







thread_task(url_list)
若使用多线程,每一个线程处理自己被分配到的作品列表:
每一个线程遍历自己分配到的作品列表,进行逐项处理
def thread_task(ul):
for item in ul:
href = item[0]
is_pictures = (True if item[1] == 0 else False)
res = work_task(href, is_pictures)
if res == 0: # 被阻止正常访问
break
处理每一项作品:
处理每一项作品
def work_task(href, is_pictures):
# href 中最后的一个路径参数就是博主的id
work_id = href.split(‘/’)[-1]
# 判断是否已经下载过该作品
has_downloaded = check_download_or_not(work_id, is_pictures)
# 没有下载,则去下载
if not has_downloaded:
if not is_pictures:
res = deal_video(work_id)
else:
res = deal_pictures(work_id)
if res == 0:
return 0 # 无法正常访问
else:
print('当前作品已被下载')
return 2
return 1
## 4、处理图文类型作品
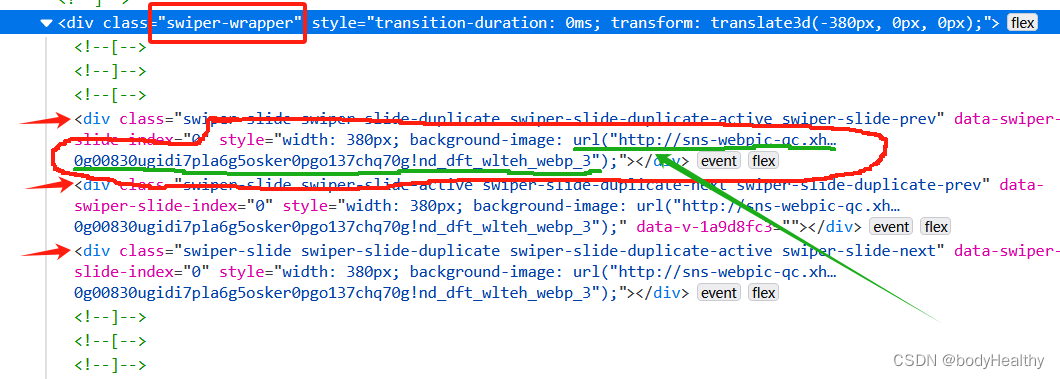
对于图文类型,每一张图片都作为 div 元素的背景图片进行展示,图片对应的 URL 在 div 元素的 style 中。 可以先获取到 style 的内容,然后根据圆括号进行分隔,最后得到图片的地址。
这里拿到的图片是没有水印的。
处理图片类型作品的一系列操作
def download_pictures_prepare(res_links, path, date):
# 下载作品到目录
index = 0
for src in res_links:
download_resource(src, f’{path}/{date}-{index}.webp’)
index += 1
处理图片类型的作品
def deal_pictures(work_id):
# 直接 requests 请求回来,style 是空的,使用 webdriver 获取当前界面的源代码
temp_driver = webdriver.Chrome()
temp_driver.set_page_load_timeout(5)
temp_driver.get(f’https://www.xiaohongshu.com/explore/{work_id}')
sleep(1)
try:
# 如果页面中有 class=‘feedback-btn’ 这个元素,则表示不能正常访问
temp_driver.find_element(By.CLASS_NAME, ‘feedback-btn’)
except NoSuchElementException: # 没有该元素,则说明能正常访问到作品页面
WebDriverWait(temp_driver, 5).until(EC.presence_of_element_located((By.CLASS_NAME, ‘swiper-wrapper’)))
# 获取页面的源代码
source_code = temp_driver.page_source
temp_driver.quit()
html = BeautifulSoup(source_code, 'lxml')
swiper_sliders = html.find_all(class_='swiper-slide')
# 当前作品的发表日期
date = html.find(class_='bottom-container').span.string.split(' ')[0].strip()
# 图片路径
res_links = []
for item in swiper_sliders:
# 在 style 中提取出图片的 url
url = item['style'].split('url(')[1].split(')')[0].replace('"', '').replace('"', '') 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5278
5278











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









