







int j = i - gap;
for (; j >= 0; j -= gap) {
if (elem[j] > tmp) {
elem[j + gap] = elem[j];
} else {
break;
}
}
elem[j + gap] = tmp;
}
}
public void shellSort(int[] elem) {
int gap = elem.length;
while (gap > 1) {
gap = gap / 3 + 1; // 希尔排序的增量是不确定的
shell(elem, gap);
}
}
优化:希尔排序快不快主要取决于怎么去取增量序列 , 比如二分法或者knuth序列法 有兴趣的读者可以去了解一下
时间复杂度: O(n ^ (1.3 - 2))
空间复杂度:O(1)
稳定性: 不稳定
堆排序
=======
原理:指利用堆这种数据结构所设计的一种排序算法。堆是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。

- 大顶堆:每个节点的值都大于或等于其子节点的值,在堆排序算法中用于升序排列

- 小顶堆:每个节点的值都小于或等于其子节点的值,在堆排序算法中用于降序排列

由于堆排序涉及到数据结构中堆的知识 如果还没学过堆的读者 可以先去作者的另一篇文章 「Java数据结构」- 堆(优先级队列)") 了解一下, 在排序之间要先将数组元素构建成一个堆**<建大堆还是小堆,取决于排升序还是排降序 , 作者这里讲解的是排升序 , 构建的是大堆>**
堆排序(升序)动图演示
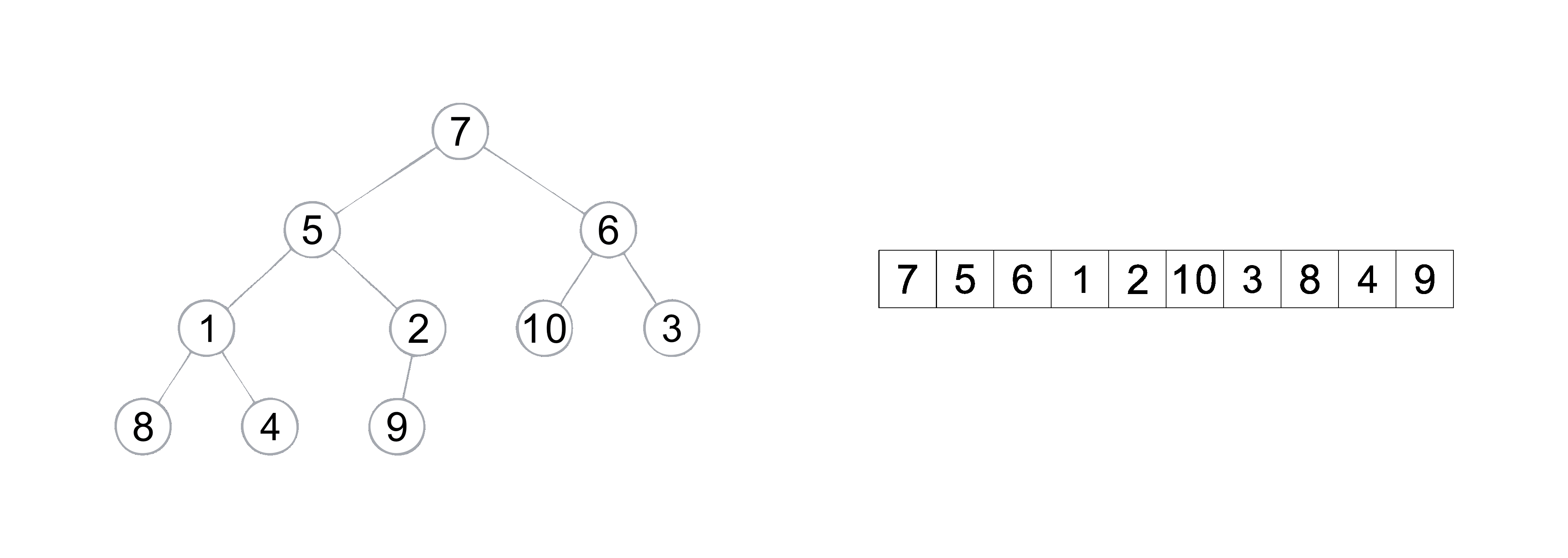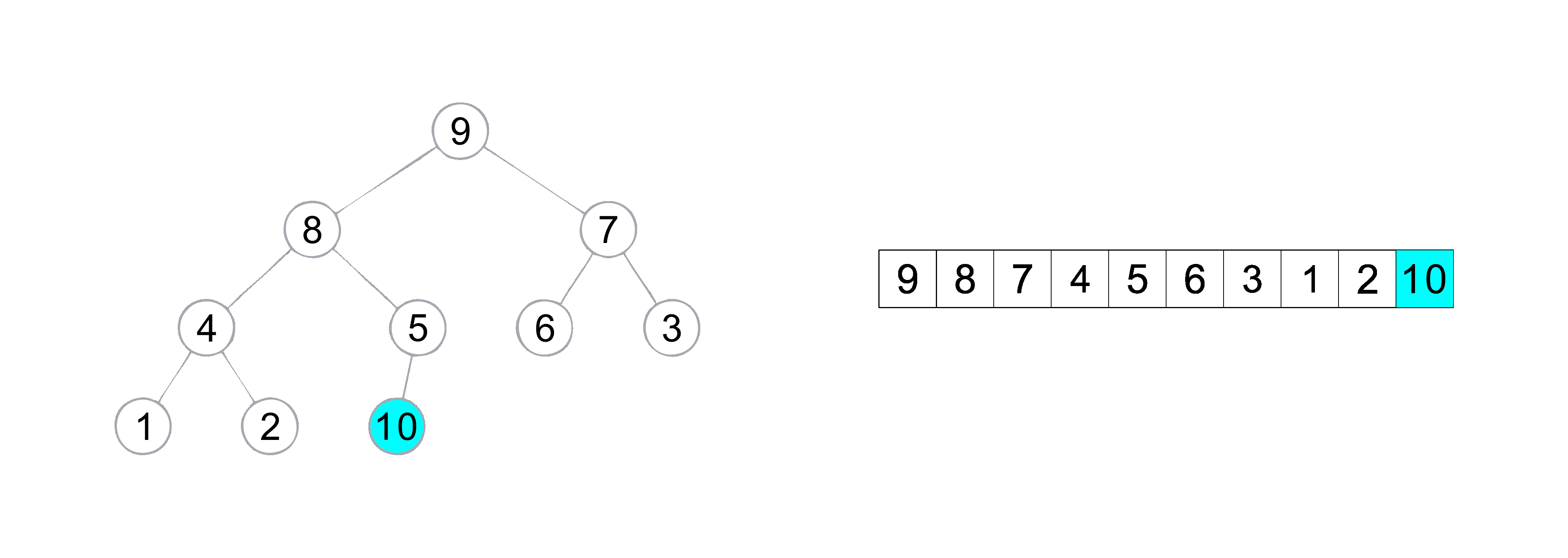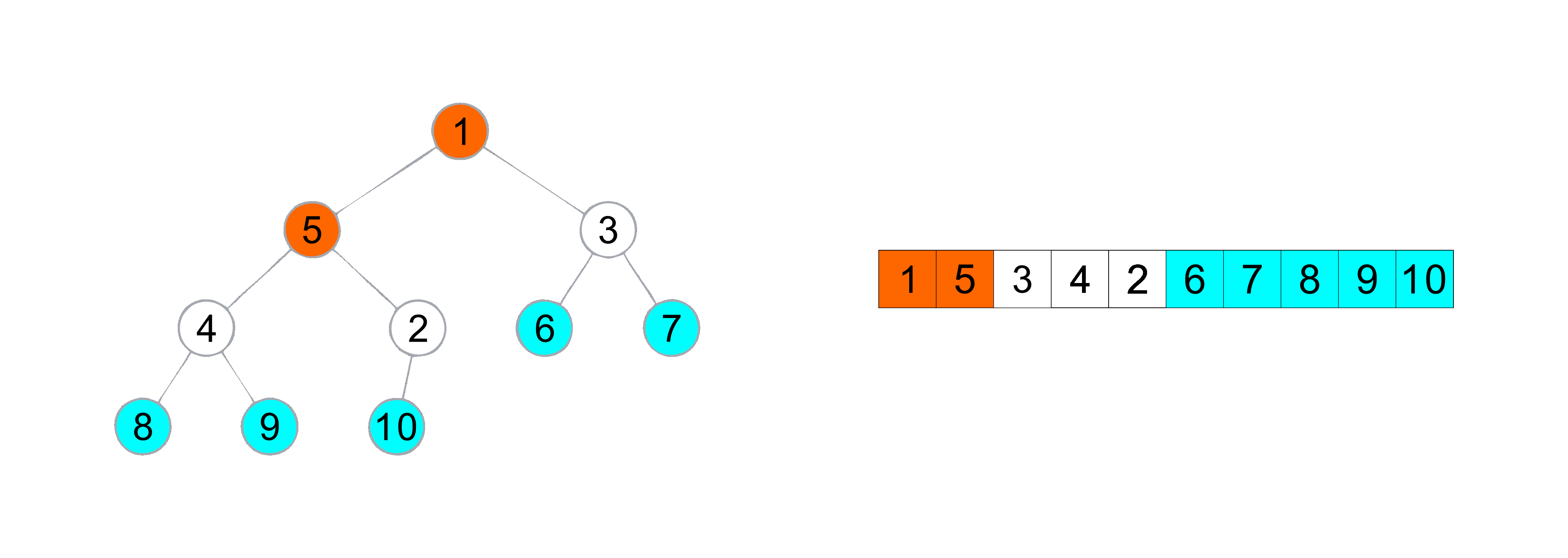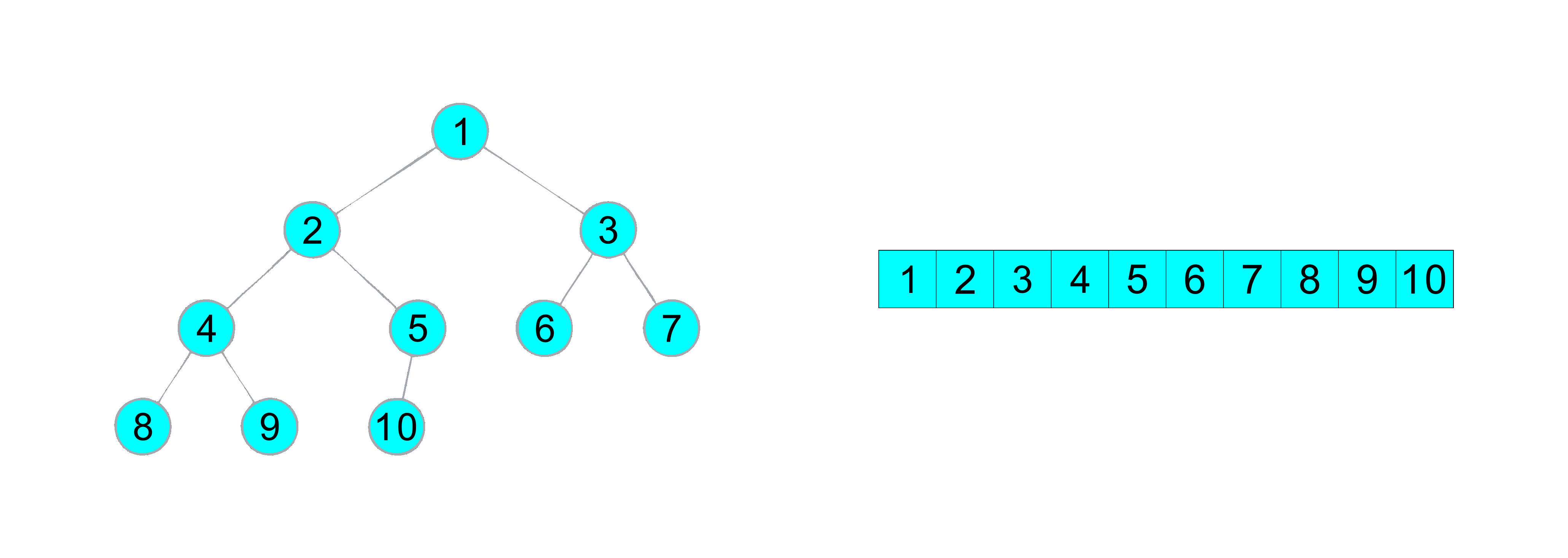
构建完堆之后 , 由于堆的特性 , 在堆顶的元素是数组中最大的元素, 所以将堆顶与数组最后元素进行交换 ,然后再从堆顶进行向下调整将第 N 大的元素调到堆顶 , 所以我们只需要控制向上调整的边界 , 然后重复 交换 和 向上调整 的操作即可编写出堆排序
代码实现
// 向下调整代码
public void adjustDown(int[] elem, int parent, int len) {
int child = 2 * parent + 1;
while (child < len) {
if (child + 1 < len && elem[child] < elem[child + 1]) {
child++;
}
if (elem[parent] < elem[child]) {
swap(elem, child, parent);
parent = child;
child = parent * 2 + 1;
} else {
break;
}
}
}
// 建堆代码
public void createHeap(int[] elem) {
for (int i = (elem.length - 1 - 1) / 2; i >= 0; i–) {
adjustDown(elem, i, elem.length);
}
}
// 堆排序
public void heapSort(int[] elem) {
createHeap(elem);
int len = elem.length - 1;
//从后往前调整
while (len > 0) {
//交换堆顶和堆尾的元素
swap(elem, 0, len);
//重新调整
adjustDown(elem, 0, len);
len–;
}
}
重点:排升序建大堆 , 排降序建小堆
==========================
时间复杂度: O(n * logn)
空间复杂度:O(1)
稳定性: 不稳定
快速排序
========
原理:从待排序区间选择一个数,作为基准值 , 遍历整个待排序区间,将比基准值小的(可以包含相等的)放到基准值的左边,将比基准值大的(可 以包含相等的)放到基准值的右边 , 采用分治思想,对左右两个小区间按照同样的方式处理,直到小区间的长度 == 1,代表已经有序,或者小区间 的长度 == 0,代表没有数据
快速排序挖坑法动图演示

实现快排的方法有多种 <Hoare 法 , 挖坑法 , 前后指针法> 这里作者挑 挖坑法 来给大家进行讲解
挖坑法
给定一组数据

思路
选区间最左边作为基准值 使用变量 key 进行保存 , 给定 low 变量指向这个区间的最左边 且 low 起始位置就是一个**“坑”, 给定 high 变量指向这个区间最最右边 , 由于基准值被变量 key 保存了 , 所以可以认定最左边的数可以进行覆盖 , 也就形成了一个’‘坑’'** , 可以供其它值进行填坑

此时先从 high 位置开始向前找比基准值 key 更小的值 , 如果遇到比 key 值大的元素则继续向前寻找 , 直至找到更小的元素 , 找到时则将该值填入到 low 位置上 , 此时在 high 位置也形成了一个可覆盖的 “坑”

随着 high 位置停止向前移动 , 接下来就使 low 位置开始向后寻找大于 key 值的元素 , 遇到小于 key 值的元素则继续向后走 , 直至找到比 key 值更大的元素则停止移动 , 此时将该 low 位置上的元素填入刚才 high 形成的 “坑”

重复以上两个操作 ,那怎么控制什么时候不继续往下找呢 , 给的结束条件是 : 如果 low 指针和 high 指针相遇了 , 这个时候就可以将基准值 key 放到两指针相遇的位置 , 当前这个 key 值的左边是比它小的数 , 而 key 值的右边就是比它大的数 , 此时的 key 值就处于有序的位置上

注意:如果选基准时 , 选的是最左边的元素为基准 , 那么第一次找元素必须先从右边开始寻找!!!
到这还未结束 , 挖坑法只是辅助某个元素放到有序集合中属于它的正确位置上 , 而快速排序还有一个核心思想 : 分治思想
分治
分治,字面上的解释是“分而治之”,就是把一个复杂的问题分成两个或更多的相同或相似的子问题,再把子问题分成更小的子问题……直到最后子问题可以简单的直接求解,原问题的解即子问题的解的合并
在快排中的分治 , 是将一个大的无序区间分成多个小的无序区间 , 快速排序中通过 挖坑法 计算出基准值位置 , 而无序区间就从基准值位置开始分割 , 基准左边为一个无序区间 , 基准值位置右边为一个无序区间 , 而基准值已经有序不参与分割

随着小区间再进行计算基准值 与 分割 , 直至区间长度为 1 时 停止切割 , 使用变量 start 记录当前区间的最左边的位置 , 使用变量 end 记录当前区间最右边的位置 , 当每次挖坑法执行完之后 , 用 pivot 记录基准位置 , 所以可以使用递归模拟分割区间
递推公式 : quickSort(start , end) = quick(start , pivot - 1) + quick(pivot + 1 , end)
代码实现
private int partition(int[] elem, int low, int high) {
int key = elem[low];//保存基准值,形成一个坑
while (low < high) {
//找比基准值小的值,记录该下标
while (low < high && elem[high] >= key) {
high–;
}
//找到后将左边形成的坑放置比基准小的值,此时右边就新形成了一个坑
elem[low] = elem[high];
//找比基准值大的值,记录该下标
while (low < high && elem[low] <= key) {
low++;
}
//找到后将右边形成的坑放置比基准大的值,此时左边就新形成了一个坑
elem[high] = elem[low];
}
//low 和 high相遇时,一定是个坑,此时将基准放到low下标处
elem[low] = key;
return low;
}
private void quick(int[] elem, int start, int end) {
//递归结束条件
if (start >= end) {
return;
}
int pivot = partition(elem, start, end); // 拿到基准值位置
quick(elem, start, pivot - 1); // 在基准左边形成一个区间
quick(elem, pivot + 1, end); // 在基准右边形成一个区间
}
public void quickSort(int[] elem) {
quick(elem, 0, elem.length - 1);
}
作者这里介绍的是简单版本的快速排序 , 这个快速排序未经过任何优化 , 有兴趣的读者可以去了解一下关于快速排序的优化方法
时间复杂度: O(n * logn)
空间复杂度:O(n * logn)
稳定性: 不稳定
归并排序
========
原理:将已有序的子序列合并,得到完全有序的序列,即先使每个子序列有序,再使子 序列段间有序
归并排序动图演示

分割
归并排序同样采用的是分治思想 , 归并排序是先进行分割 , 将一个大区间分割成多个小区间 , 所有区间以中间值作为基准 , 从每个区间中间值开始切割 , 直至区间长度为 1 时停止分割

对于分割区间的过程 , 我们可以使用递归来模拟 , 我们可以定义一个变量 start 记录当前区间最左边 , 变量 end 记录区间最右边 , mid 变量记录基准位置 由于是通过中间值来进行切割 , 可以得出 左区间 = start ~ mid 而 右区间 = mid+1 ~ end , 所以可以得到递推公式如下
递推公式:mergeSort(start , end) = merge(start , mid) + merge(mid+1 , end)
合并
当分割区间长度为 1 时就进行合并 , 合并过程中以基准值分割的两个区间中的元素进行比较 , 放入到一个新的数组中

用变量 s1 记录左区间开始的索引位置 low , s1 索引结束位置为 mid , 再用变量 s2 记录右区间的开始的索引位置mid + 1 , s2 索引结束位置为 high ,两个索引在原数组中进行元素比较大小 , 小的元素先放到新数组中 , 随后对应的索引向前走一步 , 当两个指针其中一个索引超出了索引结束位置时退出比较 , 将剩下没超过索引位置的索引 , 从当前位置开始向后所有的元素添加到新的数组中 , 直至超出索引位置。
经过以上操作 , 此时的新数组中的元素是有序的 , 然后将新数组中的元素重新拷贝到原数组中 , 拷贝完成后 , 原数组中 low 至 high 区间中的元素就是有序的。
重复以上合并的操作 , 直至所有区间都合并完成 , 这个时候就排序完成了

代码实现
// 合并操作
// 3
public void merge(int[] elem, int low, int mid, int high) {
//用一个临时数组用来交换顺序
int[] tmp = new int[high - low + 1];
int s1 = low; // 左区间开始位置
int s2 = mid + 1; // 右区间开始位置
int k = 0;//临时数组的索引开始位置
// 比较两个区间中的元素
while (s1 <= mid && s2 <= high) {
if (elem[s1] <= elem[s2]) {
tmp[k++] = elem[s1++];
} else {
tmp[k++] = elem[s2++];
}
}
//循环结束两种情况
//1、左区间还剩数值没有被放到tmp数组上
while (s1 <= mid) {
tmp[k++] = elem[s1++];
}
//2、右区间还剩数值没有被放到tmp数组上
while (s2 <= high) {
tmp[k++] = elem[s2++];
}
//将tmp数组的值放回到原数组中
//[i+low] 就是当前的左区间下标开始位置
for (int i = 0; i < tmp.length; i++) {
elem[i + low] = tmp[i];
}
}
// 切割操作
// 2
public void mergeSortInternal(int[] elem, int start, int end) {
//递归终止条件,拆分到只有一个数的时候停止递归
if (start >= end) {
return;
}
//选出中间下标作为拆分基准
int mid = start + (end - start) / 2;
//递归拆分
mergeSortInternal(elem, start, mid); // 左区间
mergeSortInternal(elem, mid + 1, end);// 右区间
//切割完成后进行合并
merge(elem, start, mid, end);
}
// 归并排序
// 1
public void mergeSort(int[] elem) {
mergeSortInternal(elem, 0, elem.length - 1);
}
时间复杂度: O(n * logn)
空间复杂度:O(n)
稳定性: 稳定
计数排序
========
计数排序是一种牺牲内存空间来换取低时间的排序算法,同时它也是一种不基于比较的算法。这里的不基于比较指的是数组元素之间不存在比较大小的排序算法
计数排序动图演示
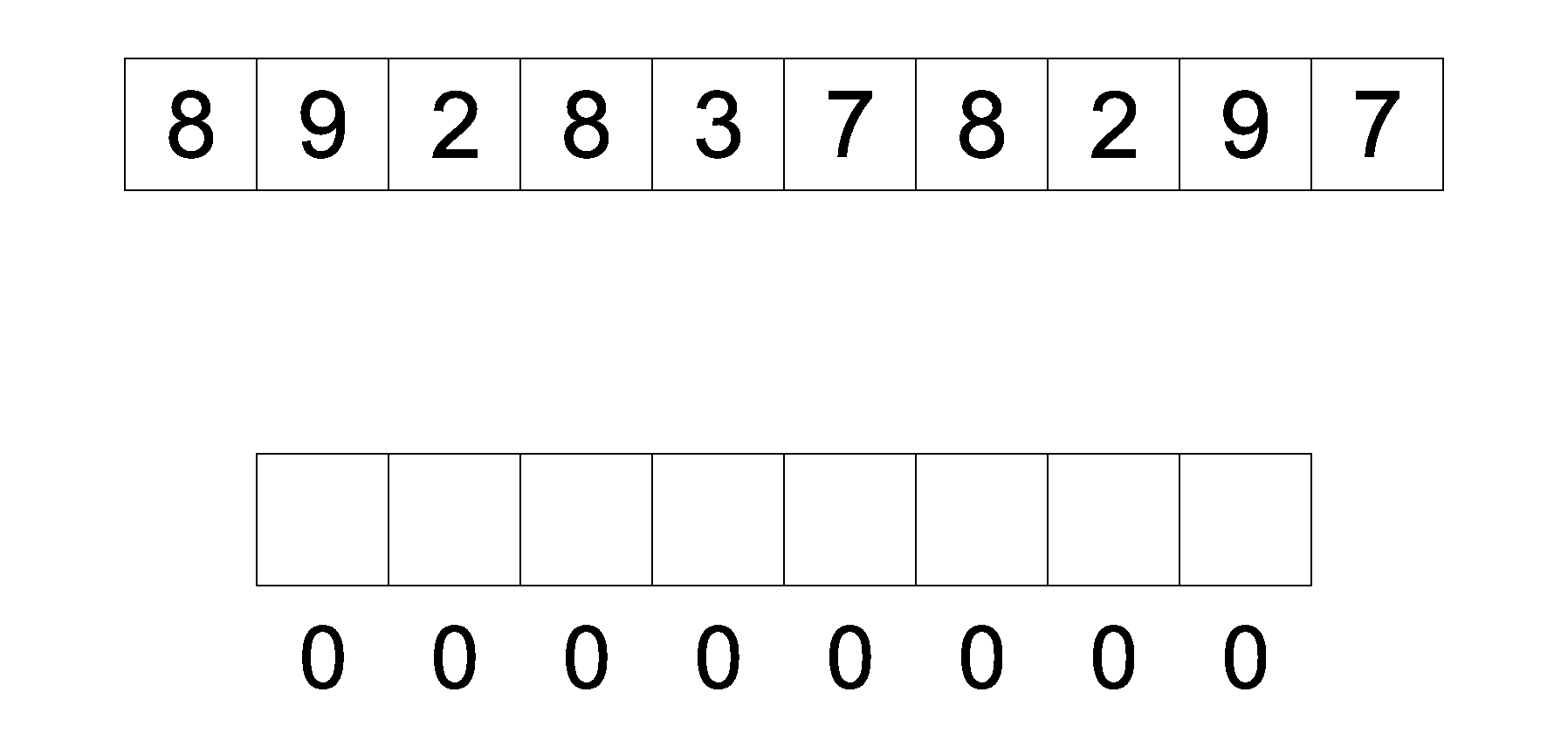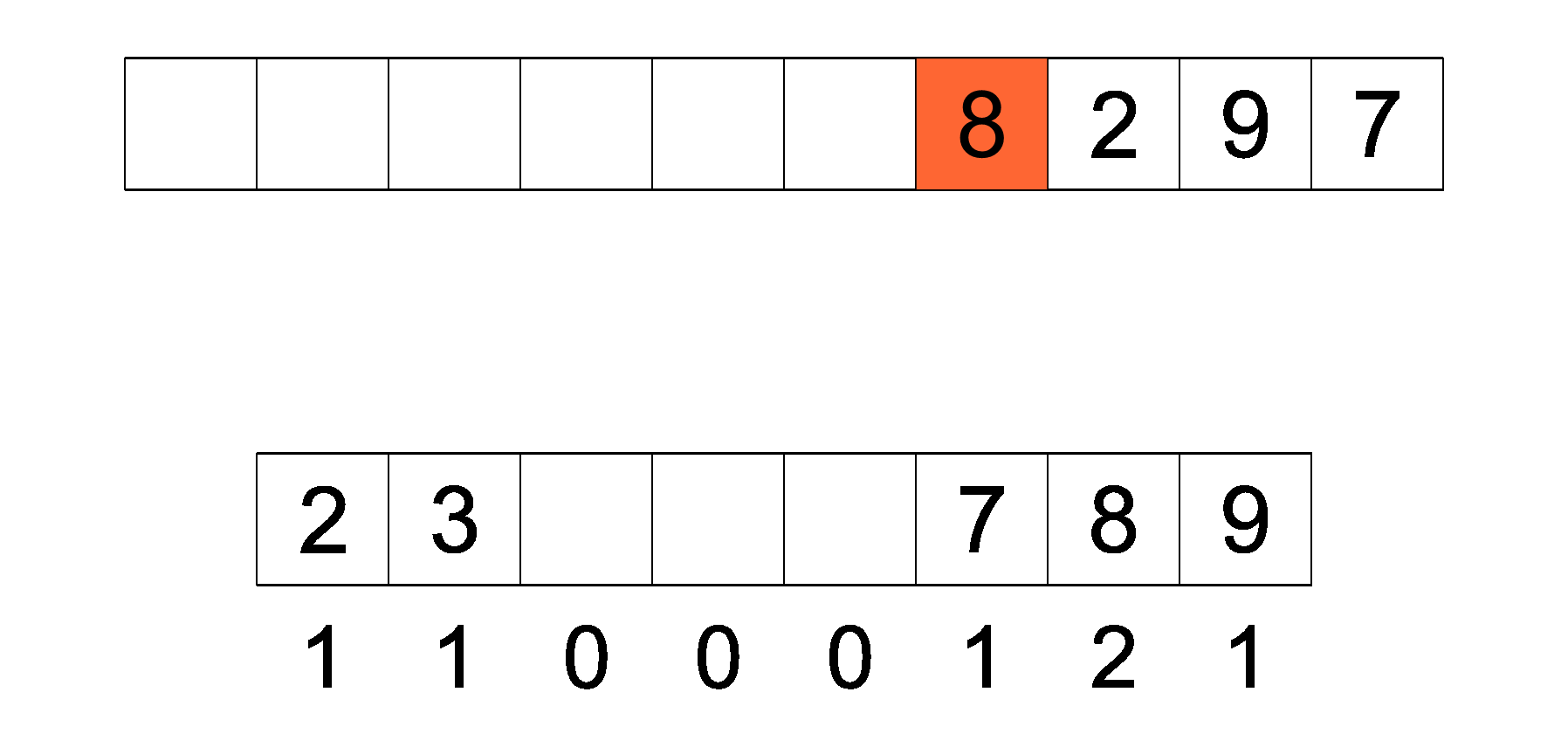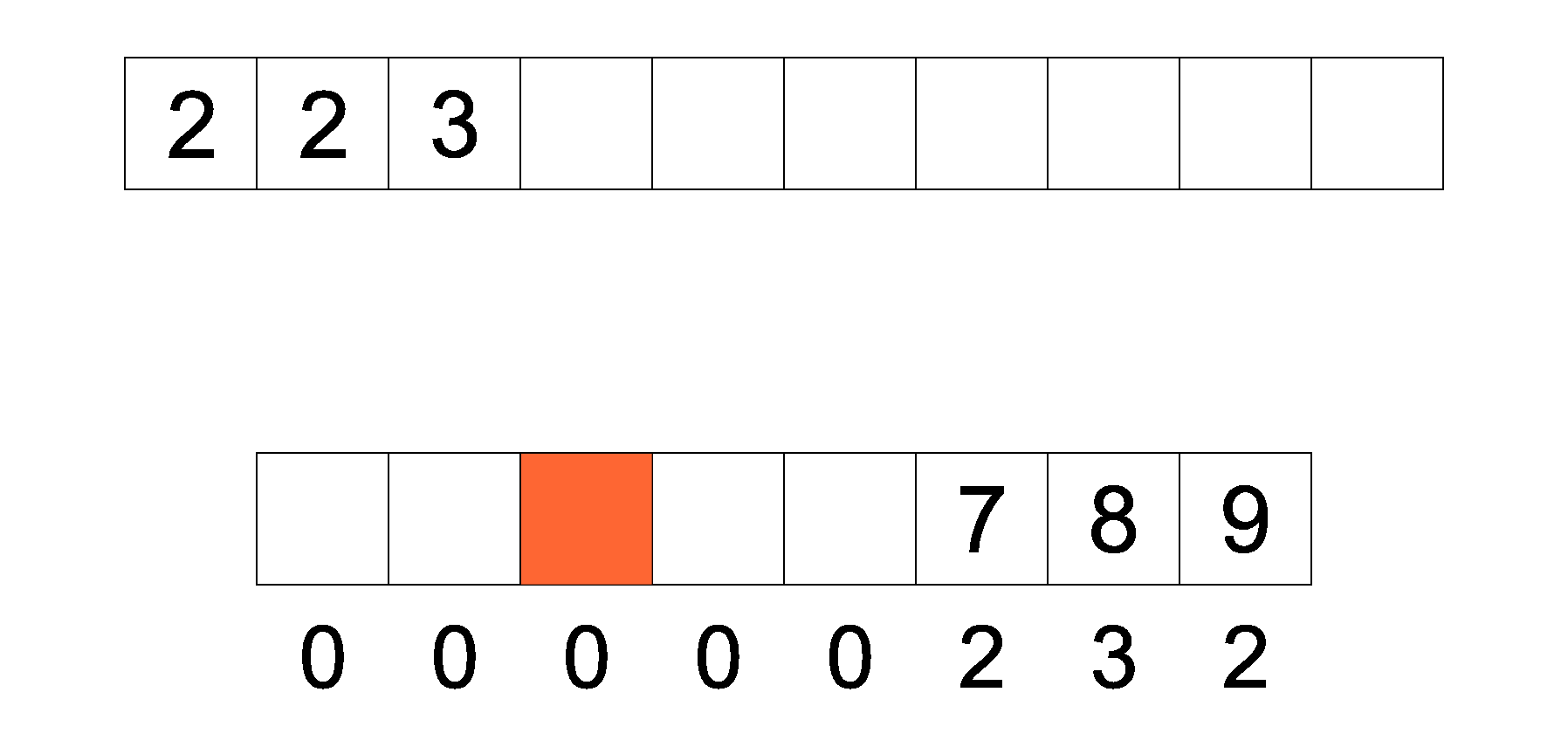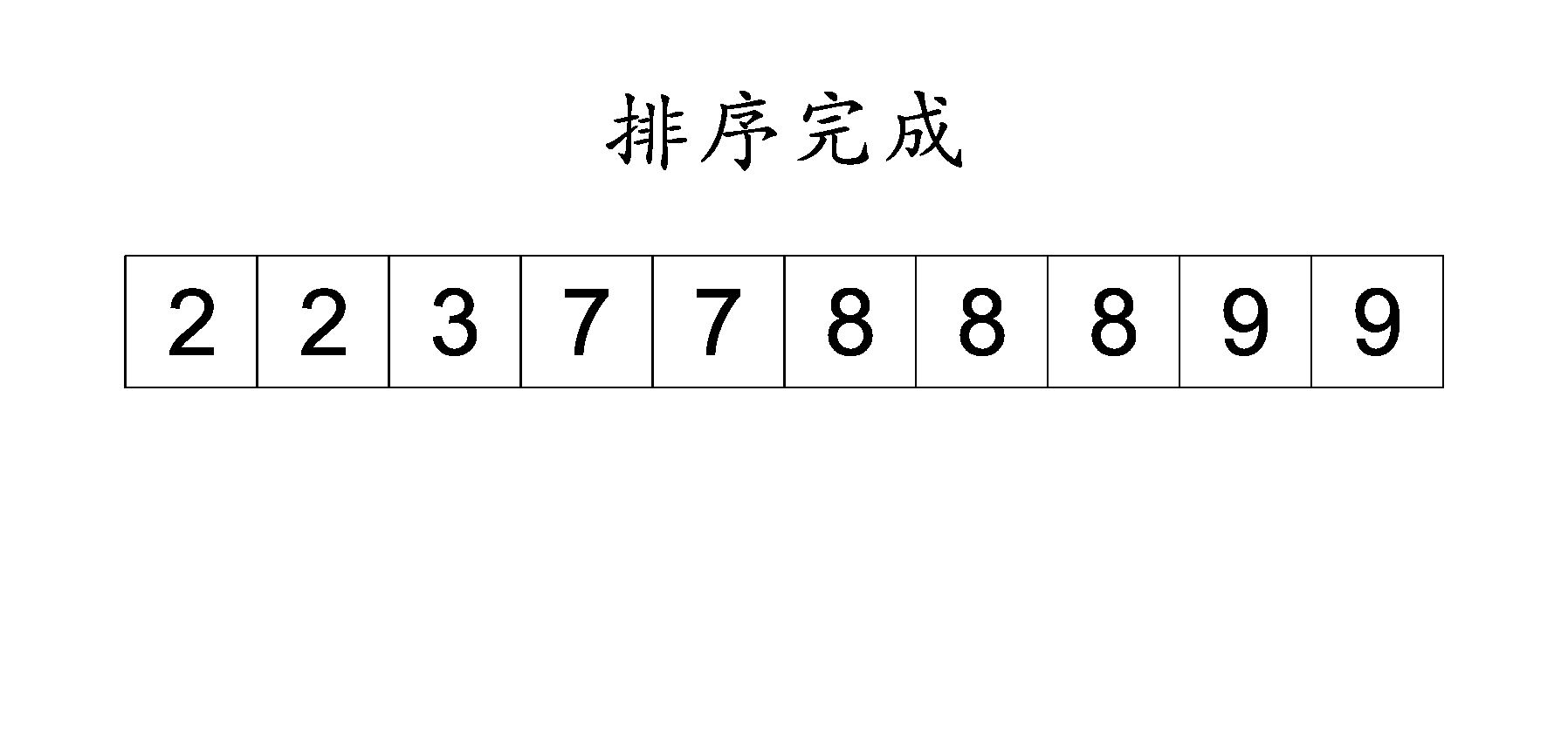
计数排序是一种空间换取时间的算法 , 先要在原数组中找到最大的数, 使用 max 记录 , 最小的数使用 min 记录 , 随后需要一个长度为 max - min + 1 的新数组

而新数组是以 原数组的元素与最小值的差值 作为索引值 , 每个索引上都会记录原数组的元素出现了多少次

遍历原数组 ,每个元素都以与最小值的差值在新数组中记录 , 遍历完成之后 , 再遍历新数组 , 将新数组的下标加最小值的和放回到原数组 , 当新数组中下标记录的值为 0 后 , 向后寻找下一个记录大于 0 的下标 , 然后在执行下标加最小值的和放回到原数组操作 , 直至遍历完新数组 , 此时排序就完成了.
代码实现
// 计数排序
public void countingSort(int[] elem) {
int max = elem[0];
int min = elem[0];
for (int value : elem) {
if (value > max)
max = value;
if (value < min) {
min = value;
}
}
// 最大值与最小值的差值+1做为新数组长度
int k = max - min + 1;
int[] counter = new int[k];
for (int i : elem) {
counter[i - min]++; // 原数组的元素 i 与最小值 min 的差值当做新数组的索引 , 且在新数组当前索引上的元素进行自增一次
}
int j = 0; // 原数组的索引开始位置
// 遍历新数组
for (int i = 0; i < counter.length; i++) {
// 查看当前索引记录是否大于 0
while ((counter[i]–) > 0) {
elem[j++] = i + min; // 将当前索引位置加 min 还原原数组的元素放回原数组
}
}
}
计数排序的优点是速度快 , 不过缺点也很明显 , 计数排序只能直接应用于非负整数的排序中 , 如果需要排序的数据含有负数,或者是其他类型的值,那么,还需要在不改变相对大小的情况下映射成非负整数,使整个排序逻辑变得复杂。
最后
由于细节内容实在太多了,为了不影响文章的观赏性,只截出了一部分知识点大致的介绍一下,每个小节点里面都有更细化的内容!

小编准备了一份Java进阶学习路线图(Xmind)以及来年金三银四必备的一份《Java面试必备指南》

最大值与最小值的差值+1做为新数组长度
int k = max - min + 1;
int[] counter = new int[k];
for (int i : elem) {
counter[i - min]++; // 原数组的元素 i 与最小值 min 的差值当做新数组的索引 , 且在新数组当前索引上的元素进行自增一次
}
int j = 0; // 原数组的索引开始位置
// 遍历新数组
for (int i = 0; i < counter.length; i++) {
// 查看当前索引记录是否大于 0
while ((counter[i]–) > 0) {
elem[j++] = i + min; // 将当前索引位置加 min 还原原数组的元素放回原数组
}
}
}
计数排序的优点是速度快 , 不过缺点也很明显 , 计数排序只能直接应用于非负整数的排序中 , 如果需要排序的数据含有负数,或者是其他类型的值,那么,还需要在不改变相对大小的情况下映射成非负整数,使整个排序逻辑变得复杂。
最后
由于细节内容实在太多了,为了不影响文章的观赏性,只截出了一部分知识点大致的介绍一下,每个小节点里面都有更细化的内容!
[外链图片转存中…(img-7QN09SFG-1714490048403)]
小编准备了一份Java进阶学习路线图(Xmind)以及来年金三银四必备的一份《Java面试必备指南》
[外链图片转存中…(img-ANy1Jn3N-1714490048404)]














 1847
1847











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









