







口获取数据:命令get/path将返回与znode关联的数据和元数据。
口观察更改的 znode:如果znode或znode的子数据发生更改,则显示通知。观察只能使用get命令设置。
口设置数据:要设置znode数据,可以使用命令set/path/data。
口创建znode的子代:此命令与用于创建单个znode的命令类似。唯一的区别是子znode的路径将包括父路径。其命令格式为create /parent /path /subnode /path /data。
口列出znode的子节点:可以使用ls /path命令显示它。
口检查状态:可以使用stat /path命令检查。状态将描述指定znode的元数据,如时间戳或版本号。
口删除/刪除 znode: mr /path命令可以删除znode及其所有子节点。
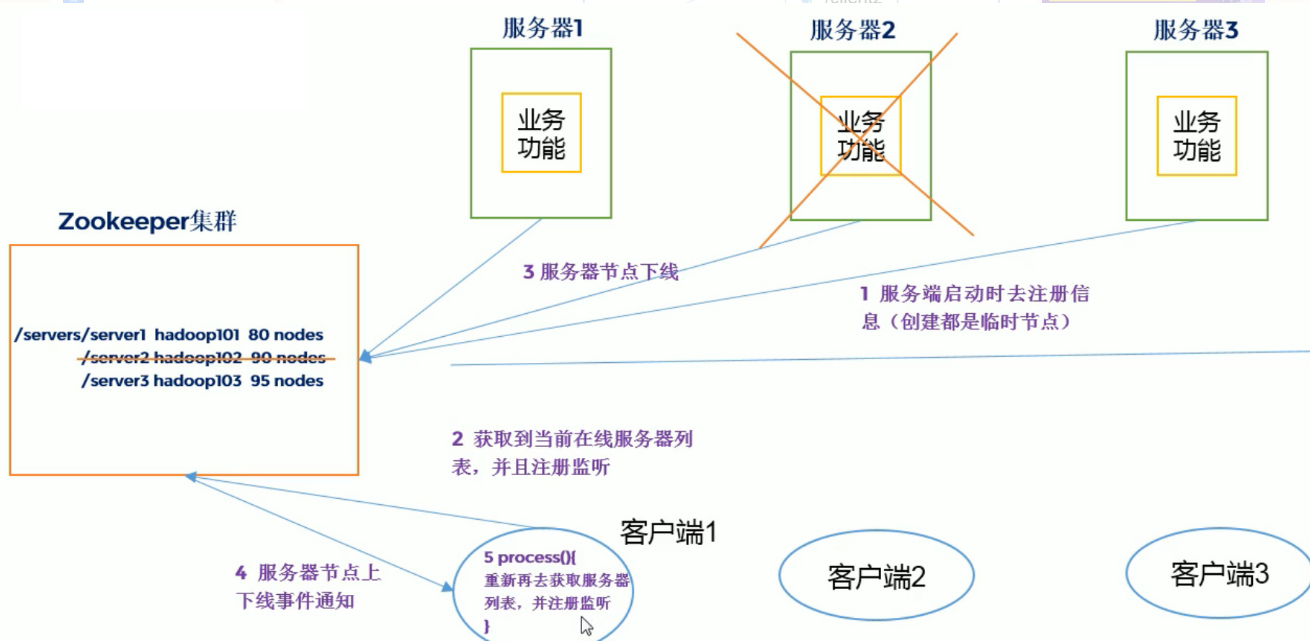
请注意,术语Zookeeper节点(znode)在这里是首次出现。在存储数据时,Zookeeper将使用树结构,其中每个节点称为znode.这些znode的名称基于从根节点获取的路径。每个节点都有一个名称。可以使用从根节点开始的绝对路径访问它。此概念类似于Consul文件夹,并已用于在键/值存储中创建键。
服务发现
====
Apache Zookeeper最流行的Java客户端库是Apache Curator.它提供了一个API框架和实用程序,使Apache Zookeeper的应用变得更加容易。它还包括常见用例和扩展,如服务发现或Java 8异步DSL. Spring Cloud Zookeeper可以利用一个这样的扩展来实现服务发现。Spring Cloud Zookeeper对Curator库的使用对于开发人员来说是完全透明的,所以在这里就不必做更多的介绍。
1.客户端实现
客户端的用法与其他服务发现相关的SpringCloud项目相同。应用程序的main类或@Configuration类应使用@EnableDiscoveryClient注解。默认的服务名称、实例ID和端口分别取自spring application.name. Spring Context ID和server.port.示例应用程序源代码位于GitHub存储库tp:/github.com/piomin/sample-spring-cloud- zookeeper.git)中。从根本上说,除了Spring Cloud Zookeeper Discovery依赖项之外,它与为Consul引入示例系统没有什么不同。它仍然由4个微服务组成,这些微服务之间可以相互通信。现在,在克隆存储库之后,可以使用mvn clean install 命令构建它。然后使用java jar命令运行具有活动配置文件名称的每个服务,如java jar -spring profiles active zonel order-service/target/order- service-1.0-SNAPSHOT.jar.
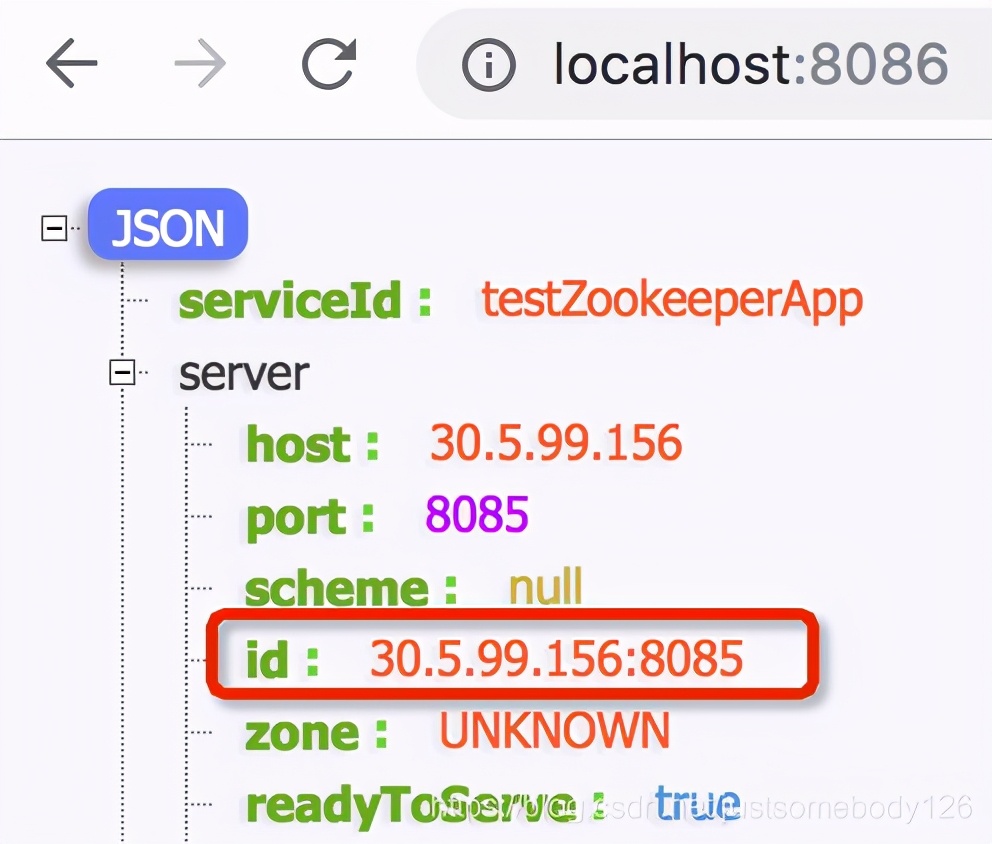
可以使用CLI命令Is和get查看已注册服务和实例的列表。默认情况下,Spring Cloud Zookeeper会注册/services根文件夹中的所有实例。它可能会被spring cou.ooceeper.discovery.root属性覆盖,如图10.9 所示。

2. Zookeeper 依赖项
Spring Cloud Zookeeper还有一个名为Zookeeper依赖项(ookeeper Dependencies)的附加功能。这里的依赖项应理解为在Zookeeper中注册的其他应用程序,这些应用程序通过Feign客户端或Spring RestTemplate调用。可以将这些依赖项作为应用程序的属性提供。在将spring-cloud-starter zookeeper discovery启动器包含到项目中之后,可以通过自动配置启用该功能。当然,也可以通过将spring.cloud.zookeeper .dependency .enabled属性设置为false来禁用它。
Zookeeper依赖项机制的配置随着spring cloud.zookeeper.dependencies.*属性一起提供。以下是来自order-service 服务的bootstrap.yml文件的片段。此服务可与所有其他可用服务集成。
spring:
application:
name: order-service
cloud:
zookeeper :
connect-string: 192 .168.99.100:2181
dependency:
resttemplate:
enabled: false
dependencies:
account :
path: account- service
loadBalancerType: ROUND ROBIN
required: true
customer :
path: customer-service
loadBalancerType: ROUND ROBIN
required: true
product:
path: product- service
loadBalancerType: ROUND ROBIN
required: true
现在来仔细看一看前面的配置。每个被调用服务的roo属性是别名,然后可以由Feign客户端或@LoadBalanced RestTemplate用作服务名称。
@FeignClient (name = “customer”)
public interface CustomerClient {
@GetMapping (“/wi thAccounts/ {customerId}”)
Customer findByI dWithAccounts (@Pathvariable (“customerId”) Long
customerId);
}
配置中的下一个非常重要的字段是路径。它设置在Zookeeper中注册依赖项的路径。因此,如果该属性具有的值为customer -service,则意味着Spring Cloud Zookeeper会尝试在路径
/services/customer-service下查找相应的服务znode.还有一些其他属性可以自定义客户端的行为。其中之一是 loadBalancerType,用于应用负载均衡策略。开发人员可以在3种可用策略之间选择一 :ROUND_ _ROBIN、RANDOM和STICKY。还可以为每个服务映射将required属性设置为true。现在,如果应用程序在引导期间无法检测到所需的依赖项,则无法启动。Spring Cloud Zookeeper 依赖项还允许管理API 版本(属性contentTypeTemplate和versions)和请求标头(headers 属性)。
默认情况下,Spring Cloud Zookeeper允许RestTemplate与依赖项进行通信。在分支依赖项
tps:/ithub.com/piomin/sample-spring-cloud- zoeeper/ree/dependencies)提供的示例应用程序中,我们使用了Feign客户端而不是@LoadBalanced RestTemplate。为了禁用该功能,应该将属性springcloud.zokeper. dependency rsttemplate enabled设置为false.
分布式配置
=====
Zookeeper的配置管理与Spring Cloud Consul Config的配置管理非常相似。默认情况下,所有属性源都存储在/config 文件夹(或Zookeeper术语中的znode)中。如前文所述,假设在bootstrap.yml文件中将spring application.name属性设置为order-service,并将springprofiles.active运行参数设置为zonel, 那么它会尝试按以下顺序查找属性源:confg/order-service、zonel/、 config/order-service/ 、configapplication. zone1/、 config/application/。存储在命名空间中具有configapplication前缀的文件夹中的属性可用于使用Zookeeper进行分布式配置的所有应用程序。
要访问示例应用程序,需要切换到http:/ihbco/piomin/sample -spring- cloud-zookeeper.git存储库中的分支配置。本地application.yml或botstrap.yml文件中定义的配置如下所示,现已移至Zookeeper.
—
spring:
profiles: zonel
server:
总结
上述知识点,囊括了目前互联网企业的主流应用技术以及能让你成为“香饽饽”的高级架构知识,每个笔记里面几乎都带有实战内容。
很多人担心学了容易忘,这里教你一个方法,那就是重复学习。
打个比方,假如你正在学习 spring 注解,突然发现了一个注解@Aspect,不知道干什么用的,你可能会去查看源码或者通过博客学习,花了半小时终于弄懂了,下次又看到@Aspect 了,你有点郁闷了,上次好像在哪哪哪学习,你快速打开网页花了五分钟又学会了。
从半小时和五分钟的对比中可以发现多学一次就离真正掌握知识又近了一步。

人的本性就是容易遗忘,只有不断加深印象、重复学习才能真正掌握,所以很多书我都是推荐大家多看几遍。哪有那么多天才,他只是比你多看了几遍书。
解@Aspect,不知道干什么用的,你可能会去查看源码或者通过博客学习,花了半小时终于弄懂了,下次又看到@Aspect 了,你有点郁闷了,上次好像在哪哪哪学习,你快速打开网页花了五分钟又学会了。
从半小时和五分钟的对比中可以发现多学一次就离真正掌握知识又近了一步。
[外链图片转存中…(img-TiY4E2IB-1714679559110)]
人的本性就是容易遗忘,只有不断加深印象、重复学习才能真正掌握,所以很多书我都是推荐大家多看几遍。哪有那么多天才,他只是比你多看了几遍书。















 4360
4360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









