







下图是完美实现微服务的十二原则: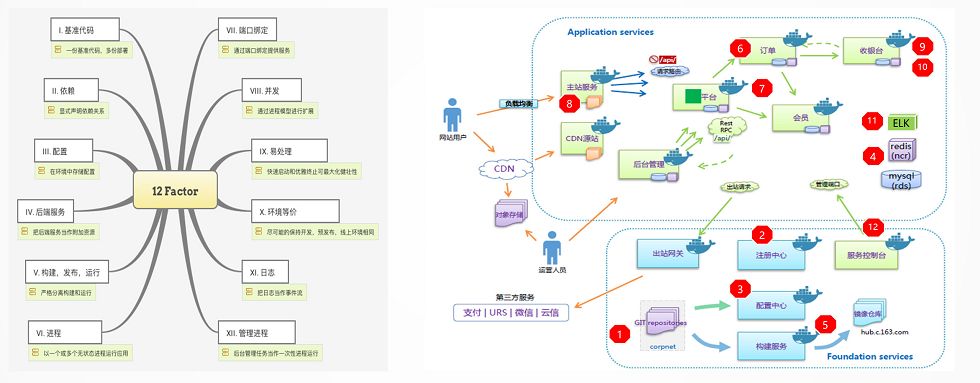
接下来,细说微服务架构设计中不得不知的十大要点。
负载均衡 + API 网关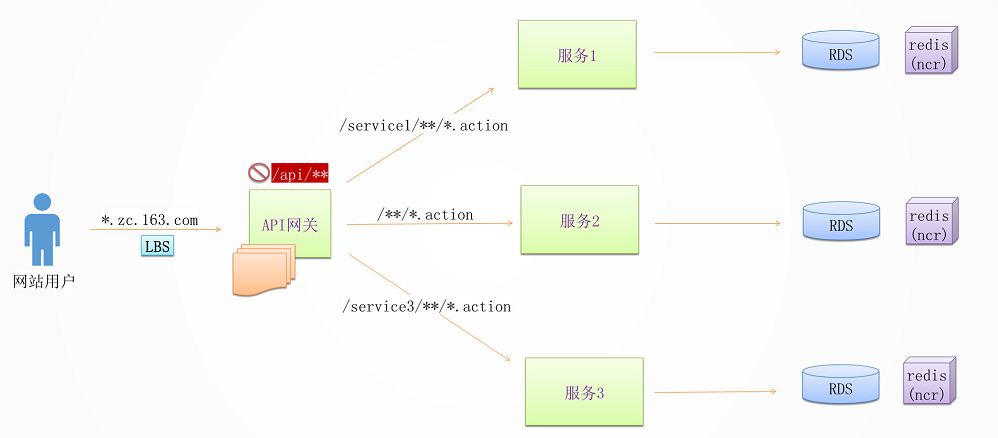
在实施微服务的过程中,不免要面临服务的聚合与拆分。
当后端服务的拆分相对比较频繁的时候,作为手机 App 来讲,往往需要一个统一的入口,将不同的请求路由到不同的服务,无论后面如何拆分与聚合,对于手机端来讲都是透明的。
有了 API 网关以后,简单的数据聚合可以在网关层完成,这样就不用在手机 App 端完成,从而手机 App 耗电量较小,用户体验较好。
有了统一的 API 网关,还可以进行统一的认证和鉴权,尽管服务之间的相互调用比较复杂,接口也会比较多。
API 网关往往只暴露必须的对外接口,并且对接口进行统一的认证和鉴权,使得内部的服务相互访问的时候,不用再进行认证和鉴权,效率会比较高。
有了统一的 API 网关,可以在这一层设定一定的策略,进行 A/B 测试,蓝绿发布,预发环境导流等等。
API 网关往往是无状态的,可以横向扩展,从而不会成为性能瓶颈。
无状态化与独立有状态集群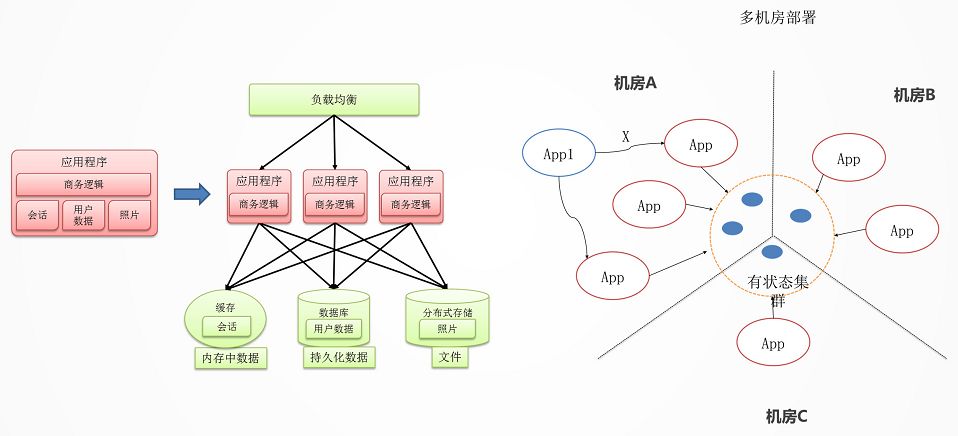
影响应用迁移和横向扩展的重要因素就是应用的状态。无状态服务,是要把这个状态往外移,将 Session 数据,文件数据,结构化数据保存在后端统一的存储中,从而应用仅仅包含商务逻辑。
状态是不可避免的,例如 ZooKeeper,DB,Cache 等,把这些所有有状态的东西收敛在一个非常集中的集群里面。
整个业务就分两部分,一个是无状态的部分,一个是有状态的部分。
无状态的部分能实现两点:
跨机房随意地部署,也即迁移性。
弹性伸缩,很容易地进行扩容。
有状态的部分,如ZooKeeper,DB,Cache 有自己的高可用机制,要利用到它们自己高可用的机制来实现这个状态的集群。
虽说无状态化,但是当前处理的数据,还是会在内存里面的,当前的进程挂掉数据,肯定也是有一部分丢失的。
为了实现这一点,服务要有重试的机制,接口要有幂等的机制,通过服务发现机制,重新调用一次后端服务的另一个实例就可以了。
数据库的横向扩展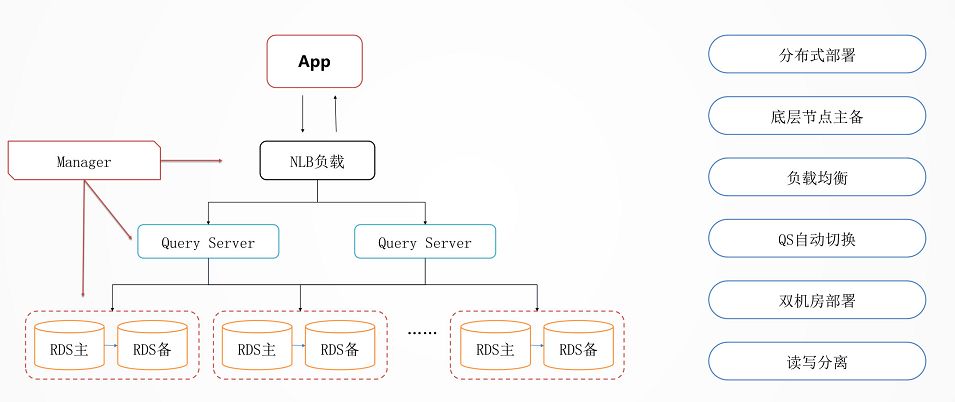
数据库是保存状态,是最重要的也是最容易出现瓶颈的。有了分布式数据库可以使数据库的性能随着节点增加线性地增加。
分布式数据库最最下面是 RDS,是主备的,通过 MySQL 的内核开发能力,我们能够实现主备切换数据零丢失。
所以数据落在这个 RDS 里面,是非常放心的,哪怕是挂了一个节点,切换完了以后,你的数据也是不会丢的。
再往上就是横向怎么承载大的吞吐量的问题,上面有一个负载均衡 NLB,用 LVS,HAProxy,Keepalived,下面接了一层 Query Server。
Query Server 是可以根据监控数据进行横向扩展的,如果出现了故障,可以随时进行替换的修复,对于业务层是没有任何感知的。
另外一个就是双机房的部署,DDB 开发了一个数据运河 NDC 的组件,可以使得不同的 DDB 之间在不同的机房里面进行同步。
这时候不但在一个数据中心里面是分布式的,在多个数据中心里面也会有一个类似双活的一个备份,高可用性有非常好的保证。
 缓存
缓存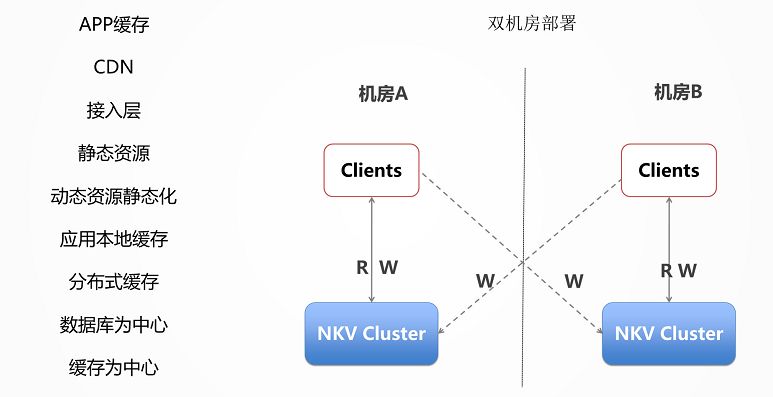
**在高并发场景下缓存是非常重要的。**要有层次的缓存,使得数据尽量靠近用户。数据越靠近用户能承载的并发量也越大,响应时间越短。
在手机客户端 App 上就应该有一层缓存,不是所有的数据都每时每刻从后端拿,而是只拿重要的,关键的,时常变化的数据。
尤其对于静态数据,可以过一段时间去取一次,而且也没必要到数据中心去取,可以通过 CDN,将数据缓存在距离客户端最近的节点上,进行就近下载。
有时候 CDN 里面没有,还是要回到数据中心去下载,称为回源,在数据中心的最外层,我们称为接入层,可以设置一层缓存,将大部分的请求拦截,从而不会对后台的数据库造成压力。
如果是动态数据,还是需要访问应用,通过应用中的商务逻辑生成,或者去数据库读取,为了减轻数据库的压力,应用可以使用本地的缓存,也可以使用分布式缓存。
如 Memcached 或者 Redis,使得大部分请求读取缓存即可,不必访问数据库。
当然动态数据还可以做一定的静态化,也即降级成静态数据,从而减少后端的压力。
服务拆分与服务发现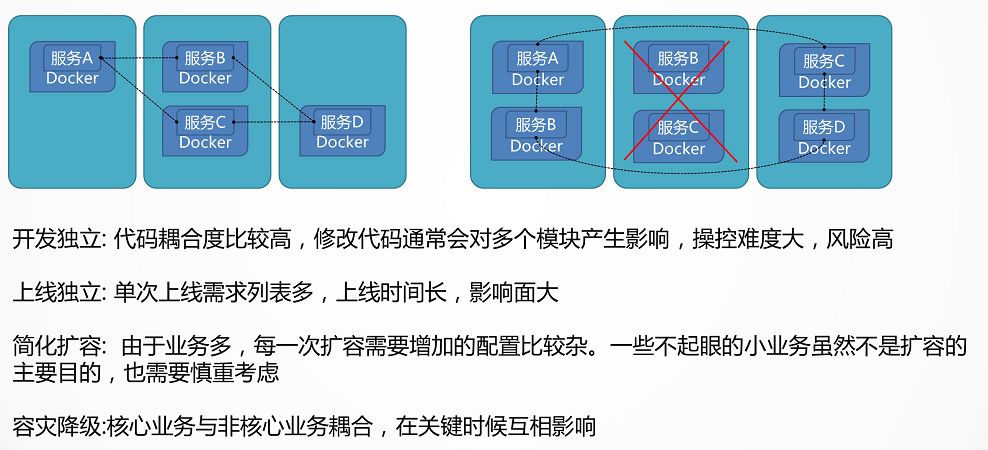
当系统扛不住,应用变化快的时候,往往要考虑将比较大的服务拆分为一系列小的服务。
这样第一个好处就是开发比较独立,当非常多的人在维护同一个代码仓库的时候,往往对代码的修改就会相互影响。
常常会出现我没改什么测试就不通过了,而且代码提交的时候,经常会出现冲突,需要进行代码合并,大大降低了开发的效率。
另一个好处就是上线独立,物流模块对接了一家新的快递公司,需要连同下单一起上线,这是非常不合理的行为。
我没改还要我重启,我没改还让我发布,我没改还要我开会,都是应该拆分的时机。
再就是高并发时段的扩容,往往只有最关键的下单和支付流程是核心,只要将关键的交易链路进行扩容即可,如果这时候附带很多其他的服务,扩容既是不经济的,也是很有风险的。
另外的容灾和降级,在大促的时候,可能需要牺牲一部分的边角功能,但是如果所有的代码耦合在一起,很难将边角的部分功能进行降级。
当然拆分完毕以后,应用之间的关系就更加复杂了,因而需要服务发现的机制,来管理应用相互的关系,实现自动的修复,自动的关联,自动的负载均衡,自动的容错切换。
服务编排与弹性伸缩
当服务拆分了,进程就会非常的多,因而需要服务编排来管理服务之间的依赖关系,以及将服务的部署代码化,也就是我们常说的基础设施即代码。
这样对于服务的发布,更新,回滚,扩容,缩容,都可以通过修改编排文件来实现,从而增加了可追溯性,易管理性,和自动化的能力。
既然编排文件也可以用代码仓库进行管理,就可以实现一百个服务中,更新其中五个服务,只要修改编排文件中的五个服务的配置就可以。
当编排文件提交的时候,代码仓库自动触发自动部署升级脚本,从而更新线上的环境。
当发现新的环境有问题时,当然希望将这五个服务原子性地回滚,如果没有编排文件,需要人工记录这次升级了哪五个服务。
有了编排文件,只要在代码仓库里面 Revert,就回滚到上一个版本了。所有的操作在代码仓库里都是可以看到的。
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

最后
2020年在匆匆忙忙慌慌乱乱中就这么度过了,我们迎来了新一年,互联网的发展如此之快,技术日新月异,更新迭代成为了这个时代的代名词,坚持下来的技术体系会越来越健壮,JVM作为如今是跳槽大厂必备的技能,如果你还没掌握,更别提之后更新的新技术了。

更多JVM面试整理:

《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
更新的新技术了。
[外链图片转存中…(img-WobEa8T7-1713520211853)]
更多JVM面试整理:
[外链图片转存中…(img-NmlRULAv-1713520211853)]
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!















 291
291











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









