







刚好就和上述must相反,说白了也就是逻辑运算符“与”。
③should
通用的道理:多个查询条件通过should连接,相当于以前常用的or,说白了也就是逻辑运算符“与”。
ps:关于其格式使用,不要看它图中好像挺复杂的样子,其实都可以通过工具有提示,并且这些写多了基本也就知道了。
2范围查询
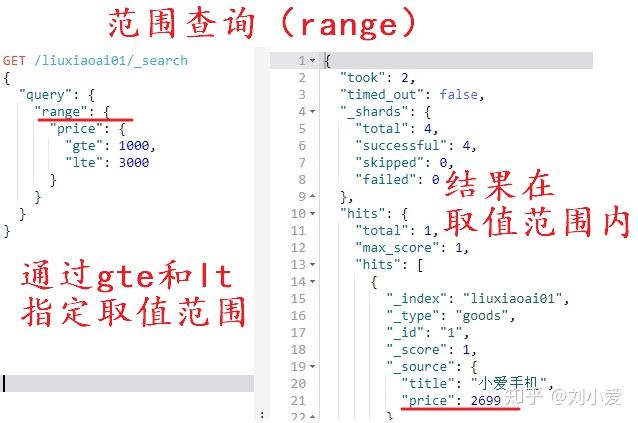
商品都有自己的价格,用户可以通过设定价格区间搜索到对应的商品。
range就可以实现范围查询,其中通过四种字符说明查询的区间。
-
gt:表示大于
-
get:表示大于等于
-
lt:表示小于
-
lte:表示小于等于
3模糊查询
实际应用中用户搜索时输入的词条与实际词条存在偏差,但也能搜索到对应的数据,这就需要使用到模糊查询了。
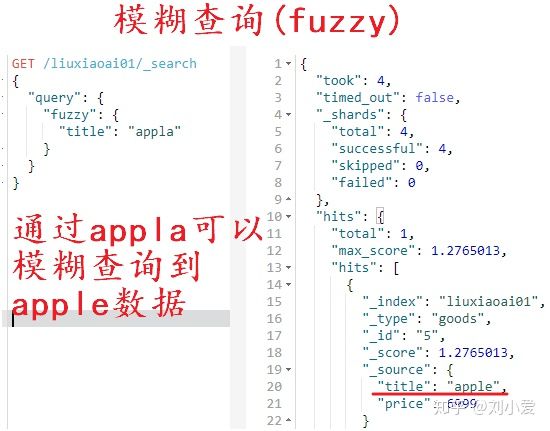
关键字是fuzzy,翻译过来也就是模糊的。
上述例子中,我添加了一个apple数据,查询的时候通过appla就可以模糊查询到,但是偏差的编辑距离不能超过2,其中也可以通过fuzziness来指定允许的编辑距离。
此外还有过滤,排序这些操作,并且上述这些操作一般都是组合起来使用的,其实无外乎就是记住关键字:
-
关于过滤对应的也就是filter。
-
关于排序也就对应着sort。
三、聚合aggregations
Elasticsearch中的聚合包含多种类型,最常用的有两种:
①桶(bucket)
其实蛮好理解的,比如上海现在一直在执行的垃圾分类,就有多个桶:干垃圾桶、湿垃圾桶、有害垃圾桶以及可回收物桶。
所以桶的作用就在于按照某种方式对数据进行分组,它只负责分组,不进行运算。
②度量(metrics)
也就是我们以前学的聚合函数,比如求平均值、最大值、最小值以及求和…等这些运算。
2聚合的使用

在使用之前,我们需要创建一个索引库并添加数据,作为聚合的测试数据。
cars索引库,有color和make两个字段,字段类型都为keyword,也就是不分词。
也就是关于汽车的一个索引库,有颜色和生产商这两个字段。
根据我们这两天的学习情况就可以简单地实现,具体添加了哪些数据就不做说明了。
桶的使用

size表示是查询条数,我这里设置为1,主要在于一个了解,重点在于聚合结果。
aggs也就是聚合aggregations的简写,说明这是一个聚合查询:
-
popular_make:聚合名,这是自定义的一个名称,尽量见名知义即可。
-
terms:划分桶的方式,有多种方式,这里是根据词条划分。
-
field:划分桶的字段,这里根据make划分。
这样聚合之后,索引库中的数据就根据field这个字段划分成了4个桶:例子中也就是"honda"、“ford”、“toyota”、“bmw”。
elasticsearch中关于桶的划分方式有多种:
-
Date Histogram:根据日期分组。
-
Historgram:根据数值分组。
-
Terms:根据词条内容分组,也就是上述使用的。
-
Range:数值和日期的范围分组。
-
……等等多种方式。
度量的使用

认真观察①和②会发现它们的格式就是一样的,格式无外乎就是4步骤:
-
aggs说明是聚合查询。
-
给这个聚合自定义一个名称。
-
说明聚合类型:①中terms是桶的类型,②中avg是度量的类型。
-
field说明聚合字段:①中根据make划分成多个桶,②中求桶中price字段的平均值。
上述例子也能看出聚合之间能嵌套使用。
文末
我将这三次阿里面试的题目全部分专题整理出来,并附带上详细的答案解析,生成了一份PDF文档
- 第一个要分享给大家的就是算法和数据结构

- 第二个就是数据库的高频知识点与性能优化

- 第三个则是并发编程(72个知识点学习)

- 最后一个是各大JAVA架构专题的面试点+解析+我的一些学习的书籍资料

还有更多的Redis、MySQL、JVM、Kafka、微服务、Spring全家桶等学习笔记这里就不一一列举出来
第三个则是并发编程(72个知识点学习)
[外链图片转存中…(img-3CMDtfQd-1714290078071)]
- 最后一个是各大JAVA架构专题的面试点+解析+我的一些学习的书籍资料
[外链图片转存中…(img-LzbcvGGm-1714290078071)]
还有更多的Redis、MySQL、JVM、Kafka、微服务、Spring全家桶等学习笔记这里就不一一列举出来














 275
275











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









