







| — | — | — | — |
| UUID | UUID是通用唯一标识码的缩写,其目的是上分布式系统中的所有元素都有唯一的辨识信息,而不需要通过中央控制器来指定唯一标识。 | 1. 降低全局节点的压力,使得主键生成速度更快;2. 生成的主键全局唯一;3. 跨服务器合并数据方便 | 1. UUID占用16个字符,空间占用较多;2. 不是递增有序的数字,数据写入IO随机性很大,且索引效率下降 |
| 数据库主键自增 | MySQL数据库设置主键且主键自动增长 | 1. INT和BIGINT类型占用空间较小;2. 主键自动增长,IO写入连续性好;3. 数字类型查询速度优于字符串 | 1. 并发性能不高,受限于数据库性能;2. 分库分表,需要改造,复杂;3. 自增:数据量泄露 |
| Redis自增 | Redis计数器,原子性自增 | 使用内存,并发性能好 | 1. 数据丢失;2. 自增:数据量泄露 |
| 雪花算法(snowflake) | 大名鼎鼎的雪花算法,分布式ID的经典解决方案 | 1. 不依赖外部组件;2. 性能好 | 时钟回拨 |
目前流行的分布式ID解决方案有两种:「号段模式」和「雪花算法」。
**「号段模式」**依赖于数据库,但是区别于数据库主键自增的模式。假设100为一个号段100,200,300,每取一次可以获得100个ID,性能显著提高。
**「雪花算法」**是由符号位+时间戳+工作机器id+序列号组成的,如图所示: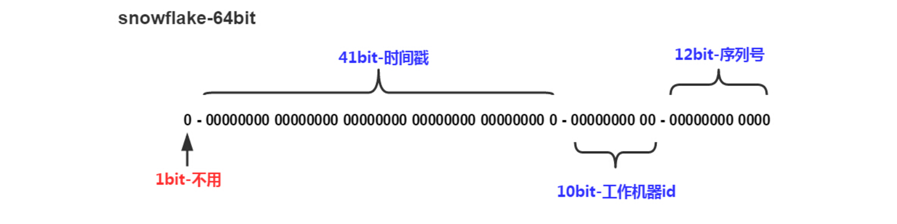
符号位为0,0表示正数,ID为正数。
时间戳位不用多说,用来存放时间戳,单位是ms。
工作机器id位用来存放机器的id,通常分为5个区域位+5个服务器标识位。
序号位是自增。
- 雪花算法能存放多少数据?时间范围:2^41 / (3652460601000) = 69年 工作进程范围:2^10 = 1024 序列号范围:2^12 = 4096,表示1ms可以生成4096个ID。
根据这个算法的逻辑,只需要将这个算法用Java语言实现出来,封装为一个工具方法,那么各个业务应用可以直接使用该工具方法来获取分布式ID,只需保证每个业务应用有自己的工作机器id即可,而不需要单独去搭建一个获取分布式ID的应用。下面是推特版的Snowflake算法:
public class SnowFlake {
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 110
110

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









