







总结
在这里,由于面试中MySQL问的比较多,因此也就在此以MySQL为例为大家总结分享。但是你要学习的往往不止这一点,还有一些主流框架的使用,Spring源码的学习,Mybatis源码的学习等等都是需要掌握的,我也把这些知识点都整理起来了


复杂的调用链条容易出错
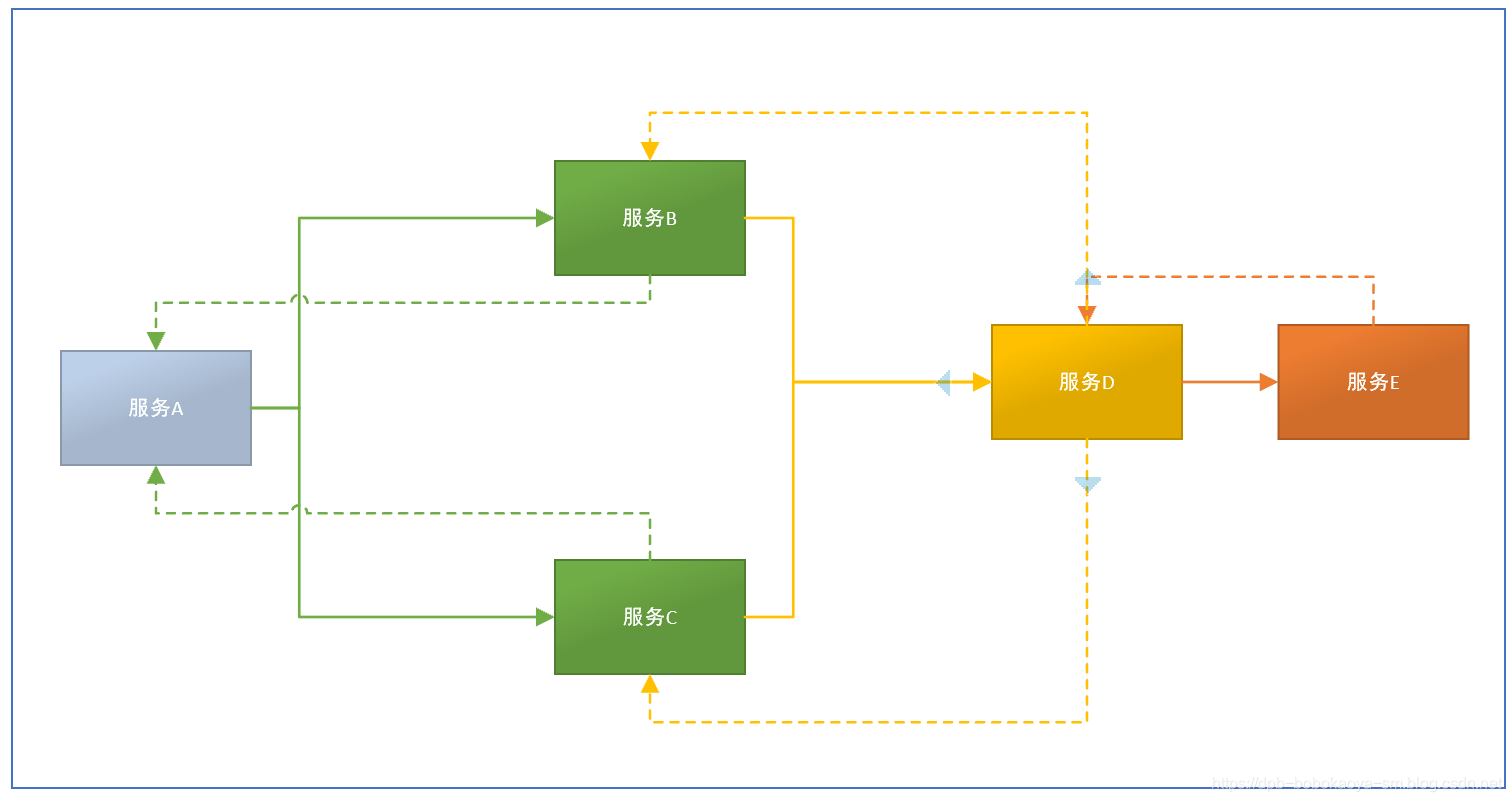
在复杂的微服务架构系统中,几乎每一个前端请求都会形成一个复杂的分布式服务调用链路,在每条链路中任何一个依赖服务出现延迟超时或者错误都有可能引起整个请求最后的失败
例如:
在微服务系统中,一个来自用户的请求,请求先达到前端A(如前端界面)然后通过远程调用,到达系统中间件B,C(负载均衡,网关等),最后达到后端服务D,E,后端经过一系列的业务逻辑计算最后将数据返回给用户,对于这样一个请求,经历了这么多个服务,怎么样将它的请求过程的数据记录下来呢?这就需要用到服务链路追踪
微服务跟踪(sleuth)其实是一个工具,它在整个分布式系统中能跟踪一个用户请求的过程(包括数据采集,数据传输,数据存储,数据分析,数据可视化),捕获这些跟踪数据,就能构建微服务的整个调用链的视图,这是调试和监控微服务的关键工具。
SpringCloudSleuth有4个特点
| 特点 | 说明 |
| — | :-- |
| 提供链路追踪 | 通过sleuth可以很清楚的看出一个请求经过了哪些服务,
可以方便的理清服务局的调用关系 |
| 性能分析 | 通过sleuth可以很方便的看出每个采集请求的耗时,
分析出哪些服务调用比较耗时,当服务调用的耗时
随着请求量的增大而增大时,也可以对服务的扩容提
供一定的提醒作用 |
| 数据分析
优化链路 | 对于频繁地调用一个服务,或者并行地调用等,
可以针对业务做一些优化措施 |
| 可视化 | 对于程序未捕获的异常,可以在zipkpin界面上看到 |
========================================================================
我们通过一个简单的微服务调用案例来演示下Sleuth是怎么跟踪请求调用的,案例结构图如下:
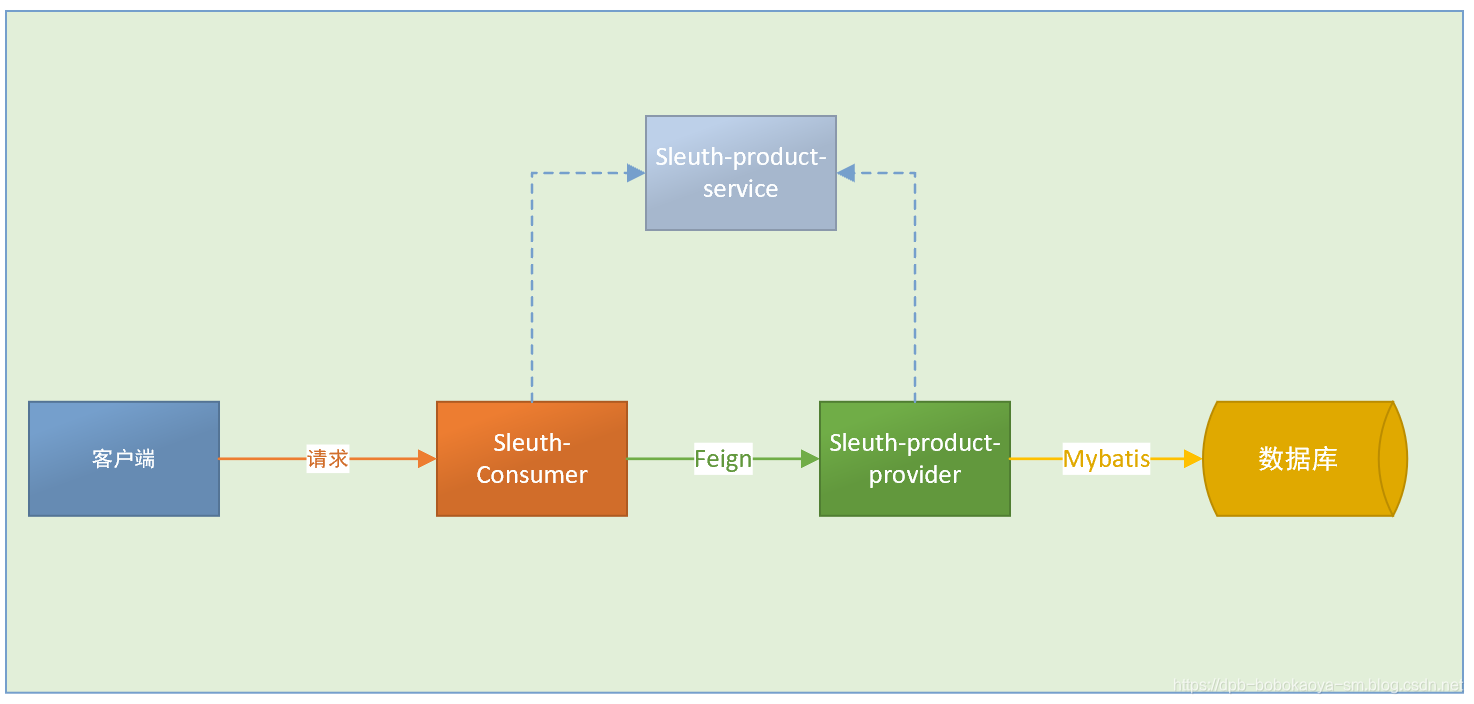
1.1 创建服务
1.2 创建pojo
此处的Product类以及相关代码在GitHub上

1.3 创建service接口
@RequestMapping(“/product”)
public interface ProductService {
@RequestMapping(value=“findAll”,method=RequestMethod.GET)
public List findAll();
}
2.1 创建项目
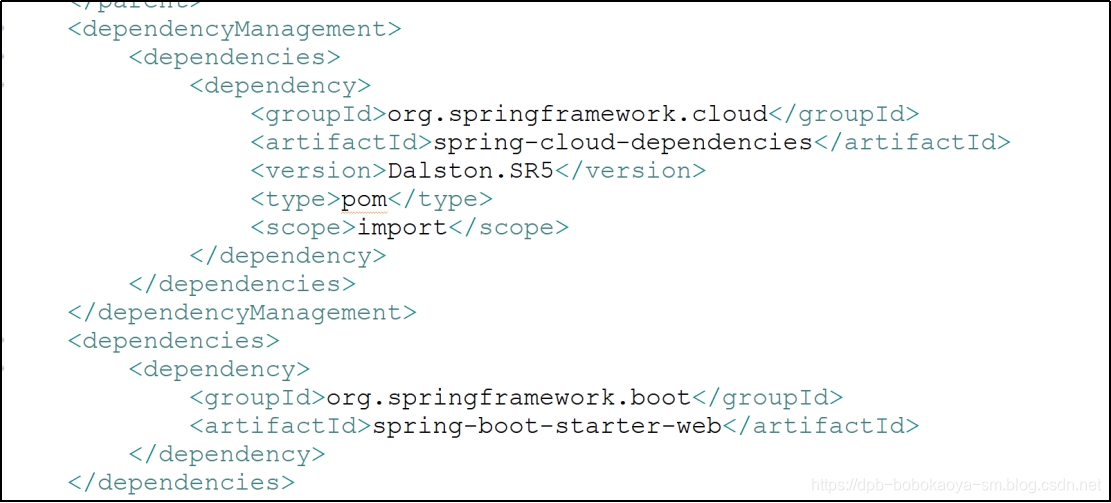
2.2 pom文件
注意添加sleuth的依赖
<project xmlns=“http://maven.apache.org/POM/4.0.0” xmlns:xsi=“http://www.w3.org/2001/XMLSchema-instance”
xsi:schemaLocation=“http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd”>
4.0.0
org.springframework.boot
spring-boot-starter-parent
1.5.13.RELEASE
com.bobo
sleuth-product-provider
0.0.1-SNAPSHOT
org.springframework.boot
spring-boot-starter-web
org.mybatis.spring.boot
mybatis-spring-boot-starter
1.3.4
org.springframework.boot
spring-boot-starter-test
test
org.springframework.cloud
spring-cloud-starter-eureka
mysql
mysql-connector-java
5.1.47
com.bobo
sleuth-product-service
0.0.1-SNAPSHOT
org.springframework.cloud
spring-cloud-starter-sleuth
org.springframework.cloud
spring-cloud-dependencies
Dalston.SR5
pom
import
org.springframework.boot
spring-boot-maven-plugin
2.3 配置文件
没有特殊的
spring.application.name=sleuth-product
server.port=9001
#\u8BBE\u7F6E\u670D\u52A1\u6CE8\u518C\u4E2D\u5FC3\u5730\u5740\uFF0C\u6307\u5411\u53E6\u4E00\u4E2A\u6CE8\u518C\u4E2D\u5FC3
eureka.client.serviceUrl.defaultZone=http://dpb:123456@eureka1:8761/eureka/,http://dpb:123456@eureka2:8761/eureka/
#--------------db----------------
mybatis.type-aliases-package=com.book.product.pojo
mybatis.mapper-locations=classpath:com/bobo/product/mapper/*.xml
spring.datasource.driverClassName=com.mysql.jdbc.Driver
spring.datasource.url=jdbc:mysql://localhost:3306/book-product?useUnicode=true&characterEncoding=UTF-8&zeroDateTimeBehavior=convertToNull
spring.datasource.username=root
spring.datasource.password=123456
注意添加日志配置文件,日志级别设置为debug

2.4 业务代码
业务代码提供了对商品数据的查询。
3.1 创建项目
3.2 pom文件
统一注意添加sleuth的依赖
<project xmlns=“http://maven.apache.org/POM/4.0.0” xmlns:xsi=“http://www.w3.org/2001/XMLSchema-instance”
xsi:schemaLocation=“http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd”>
4.0.0
org.springframework.boot
spring-boot-starter-parent
1.5.13.RELEASE
com.bobo
sleuth-consumer
0.0.1-SNAPSHOT
org.springframework.cloud
spring-cloud-dependencies
Dalston.SR5
pom
import
最后






由于篇幅原因,就不多做展示了
转存中…(img-k1kdwiHP-1715326426230)]
[外链图片转存中…(img-6aGe2F1t-1715326426230)]
[外链图片转存中…(img-asEDpZLI-1715326426231)]
[外链图片转存中…(img-ePXLH28P-1715326426231)]
[外链图片转存中…(img-yT1WdOa9-1715326426231)]
由于篇幅原因,就不多做展示了















 365
365











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









