







当数据的访问模式不随时间变化的时候,LFU的策略能够带来最佳的缓存命中率。然而LFU有两个缺点:
首先,它需要给每个记录项维护频率信息,每次访问都需要更新,这是个巨大的开销;
其次,如果数据访问模式随时间有变,LFU的频率信息无法随之变化,因此早先频繁访问的记录可能会占据缓存,而后期访问较多的记录则无法被命中。
因此,大多数的缓存设计都是基于LRU或者其变种来进行的。相比之下,LRU并不需要维护昂贵的缓存记录元信息,同时也能够反应随时间变化的数据访问模式。然而,在许多负载之下,LRU依然需要更多的空间才能做到跟LFU一致的缓存命中率。因此,一个“现代”的缓存,应当能够综合两者的长处。
TinyLFU维护了近期访问记录的频率信息,作为一个过滤器,当新记录来时,只有满足TinyLFU要求的记录才可以被插入缓存。如前所述,作为现代的缓存,它需要解决两个挑战:
-
一个是如何避免维护频率信息的高开销;
-
另一个是如何反应随时间变化的访问模式。
首先来看前者,TinyLFU借助了数据流Sketching技术,Count-Min Sketch显然是解决这个问题的有效手段,它可以用小得多的空间存放频率信息,而保证很低的False Positive Rate。但考虑到第二个问题,就要复杂许多了,因为我们知道,任何Sketching数据结构如果要反应时间变化都是一件困难的事情,在Bloom Filter方面,我们可以有Timing Bloom Filter,但对于CMSketch来说,如何做到Timing CMSketch就不那么容易了。
TinyLFU采用了一种基于滑动窗口的时间衰减设计机制,借助于一种简易的reset操作:每次添加一条记录到Sketch的时候,都会给一个计数器上加1,当计数器达到一个尺寸W的时候,把所有记录的Sketch数值都除以2,该reset操作可以起到衰减的作用 。
W-TinyLFU主要用来解决一些稀疏的突发访问元素。在一些数目很少但突发访问量很大的场景下,TinyLFU将无法保存这类元素,因为它们无法在给定时间内积累到足够高的频率。因此W-TinyLFU就是结合LFU和LRU,前者用来应对大多数场景,而LRU用来处理突发流量。
在处理频率记录的方案中,你可能会想到用hashMap去存储,每一个key对应一个频率值。那如果数据量特别大的时候,是不是这个hashMap也会特别大呢。由此可以联想到 Bloom Filter,对于每个key,用n个byte每个存储一个标志用来判断key是否在集合中。原理就是使用k个hash函数来将key散列成一个整数。
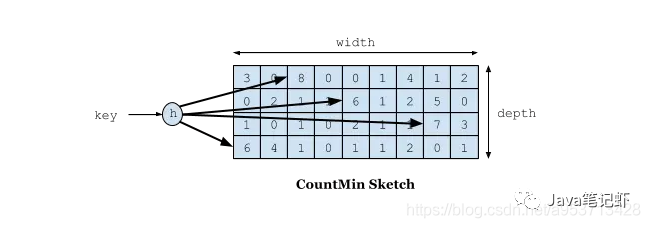
在W-TinyLFU中使用Count-Min Sketch记录我们的访问频率,而这个也是布隆过滤器的一种变种。如下图所示:
在这里插入图片描述
如果需要记录一个值,那我们需要通过多种Hash算法对其进行处理hash,然后在对应的hash算法的记录中+1,为什么需要多种hash算法呢?由于这是一个压缩算法必定会出现冲突,比如我们建立一个byte的数组,通过计算出每个数据的hash的位置。
比如张三和李四,他们两有可能hash值都是相同,比如都是1那byte[1]这个位置就会增加相应的频率,张三访问1万次,李四访问1次那byte[1]这个位置就是1万零1,如果取李四的访问评率的时候就会取出是1万零1,但是李四命名只访问了1次啊,为了解决这个问题,所以用了多个hash算法可以理解为long[][]二维数组的一个概念,比如在第一个算法张三和李四冲突了,但是在第二个,第三个中很大的概率不冲突,比如一个算法大概有1%的概率冲突,那四个算法一起冲突的概率是1%的四次方。通过这个模式我们取李四的访问率的时候取所有算法中,李四访问最低频率的次数。所以他的名字叫Count-Min Sketch。
2. 使用
Caffeine Cache 的github地址:
https://github.com/ben-manes/caffeine
目前的最新版本是:
com.github.ben-manes.caffeine
caffeine
2.6.2
2.1 缓存填充策略
Caffeine Cache提供了三种缓存填充策略:手动、同步加载和异步加载。
1.手动加载
在每次get key的时候指定一个同步的函数,如果key不存在就调用这个函数生成一个值。
/**
* 手动加载
* @param key
* @return
*/
public Object manulOperator(String key) {
Cache<String, Object> cache = Caffeine.newBuilder()
.expireAfterWrite(1, TimeUnit.SECONDS)
.expireAfterAccess(1, TimeUnit.SECONDS)
.maximumSize(10)
.build();
//如果一个key不存在,那么会进入指定的函数生成value
Object value = cache.get(key, t -> setValue(key).apply(key));
cache.put(“hello”,value);
//判断是否存在如果不存返回null
Object ifPresent = cache.getIfPresent(key);
//移除一个key
cache.invalidate(key);
return value;
}
public Function<String, Object> setValue(String key){
return t -> key + “value”;
}
2. 同步加载
构造Cache时候,build方法传入一个CacheLoader实现类。实现load方法,通过key加载value。
/**
* 同步加载
* @param key
* @return
*/
public Object syncOperator(String key){
LoadingCache<String, Object> cache = Caffeine.newBuilder()
.maximumSize(100)
.expireAfterWrite(1, TimeUnit.MINUTES)
.build(k -> setValue(key).apply(key));
return cache.get(key);
}
public Function<String, Object> setValue(String key){
return t -> key + “value”;
}
3. 异步加载
AsyncLoadingCache是继承自LoadingCache类的,异步加载使用Executor去调用方法并返回一个CompletableFuture。异步加载缓存使用了响应式编程模型。
如果要以同步方式调用时,应提供CacheLoader。要以异步表示时,应该提供一个AsyncCacheLoader,并返回一个CompletableFuture。
/**
* 异步加载
* @param key
* @return
*/
public Object asyncOperator(String key){
AsyncLoadingCache<String, Object> cache = Caffeine.newBuilder()
.maximumSize(100)
.expireAfterWrite(1, TimeUnit.MINUTES)
.buildAsync(k -> setAsyncValue(key).get());
return cache.get(key);
}
public CompletableFuture setAsyncValue(String key){
return CompletableFuture.supplyAsync(() -> {
return key + “value”;
});
}
2.2 回收策略
Caffeine提供了3种回收策略:基于大小回收,基于时间回收,基于引用回收。
1. 基于大小的过期方式
基于大小的回收策略有两种方式:一种是基于缓存大小,一种是基于权重。
// 根据缓存的计数进行驱逐
LoadingCache<String, Object> cache = Caffeine.newBuilder()
.maximumSize(10000)
.build(key -> function(key));
// 根据缓存的权重来进行驱逐(权重只是用于确定缓存大小,不会用于决定该缓存是否被驱逐)
LoadingCache<String, Object> cache1 = Caffeine.newBuilder()
.maximumWeight(10000)
.weigher(key -> function1(key))
.build(key -> function(key));
maximumWeight与maximumSize不可以同时使用。
2.基于时间的过期方式
// 基于固定的到期策略进行退出
LoadingCache<String, Object> cache = Caffeine.newBuilder()
.expireAfterAccess(5, TimeUnit.MINUTES)
.build(key -> function(key));
LoadingCache<String, Object> cache1 = Caffeine.newBuilder()
.expireAfterWrite(10, TimeUnit.MINUTES)
.build(key -> function(key));
// 基于不同的到期策略进行退出
LoadingCache<String, Object> cache2 = Caffeine.newBuilder()
.expireAfter(new Expiry<String, Object>() {
@Override
public long expireAfterCreate(String key, Object value, long currentTime) {
return TimeUnit.SECONDS.toNanos(seconds);
}
@Override
public long expireAfterUpdate(@Nonnull String s, @Nonnull Object o, long l, long l1) {
return 0;
}
@Override
public long expireAfterRead(@Nonnull String s, @Nonnull Object o, long l, long l1) {
return 0;
}
}).build(key -> function(key));
Caffeine提供了三种定时驱逐策略:
-
expireAfterAccess(long, TimeUnit):在最后一次访问或者写入后开始计时,在指定的时间后过期。假如一直有请求访问该key,那么这个缓存将一直不会过期。
-
expireAfterWrite(long, TimeUnit): 在最后一次写入缓存后开始计时,在指定的时间后过期。
-
expireAfter(Expiry): 自定义策略,过期时间由Expiry实现独自计算。
缓存的删除策略使用的是惰性删除和定时删除。这两个删除策略的时间复杂度都是O(1)。
3. 基于引用的过期方式
Java中四种引用类型
// 当key和value都没有引用时驱逐缓存
LoadingCache<String, Object> cache = Caffeine.newBuilder()
.weakKeys()
.weakValues()
.build(key -> function(key));
// 当垃圾收集器需要释放内存时驱逐
LoadingCache<String, Object> cache1 = Caffeine.newBuilder()
.softValues()
.build(key -> function(key));
注意:AsyncLoadingCache不支持弱引用和软引用。
-
Caffeine.weakKeys():使用弱引用存储key。如果没有其他地方对该key有强引用,那么该缓存就会被垃圾回收器回收。由于垃圾回收器只依赖于身份(identity)相等,因此这会导致整个缓存使用身份 (==) 相等来比较 key,而不是使用 equals()。
-
Caffeine.weakValues() :使用弱引用存储value。如果没有其他地方对该value有强引用,那么该缓存就会被垃圾回收器回收。由于垃圾回收器只依赖于身份(identity)相等,因此这会导致整个缓存使用身份 (==) 相等来比较 key,而不是使用 equals()。
-
Caffeine.softValues() :使用软引用存储value。当内存满了过后,软引用的对象以将使用最近最少使用(least-recently-used ) 的方式进行垃圾回收。由于使用软引用是需要等到内存满了才进行回收,所以我们通常建议给缓存配置一个使用内存的最大值。softValues() 将使用身份相等(identity) (==) 而不是equals() 来比较值。
Caffeine.weakValues()和Caffeine.softValues()不可以一起使用。
3. 移除事件监听
Cache<String, Object> cache = Caffeine.newBuilder()
.removalListener((String key, Object value, RemovalCause cause) ->
System.out.printf(“Key %s was removed (%s)%n”, key, cause))
.build();
4. 写入外部存储
CacheWriter 方法可以将缓存中所有的数据写入到第三方。
LoadingCache<String, Object> cache2 = Caffeine.newBuilder()
.writer(new CacheWriter<String, Object>() {
@Override public void write(String key, Object value) {
// 写入到外部存储
}
@Override public void delete(String key, Object value, RemovalCause cause) {
// 删除外部存储
}
})
.build(key -> function(key));
如果你有多级缓存的情况下,这个方法还是很实用。(搜索公众号Java知音,回复“2021”,送你一份Java面试题宝典)
注意:CacheWriter不能与弱键或AsyncLoadingCache一起使用。
5. 统计#
与Guava Cache的统计一样。
Cache<String, Object> cache = Caffeine.newBuilder()
.maximumSize(10_000)
.recordStats()
.build();
通过使用Caffeine.recordStats(), 可以转化成一个统计的集合. 通过 Cache.stats() 返回一个CacheStats。CacheStats提供以下统计方法:
-
hitRate(): 返回缓存命中率
-
evictionCount(): 缓存回收数量
-
averageLoadPenalty(): 加载新值的平均时间
3. SpringBoot 中默认Cache-Caffine Cache
SpringBoot 1.x版本中的默认本地cache是Guava Cache。在2.x(Spring Boot 2.0(spring 5) )版本中已经用Caffine Cache取代了Guava Cache。毕竟有了更优的缓存淘汰策略。
下面我们来说在SpringBoot2.x版本中如何使用cache。
1. 引入依赖:
org.springframework.boot
spring-boot-starter-cache
com.github.ben-manes.caffeine
caffeine
2.6.2
2. 添加注解开启缓存支持
添加@EnableCaching注解:
@SpringBootApplication
@EnableCaching
public class SingleDatabaseApplication {
public static void main(String[] args) {
SpringApplication.run(SingleDatabaseApplication.class, args);
}
}
3. 配置文件的方式注入相关参数
properties文件
spring.cache.cache-names=cache1
spring.cache.caffeine.spec=initialCapacity=50,maximumSize=500,expireAfterWrite=10s
或Yaml文件
spring:
cache:
type: caffeine
cache-names:
- userCache
caffeine:
spec: maximumSize=1024,refreshAfterWrite=60s
如果使用refreshAfterWrite配置,必须指定一个CacheLoader.不用该配置则无需这个bean,如上所述,该CacheLoader将关联被该缓存管理器管理的所有缓存,所以必须定义为CacheLoader<Object, Object>,自动配置将忽略所有泛型类型。
import com.github.benmanes.caffeine.cache.CacheLoader;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author: rickiyang
* @description:
*/
@Configuration
public class CacheConfig {
/**
* 相当于在构建LoadingCache对象的时候 build()方法中指定过期之后的加载策略方法
* 必须要指定这个Bean,refreshAfterWrite=60s属性才生效
* @return
*/
@Bean
public CacheLoader<String, Object> cacheLoader() {
CacheLoader<String, Object> cacheLoader = new CacheLoader<String, Object>() {
@Override
public Object load(String key) throws Exception {
return null;
}
// 重写这个方法将oldValue值返回回去,进而刷新缓存
@Override
public Object reload(String key, Object oldValue) throws Exception {
return oldValue;
}
};
return cacheLoader;
}
}
Caffeine常用配置说明:
-
initialCapacity=[integer]: 初始的缓存空间大小 -
maximumSize=[long]: 缓存的最大条数 -
maximumWeight=[long]: 缓存的最大权重 -
expireAfterAccess=[duration]: 最后一次写入或访问后经过固定时间过期 -
expireAfterWrite=[duration]: 最后一次写入后经过固定时间过期 -
refreshAfterWrite=[duration]: 创建缓存或者最近一次更新缓存后经过固定的时间间隔,刷新缓存 -
weakKeys: 打开key的弱引用 -
weakValues:打开value的弱引用 -
softValues:打开value的软引用 -
recordStats:开发统计功能
注意:
-
expireAfterWrite和expireAfterAccess同时存在时,以expireAfterWrite为准。
-
maximumSize和maximumWeight不可以同时使用
-
weakValues和softValues不可以同时使用
需要说明的是,使用配置文件的方式来进行缓存项配置,一般情况能满足使用需求,但是灵活性不是很高,如果我们有很多缓存项的情况下写起来会导致配置文件很长。所以一般情况下你也可以选择使用bean的方式来初始化Cache实例。(搜索公众号Java知音,回复“2021”,送你一份Java面试题宝典)
下面的演示使用bean的方式来注入:
package com.rickiyang.learn.cache;
import com.github.benmanes.caffeine.cache.CacheLoader;
import com.github.benmanes.caffeine.cache.Caffeine;
import org.apache.commons.compress.utils.Lists;
import org.springframework.cache.CacheManager;
import org.springframework.cache.caffeine.CaffeineCache;
import org.springframework.cache.support.SimpleCacheManager;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Primary;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.TimeUnit;
/**
* @author: rickiyang
* @description:
*/
@Configuration
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024b (备注Java)

1200页Java架构面试专题及答案
小编整理不易,对这份1200页Java架构面试专题及答案感兴趣劳烦帮忙转发/点赞


百度、字节、美团等大厂常见面试题

等大厂,18年进入阿里一直到现在。**
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
[外链图片转存中…(img-nMeuJUmR-1712048388348)]
[外链图片转存中…(img-XCeuJuaF-1712048388348)]
[外链图片转存中…(img-TU313dMn-1712048388349)]
[外链图片转存中…(img-dE1p6u51-1712048388349)]
[外链图片转存中…(img-zhO7yqtH-1712048388349)]
[外链图片转存中…(img-Rz2rgJiU-1712048388350)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录大纲截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且后续会持续更新
如果你觉得这些内容对你有帮助,可以添加V获取:vip1024b (备注Java)
[外链图片转存中…(img-CuY7sKDi-1712048388350)]
1200页Java架构面试专题及答案
小编整理不易,对这份1200页Java架构面试专题及答案感兴趣劳烦帮忙转发/点赞
[外链图片转存中…(img-zS338mPm-1712048388350)]
[外链图片转存中…(img-RnkN1lDx-1712048388351)]
百度、字节、美团等大厂常见面试题
[外链图片转存中…(img-rArttr9K-1712048388351)]














 778
778











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









