







Spark 内存管理
相比其他大数据计算引擎,关于 Spark 的特性与优势,想必你听到最多的字眼,就是“内存计算”。合理而又充分地利用内存资源,是 Spark 的核心竞争力之一。因此,作为开发者,我们弄清楚 Spark 是如何使用内存的,就变得非常重要。
Spark 内存区域划分
对于任意一个 Executor 来说,Spark 会把内存分为 4 个区域,分别是 Reserved Memory、User Memory、Execution Memory 和 Storage Memory。
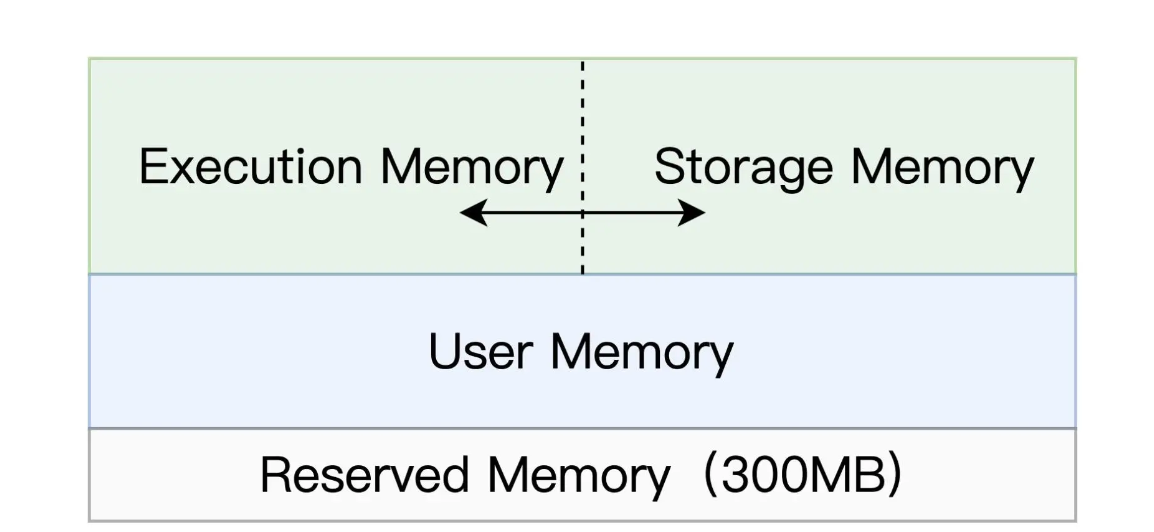
- Reserved Memory 固定为 300MB,不受开发者控制,它是 Spark 预留的、用来存储各种 Spark 内部对象的内存区域
- User Memory 用于存储开发者自定义的数据结构,例如 RDD 算子中引用的数组、列表、映射等等。
- Execution Memory 用来执行分布式任务。分布式任务的计算,主要包括数据的转换、过滤、映射、排序、聚合、归并等环节,而这些计算环节的内存消耗,统统来自于 Execution Memory。
- Storage Memory 用于缓存分布式数据集,比如 RDD Cache、广播变量等等。
不难发现,Execution Memory 和 Storage Memory 这两块内存区域,对于 Spark 作业的执行性能起着举足轻重的作用。因此,在所有的内存区域中,Execution Memory 和 Storage Memory 是最重要的,也是开发者最需要关注的。
在 Spark 1.6 版本之前,Execution Memory 和 Storage Memory 的空间划分是静态的,一旦空间划分完毕,不同内存区域的用途与尺寸就固定了。也就是说,即便你没有缓存任何 RDD 或是广播变量,Storage Memory 区域的空闲内存也不能用来执行映射、排序或聚合等计算任务,宝贵的内存资源就这么白白地浪费掉了。
考虑到静态内存划分的弊端,在 1.6 版本之后,Spark 推出了统一内存管理模式,在这种模式下,Execution Memory 和 Storage M
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1725
1725

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









