







- dictionary:字典类型
字符串类型
=========
字符串类型由以下结构表示:字符串长度:字符串原文,例如:
42:udp://tracker.pirateparty.gr:6969/announce。
整形类型
========
整形类型由以下结构表示:i<整形数据>e,例如i1234e,则表明的整形数据为1234。
列表类型
========
列表类型由以下结构表示:l<列表数据>e,即列表以字母l开头,以字母e结束,中间的均为列表中的数据,中间的值可以为任意的四种类型之一。
字典类型
========
字典类型由以下结构表示:d<字典数据>e,即字典由字母d开头,以字母e结束,中间的均为字典中的数据,中间的值可以为任意的四种类型之一。
实际组合解析
==========
根据上述描述来看看实际的内容解析,我们以下方的数据为例:
d8:announce49:udp://tracker.leechers-paradise.org:6969/announce13:announce-listll49:udp://tracker.leechers-paradise.org:6969/announceel48:udp://tracker.internetwarriors.net:1337/announceeee
大家可以先尝试根据上面的内容对这一串内容进行解析,我将这一串数据拆分开来方便大家理解和查看,可以明显看出其由一个拥有两个键值的字典,其中一个键为announce,另一个键为announce-list,两者的值一个为
udp://tracker.leechers-paradise.org:6969/announce,一个为列表,列表内还嵌套了一层列表。
d
8:announce
49:udp://tracker.leechers-paradise.org:6969/announce
13:announce-list
l
l
49:udp://tracker.leechers-paradise.org:6969/announce
e
l
48:udp://tracker.internetwarriors.net:1337/announce
e
e
e
回到顶部
Torrent文件解析
===============
根据上文对Torrent文件编码的了解,那么我们使用代码对Torrent文件就很简单了。我们只需要读取种子字节流,判断具体是哪种类型并进行相应转换即可。
即:读取文件字节,判断字节属于哪一种类型:0-9 : 字符串类型、i:整形数据、l:列表数据、d:字典数据
再根据每个数据具体类型获取该数据的内容,再读取下一个文件字节获取下一个数据类型即可,根据这个分析,伪代码如下:
获取字符串值
==========
// 当读取到字节对应的内容为0-9时进入该方法
String readString(byte[] info,int offset) {
// 读取‘:’以前的数据,即字符串长度
int length = readLength(info,offset);
// 根据字符串长度,获取实际字符串内容
string data = readData(info,length,offset);
// 返回读取到的字符串内容,整个读取过程中读过的偏移量要累加到offset
return data;
}
获取整数类型
==========
这里有一个注意项,考虑到数据边界问题,例如java等语言,推荐使用Long类型,以防数据越界。
// 当读取到的字节对应的内容为i时,进入该方法
Long readInt(byte[] info,int offset) {
// 读取第一个’e’之前的数据,包括’e’
string data = readInt(info,offset)
return Long.valueOf(data);
}
获取列表类型
==========
因为列表类型中可以夹杂所有四种类型中任意要给即需要用到上面两个方法。
// 当读取到的字节对应的内容为l时,进入该方法
List readList(byte[] info,int offset){
List list = new List();
// 读取到第一个’e’为止
while(info[offset] != ‘e’){
swtich(info[offset]){
// 如果是列表,读取列表并向列表添加
case ‘l’:
list.add(readList(info,offset));
break;
// 如果是字典,读取字典并向列表添加
case ‘d’:
list.add(readDictionary(info,offset));
break;
// 如果是整形数据,读取数据并向列表添加
case ‘i’:
list.add(readInt(info,offset));
break;
// 如果是字符串,读取字符串数据并向列表添加
case ‘0-9’:
list.add(readString(info,offset));
}
}
// offset向前移一位,把列表的结束符’e’移动为已读
offset++;
return list;
}
读取字典类型
==========
读取字典类型与列表十分相似,唯一不同的就是需要区分键值,字典的键值可能为字符串,故依此来判断。
// 当读取到的字节对应的内容为d时,进入该方法
Dictionary readDictionary(byte[] info,int offset){
Dictionary dic = new Dictionary();
// key为null时,字符串为键,否则为值
String key = null;
// 读取到第一个’e’为止
while(info[offset] != ‘e’){
swtich(info[offset]){
// 如果是列表,读取列表并向字典添加,添加列表时肯定存在键,直接添加并将键置空
case ‘l’:
dic.put(key,readList(info,offset));
key = null;
break;
// 如果是字典,读取字典并向字典添加,添加字典时肯定存在键,直接添加并将键置空
case ‘d’:
dic.put(key,readDictionary(info,offset));
key = null;
break;
// 如果是整形数据,读取数据并向字典添加,添加整形数据时肯定存在键,直接添加并将键置空
case ‘i’:
dic.put(key,readInt(info,offset));
key = null;
break;
// 如果是字符串
case ‘0-9’:
string data = readString(info,offset);
// key为null时,字符串为键,否则为值
if(key == null){
key = data;
}else{
dic.put(key,data);
key = null;
}
}
}
// offset向前移一位,把列表的结束符’e’移动为已读
offset++;
return dic;
}
回到顶部
Torrent文件与Magnet
====================
磁力链接与Torrent文件是可以相互转换的,此文只讨论根据Torrent文件如何转换为Magnet磁力链接。
Magnet概述
============
磁力链接由一组参数组成,参数间的顺序没有讲究,其格式与在HTTP链接末尾的查询字符串相同。最常见的参数是"xt",是"exact topic"的缩写,通常是一个特定文件的内容散列函数值形成的URN,例如:
magnet:?xt=urn:bith:YNCKHTQCWBTRNJIV4WNAE52SJUQCZO5C
注意,虽然这个链接指向一个特定文件,但是客户端应用程序仍然必须进行搜索来确定哪里,如果有,能够获取那个文件(即通过DHT进行搜索,这样就实现了Magnet到Torrent的转换,本文不讨论)。
部分字段名见下方表格:
字段名含义magnet协议名xtexact topic的缩写,包含文件哈希值的统一资源名称。BTIH(BitTorrent Info Hash)表示哈希方法名,这里还可以使用ED2K,AICH,SHA1和MD5等。这个值是文件的标识符,是不可缺少的。dndisplay name的缩写,表示向用户显示的文件名。这一项是选填的。trtracker的缩写,表示tracker服务器的地址。这一项也是选填的。bithBitTorrent info hash,种子散列函数
Torrent转换为Magnet
====================
- dn : 向用户显示的文件名
即为Torrent文件中,Info字典下的name键所对应的值
- tr : tracker服务器地址
即为Torrent文件中,announce以及announce-list两个键所对应的值
- bitch : 种子散列值
即为Torrent文件中,info对应的字典的SHA1哈希值(Hex)
根据下图,为4:infod,以d的地址作为哈希原文的起始索引,则为Adress:00 01A3
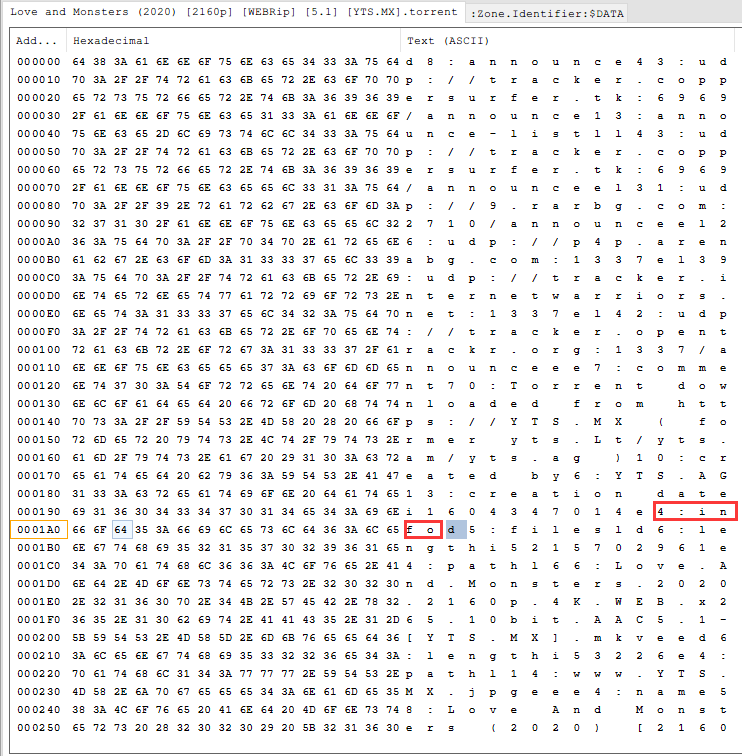
到整个info结束,以e的地址作为哈希原文的终止索引地址,则为Adress:03 0BE7

根据上述可知:
magnet = ‘magnet:?xt=urn:btih:’+Hex(Sha1(info))+‘&dn=’+encode(name)+‘&tr=’+encode(announce)
结合上一部分的实现,我们可以在读取info时记录startindex和endindex,即:
Dictionary readDictionary(byte[] info,int offset){
//…
case ‘d’:
bool record = key == ‘info’;
if(record){
startindex = offset;
}
readDictoinary(info,offset);
if(record){
endindex = offset
}
}
string getBith(byte[] info,int start,int end){
// 获取info中从start到end的字节数组,并对其进行摘要计算
byte[] infoByte = new byte[infoEnd - infoStart + 1];
System.arraycopy(torrentBytes, infoStart, infoByte, 0, infoEnd - infoStart + 1);
return Hex.toHex(Sha1.toSha1(infoByte));
}
回到顶部
具体实现
========
本人通过Java实现了以上部分逻辑(Torrent文件解析以及Magnet链接生成),若有需要参考的读者可以到以下网址获取相关内容:
工具类目录:
https://github.com/Rekent/common-utils/tree/master/src/main/java/com/rekent/tools/utils/torrent
解析类源码:
https://github.com/Rekent/common-utils/blob/master/src/main/java/com/rekent/tools/utils/torrent/TorrentFileResovler.java
依赖jar包:
https://github.com/Rekent/common-utils/releases/tag/v0.0.3
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

总结
总体来说,如果你想转行从事程序员的工作,Java开发一定可以作为你的第一选择。但是不管你选择什么编程语言,提升自己的硬件实力才是拿高薪的唯一手段。
如果你以这份学习路线来学习,你会有一个比较系统化的知识网络,也不至于把知识学习得很零散。我个人是完全不建议刚开始就看《Java编程思想》、《Java核心技术》这些书籍,看完你肯定会放弃学习。建议可以看一些视频来学习,当自己能上手再买这些书看又是非常有收获的事了。

《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
、实战项目、讲解视频,并且会持续更新!**
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)
总结
总体来说,如果你想转行从事程序员的工作,Java开发一定可以作为你的第一选择。但是不管你选择什么编程语言,提升自己的硬件实力才是拿高薪的唯一手段。
如果你以这份学习路线来学习,你会有一个比较系统化的知识网络,也不至于把知识学习得很零散。我个人是完全不建议刚开始就看《Java编程思想》、《Java核心技术》这些书籍,看完你肯定会放弃学习。建议可以看一些视频来学习,当自己能上手再买这些书看又是非常有收获的事了。
[外链图片转存中…(img-XiPSrPdD-1713374787092)]
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!














 7982
7982











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









