







 本文探讨了使用机器学习方法对泰坦尼克号沉没数据进行分析,通过多种模型如逻辑回归、随机森林、SVM等来预测乘客的生存概率,评估了不同模型的性能,以提高船舶安全的认识。
本文探讨了使用机器学习方法对泰坦尼克号沉没数据进行分析,通过多种模型如逻辑回归、随机森林、SVM等来预测乘客的生存概率,评估了不同模型的性能,以提高船舶安全的认识。
背景描述
泰坦尼克号轮船的沉没是历史上最为人熟知的海难事件之一。1912年4月15日,在她的处女航中,泰坦尼克号在与冰山相撞后沉没,在船上的 2224 名乘客和机组人员中,共造成 1502 人死亡。这场耸人听闻的悲剧震惊了国际社会,从而促进了船舶安全规定的完善。造成海难失事的原因之一是乘客和机组人员没有足够的救生艇。
数据说明
数据描述:
| 变量名称 | PassengerId | Survived | Pclass | Name | Sex | Age | SibSp | Parch | Ticket | Fare | Cabin | Embarked |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 变量解释 | 乘客编号 | 是否存活 | 船舱等级 | 姓名 | 性别 | 年龄 | 兄弟姐妹和配偶数量 | 父母与子女数量 | 票的编号 | 票价 | 座位号 | 登船码头 |
数据来源
Titanic Competition : How top LB got their score
目录
三 建模以及模型评价
1. 数据分离
将经过特征工程处理后的数据分开,分成最初的训练数据和测试数据;
1.1 读取数据
import pandas as pd
train = pd.read_csv('train.csv')
test = pd.read_csv('test.csv')
truth = pd.read_csv('gender_submission.csv')
train_and_test = pd.read_csv('经过特征工程处理后的数据.csv')
PassengerId = test['PassengerId']
1.2 划分训练集和测试集
index = PassengerId[0] - 1
train_and_test_drop = train_and_test.drop(['PassengerId', 'Name', 'Ticket'], axis=1)
train_data = train_and_test_drop[:index]
test_data = train_and_test_drop[index:]
train_X = train_data.drop(['Survived'], axis=1)
train_y = train_data['Survived']
test_X = test_data.drop(['Survived'], axis=1)
test_y = truth['Survived']
train_X.shape, train_y.shape, test_X.shape
2. 建模以及模型评价
from sklearn.linear_model import LogisticRegression # 逻辑回归
from sklearn.ensemble import RandomForestClassifier # 随机森林
from sklearn.svm import SVC # 支持向量机
from sklearn.neighbors import KNeighborsClassifier # K最近邻
from sklearn.tree import DecisionTreeClassifier # 决策树
from sklearn.ensemble import GradientBoostingClassifier # 梯度提升树GBDT
import lightgbm as lgb # LightGBM算法
from xgboost.sklearn import XGBClassifier # XGBoost算法
from sklearn.ensemble import ExtraTreesClassifier # 极端随机树
from sklearn.ensemble import AdaBoostClassifier #
from sklearn.ensemble import BaggingClassifier
from sklearn.metrics import roc_auc_score # 准确率评价模型好坏
import warnings
warnings.filterwarnings("ignore")
2.1 逻辑回归
lr = LogisticRegression() # logit 逻辑回归
lr.fit(train_X, train_y)
pred_lr = lr.predict(test_X)
accuracy_lr = roc_auc_score(test_y, pred_lr)
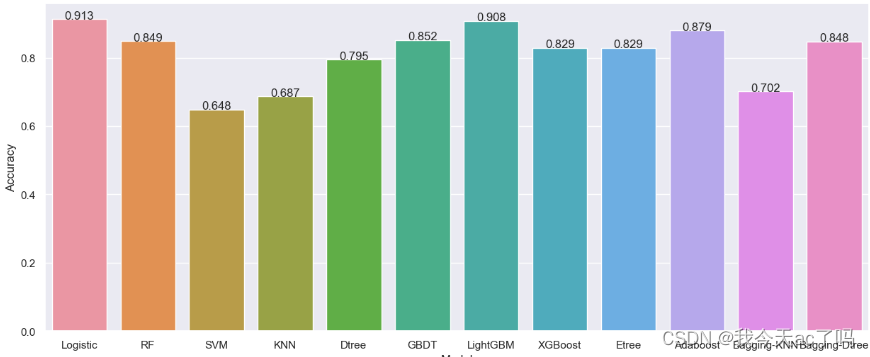
print("逻辑回归的预测结果:", accuracy_lr)
2.2 随机森林-RF
rfc = RandomForestClassifier()
rfc.fit(train_X, train_y)
pred_rfc = rfc.predict(test_X)
accuracy_rfc = roc_auc_score(test_y, pred_rfc)
print("随机森林的预测结果:", accuracy_rfc)
2.3 支持向量机-SVM
svm = SVC()
svm.fit(train_X,train_y)
pred_svm = svm.predict(test_X)
accuracy_svm = roc_auc_score(test_y, pred_svm)
print("支持向量机的预测结果:", accuracy_svm)
2.4 K最近邻-KNN
knn = KNeighborsClassifier()
knn.fit(train_X,train_y)
pred_knn = knn.predict(test_X)
accuracy_knn = roc_auc_score(test_y, pred_knn)
print("K最近邻分类器的预测结果:", accuracy_knn)
2.5 决策树
dtree = DecisionTreeClassifier()
dtree.fit(train_X,train_y)
pred_dtree = dtree.predict(test_X)
accuracy_dtree = roc_auc_score(test_y, pred_dtree)
print("决策树模型的预测结果:", accuracy_dtree)
2.6 梯度提升决策树-GBDT
gbdt = GradientBoostingClassifier()
gbdt.fit(train_X, train_y)
pred_gbdt = gbdt.predict(test_X)
accuracy_gbdt = roc_auc_score(test_y, pred_gbdt)
print("GBDT模型的预测结果:", accuracy_gbdt)
2.7 LightGBM算法
lgb_train = lgb.Dataset(train_X, train_y)
lgb_eval = lgb.Dataset(test_X, test_y, reference = lgb_train)
gbm = lgb.train(params = {}, train_set = lgb_train, valid_sets = lgb_eval)
pred_lgb = gbm.predict(test_X, num_iteration = gbm.best_iteration)
accuracy_lgb = roc_auc_score(test_y, pred_lgb)
print("LightGBM模型的预测结果:", accuracy_lgb)
2.8 XGBoost算法
xgbc = XGBClassifier()
xgbc.fit(train_X, train_y)
pred_xgbc = xgbc.predict(test_X)
accuracy_xgbc = roc_auc_score(test_y, pred_xgbc)
print("XGBoost模型的预测结果:", accuracy_xgbc)
2.9 极端随机树
etree = ExtraTreesClassifier()
etree.fit(train_X, train_y)
pred_etree = etree.predict(test_X)
accuracy_etree = roc_auc_score(test_y, pred_etree)
print("极端随机树模型的预测结果:", accuracy_etree)
2.10 AdaBoost算法
abc = AdaBoostClassifier()
abc.fit(train_X, train_y)
pred_abc = abc.predict(test_X)
accuracy_abc = roc_auc_score(test_y, pred_abc)
print("AdaBoost模型的预测结果:", accuracy_abc)
2.11 基于Bagging的K最近邻
bag_knn = BaggingClassifier(KNeighborsClassifier())
bag_knn.fit(train_X, train_y)
pred_bag_knn = bag_knn.predict(test_X)
accuracy_bag_knn = roc_auc_score(test_y, pred_bag_knn)
print("基于Bagging的K紧邻模型的预测结果:", accuracy_bag_knn)
2.12 基于Bagging的决策树
bag_dt = BaggingClassifier(DecisionTreeClassifier())
bag_dt.fit(train_X, train_y)
pred_bag_dt = bag_dt.predict(test_X)
accuracy_bag_dt = roc_auc_score(test_y, pred_bag_dt)
print("基于Bagging的决策树模型的预测结果:", accuracy_bag_dt)
3. 小结
如果本文有存在不足的地方,欢迎大家在评论区留言。
















 1789
1789

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









