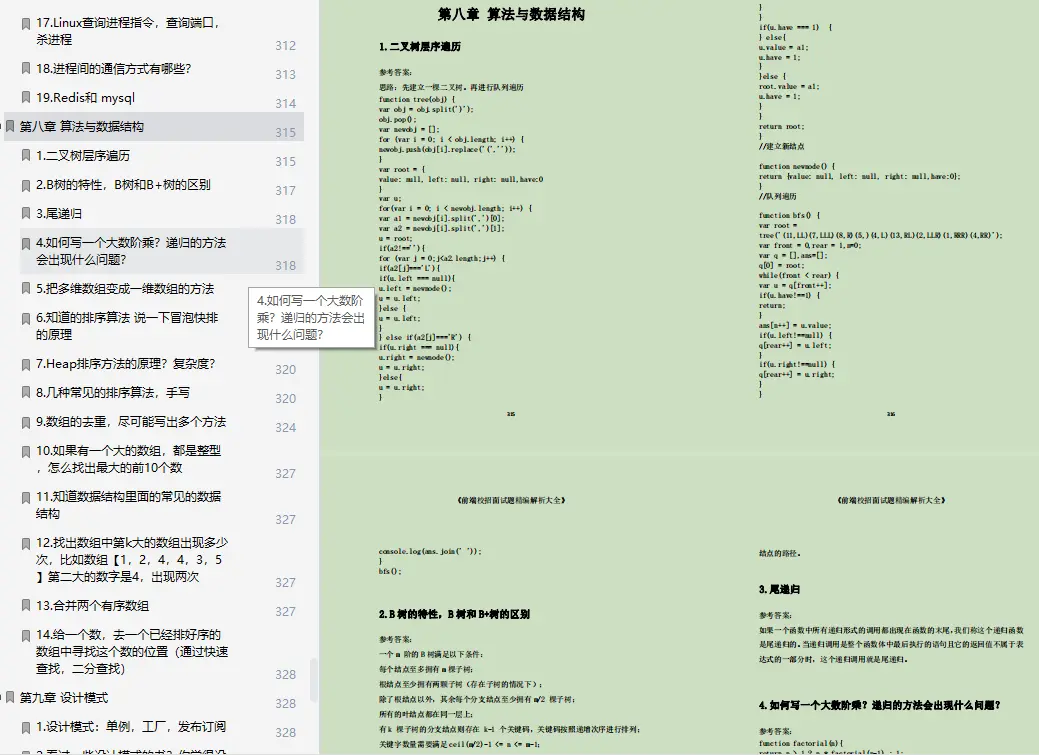
CodeChina开源项目:【大厂前端面试题解析+核心总结学习笔记+真实项目实战+最新讲解视频】
一个人可以走的很快,但一群人才能走的更远。如果你从事以下工作或对以下感兴趣,欢迎戳这里加入程序员的圈子,让我们一起学习成长!
AI人工智能、Android移动开发、AIGC大模型、C C#、Go语言、Java、Linux运维、云计算、MySQL、PMP、网络安全、Python爬虫、UE5、UI设计、Unity3D、Web前端开发、产品经理、车载开发、大数据、鸿蒙、计算机网络、嵌入式物联网、软件测试、数据结构与算法、音视频开发、Flutter、IOS开发、PHP开发、.NET、安卓逆向、云计算
yc9kzRw6-1712327966453)]
一个人可以走的很快,但一群人才能走的更远。如果你从事以下工作或对以下感兴趣,欢迎戳这里加入程序员的圈子,让我们一起学习成长!
AI人工智能、Android移动开发、AIGC大模型、C C#、Go语言、Java、Linux运维、云计算、MySQL、PMP、网络安全、Python爬虫、UE5、UI设计、Unity3D、Web前端开发、产品经理、车载开发、大数据、鸿蒙、计算机网络、嵌入式物联网、软件测试、数据结构与算法、音视频开发、Flutter、IOS开发、PHP开发、.NET、安卓逆向、云计算


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









