







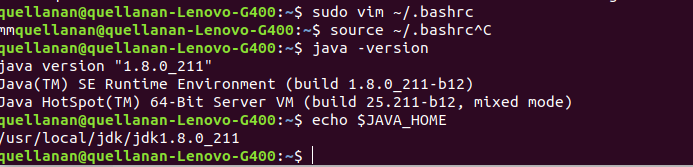
保存退出后,执行
$ source ~/.bashrc
##让上面修改的文件生效,和重启电脑起到相同效果。
##接下来测试一下你的java环境变量是否配置好了把
$ java -version
$ java
$ javac
$ echo $JAVA_HOME
上面的四个都可以试试,配置好了是有的
3.配置ssh免密登录
切换到 hadoop 用户,hadoop 用户时密码为 hadoop。后续步骤都将在 hadoop 用户的环境中执行。
$ su hadoop
配置ssh环境免密码登录。 在/home/hadoop目录下执行
$cd ~
$ ssh-keygen -t rsa #一路回车
$ cat .ssh/id_rsa.pub >> .ssh/authorized_keys
$ chmod 600 .ssh/authorized_keys
验证登录本机是否还需要密码,第一次需要密码以后不需要密码就可以登录。
$ ssh localhost
#仅需输入一次hadoop密码,以后不需要输入

4.下载并安装Hadoop
我选的是Hadoop 2.6.0,大家可以选择自己想要的Hadoop版本,但是方法都是一样的
$ wget http://labfile.oss.aliyuncs.com/hadoop-2.6.0.tar.gz
$ tar zxvf hadoop-2.6.0.tar.gz
$ chmod 777 /home/hadoop/hdfs/hadoop-2.6.0
为什么要修改文件夹的权限呢,因为下载的的Hadoop解压后的所有者和用户组是20000,不知道你们是什么,应该不是你的当前用户,所以你当前用户在操作这个文件的时候总提示权限不足,者也是后面的一个坑啊。
5.配置Hadoop
一样的,打开当前用户的.bashrc 文件,进行修改
#HADOOP START
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_211
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.: J A V A H O M E / l i b : {JAVA_HOME}/lib: JAVAHOME/lib:{JRE_HOME}/lib
export HADOOP_HOME=/home/hadoop/hdfs/hadoop-2.6.0
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_INSTALL=$HADOOP_HOME
export PATH=.: J A V A H O M E / b i n : {JAVA_HOME}/bin: JAVAHOME/bin:PATH: H A D O O P H O M E / b i n : {HADOOP_HOME}/bin: HADOOPHOME/bin:{HADOOP_HOME}/sbin
#HADOOP END

其实配置Hadoop用不到这么多,之后待会部署伪分布式模式的时候要加上这些变量,所以才一次给出来,如果只配置单机模式,配置下面就好
#JAVA
export JAVA_HOME=/usr/local/jdk/jdk1.8.0_211
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.: J A V A H O M E / l i b : {JAVA_HOME}/lib: JAVAHOME/lib:{JRE_HOME}/lib
#HADOOP START
export HADOOP_HOME=/home/hadoop/hdfs/hadoop-2.6.0
export PATH=.: J A V A H O M E / b i n : {JAVA_HOME}/bin: JAVAHOME/bin:PATH: H A D O O P H O M E / b i n : {HADOOP_HOME}/bin: HADOOPHOME/bin:{HADOOP_HOME}/sbin
#HADOOP END
保存之后,同样执行$ source ~/.bashrc生效。
6. 单机模式测试
到此其实单机模式就已经配置好了。现在可以看看你的hadoop 配置好没。
$ hadoop version
会显示出当前你安装的hadoop 版本,证明安装成功啦
接下来测试一下:
创建输入临时目录的内容文件。可以在任何地方创建此输入目录用来工作。
$ mkdir input
$ cp $HADOOP_HOME/*.txt input
$ ls -l input
它会在输入目录中的给出以下文件:
total 24
-rw-r–r-- 1 root root 15164 Feb 21 10:14 LICENSE.txt
-rw-r–r-- 1 root root 101 Feb 21 10:14 NOTICE.txt
-rw-r–r-- 1 root root 1366 Feb 21 10:14 README.txt
接下来进行Hadoop自带的单词统计的例子
$ hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduceexamples-2.6.0.jar wordcount input ouput
这里我也碰到一个坑,就是上面的说的权限问题。我执行这个语句之后,疯狂报错,最后仔细看看是创建ouput文件夹以及生成里面的文件失败。最后也是找了很久才知道把权限改一下,然后就正常运行了。
看看结果:
cat ouput/*

到此就单机模式部署好啦,接下虚分布模式
7. 伪分布模式部署
伪分布模式,修改的配置文件有点多,一步一步来。
1.首先修改.bashrc 把文章前面说的那些变量加上去。最后的效果图再看一遍
2.接下来的配置修改都是在这个目录下的。
$ cd $HADOOP_HOME/etc/hadoop

3.修改 hadoop-env.sh
把JAVA_HOME路径改成你对应的路径,不然最后测试会提示找不到JAVA_HOME

4.修改 core-site.xml
core-site.xml文件中包含如读/写缓冲器用于Hadoop的实例的端口号的信息,分配给文件系统存储,用于存储所述数据存储器的限制和大小。
打开core-site.xml 并在,标记之间添加以下属性。
fs.default.name
hdfs://localhost:9000
5.修改hdfs-site.xml
hdfs-site.xml 文件中包含如复制数据的值,NameNode路径的信息,,本地文件系统的数据节点的路径。这意味着是存储Hadoop基础工具的地方。
打开这个文件,并在这个文件中的标签之间添加以下属性。
dfs.replication
1
dfs.name.dir
file:///home/hadoop/hadoopinfra/hdfs/namenode
dfs.data.dir
file:///home/hadoop/hadoopinfra/hdfs/datanode
6.修改yarn-site.xml
此文件用于配置成yarn在Hadoop中。打开 yarn-site.xml文件,并在文件中的标签之间添加以下属性。
yarn.nodemanager.aux-services
mapreduce_shuffle
7.修改mapred-site.xml
此文件用于指定正在使用MapReduce框架。
缺省情况下,包含Hadoop的模板yarn-site.xml。首先,它需要从mapred-site.xml复制。获得mapred-site.xml模板文件使用以下命令。
$ cp mapred-site.xml.template mapred-site.xml
打开mapred-site.xml文件,并在此文件中的标签之间添加以下属性。
mapreduce.framework.name
yarn
好啦,到此,所有的配置都已经配置好了,现在来验证一下吧
8.伪分布模式验证
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

最后
面试前一定少不了刷题,为了方便大家复习,我分享一波个人整理的面试大全宝典
- Java核心知识整理

Java核心知识
- Spring全家桶(实战系列)

- 其他电子书资料

Step3:刷题
既然是要面试,那么就少不了刷题,实际上春节回家后,哪儿也去不了,我自己是刷了不少面试题的,所以在面试过程中才能够做到心中有数,基本上会清楚面试过程中会问到哪些知识点,高频题又有哪些,所以刷题是面试前期准备过程中非常重要的一点。
以下是我私藏的面试题库:

《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
理的面试大全宝典**
- Java核心知识整理
[外链图片转存中…(img-OILazaHj-1713434905506)]
Java核心知识
- Spring全家桶(实战系列)
[外链图片转存中…(img-6fmiJYzO-1713434905506)]
- 其他电子书资料
[外链图片转存中…(img-Ph9xg5rg-1713434905506)]
Step3:刷题
既然是要面试,那么就少不了刷题,实际上春节回家后,哪儿也去不了,我自己是刷了不少面试题的,所以在面试过程中才能够做到心中有数,基本上会清楚面试过程中会问到哪些知识点,高频题又有哪些,所以刷题是面试前期准备过程中非常重要的一点。
以下是我私藏的面试题库:
[外链图片转存中…(img-BKiEPxlY-1713434905507)]
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!















 132万+
132万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









