







 本文介绍了如何使用逻辑回归和随机梯度下降分类器(SGD)进行情感分析,包括搭建训练模型(TfidfVectorizer和逻辑回归),优化模型参数(网格搜索和交叉验证),以及可视化训练效果。文章还展示了如何处理文本数据,进行预处理和特征提取,以适应机器学习模型的需求。
本文介绍了如何使用逻辑回归和随机梯度下降分类器(SGD)进行情感分析,包括搭建训练模型(TfidfVectorizer和逻辑回归),优化模型参数(网格搜索和交叉验证),以及可视化训练效果。文章还展示了如何处理文本数据,进行预处理和特征提取,以适应机器学习模型的需求。
目录
四、 搭建训练模型(逻辑回归模型)
使用的训练模型是逻辑回归模型,通过在文本特征上训练逻辑回归模型来进行情感分类任务。
通过创建机器学习流水线(Pipeline),将特征提取器(TfidfVectorizer)和分类器(LogisticRegression)组合在一起。TfidfVectorizer用于将文本数据转换为向量表示,而LogisticRegression用于对向量化的文本数据进行分类。
通过使用GridSearchCV模块进行网格搜索和交叉验证,可以对逻辑回归模型的参数进行多种组合尝试,并选择在训练集上表现最佳的参数组合。最终,模型在训练集上训练得到最佳参数的逻辑回归模型。
1. 导包

2. 创建TfidfVectorizer对象
创建TfidfVectorizer对象,用于提取文本特征。参数设置包括去除重音符号、不将文本转换为小写以及不使用预处理器。

3. 定义参数网格
定义参数网格,用于网格搜索和交叉验证。参数网格中包含了多个参数的取值组合,通过尝试不同的组合来找到最佳的模型参数。

4. 创建机器学习流水线
创建机器学习流水线,包括特征提取器(TfidfVectorizer)和分类器(LogisticRegression)。
特征提取器:使用TfidfVectorizer将文本数据转换为特征向量。在流水线中,特征提取器的名称为’vect’,对应的对象是tfidf,即创建的TfidfVectorizer对象。
分类器:使用逻辑回归(Logistic Regression)算法进行分类。在流水线中,分类器的名称为’clf’,对应的对象是LogisticRegression,其中设置了random_state为0,solver为’liblinear’。

5. 创建网格搜索对象并进行网格搜索和交叉验证
创建网格搜索对象,指定要搜索的机器学习流水线(lr_tfidf)、参数网格、评分指标(accuracy)、交叉验证的折数(cv)、详细输出信息的级别(verbose)以及并行运行的作业数(n_jobs)。通过gs_lr_tfidf.fit(X_train, y_train)在训练集上进行网格搜索和交叉验证,寻找最佳的参数组合。
6. 打印结果
打印网格搜索得到的最佳参数组合以及交叉验证的得分。
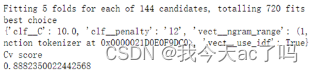
原本训练集和测试集1:1的时候得到结果为0.8431044776119403,在经过我们对于训练集和测试集比例的修改后,并且使用了全部的数据,结果比之前的好。不过有个问题,当数据量太大的时候,运行的时间太长了。
五、 优化训练模型(随机梯度下降分类器(SGD))
SGD是scikit-learn库中的一个模型类,它是一种线性分类器,适用于大规模数据集和高维特征空间。
SGD使用随机梯度下降算法进行训练,在每个训练样本上进行梯度计算和参数更新,从而逐步优化模型的权重。它可以处理二元分类和多类分类问题,并支持不同的损失函数。
SGD主要应用在大规模稀疏数据问题上,经常用在文本分类及自然语言处理,是深度学习中常用的优化算法之一。
1. 导包
stopwords.words(‘english’)获取了英语停用词列表,并将其存储在变量stop中供后续使用。这将在文本处理任务中用于过滤停用词,以提高特征提取的准确性和模型的性能。
2. 函数定义
delete_html(text): 这是一个函数定义,用于删除文本中的HTML标签、提取表情符号、删除非字母数字字符、转换为小写,并过滤停用词。函数接受一个文本作为输入,然后按照一系列的操作对文本进行处理,并返回处理后的结果。
stream_doc(path): 这是一个生成器函数定义,用于从指定路径的文件中逐行生成文本和标签。函数打开指定路径的文件,并从第二行开始遍历文件中的每一行,提取文本和标签,然后通过yield语句生成文本和标签的生成器。
get_doc(doc_stream, size): 这是一个函数定义,用于从文本流中获取指定数量的文本和标签。函数接受一个文本流和一个大小参数作为输入,通过迭代文本流,每次从文本流中获取下一个文本和标签,并将它们分别添加到文本列表和标签列表中,直到达到指定的大小。如果文本流迭代结束,则返回None值。

这些函数的目的是为了处理文本数据,删除HTML标签,提取表情符号,过滤停用词,并从文件中生成文本和标签的生成器或获取指定数量的文本和标签。这些操作通常用于文本预处理阶段,以准备数据用于机器学习模型的训练或测试。
3. 文本分类训练
基于HashingVectorizer和SGDClassifier的文本分类训练过程,通过处理文本数据、提取特征向量并训练分类模型,最终得到一个能够对新的文本进行分类的模型。

4. 模型训练
在每次迭代中,从训练数据流中获取大小为1000的训练文本和标签。如果获取的训练数据集为空,表示已经遍历完所有的训练数据,此时跳出循环。将训练文本使用vect对象进行向量化表示,将文本转换为特征向量。使用clf对象的partial_fit方法对模型进行部分拟合训练,使用获取的训练文本和标签,指定类别数组classes。更新进度条的显示,表示完成了一个迭代。
整个循环过程会重复执行45次,每次迭代都会使用不同的训练文本进行模型的部分拟合训练,最终完成模型的训练过程。

图19:训练模型
5. 打印评估结果
相比上一种方式训练全部训练集的0.89的准确度有所下降,但是在我们的FOR循环中,每次使用1000个数据进行迭代,对模型进行训练,我们只需要不到一分钟的时间就可以完成。
六、 可视化分析
1. 训练后的模型的准确率变化曲线
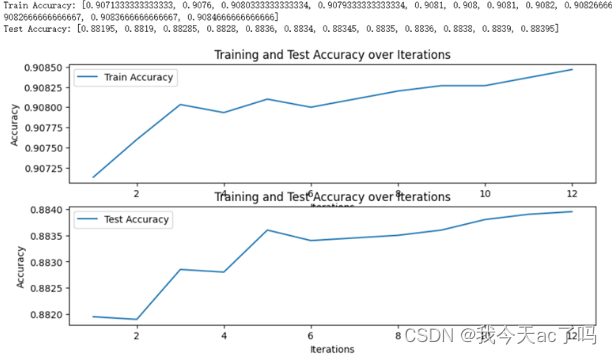
使用TF-IDF向量化器和SGD分类器对电影评论进行情感分类的过程,并绘制了训练集和测试集准确率随迭代次数的变化曲线。
具体的步骤如下:
- 读取CSV文件,获取评论文本和标签。
- 使用train_test_split函数将数据集划分为训练集和测试集,其中测试集占比为40%。
- 初始化TF-IDF向量化器vectorizer,并在训练集上进行向量化。
- 创建SGD分类器clf,使用对数损失函数进行训练。
- 初始化准确率列表train_accuracy和test_accuracy。
- 迭代训练模型,共进行num_iterations次迭代。
- 在训练集上进行部分拟合,并计算训练集上的准确率。
- 在测试集上进行预测并计算测试集上的准确率。
- 将训练集和测试集的准确率分别存储到train_accuracy和test_accuracy列表中。
- 打印训练集和测试集的准确率。
- 绘制训练集和测试集准确率随迭代次数的变化曲线。
通过使用Matplotlib库绘制两个子图,分别展示训练集和测试集准确率随迭代次数的变化曲线。
2. 深度学习模型对应的准确率变化曲线
使用TensorFlow构建了一个深度学习模型,并对电影评论进行情感分类。
具体的步骤如下:
- 导入所需的库,包括matplotlib.pyplot、tensorflow和pandas。
- 读取CSV文件movie_data.csv,获取评论文本和标签。
- 使用train_test_split函数将数据集划分为训练集和验证集,其中验证集占比为40%。
- 创建Tokenizer对象并在训练集上进行拟合,用于构建词汇表。
- 将文本转换为序列,使用texts_to_sequences方法将训练集和测试集的文本转换为对应的序列。
- 获取最大序列长度,通过找到训练集中序列的最大长度来确定。
- 使用pad_sequences函数将序列填充至相同长度,将训练集和测试集的序列填充至最大序列长度。
- 构建深度学习模型,包括嵌入层、全局平均池化层、全连接层和输出层。
- 编译模型,指定损失函数、优化器和评估指标。
- 定义回调函数History,用于保存训练过程中的指标值。
- 训练模型,使用fit方法传入训练数据、训练轮数、批次大小、验证数据和回调函数。
- 获取训练过程中的准确率和损失函数,分别存储在train_accuracy和train_loss列表中,以及验证集上的准确率和损失函数,分别存储在val_accuracy和val_loss列表中。
- 使用matplotlib.pyplot绘制训练集和验证集准确率随训练轮数的变化曲线。
- 使用matplotlib.pyplot绘制训练集和验证集损失函数随训练轮数的变化曲线。
我写的这个深度学习模型是一个简单的文本分类模型,用于对电影评论进行情感分类以下是模型的主要组成部分:
嵌入层:将输入的文本序列映射为密集的低维向量表示。使用了词嵌入技术,将输入序列的每个单词都会被嵌入为一个100维的向量。
池化层:对每个输入序列的所有词向量进行平均池化,将变长的序列转换为固定长度的特征向量。这有助于捕捉输入序列的整体语义信息。
全连接层:是一个具有64个神经元的全连接层,使用ReLU激活函数。它接收全局平均池化层的输出作为输入,并通过学习适合分类任务的非线性特征表示。
输出层:是一个具有1个神经元的全连接层,使用Sigmoid激活函数。它将全连接层的输出映射到0到1之间的概率值,表示正面情感的概率。
整个模型的目标是根据电影评论的文本内容预测情感标签,将评论分类为正面情感(1)或负面情感(0)。模型通过训练过程中的反向传播和优化算法(使用Adam优化器)来逐渐调整模型参数,以最大程度地减小训练数据上的损失函数。
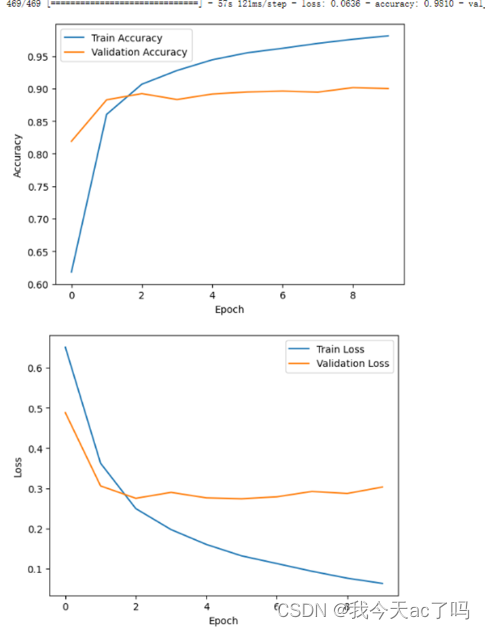
如图所示,在训练集上进行深度学习后,准确度远远高于验证准确度,而且损失函数也比验证损失函数小,说明深度学习训练效果好。
总结
这里选择了使用机器学习进行情感分析,在数据处理的时候经过构建CSV文档,读取CSV文件包含电影评论和情感标签的内容,用于训练和测试模型。为了准备文本数据进行特征提取,使用了正则表达式来剔除特定的符号或HTML标签,使用了用口袋模型进行文本处理和特征提取。这样可以清洗和规范化文本数据,使其更适合进行机器学习处理。
为了将文本数据转换为可供机器学习模型使用的特征表示,采用了TF-IDF向量化方法。使用scikit-learn库中的TfidfVectorizer类,将训练集的文本数据转换为TF-IDF特征向量表示。
在模型搭建方面,选择了随机梯度下降分类器(SGDClassifier)作为机器学习模型。这是一种线性模型,适用于大规模数据和高维特征的分类任务。在这里,使用了对数损失函数作为模型的损失函数,通过最小化损失函数来学习模型的参数。
在训练阶段,使用部分拟合方法对模型进行训练。部分拟合是一种增量式学习方法,可以逐步更新模型的参数,适用于处理大规模数据集。通过迭代训练过程,模型逐渐优化,学习数据中的模式和特征。
对于情感分析这个任务,其实主要是一个二分类任务,将电影评论分为正面情感和负面情感两类。因此,在模型训练过程中,使用了二分类的评估指标,如准确率来评估模型在训练集和测试集上的性能。实验结果表明,该模型在测试集上获得了一定的准确率,对于二分类任务的情感分析具有一定的效果。
当然,要知道训练集和测试集的比例选择通常取决于具体的应用场景和数据集大小。将数据集划分为训练集和测试集的目的是评估模型在未见过的数据上的性能表现,并检验模型的泛化能力。常见的划分比例包括 7:3、8:2 或者 9:1 等。选择适当的比例可以在一定程度上平衡训练集和测试集之间的数据量,确保有足够的数据用于模型的训练和评估。
也知道SGD(随机梯度下降),可以用于训练机器学习模型。在机器学习中,训练模型的目标是通过调整模型参数来最小化损失函数。梯度下降算法是一种常见的优化方法,而SGD是梯度下降算法的一种变体。SGD的主要思想是每次迭代时,不是使用所有训练样本的梯度来更新模型参数,而是随机选择一个样本的梯度进行更新。这种随机选择的方式可以显著减少每次迭代的计算开销,尤其适用于大规模数据集。相比于传统的梯度下降算法,SGD通常具有更快的训练速度。
SGD(随机梯度下降)可以用于训练线性分类器,其中最常见的是SGD分类器。SGD分类器是一种基于梯度下降优化算法的线性分类器。它在每次迭代中使用随机梯度下降的方式更新模型的参数,通过最小化损失函数来拟合训练数据。在SGD分类器中,模型通过一条线性决策边界将输入样本分为不同的类别。该决策边界由模型的权重向量和偏置项决定,这些参数通过迭代优化过程逐步调整。SGD分类器的优点是它对大规模数据集的训练具有高效性,因为它每次仅使用单个样本或一小批样本来更新参数,而不是使用整个训练集。这使得SGD分类器适用于大规模和在线学习任务。对于二分类问题,SGD分类器使用二元交叉熵损失函数作为目标函数,并通过梯度下降来最小化该损失。训练过程中,SGD分类器根据每个样本的特征和对应的标签进行参数更新,逐渐调整模型以最大程度地减少分类误差。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









