







 本文介绍了ClickHouse在字节跳动广告DMP和CDP中的应用,重点讨论了第一版技术方案,包括明细存储、SQL优化以及在面对复杂查询和大查询时的不足。第二版方案引入了RoaringBitmap,通过位图计算优化了查询性能,减少了数据传输和资源消耗。文章还提到了RoaringBitmap的局限性及其改进,包括编码优化、并行计算和读取优化,展示了在ClickHouse上进行位图处理如何提升计算效率。
本文介绍了ClickHouse在字节跳动广告DMP和CDP中的应用,重点讨论了第一版技术方案,包括明细存储、SQL优化以及在面对复杂查询和大查询时的不足。第二版方案引入了RoaringBitmap,通过位图计算优化了查询性能,减少了数据传输和资源消耗。文章还提到了RoaringBitmap的局限性及其改进,包括编码优化、并行计算和读取优化,展示了在ClickHouse上进行位图处理如何提升计算效率。
那么首先是我们的第一版技术方案,这个技术方案的背景是,业务提出来希望能够尽快上线,时间比较紧。

我们采用明细存储的方式,表有 2 列,分别是 tag_id 和 uid。每一个 tag_id 表示一个人群包,uid 是对应的用户 id。那么如果是一个比较大的人群包,可能需要用上亿行来表示。我们对 tag_id 建立了主键,因此可以快速的找出对应的用户 id 集合。集合的交集操作会转化为 in,并集为 or,补集为 not in 表示。

我们看一个具体的例子。如果我们要求 A 交上 B 和 C 的并集。那么对应的 sql 就是如此。其中,交集是采用 in 子查询的方式。并集直接用 or 表示。其中,SELECT distinct uid FROM tag_uid_map WHERE (tag_id = B) OR (tag_id = C) 用来表示 B | C。SELECT count distinct(uid) FROM tag_uid_map WHERE tag_id = A 表示集合 A,uid IN 表示求交集计算。
A&(B|C)
SELECT count distinct(uid)
FROM tag_uid_map
WHERE tag_id = A
AND uid IN (
SELECT distinct uid
FROM tag_uid_map
WHERE (tag_id = B) OR (tag_id = C)
)
在这种情况下,我们想要快速的求出 sql 的结果,采用了 2 个优化方向:
-
因为 clickhouse 是分布式数据库,我们希望尽可能并行计算,减少节点之间数据传输,把计算下推下去,减少汇聚节点的计算压力。
-
因为最后要获取去重后的用户数,看看如何能够快速计算 count distinct。上一次分享也有人问字节是否在 count distinct 做过一些优化?我们也做了一些优化和尝试。

我们继续看之前的场景, A 交上 B 和 C 的并集。我们有没有办法能够划分不同的区间进行并行计算呢?答案当然是有的。

如果我们把用户 id 按照奇数偶数分为 2 个区间,可以保证一个用户只会在一个区间内,因为用户的 id 要么是奇数要么是偶数,且区间之间用户 id 不重复。那么 A B C 也同样划分为奇偶两个区间。在这样的基础上,可以在区间内单独的计算子集合的结果最后对区间计算结果进行汇总。A 交上 B 和 C 的并集就等于 A_奇数集合 交上 B_奇数集合和 C_奇数集合的并集 并上 A_偶数集合 交上 B_偶数集合和 C_偶数集合的并集的结果。对于人群预估来说,我们更关心集合的数目。A 交上 B 和 C 的并集所对应用户的个数可以转化为,A_奇数集合 交上 B_奇数集合和 C_奇数集合的并集所对应用户的个数加上 A_偶数集合 交上 B_偶数集合和 C_偶数集合的并集的用户数。因此,通过把用户 id 划分到不同的集合,我们可以在每个集合上并行计算。最后只需要把每个集合的用户数做一次累加就可以,我们的计算方式就是这样的。
以 A 交 B 为例:


我们在数据导入的时候按照用户 id 划分为 4 个区间,分别导入到 4 台不同的机器,保证每台机器上的用户不重复。这样在每一台机器计算完结果后,直接把结果进行汇总。同时,在人群预估的场景下,我们返回的是子区间 count distinct 结果,而不是对应的聚合函数中间状态。这样可以大大减少输的数据量。同时,最后只需要做一次累加,不需要把聚合函数中间状态进行 merge 后求去重后结果。实际场景的话我们划分的区间数可能要比机器数要多,这样才可能并行导入。
因此,在 clickhouse 上的改动主要是两个:
-
导入的时候按照 uid 分片,实际中肯定不是按照奇偶来划分了
-
扩充了 sql 语法,并行计算,修改了引擎的执行逻辑。支持 count distinct 中间结果不做 merge 直接进行累加
第二个优化是快速计算 count distinct,这里我们做过几个方向的尝试,比较通用的思路有两个:
-
优化 hash 函数,能够快速求出 hash 结果。
-
通过一些近似函数的方式,在允许一定的误差的情况下快速求出结算结果,比如 UniqHLL12/UniqCombined 等
其他还有一些思路偏探索,主要是精确算法下优化 hash 表的结构,减少 hash 冲突。
随着上面的一系列优化后,第一版本的方案上线了。
-
优点是基本能满足需求,大部分的查询都小于 5 s。
-
缺点是当表达式非常复杂,特别是存在很多的交集和补集的时候,由于交集和补集需要用子查询来实现,SQL 会非常长,对用户很不友好,且不利于分析。
-
其次,当人群包非常大且表达式复杂的时候查询容易超时。因为 in 和 not in 的操作是比较花费 cpu 资源的。
随着数据量的不断增长 ClickHouse 在当前存储引擎的支持下也难以保证查询时间,而且这些大查询还会影响其他查询,因此我们觉得有必要做新一版的开发。
技术方案 V2
下面介绍一下我们的第二版方案。这个方案做了很多的优化,我们也已经对核心的技术方案申请了专利。

我们认为,可以使用位图来进行计算,因为位图是一种逻辑上非常巧妙的描叙集合的方法。根据用户 id 的特性,我们准备采用性能最好的稀疏位图索引 RoaringBitmap 来表示一个标签对应的人群包。在这样的情况下,集合的计算可以转换到对应位图的计算。
例如 A 交上 B 和 C 的并集可以转换为 RoaringBitmap 的计算
 ClickHouse 其实有引入 RoaringBitmap,但是是 32 位的 bitmap。而我们的用户规模用 32 位表示并不够,因此我们给 ClickHouse 引入了 Bitmap64 类型和一系列的相关计算函数。
ClickHouse 其实有引入 RoaringBitmap,但是是 32 位的 bitmap。而我们的用户规模用 32 位表示并不够,因此我们给 ClickHouse 引入了 Bitmap64 类型和一系列的相关计算函数。
我们第二版本的表结构长这样,还是 2 列,但不需要明细存储。一列 tag_id 用来表示标签,另外用类型为 Bitmap64 的 uids 列表示标签所对应的用户 id。
相比于第一个方案,tag_id 只需要存 1 个,会节省空间。另外,uids 用 RoaringBitmap 存储也会比原来的存储要节省不少空间。而集合的交并补也对应了 bitmap 的交并补计算。

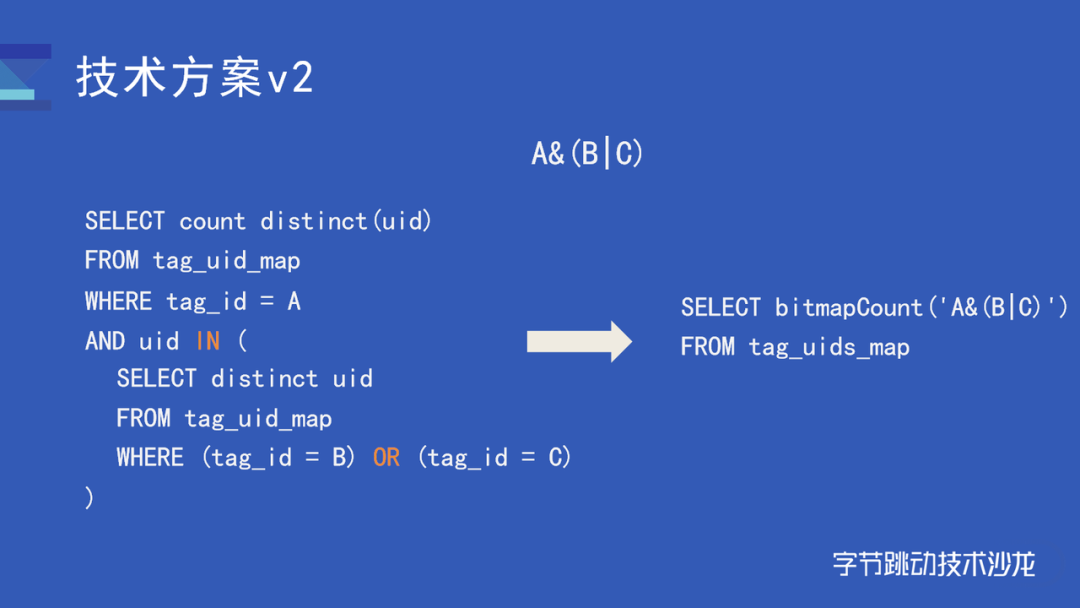
如果我们要求 A 交上 B 和 C 的并集。对应的 sql 相比第一版本就要简单很多了。看右边,基本上从表达式就能对计算的内容一目了然,非常直观。相比于使用第一版本的建表和查询方式,使用 bitmap 有如下优势:
-
空间节省,没有冗余数据,RoaringBitmap 存储高效
-
计算高效
-
Sql 直观,无需子查询,且具有更好的拓展性。
光是用 RoaringBitmap 其实是不够的,我们花了 1-2 个礼拜快速做了一个 demo 出来,发现效果并不理想,与第一版本的差距不大。我们在这个基础上做了很多的优化,目标就是让整体计算尽可能得快,可以分为以下几个方面:
-
和第一版本的想法一样,尽可能的并行计算,减少数据传输
-
在数据层面进行优化
-
计算的优化
-
读取的优化
-
通过 cache 减少计算的数据量
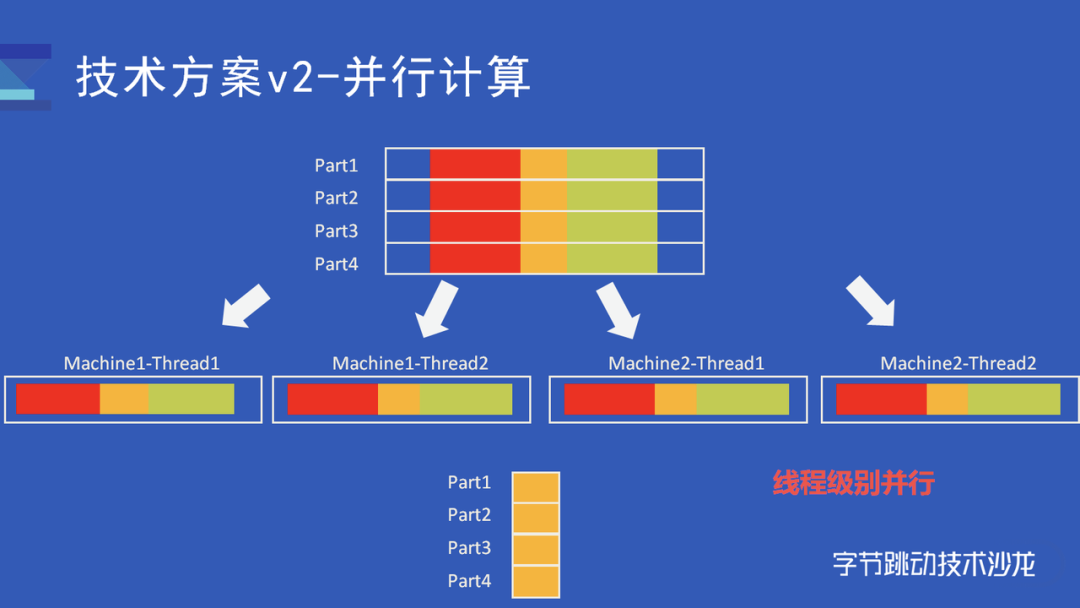
首先是并行计算,相比于之前用子查询来表示交集和补集,采用 RoaringBitmap 来实现交集和补集要简单很多,这样使得我们的计算可以更加充分的并行,到线程粒度。这样,一方面我们可以更好的利用上多核的计算资源。另一方面,可以更好的控制查询使用的资源,避免一些大查询占用过多资源。如上图所示,我们把全量数据分成很多份,每台机器的每一个线程处理其中一部分的数据,得出对应的计算结果。最后将各线程直接合并。
这个与 ClickHouse 默认的处理机制是不一样的,Clickhouse 在多线程读取的时候,读取的数据并不是固定的,哪个线程处理完了就去读新的数据,当处理速度跟不上的话也会降低线程数目。如果要实现每个线程固定读对应的数据,并在读取完成后完成计算,就需要修改整个读取和处理模型。
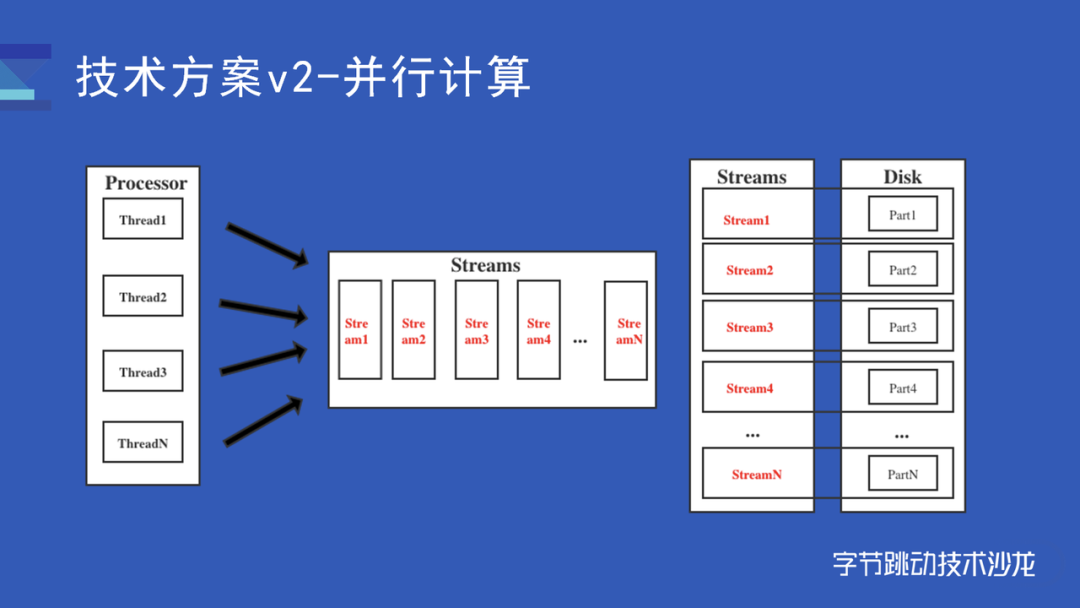
这个是我们的读取和处理模型,可以看到,数据在导入的时候被分成了若干份,每一份 uid 都是独立的。我们通过建立 input stream 去读取对应的数据,stream 的数量和数据分成的数量相等,并保证一个同一份数据只会进入一个 Stream。ParallelBitMapProcessor 构造一个线程池,从队列里面一次取 Stream 进行数据读取,当一个线程完全读完一个 Stream 之后,才会调用下一个 stream。
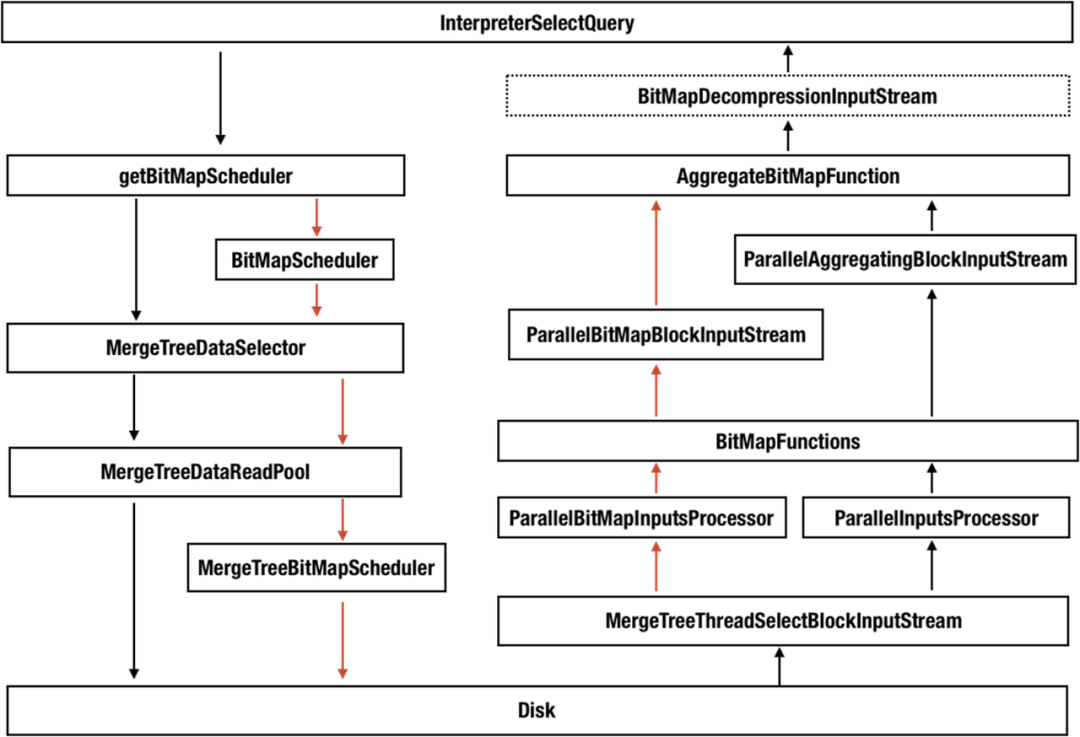
ClickHouse 整体的结构如上图所示,黑色的是原来 ClickHouse 的读取和执行流程,红色的是我们新增的,可以看到,基本上整个读取和执行流程都发生了变化,改动还是比较大的。

在整个并行后我们发现效果并不是非常理想,相比于第一版本的提升并不明显,通过对 RoaringBitmap 底层原理的深入研究和对数据的分析,我们发现,原因是因为区间内的用户 id 过于离散。
离散的原因有 2 点:
-
uid 的生成并不是连续的。
-
由于数据按照一定规则均匀划分到不同的区间内,那么就会导致子区间内的数据比原始空间更加离线。
那么为什么离散的情况下会导致计算效果并不理想,大家可能有疑问,RoaringBitmap 不就是用来存储稀疏的数据的吗?
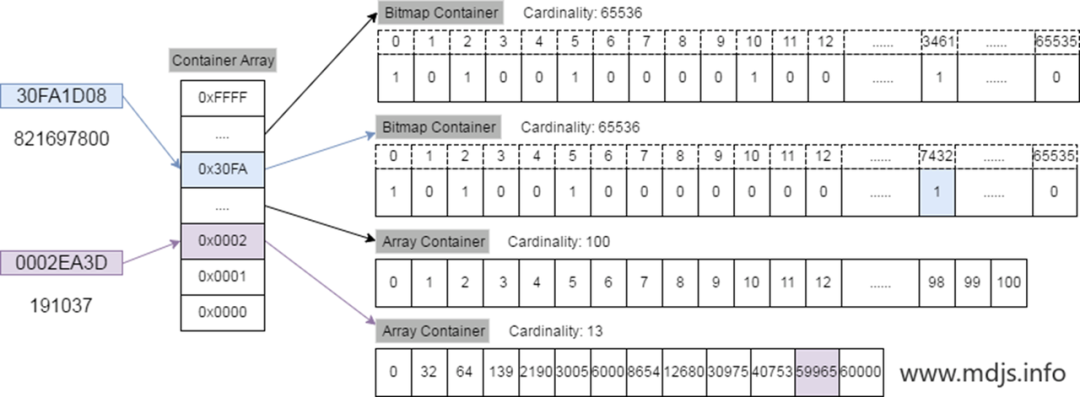
原因跟 RoaringBitmap64 的实现有关,RoaringBitmap64 是由一系列 RoaringBitmap32 表示。实现方式有很多种,一种比较通用的做法用 map 存储,是把前 32 位存成 key,value 是 后 32 所对应的 RoaringBitmap32,RoaringBitmap32 的实现如图中所示。
第一层称之为 Chunk(高 16 位),如果该取值范围内没有数据就不会创建 Chunk。
第二层称之为 Container(低 16 位),会依据数据分布进行创建。
RoaringBitmap32 使用两种容器结构:Array Container 和 Bitmap Container。Array Container 存放稀疏的数据,Bitmap Container 存放稠密的数据。若一个 Container 里面的元素数量小于 4096,就使用 Array Container;反之,就用 Bitmap 来存储值。
当数据比较稀疏的时候,我们发现一个人群包对应的 RoaringBitmap64 由很多个 RoaringBitmap32 组成,每个 RoaringBitmap32 内部又由很多个 array container 组成。而对有序数组的交并补计算尽管也比较高效,但是相比于 bitmap 计算来说还是有明显的差异。这样导致计算性能提升不上去。因此我们就在想,能不能通过编码的方式,对区间内的数据进行编码,让数据更加集中,从而提升计算效率。事实上我们也是这么做的,我们实现了一种高效的编码,希望达到如下效果:
-
编码后同一个区间内的用户相对集中
-
不同区间的用户编码后同样在不同的区间内
-
编码后同一个人群包同一个区间内的用户 id 相对集中
通过编码,能够非常好地加速计算,计算速度提升 1~2 个量级
当然,编码的过程是在引擎内部实现的,对用户是无感知的。当数据导入的时候,会自动完成编码。
这块其实有一个比较大的工程量,有这几个问题需要解决:
-
编码相当于是一个额外的工作量,会对导入有一定影响。同时,如果要导出 uid,需要增加额外的解码过程。如何减少编、解码带来的额外的代价。
-
原来为了能够尽快导入数据,我们是采用并行导入的方式。增加了额外的编码环节是否会导致导入必须要串行来完成,并行导入如果都在写字典是否会导致数据产生冲突
-
主备之间如何高效同步字典,避免字典的同步不及时导致数据无法解码。有一些一致性的问题要处理。
-
字典如何高效管理、备份,避免丢失。

除了数据通过编码优化分布性外,我们还从工程的角度对计算进行了优化。主要有下面 3 点:
-
通过一些指令集计算和汇编指令对计算进行加速,在我们实际测试中发现这个能够大大加快计算速度。
-
另外,我们 bitmap 的计算能够尽可能在原地完成,减少数据拷贝。举个例子,求 A 与 C 的并集,我们可以直接在 A 上面进行计算,得到结果。当我们的计算表达式包含多个 A 的时候且 A 在左侧的时候,这样就失效了。因此,需要我们处理的时候需要对整个表达式进行处理和判断,看看哪些计算可以在原地完成。当然,更进一步的话,在这个 Case 中我们通过移动位置(A 和 C 交换位置)也是可以做到原地计算的。
-
是我们在对比第一第二版本的时候发现,bitmap 在交集和补集的性能上相比原来的子查询有非常明显的提升,但是在大量的并集的情况下与原来的相比提升不够明显。这个一方面说明 clickhouse 的性能还是非常优越的,另一方面也给我们带来了挑战。最后我们发现可以把 RoaringBitmap32 的 Fast Union 的思想移植到 RoaringBiamap64 上,通过 lazy 计算的方式,提高大量并集的计算性能。
当然,以上说的其实是我们在工程实践的一些大的有明显效果的优化点,其实小的优化点还有很多,工程上要做的事情很多。
除了计算以外,读取的优化也很重要。大家都知道 clickhouse 是列存数据库,对于每一列的数据又是分块存储的,默认是每 8192 行为一块。分块存储的好处是能够更好的做压缩,减小数据存储。对于一些基本类型来说效果很好。但是对于 bitmap 类型来说本身值的类型就非常大,8192 行组成的块大小非常大,如果我只是读取其中的一个 bitmap,会有很大的读放大,会非常影响性能。
另外,由于 clickhouse 是一个在主键上的稀疏索引,并不能精确地定位某一个块中是否包含对应的数据。这个对于普通类型也是没有问题的,因为有的时候建立精确索引并且查找索引的代价还不如直接暴力扫原始数据。但是对于 bitmap 来说我们是希望能够精确到定位到数据的。
因此我们做了这几个优化:
-
调整块的大小,把默认的 8192 行改成了 128,这个是我们实际测试中在我们场景的最佳实践。如果数据太细,那么会导致 mark 文件过大,读取索引定位数据的时间变长。
-
定期合并历史数据,因为我们有的标签是一个增量数据,我们希望通过一些合并减少数据读取
-
通过二级索引的方式能够更好的精确定位,尽量减少读取不需要的数据

最后一个优化点也是很多系统都必备的,那就是 cache。因为用户读取的数据和计算的结果通常具有 2 8 原则,即经常读取的都是一小部分数据。因此,我们通过 cache 可以加速第二、第三次读取时间。实际上我们做了三层的 cache:
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数初中级Android工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则近万的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Android移动开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Android开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注:Android)

总结
最后为了帮助大家深刻理解Android相关知识点的原理以及面试相关知识,这里放上相关的我搜集整理的14套腾讯、字节跳动、阿里、百度等2021最新面试真题解析,我把技术点整理成了视频和PDF(实际上比预期多花了不少精力),包知识脉络 + 诸多细节。
网上学习 Android的资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
《Android学习笔记总结+移动架构视频+大厂面试真题+项目实战源码》,点击传送门即可获取!
的原理以及面试相关知识,这里放上相关的我搜集整理的14套腾讯、字节跳动、阿里、百度等2021最新面试真题解析,我把技术点整理成了视频和PDF(实际上比预期多花了不少精力),包知识脉络 + 诸多细节。
[外链图片转存中…(img-oxK5VXNF-1711994938759)]
[外链图片转存中…(img-4M5Z46Cn-1711994938759)]
[外链图片转存中…(img-EJ81uc5v-1711994938759)]
[外链图片转存中…(img-WkSgAYC0-1711994938759)]
网上学习 Android的资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









