






学会使用python编写自动化脚本减少人工收集数据的时间精力,明白爬虫的原理逻辑,使用简单方式或取数据,保存数据。
python提供了丰富的第三方库给我们使用,大大降低了我们编写程序的难度,此次只用到了requests、pandas两个库即可完成该项目。
Requests介绍
requests 库是 Python 中一个常用的 HTTP 请求库,它提供了简洁且强大的接口,用于发送 HTTP 请求并处理响应。相比于 urllib 库,requests 库更加方便和直观,适合编写爬虫程序和进行网络请求操作
基本作用:
-
发送请求:你可以使用Requests库发送各种HTTP请求,如GET、POST、PUT、DELETE等。
-
传递URL参数:可以轻松地将字典传递给params参数,Requests库会自动将字典编码为URL参数。
-
发送数据:可以使用data参数发送表单数据,Requests库会自动编码为合适的格式。
-
JSON响应内容:如果响应是JSON格式,可以使用.json()方法直接获取JSON解析后的数据。
-
自定义头部:可以通过headers参数添加HTTP头部。
-
复杂的POST请求:可以发送多部分编码的文件。
......
pandas介绍
Pandas 是一个开源的Python数据分析库,提供了高性能、易于使用的数据结构和数据分析工具。它是基于NumPy库构建的,特别适合处理表格数据,例如Excel电子表格或SQL表。Pandas是数据科学领域中常用的工具之一,它支持不同类型的数据,如数值、字符串、时间序列等。
Pandas的主要功能
Pandas提供了丰富的功能,包括数据清洗、数据转换、数据分析和数据可视化。它可以处理缺失数据、重复数据,支持数据的合并、重塑和分组。通过整合Matplotlib和Seaborn等库,Pandas还可以进行数据可视化,绘制各种统计图表。
......
代码实现:
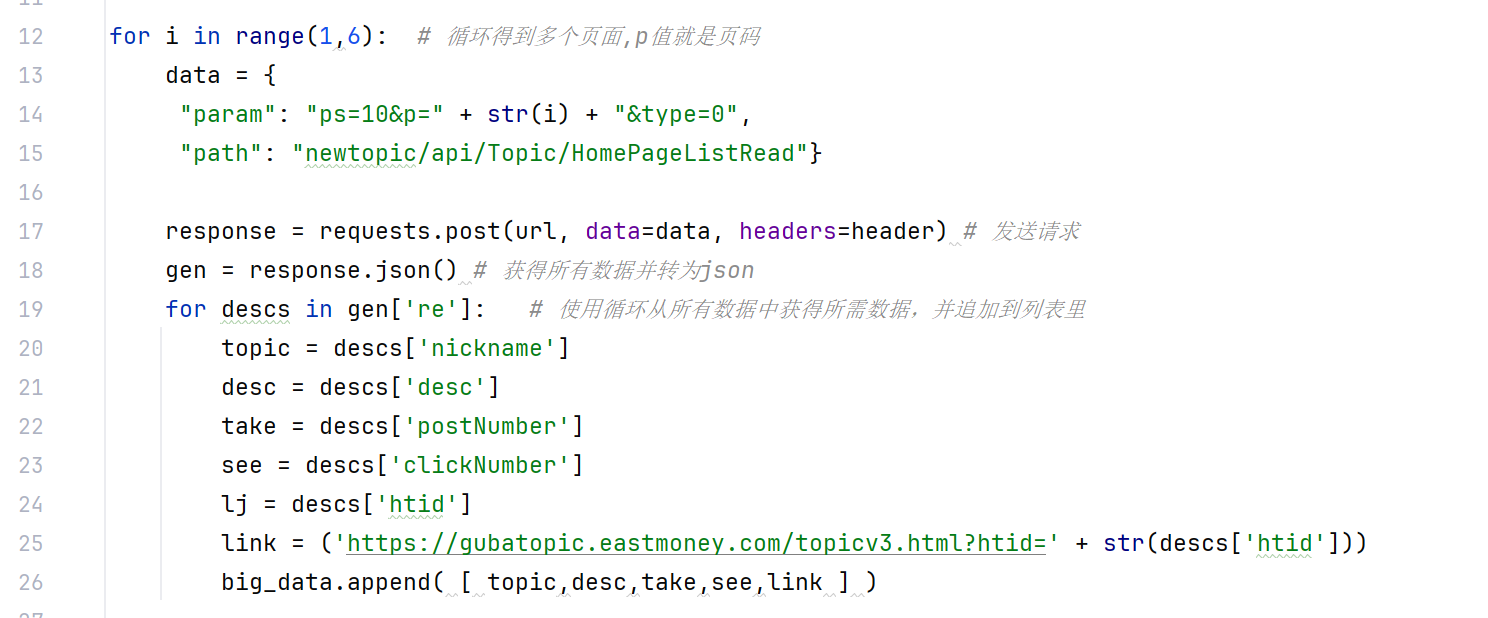
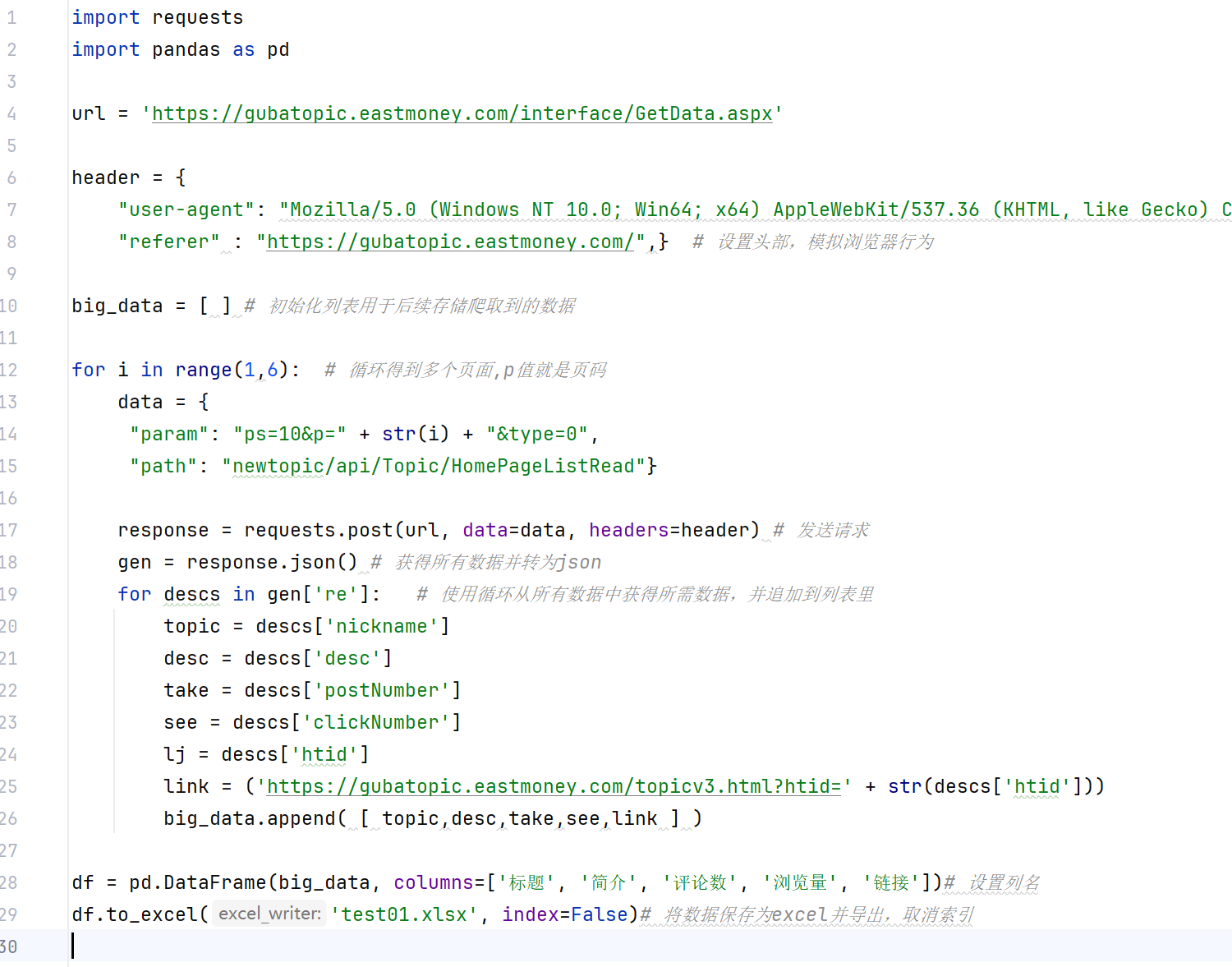
导入所需库---requests库用于发送HTTP请求,模拟浏览器获取网页数据;pandas库用于数据处理和表格生成,方便后续存储为Excel文件
目标URL:东方财富网热门话题数据接口
该URL是通过分析网页请求发现的API接口,用于获取话题列表数据

设置请求头(Headers),模拟真实浏览器行为
user-agent字段标识浏览器类型和版本,避免被网站识别为爬虫
referer字段表示请求来源页面,符合网站跳转逻辑

初始化数据存储列表
big_data用于存放从各个页面爬取的话题数据,每个元素是一条记录列表

循环获取多页数据(页码从1到5)
通过观察发现URL参数中的p值代表页码,ps=10表示每页显示10条数据
构造POST请求的参数
param参数包含分页信息和数据类型(type=0表示热门话题)
path参数指定数据接口路径,对应首页话题列表
发送POST请求
使用requests.post()方法向目标URL提交参数和请求头
该方法会自动处理HTTP连接,返回response对象包含服务器响应内容
解析响应数据
调用response.json()将返回的JSON格式数据转为Python字典对象
假设接口返回的JSON结构中,'re'字段包含话题列表数据
遍历单页数据中的每条话题记录
descs代表每条话题的详细信息字典
提取所需字段
nickname:话题标题
desc:话题简介(可能包含关联股信息)
postNumber:评论数
clickNumber:浏览量
htid:话题ID,用于生成详情页链接
构造话题详情页链接
通过htid参数拼接完整URL,方便后续访问详情页
将单条记录添加到数据列表
按顺序存储字段,确保与后续DataFrame列名对应
将列表数据转为DataFrame表格
columns参数指定表格列名,需与big_data中记录顺序一致
导出数据到Excel文件
to_excel()方法将DataFrame写入Excel,index=False取消默认行索引

完整代码:
运行结果:



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









