







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

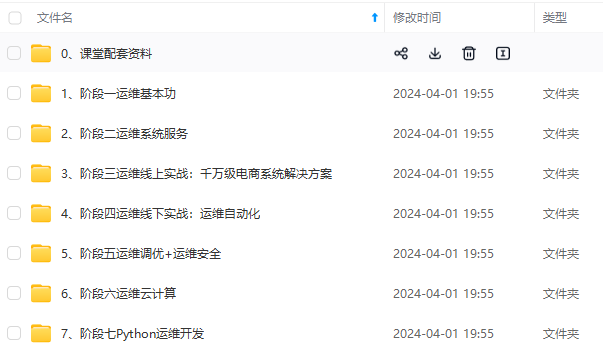
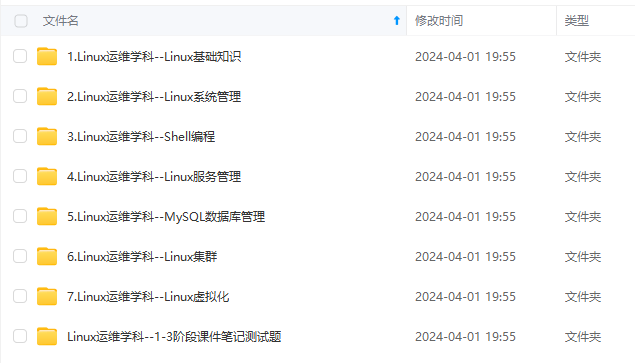
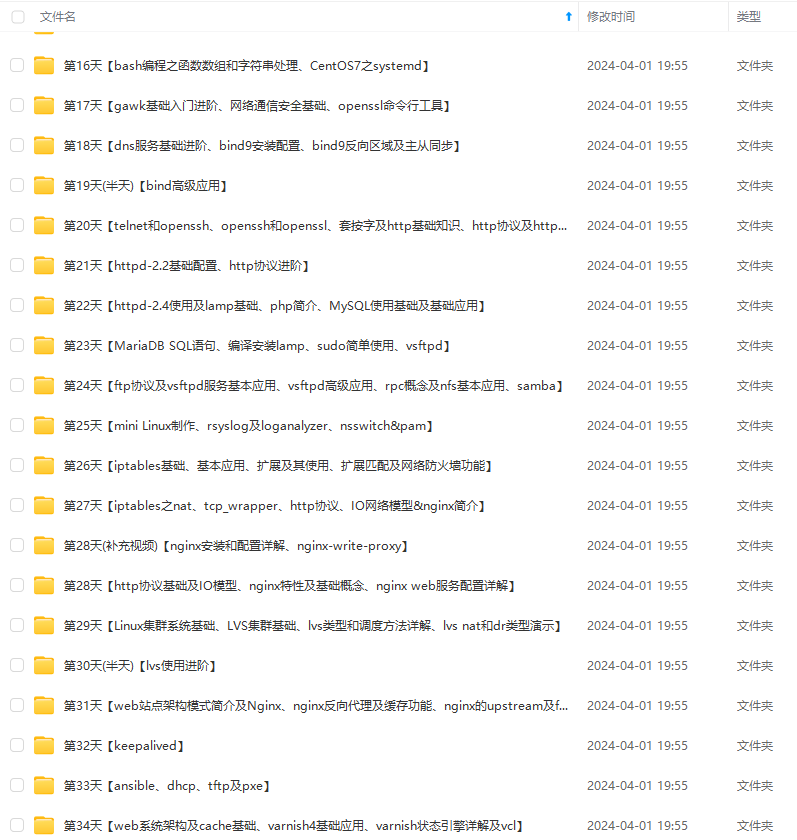
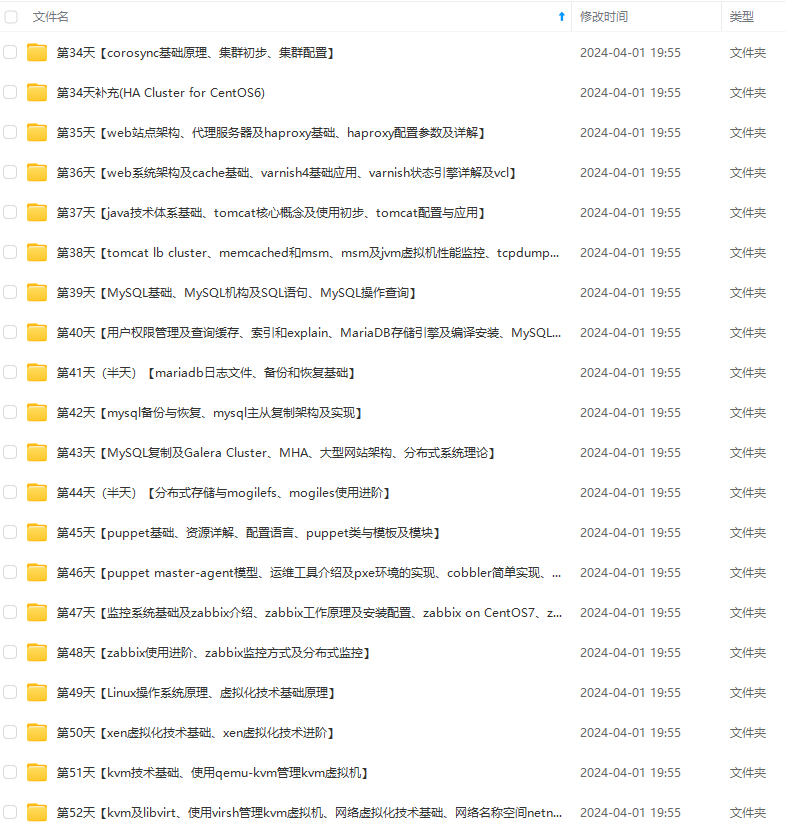
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注运维)

正文
https://github.com/prometheus/graphite_exporter/releases/download/v0.12.0/graphite_exporter-0.12.0.linux-amd64.tar.gz
#haproxy_exporter
https://github.com/prometheus/haproxy_exporter/releases/download/v0.13.0/haproxy_exporter-0.13.0.linux-amd64.tar.gz
#memcached_exporter
https://github.com/prometheus/memcached_exporter/releases/download/v0.9.0/memcached_exporter-0.9.0.linux-amd64.tar.gz
#mysqld_exporter
https://github.com/prometheus/mysqld_exporter/releases/download/v0.14.0/mysqld_exporter-0.14.0.linux-amd64.tar.gz
#node_exporter
https://github.com/prometheus/node_exporter/releases/download/v1.3.1/node_exporter-1.3.1.linux-amd64.tar.gz
#pushgateway
https://github.com/prometheus/pushgateway/releases/download/v1.4.2/pushgateway-1.4.2.linux-amd64.tar.gz
#statsd_exporter
https://github.com/prometheus/statsd_exporter/releases/download/v0.22.4/statsd_exporter-0.22.4.linux-amd64.tar.gz
#dingding插件
https://github.com/timonwong/prometheus-webhook-dingtalk/releases/download/v2.1.0
/prometheus-webhook-dingtalk-2.1.0.linux-amd64.tar.gz
#mongodb_exporter
https://github.com/percona/mongodb_exporter/releases/download/v0.32.0/mongodb_exporter-0.32.0.linux-amd64.tar.gz
#prometheus-mongodb-query-exporter-2.1.0
https://github.com/raffis/mongodb-query-exporter/releases/download/prometheus-mongodb-query-exporter-2.1.0/prometheus-mongodb-query-exporter-2.1.0.tgz
#### 安装go 语言环境
#下载地址:https://go.dev/dl/go1.18.1.linux-amd64.tar.gz
#golang环境变量
export PATH=$PATH:/game/soft/go/bin
#### 安装prometheus
#prometheus环境变量
export PATH=$PATH:/game/soft/prometheus
#### prometheus启动文件
[Unit]
Description=prometheus
After=network.target
[Service]
Type=simple
ExecStart=/game/soft/prometheus/prometheus
–config.file=/game/soft/prometheus/prometheus.yml
–web.enable-lifecycle
–storage.tsdb.path=/game/soft/prometheus/data
–storage.tsdb.retention=30d
–query.timeout=2m
–web.enable-lifecycle
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
User=prometheus
Group=prometheus
[Install]
WantedBy=multi-user.target
访问
http://IP地址:9090/
#### 配置文件prometheus.yml
#
global:
默认拉取频率[ scrape_interval: | default = 1m ]
scrape_interval: 15s
拉取超时时间[ scrape_timeout: | default = 10s ]
scrape_timeout: 10s
告警规则检测频率[ evaluation_interval: | default = 1m ]
evaluation_interval: 30s
通信时添加到任何时间序列或告警的标签[ : … ]
external_labels:
xxx: yyy
#
rule_files:
- “/game/soft/prometheus/rules/*.yml”
#
alerting:
#alert_relabel_configs:
#设定alertmanager和prometheus交互的接口,即alertmanager监听的ip地址和端口
alertmanagers:
- static_configs:
- targets:
- “127.0.0.1:9093”
#
#scrape_configs指定prometheus监控哪些资源。默认会拉取prometheus本身的时间序列数据,通过http://hostIP:9090/metrics进行拉取。
#一个scrape_config指定一组目标和参数,描述如何拉取它们。在一般情况下,一个拉取配置指定一个作业。在高级配置中,这可能会改变。
#可以通过static_configs参数静态配置目标,也可以使用支持的服务发现机制之一动态发现目标。
#此外,relabel_configs在拉取之前,可以对任何目标及其标签进行修改
scrape_configs:
job_name: <job_name>
拉取频率
[ scrape_interval: | default = <global_config.scrape_interval> ]
拉取超时时间
[ scrape_timeout: | default = <global_config.scrape_timeout> ]
拉取的http路径
[ metrics_path:
honor_labels 控制prometheus处理已存在于收集数据中的标签与prometheus将附加在服务器端的标签("作业"和"实例"标签、手动配置的目标标签和由服务发现实现生成的标签)之间的冲突
如果 honor_labels 设置为 “true”,则通过保持从拉取数据获得的标签值并忽略冲突的服务器端标签来解决标签冲突
如果 honor_labels 设置为 “false”,则通过将拉取数据中冲突的标签重命名为"exported_“来解决标签冲突(例如"exported_instance”、“exported_job”),然后附加服务器端标签
注意,任何全局配置的 "external_labels"都不受此设置的影响。在与外部系统的通信中,只有当时间序列还没有给定的标签时,它们才被应用,否则就会被忽略
[ honor_labels: | default = false ]
honor_timestamps 控制prometheus是否遵守拉取数据中的时间戳
如果 honor_timestamps 设置为 “true”,将使用目标公开的metrics的时间戳
如果 honor_timestamps 设置为 “false”,目标公开的metrics的时间戳将被忽略
[ honor_timestamps: | default = true ]
配置用于请求的协议
[ scheme: | default = http ]
可选的http url参数
params:
[ : [, …] ]
在每个拉取请求上配置 username 和 password 来设置 Authorization 头部,password 和 password_file 二选一
basic_auth:
[ username: ]
[ password: ]
[ password_file: ]
在每个拉取请求上配置 bearer token 来设置 Authorization 头部,bearer_token 和 bearer_token_file 二选一
[ bearer_token: ]
在每个拉取请求上配置 bearer_token_file 来设置 Authorization 头部,bearer_token_file 和 bearer_token 二选一
[ bearer_token_file: /path/to/bearer/token/file ]
配置拉取请求的TLS设置
tls_config:
[ <tls_config> ]
可选的代理URL
[ proxy_url: ]
Azure服务发现配置列表
azure_sd_configs:
[ - <azure_sd_config> … ]
Consul服务发现配置列表
consul_sd_configs:
[ - <consul_sd_config> … ]
DNS服务发现配置列表
dns_sd_configs:
[ - <dns_sd_config> … ]
EC2服务发现配置列表
ec2_sd_configs:
[ - <ec2_sd_config> … ]
OpenStack服务发现配置列表
openstack_sd_configs:
[ - <openstack_sd_config> … ]
file服务发现配置列表
file_sd_configs:
[ - <file_sd_config> … ]
GCE服务发现配置列表
gce_sd_configs:
[ - <gce_sd_config> … ]
Kubernetes服务发现配置列表
kubernetes_sd_configs:
[ - <kubernetes_sd_config> … ]
Marathon服务发现配置列表
marathon_sd_configs:
[ - <marathon_sd_config> … ]
AirBnB’s Nerve服务发现配置列表
nerve_sd_configs:
[ - <nerve_sd_config> … ]
Zookeeper Serverset服务发现配置列表
serverset_sd_configs:
[ - <serverset_sd_config> … ]
Triton服务发现配置列表
triton_sd_configs:
[ - <triton_sd_config> … ]
静态配置目标列表
static_configs:
[ - <static_config> … ]
目标relabel配置列表
relabel_configs:
[ - <relabel_config> … ]
metric relabel配置列表
metric_relabel_configs:
[ - <relabel_config> … ]
每次拉取样品的数量限制
metric relabelling之后,如果有超过这个数量的样品,整个拉取将被视为失效。0表示没有限制
[ sample_limit: | default = 0 ]
#
#### 配置实例
my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
scrape_timeout is set to the global default (10s).
Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
为了做好运维面试路上的助攻手,特整理了上百道 【运维技术栈面试题集锦】 ,让你面试不慌心不跳,高薪offer怀里抱!
这次整理的面试题,小到shell、MySQL,大到K8s等云原生技术栈,不仅适合运维新人入行面试需要,还适用于想提升进阶跳槽加薪的运维朋友。

本份面试集锦涵盖了
- 174 道运维工程师面试题
- 128道k8s面试题
- 108道shell脚本面试题
- 200道Linux面试题
- 51道docker面试题
- 35道Jenkis面试题
- 78道MongoDB面试题
- 17道ansible面试题
- 60道dubbo面试题
- 53道kafka面试
- 18道mysql面试题
- 40道nginx面试题
- 77道redis面试题
- 28道zookeeper
总计 1000+ 道面试题, 内容 又全含金量又高
- 174道运维工程师面试题
1、什么是运维?
2、在工作中,运维人员经常需要跟运营人员打交道,请问运营人员是做什么工作的?
3、现在给你三百台服务器,你怎么对他们进行管理?
4、简述raid0 raid1raid5二种工作模式的工作原理及特点
5、LVS、Nginx、HAproxy有什么区别?工作中你怎么选择?
6、Squid、Varinsh和Nginx有什么区别,工作中你怎么选择?
7、Tomcat和Resin有什么区别,工作中你怎么选择?
8、什么是中间件?什么是jdk?
9、讲述一下Tomcat8005、8009、8080三个端口的含义?
10、什么叫CDN?
11、什么叫网站灰度发布?
12、简述DNS进行域名解析的过程?
13、RabbitMQ是什么东西?
14、讲一下Keepalived的工作原理?
15、讲述一下LVS三种模式的工作过程?
16、mysql的innodb如何定位锁问题,mysql如何减少主从复制延迟?
17、如何重置mysql root密码?
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注运维)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
15、讲述一下LVS三种模式的工作过程?
16、mysql的innodb如何定位锁问题,mysql如何减少主从复制延迟?
17、如何重置mysql root密码?
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注运维)
[外链图片转存中…(img-zDL5nl8G-1713392842721)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









