







C语言中涉及到修改字符串的时候会重新分配内存。修改地越频繁,内存分配也就越频繁。而内存分配是会消耗性能的,那么性能下降在所难免。
而 Redis 中会涉及到字符串频繁的修改操作,这种内存分配方式显然就不适合了。于是 SDS 实现了两种优化策略:
- 空间预分配
对 SDS 修改及空间扩充时,除了分配所必须的空间外,还会额外分配未使用的空间。
具体分配规则是这样的:SDS 修改后,len 长度小于 1M,那么将会额外分配与 len 相同长度的未使用空间。如果修改后长度大于 1M,那么将分配1M的使用空间。
- 惰性空间释放
当然,有空间分配对应的就有空间释放。
SDS 缩短时,并不会回收多余的内存空间,而是使用 free 字段将多出来的空间记录下来。如果后续有变更操作,直接使用 free 中记录的空间,减少了内存的分配。
(3)二进制安全
你已经知道了 Redis 可以存储各种数据类型,那么二进制数据肯定也不例外。但二进制数据并不是规则的字符串格式,可能会包含一些特殊的字符,比如 ‘\0’ 等。
前面我们提到过,C 中字符串遇到 ‘\0’ 会结束,那 ‘\0’ 之后的数据就读取不上了。但在 SDS 中,是根据 len 长度来判断字符串结束的。
看,二进制安全的问题就解决了。
2、双端链表
列表 List 更多是被当作队列或栈来使用的。队列和栈的特性一个先进先出,一个先进后出。双端链表很好的支持了这些特性。
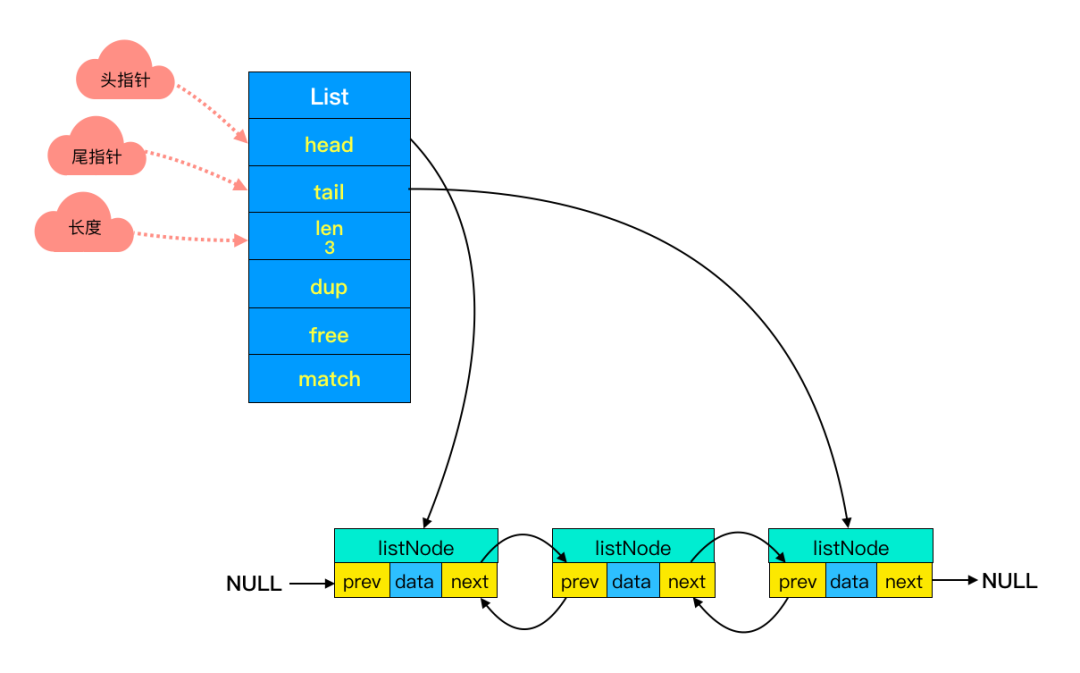
图注:- 双端链表 -
(1)前后节点

链表里每个节点都带有两个指针,prev 指向前节点,next 指向后节点。这样在时间复杂度为 O(1) 内就能获取到前后节点。
(2)头尾节点
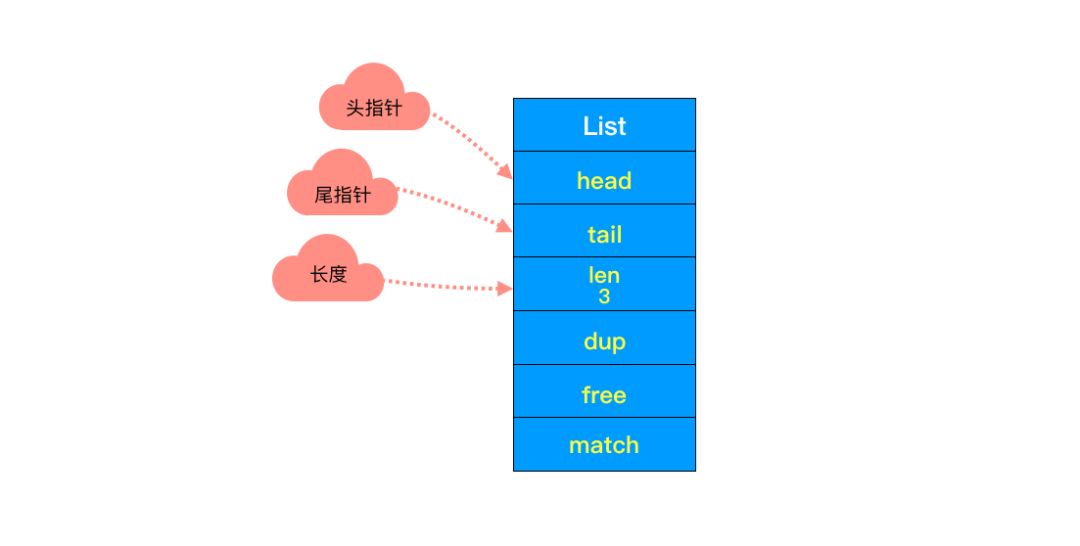
你可能注意到了,头节点里有 head 和 tail 两个参数,分别指向头节点和尾节点。这样的设计能够对双端节点的处理时间复杂度降至 O(1) ,对于队列和栈来说再适合不过。同时链表迭代时从两端都可以进行。
(3)链表长度
头节点里同时还有一个参数 len,和上边提到的 SDS 里类似,这里是用来记录链表长度的。因此获取链表长度时不用再遍历整个链表,直接拿到 len 值就可以了,这个时间复杂度是 O(1)。
你看,这些特性都降低了 List 使用时的时间开销。
3、压缩列表
双端链表我们已经熟悉了。不知道你有没有注意到一个问题:如果在一个链表节点中存储一个小数据,比如一个字节。那么对应的就要保存头节点,前后指针等额外的数据。
这样就浪费了空间,同时由于反复申请与释放也容易导致内存碎片化。这样内存的使用效率就太低了。
于是,压缩列表上场了!
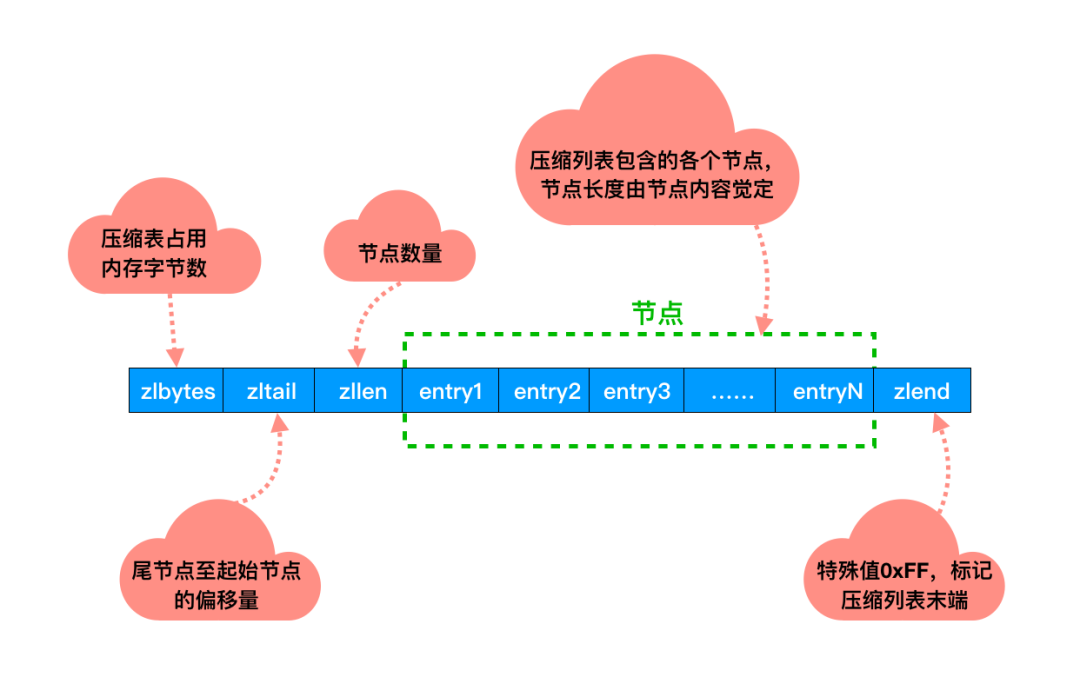
它是经过特殊编码,专门为了提升内存使用效率设计的。所有的操作都是通过指针与解码出来的偏移量进行的。
并且压缩列表的内存是连续分配的,遍历的速度很快。
4、字典
Redis 作为 K-V 型数据库,所有的键值都是用字典来存储的。
日常学习中使用的字典你应该不会陌生,想查找某个词通过某个字就可以直接定位到,速度非常快。这里所说的字典原理上是一样的,通过某个 key 可以直接获取到对应的value。
字典又称为哈希表,这点没什么可说的。哈希表的特性大家都很清楚,能够在 O(1) 时间复杂度内取出和插入关联的值。
5、跳跃表
作为 Redis 中特有的数据结构-跳跃表,其在链表的基础上增加了多级索引来提升查找效率。

这是跳跃表的简单原理图,每一层都有一条有序的链表,最底层的链表包含了所有的元素。这样跳跃表就可以支持在 O(logN) 的时间复杂度里查找到对应的节点。
下面这张是跳表真实的存储结构,和其它数据结构一样,都在头节点里记录了相应的信息,减少了一些不必要的系统开销。

合理的数据编码
===========
对于每一种数据类型来说,底层的支持可能是多种数据结构,什么时候使用哪种数据结构,这就涉及到了编码转化的问题。
那我们就来看看,不同的数据类型是如何进行编码转化的:
-
String:存储数字的话,采用int类型的编码,如果是非数字的话,采用 raw 编码;
-
List:字符串长度及元素个数小于一定范围使用 ziplist 编码,任意条件不满足,则转化为 linkedlist 编码;
-
Hash:hash 对象保存的键值对内的键和值字符串长度小于一定值及键值对;
-
Set:保存元素为整数及元素个数小于一定范围使用 intset 编码,任意条件不满足,则使用 hashtable 编码;
-
Zset:zset 对象中保存的元素个数小于及成员长度小于一定值使用 ziplist 编码,任意条件不满足,则使用 skiplist 编码。
合适的线程模型
============
Redis 快的原因还有一个是因为使用了合适的线程模型:
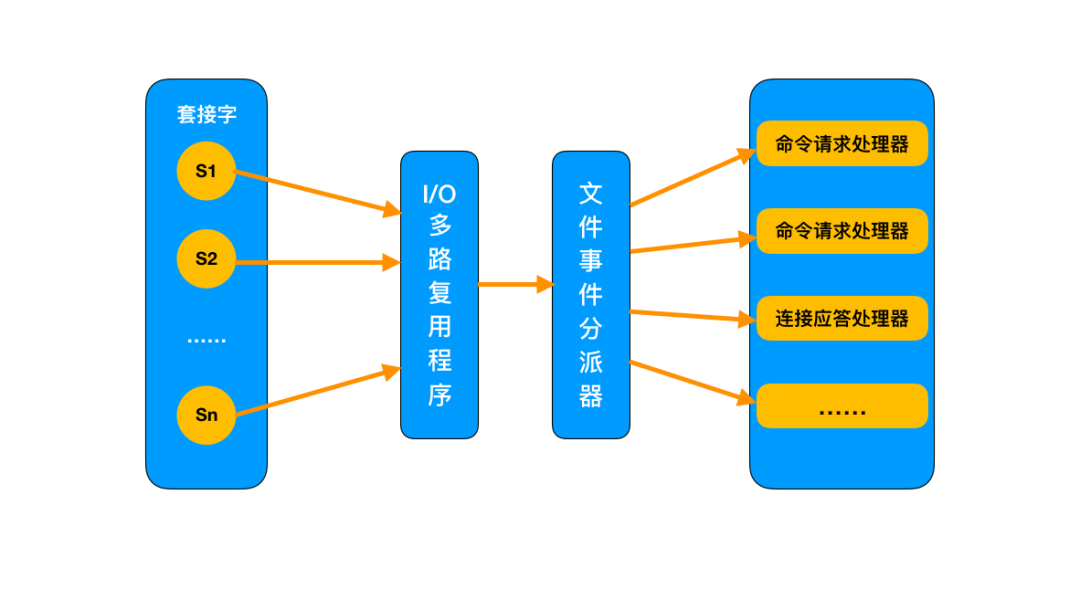
1、I/O多路复用模型
-
I/O :网络 I/O
-
多路:多个 TCP 连接
-
复用:共用一个线程或进程
生产环境中的使用,通常是多个客户端连接 Redis,然后各自发送命令至 Redis 服务器,最后服务端处理这些请求返回结果。
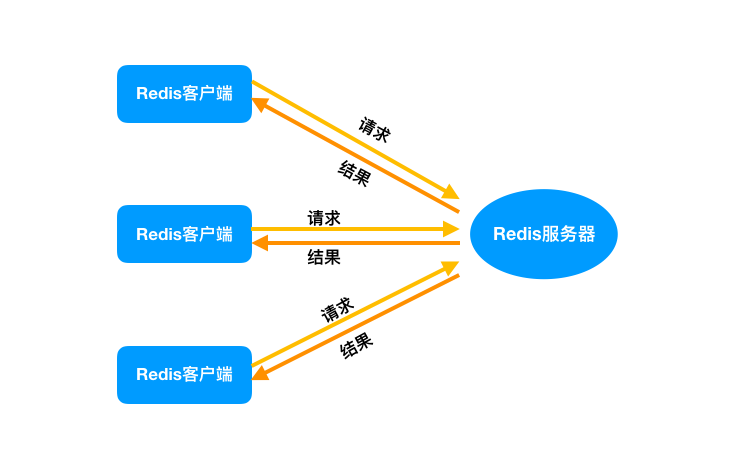
应对大量的请求,Redis 中使用 I/O 多路复用程序同时监听多个套接字,并将这些事件推送到一个队列里,然后逐个被执行。最终将结果返回给客户端。
2、避免上下文切换
你一定听说过,Redis 是单线程的。那么单线程的 Redis 为什么会快呢?
因为多线程在执行过程中需要进行 CPU 的上下文切换,这个操作比较耗时。Redis 又是基于内存实现的,对于内存来说,没有上下文切换效率就是最高的。多次读写都在一个CPU 上,对于内存来说就是最佳方案。
3、单线程模型
顺便提一下,为什么 Redis 是单线程的。
Redis 中使用了 Reactor 单线程模型,你可能对它并不熟悉。没关系,只需要大概了解一下即可。

这张图里,接收到用户的请求后,全部推送到一个队列里,然后交给文件事件分派器,而它是单线程的工作方式。Redis 又是基于它工作的,所以说 Redis 是单线程的。
总结
=======
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数Java工程师,想要提升技能,往往是自己摸索成长或者是报班学习,但对于培训机构动则几千的学费,着实压力不小。自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
如果你觉得这些内容对你有帮助,可以扫码获取!!(备注Java获取)

最后
这份文档从构建一个键值数据库的关键架构入手,不仅带你建立起全局观,还帮你迅速抓住核心主线。除此之外,还会具体讲解数据结构、线程模型、网络框架、持久化、主从同步和切片集群等,帮你搞懂底层原理。相信这对于所有层次的Redis使用者都是一份非常完美的教程了。

整理不易,觉得有帮助的朋友可以帮忙点赞分享支持一下小编~
你的支持,我的动力;祝各位前程似锦,offer不断!!!
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!
核心主线。除此之外,还会具体讲解数据结构、线程模型、网络框架、持久化、主从同步和切片集群等,帮你搞懂底层原理。相信这对于所有层次的Redis使用者都是一份非常完美的教程了。
[外链图片转存中…(img-eGLLWAei-1713755054886)]
整理不易,觉得有帮助的朋友可以帮忙点赞分享支持一下小编~
你的支持,我的动力;祝各位前程似锦,offer不断!!!
《互联网大厂面试真题解析、进阶开发核心学习笔记、全套讲解视频、实战项目源码讲义》点击传送门即可获取!















 758
758











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









