







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Linux运维全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

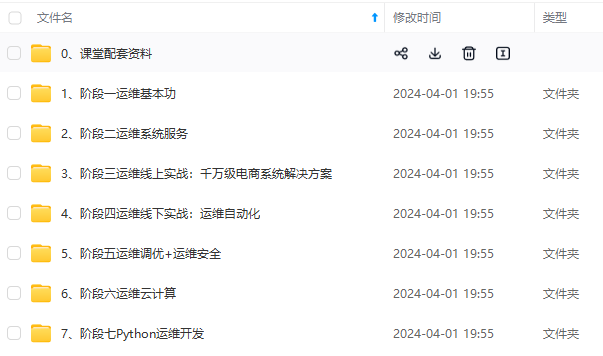
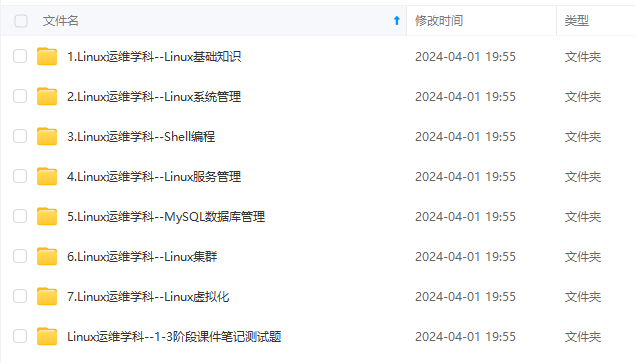
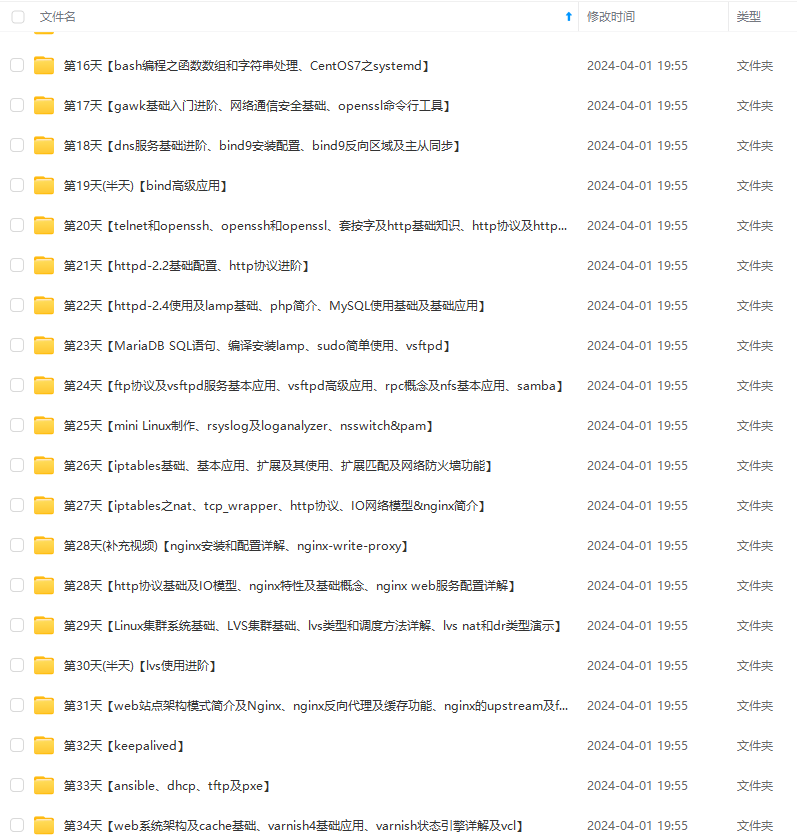
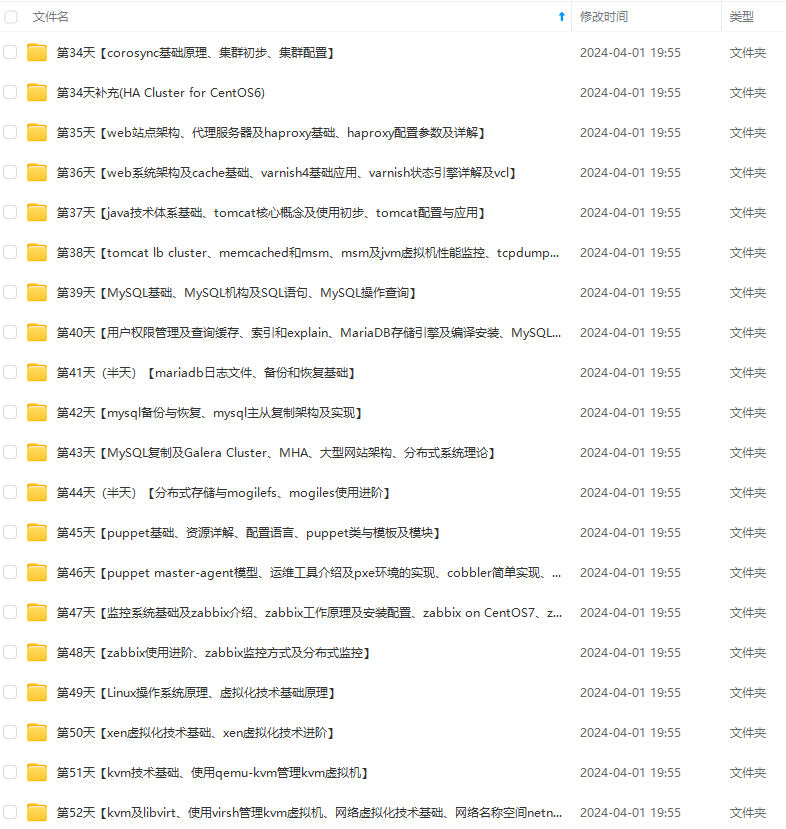
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上运维知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注运维)

正文
2、tail 截取文件末尾指定行数
#将file.txt中的末尾100行提取到renamefile.txt中
tail -n 100 file.txt > renamefile.txt
3、head与tail结合截取指定起始至结尾行的文件内容
#将file.txt中的前100行到200行提取到renamefile.txt中
#先提取前面全部的200行,然后tail截取200行中的末尾100行。
head -n 200 file.txt | tail -n 100 > renamefile.txt
4、split分割文件
### 先看看帮助文件吧
Usage: split [OPTION]... [FILE [PREFIX]]
Output pieces of FILE to PREFIXaa, PREFIXab, ...;
default size is 1000 lines, and default PREFIX is 'x'.
With no FILE, or when FILE is -, read standard input.
Mandatory arguments to long options are mandatory for short options too.
-a, --suffix-length=N generate suffixes of length N (default 2)
--additional-suffix=SUFFIX append an additional SUFFIX to file names
-b, --bytes=SIZE put SIZE bytes per output file
-C, --line-bytes=SIZE put at most SIZE bytes of records per output file
-d use numeric suffixes starting at 0, not alphabetic
--numeric-suffixes[=FROM] same as -d, but allow setting the start value
-x use hex suffixes starting at 0, not alphabetic
--hex-suffixes[=FROM] same as -x, but allow setting the start value
-e, --elide-empty-files do not generate empty output files with '-n'
--filter=COMMAND write to shell COMMAND; file name is $FILE
-l, --lines=NUMBER put NUMBER lines/records per output file
-n, --number=CHUNKS generate CHUNKS output files; see explanation below
-t, --separator=SEP use SEP instead of newline as the record separator;
'\0' (zero) specifies the NUL character
-u, --unbuffered immediately copy input to output with '-n r/...'
--verbose print a diagnostic just before each
output file is opened
--help display this help and exit
--version output version information and exit
The SIZE argument is an integer and optional unit (example: 10K is 10*1024).
Units are K,M,G,T,P,E,Z,Y (powers of 1024) or KB,MB,... (powers of 1000).
Binary prefixes can be used, too: KiB=K, MiB=M, and so on.
CHUNKS may be:
N split into N files based on size of input
K/N output Kth of N to stdout
l/N split into N files without splitting lines/records
l/K/N output Kth of N to stdout without splitting lines/records
r/N like 'l' but use round robin distribution
r/K/N likewise but only output Kth of N to stdout
GNU coreutils online help: <https://www.gnu.org/software/coreutils/>
Full documentation <https://www.gnu.org/software/coreutils/split>
or available locally via: info '(coreutils) split invocation'
#按照大小分个指定文件
# -b 指定要分割成的文件大小, renamefile为分割后文件的前缀,后面一般接xaa等顺序的字母编号
split -b 1M file.txt renamefile
#按行数将文件分割成多个文件,
# -l 指定行数,renamefile为分割后文件的前缀
split -l 100 file.txt renamefile
5、sed分割文件
sed的功能很强大,不仅可以提取文件,更重要的是对文件进行具体内容的操作,如插入,替换等。下面是默认的系统帮助文件,仅作参考
####
Usage: sed [OPTION]... {script-only-if-no-other-script} [input-file]...
-n, --quiet, --silent
suppress automatic printing of pattern space
--debug
annotate program execution
-e script, --expression=script
add the script to the commands to be executed
-f script-file, --file=script-file
add the contents of script-file to the commands to be executed
--follow-symlinks
follow symlinks when processing in place
-i[SUFFIX], --in-place[=SUFFIX]
edit files in place (makes backup if SUFFIX supplied)
-c, --copy
use copy instead of rename when shuffling files in -i mode
-b, --binary
does nothing; for compatibility with WIN32/CYGWIN/MSDOS/EMX
(open files in binary mode; CR+LF are not processed specially)
-l N, --line-length=N
specify the desired line-wrap length for the `l' command
--posix
disable all GNU extensions.
-E, -r, --regexp-extended
use extended regular expressions in the script
(for portability use POSIX -E).
-s, --separate
consider files as separate rather than as a single,
continuous long stream.
--sandbox
operate in sandbox mode (disable e/r/w commands).
-u, --unbuffered
load minimal amounts of data from the input files and flush
the output buffers more often
-z, --null-data
separate lines by NUL characters
--help display this help and exit
--version output version information and exit
If no -e, --expression, -f, or --file option is given, then the first
non-option argument is taken as the sed script to interpret. All
remaining arguments are names of input files; if no input files are
specified, then the standard input is read.
GNU sed home page: <https://www.gnu.org/software/sed/>.
General help using GNU software: <https://www.gnu.org/gethelp/>.
E-mail bug reports to: <bug-sed@gnu.org>.
分割文件操作示例:
###提取指定行,打印或输出到指定文件
#打印第12行
sed -n '12p' file.txt
[root@vmgmt ~]# sed -n '12p' file.txt
12
#获取第12行内容到新文件, 后面需要输入到文件的直接使用“>” 或“>>” 符号接新文件名,
sed -n '12p' file.txt >newfile.txt
#获取文件的最后一行
sed -n '$p' file.txt
##获取指定多行
sed -n -e '2p' -e '5p' file.txt
[root@vmgmt ~]# sed -n -e '2p' -e '5p' file.txt
2
5
##获取file文件的第10行到15行
sed -n '10,+5p' file.txt
[root@vmgmt ~]# sed -n '10,+5p' file.txt
10
11
12
13
14
15
#获取前面1到5行
sed -e '5q' file.txt
[root@vmgmt ~]# sed -e '5q' file.txt
1
2
3
4
5
#获取file中的偶数行
sed -n 'n;p' file.txt
[root@vmgmt ~]# sed -n 'n;p' file.txt
2
4
6
8
10
12
14
16
18
20
22
24
#获取file中的奇数行
sed -n 'p;n' file.txt
[root@vmgmt ~]# sed -n 'p;n' file.txt
1
3
5
7
9
11
13
15
17
19
21
23
25
###############正则表达式操作, / / ,反斜杠之间填写正则规则,具体请参考正则表达式的填写方式。
#获取文件中包含 2 字符串的所有行
sed -n '/2/p' file.txt
[root@vmgmt ~]# sed -n '/2/p' file.txt
2
12
20
21
22
23
24
25
#获取以字符1为开头的所有行
sed -n '/^1/p' file.txt
[root@vmgmt ~]# sed -n '/^1/p' file.txt
1
10
11
12
13
14
15
16
17
18
19
#获取以字符1为结尾的所有行
sed -n '/1$/p' file.txt
[root@vmgmt ~]# sed -n '/1$/p' file.txt
1
11
21
#开头结尾组合输出 以字符1开头,或以字符3结尾的行
sed -n '/^2|3$/p' file.txt
[root@vmgmt ~]# sed -rn '/^2|3$/p' file.txt
2
3
13
20
21
22
23
24
25
#获取指定要排除或删除的行后的文件内容
#删除2-6行以外的其他内容
sed '2,6!d' file.txt
[root@vmgmt ~]# sed '2,6!d' file.txt
2
3
4
5
6
#获取除2-6行以外的其他内容
sed '2,6d' file.txt
[root@vmgmt ~]# sed '2,6d' file.txt
1
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
#删除文件中的空行
sed '/^&/d' file.txt
#正则表达式方式删除
#删除包含1字符的行
sed '/1/d' file.txt
[root@vmgmt ~]# sed '/1/d' file.txt
2

最全的Linux教程,Linux从入门到精通
======================
1. **linux从入门到精通(第2版)**
2. **Linux系统移植**
3. **Linux驱动开发入门与实战**
4. **LINUX 系统移植 第2版**
5. **Linux开源网络全栈详解 从DPDK到OpenFlow**

第一份《Linux从入门到精通》466页
====================
内容简介
====
本书是获得了很多读者好评的Linux经典畅销书**《Linux从入门到精通》的第2版**。本书第1版出版后曾经多次印刷,并被51CTO读书频道评为“最受读者喜爱的原创IT技术图书奖”。本书第﹖版以最新的Ubuntu 12.04为版本,循序渐进地向读者介绍了Linux 的基础应用、系统管理、网络应用、娱乐和办公、程序开发、服务器配置、系统安全等。本书附带1张光盘,内容为本书配套多媒体教学视频。另外,本书还为读者提供了大量的Linux学习资料和Ubuntu安装镜像文件,供读者免费下载。

**本书适合广大Linux初中级用户、开源软件爱好者和大专院校的学生阅读,同时也非常适合准备从事Linux平台开发的各类人员。**
> 需要《Linux入门到精通》、《linux系统移植》、《Linux驱动开发入门实战》、《Linux开源网络全栈》电子书籍及教程的工程师朋友们劳烦您转发+评论
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注运维)**

**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
nux初中级用户、开源软件爱好者和大专院校的学生阅读,同时也非常适合准备从事Linux平台开发的各类人员。**
> 需要《Linux入门到精通》、《linux系统移植》、《Linux驱动开发入门实战》、《Linux开源网络全栈》电子书籍及教程的工程师朋友们劳烦您转发+评论
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注运维)**
[外链图片转存中...(img-Jp8wkeyF-1713367116961)]
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**















 2760
2760











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









