







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注Java)

正文
-
问 Golang 掌握得怎么样?(用了半年, 看过 effective go)
-
问算法掌握得怎么样?(到图为止都可以)
-
问最短路算法(只记得 dijkstra 了,描述了代码流程)
-
k8s 掌握得怎么样?(没有自己写过 controller 和 scheduler,但是对概念都很熟悉,看过 xxx 这几部分的源码)
-
k8s 的 exec 是怎么实现的?(这个问题正中下怀,之前写了 PinGCAP 的小作业正好对这块特别熟悉)
这轮聊得顺畅多了。同时发现蚂蚁的面试官似乎挺喜欢让你自己评价:“你觉得自己 xxx 掌握得怎么样?”(只有五位面试官,样本不够大,不能作数哦),这类问题其实我慌得要死,怕吹过头了答不上来,面试挂了事小,丢了面子事大。早知道就预习一下怎么吹嘘了。
四面
===
-
介绍一下自己
-
觉得自己基础知识掌握怎么样
-
平时一般会用到哪些数据结构?
-
链表和数组相比, 有什么优劣?
-
如何判断两个无环单链表有没有交叉点
-
如何判断两个有环单链表有没有交叉点
-
如何判断一个单链表有没有环, 并找出入环点
-
TCP 和 UDP 有什么区别?
-
描述一下 TCP 四次挥手的过程中
-
TCP 有哪些状态
-
TCP 的 LISTEN 状态是什么
-
TCP 的 CLOSE_WAIT 状态是什么
-
建立一个 socket 连接要经过哪些步骤
-
常见的 HTTP 状态码有哪些
-
301和302有什么区别
-
504和500有什么区别
-
HTTPS 和 HTTP 有什么区别
-
写一个算法题: 手写快排
这一轮全程问的基础知识,基础扎实的话就没问题了,不过大佬感觉有一点像校招的问法。
五面
===
-
介绍一下自己
-
在 k8s 上做过哪些二次开发?
-
自己用 Helm 构建过 chart 吗?有哪些?
-
有没有考虑过自己封装一个面向研发的 PaaS 平台?
-
配置中心做了什么?
-
为什么不用 zookeeper?
-
配置中心如何保证一致性?
-
Spring 里用了单例 Bean, 怎么保证访问 Bean 字段时的并发安全?
-
用并发安全的数据结构,比如 ConcurrentHashMap;或者加互斥锁
-
假如我还想隔离两个线程的数据, 怎么办?
-
ThreadLocal,然后举了个例子
-
Golang 里的逃逸分析是什么?怎么避免内存逃逸?
-
这个不知道,认怂了
-
对比一下 Golang 和 Java 的 GC
-
答了一下 CMS、G1和三色标记,我对比的点是 JVM 有分代回收,Go 的 Runtime 没有,没能深入地讲
-
Golang 的 GC 触发时机是什么
-
阈值触发;主动触发;两分钟定时触发;
-
有没有写过 k8s 的 Operator 或 Controller?(大佬:没有写过)
-
谈一谈你对微服务架构的理解
-
大体思路"微服务本质是人员组织架构演进与关注点分离"
-
谈一谈你对 Serveless 的理解
-
大体思路"Serveless 是继 docker 与容器编排之后的又一次应用开发与基础设施提供方之间的边界划分"
-
你认为 Serveless 是未来吗? 为什么?
-
大体思路"是云服务的未来,把蛋糕从企业的IT、运维与中间件部门切走,形成规模效应,做得越多赚得越多;公司内的话 servless能够帮助加速前台业务迭代,但对中后台的收益还看不到,未来可能会有比 servless 更适合中后台的架构"
面试官:最后你有什么要问我的?
大佬:为什么足足安排了五轮技术面,而且其中有两轮似乎和 k8s 没有关系啊?
面试官:我们觉得你做过的东西挺多的,各个方向都想让你尝试一下
我:那这轮是最后一轮技术面吗?
面试官:不一定
后续还问了面试官一些业务相关的问题,就不赘述了
五面最后的三个吹水问题大佬说还挺感兴趣,可惜面试官只是听他讲,没有跟他讨论。还有就是问了面试官才知道,二面四面的面试官是 PaaS 平台那边的,因此主要问 Java 没有涉及到 k8s 和 go。
六面(HR 面)
=========
之前听说过阿里系的 HR 是来"闻味道的"(看你是否适合阿里的风格),而且有一票否决权。所以还是挺有压力的。
-
问经历
-
为什么要考虑出来看看呢?
-
金句:“现在自己的技术成长有点碰到瓶颈,加上一直对您公司钦慕有加relaxed”"
-
现在公司的主营业务是什么?(这块往技术上问了很多,感觉是想考察我解释复杂问题的能力)
-
现在带人吗?report 层级是怎样的?
-
对自己这几年的经历满意吗?
-
觉得自己有什么缺点?
-
碰到过什么很挫败的事情吗?
-
未来的职业规划是怎样的?
-
看机会的时候,主要考虑的是待遇、平台、人员还是什么其他因素?
-
现在的待遇如何
-
有什么想问我的?
整体聊了 40 多分钟,话题挺广的,面试官也说了系统部这边压力挺大的,优秀的人才才能留下来。
大佬觉得 HR 面里除了谈薪酬的部分没有什么可准备的,想说什么直说就行。因为到了 HR 面至少证明你的技术没什么问题,直说出来方便 HR 判断两边的价值观是否合拍,假如真的不合拍,那其实在 HR 这一面挂了比起进去之后再后悔又跳槽要好很多,毕竟大家都不喜欢频繁跳槽的简历。
小结
完事后问了一些主观评价:
-
面试难度:正常
-
面试体验:还不错,感觉没这么难。(反正我是酸了)
-
问题偏向:基础知识,开发常识,技术见解
最后提供的Java架构学习资料,包含有:架构筑基、开源框架、分布式、微服务、高并发、网络等等,click here
- Java架构进阶之架构筑基篇(Java基础+并发编程+JVM+MySQL+Tomcat+网络+数据结构与算法)
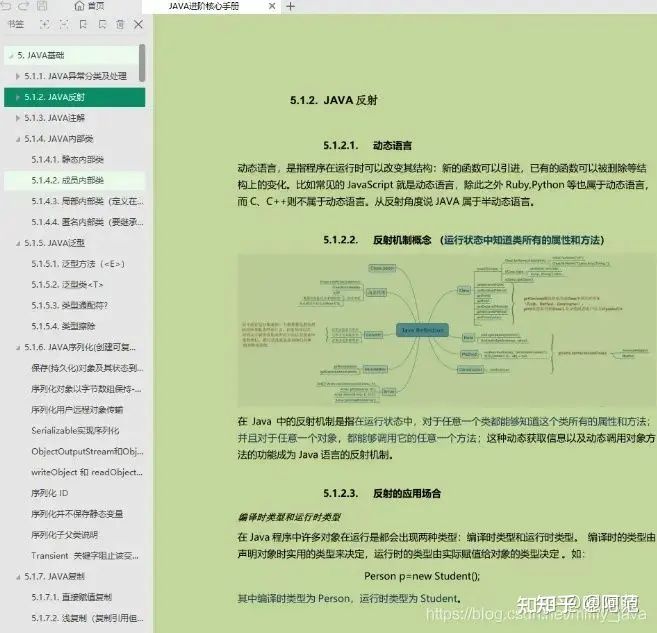
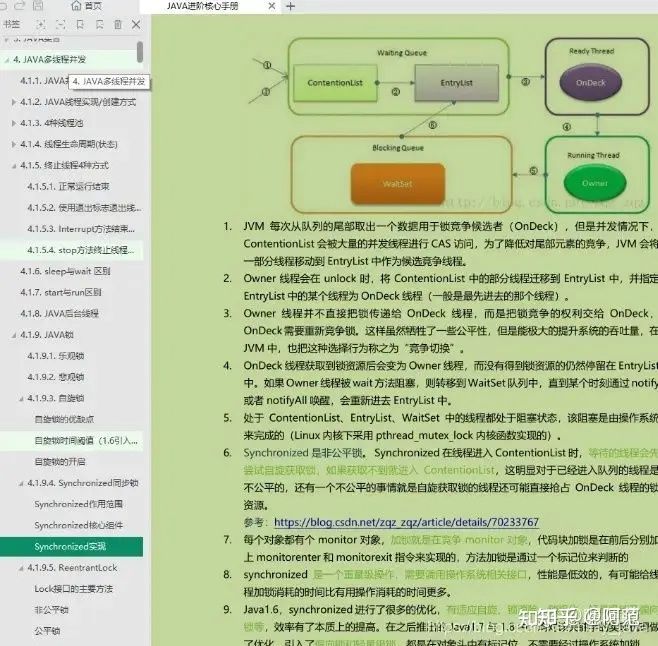

- Java架构进阶之开源框架篇(设计模式+Spring+SpringMVC+MyBatis)
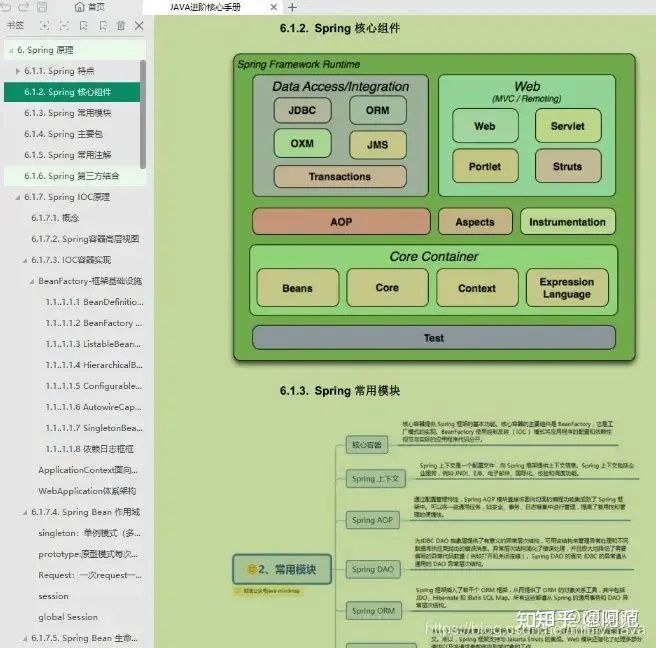
最后
笔者已经把面试题和答案整理成了面试专题文档






网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
-1713360048176)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)
[外链图片转存中…(img-42NgGUxs-1713360048176)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 381
381











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









