







本文收录在 前端基础进阶[1] 专栏,欢迎关注和收藏, 往期经典:
-
【干货】私藏的这些高级工具函数,你拥有几个? 500+ star
-
三千文字,也没写好 Function.prototype.call 200+ star
-
那些你熟悉而又陌生的函数 200+ star
-
这16种原生函数和属性的区别,你真的知道吗?精心收集,高级前端必备知识,快快打包带走100+ star
收藏不star就是耍流氓!哈
大纲
–
方便移动端阅读:
-
Base64在前端的应用
-
Base64数据编码起源
-
Base64编码64的含义
-
Base64编码优缺点
-
一些计算机和前端基础知识
-
ASCII码, Unicode , UTF-8
-
Base64编码和解码
-
其他的成熟方案
-
写在最后
Base64在前端的应用
Base64编码,你一定知道的,先来看看她在前端的一些常见应用:
当然绝部分场景都是基于Data URLs
Canvas图片生成
canvas的 toDataURL可以把canvas的画布内容转base64编码格式包含图片展示的 data URI。
const ctx = canvasEl.getContext(“2d”);
// … other code
const dataUrl = canvasEl.toDataURL();
// data:image/png;base64,iVBORw0KGgoAAAANSUhE…
你画我猜,新用户加入,要获取当前的最新的绘画界面,也可以通过Base64格式的消息传递。
文件读取
FileReader的 readAsDataURL[9]可以把上传的文件转为base64格式的data URI,比较常见的场景是用户头像的剪裁和上传。
function readAsDataURL() {
const fileEl = document.getElementById(“inputFile”);
return new Promise((resolve, reject) => {
const fd = new FileReader();
fd.readAsDataURL(fileEl.files[0]);
fd.onload = function () {
resolve(fd.result);
// data:image/png;base64,iVBORw0KGgoAAAA…
}
fd.onerror = reject;
});
}
jwt
jwt由header, payload,signature三部分组成,前两个解码后,都是可以明文看见的。拿 国服最强JWT生成Token做登录校验讲解,看完保证你学会![10] 里面的token做测试。
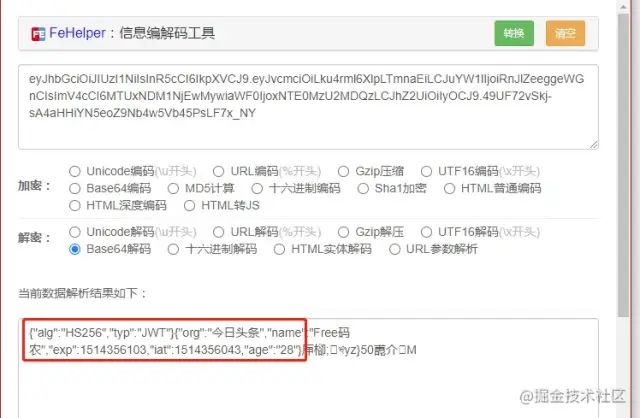
image.png
网站图片和小图片
移动端网站图标优化
复制代码
至于怎么获得这个值data:,的:
复制代码
小图片
这个就有很多场景了,比如img标签,背景图等
img标签:

css背景图:
.bg{
background: url(data:image/png;base64,iVBORw0KGgoAAAA…)
}
简单的数据加密
当然这不是好方法,但是至少让你不好解读。
const username = document.getElementById(“username”).vlaue;
const password = document.getElementById(“password”).vlaue;
const secureKey = “%%S%$%DS)_sdsdj_66”;
const sPass = utf8_to_base64(password + secureKey);
doLogin({
username,
password: sPass
})
SourceMap
借用阮大神的一段代码, 注意mappings字段,这实际上就是bas64编码格式的内容,当然你直接去解,是会失败的。
{
version : 3,
file: “out.js”,
sourceRoot : “”,
sources: [“foo.js”, “bar.js”],
names: [“src”, “maps”, “are”, “fun”],
mappings: “AAgBC,SAAQ,CAAEA”
}
具体的实现请看官方的base64-vlq.js[11]文件。
混淆加密代码
著名的代码混淆库, javascript-obfuscator[12],其也是有应用base64几码的,一起看看选项:
webpack-obfuscator[13]也是基于其封装的。
–string-array-indexes-type ‘’ (comma separated) [hexadecimal-number, hexadecimal-numeric-string]
–string-array-encoding ‘’ (comma separated) [none, base64, rc4]
–string-array-index-shift
–string-array-wrappers-count
–string-array-wrappers-chained-calls

image.png
其他
X.509公钥证书, github SSH key, mht文件,邮件附件等等,都有Base64的影子。
Base64数据编码起源
早期邮件传输协议基于 ASCII 文本,对于诸如图片、视频等二进制文件处理并不好。ASCII 主要用于显示现代英文,到目前为止只定义了 128 个字符,包含控制字符和可显示字符。为了解决上述问题,Base64 编码顺势而生。
Base64是编解码,主要的作用不在于安全性,而在于让内容能在各个网关间无错的传输,这才是Base64编码的核心作用。
除了Base64数据编码,其实还有Base32数据编码, Base16数据编码,可以参见 RFC 4648[14]。
Base64编码64的含义
64就是64个字符的意思。
base64对照表, 借用 Base64原理[15]的一张图:

-
A-Z26 -
a-z26 -
0-910 -
+ /2
26 + 26 + 10 + 2 = 64
当然还有一个字符=,这是填充字符,后面会提到,不属于64里面的范畴。
对照表的索引值,注意一下,后面的base64编码和解码会用到。
Base64编码优缺点
优点
-
可以将二进制数据(比如图片)转化为可打印字符,方便传输数据
-
对数据进行简单的加密,肉眼是安全的
-
如果是在html或者css处理图片,可以减少http请求
缺点
- 内容编码后体积变大, 至少1/3
因为是三字节变成四个字节,当只有一个字节的时候,也至少会变成三个字节。
- 编码和解码需要额外工作量
说完优缺点,回到正题:
我们今天的重点是 uf8编码转Base64编码:
基本流程
char => 码点 => utf-8编码 => base64编码
在之前要解一下编码的知识, 了解编码知识,又要先了解一些计算机的基础知识。
一些计算机和前端基础知识
比特和字节
比特又叫位。在计算机的世界里,信息的表示方式只有 0 和 1, 其可以表示两种状态。
一位二进制可以表示两状态, N位可以表示2^N种状态。
一个字节(Byte)有8位(Bit)
所以一个字节可以表示 2^8 = 256种状态;
获得字符的 Unicode码点
String.prototype.charCodeAt[16] 可以获取字符的码点,获取范围为0 ~ 65535。这个地方注意一下,关系到后面的utf-8字节数。
“a”.charCodeAt(0) // 97
“中”.charCodeAt(0) // 20013
进制表示
0b开头,可以表示二进制
注意0b10000000= 128 ,0b11000000=92,之后会用到.
0b11111111 // 255
0b10000000 // 128 后面会用到
0b11000000 // 192 后面会用到
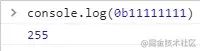
image.png
0x开头,可以表示16进制
0x11111111 // 286331153

image.png
0o开头可以表示8进制,就不多说了,本来不会涉及。
进制转换
10进制转其他进制
Number.prototype.toString\(radix\)[17]可以把十进制转为其他进制。
100…toString(2) // 1100100
100…toString(16) // 64, 也等于 ox64
其他进制转为10进制
parseInt\(string, radix\)[18]可以把其他进制,转为10进制。
parseInt(“10000000”, 2) // 128
parseInt(“10”,16) // 16
这里额外提一下一元操作符号+可以把字符串转为数字,后面也会用到,之前提到的0b,0o,0x这里都会生效。
+“1000” // 1000
+“0b10000000” // 128
+“0o10” // 8
+“0x10” // 16
位移操作
本文只涉及右移操作,就只讲右移,右移相当于除以2,如果是整数,简单说是去低位,移动几位去掉几位,其实和10进制除以10是一样的。
64 >> 2 = 16 我们一起看一下过程
0 1 0 0 0 0 0 0 64
0 1 0 0 0 0 | 0 0 16
一元 & 操作和 一元|操作
一元&
当两者皆为1的时候,值为1。本文的作用可用来去高位, 具体看代码。
3553 & 36 = 0b110111100001 & 0b111111 = 100001
因为高位缺失,不可能都为1,故均为0, 而低位相当于复制一遍而已。
110111 100001
111111
000000 100001
一元|
当任意一个为1,就输出为1. 本文用来填补0。比如,把3补成8位二进制
3 | 256 = 11 | 100000000 = 100000011
100000011.substring(1)是不是就等于8位二进制呢00000011
具备了这些基本知识,我们就开始先了解编码相关的知识。
ASCII码, Unicode , UTF-8
ASCII码
ASCII码第一位始终是0, 那么实际可以表示的状态是 2^7 = 128种状态。
ASCII 主要用于显示现代英文,到目前为止只定义了 128 个字符,包含控制字符和可显示字符。
-
0~31 之间的ASCII码常用于控制像打印机一样的外围设备
-
32~127 之间的ASCII码表示的符号,在我们的键盘上都可以被找到
完整的 ASCII码对应表,可以参见 基本ASCII码和扩展ASCII码[19]
接下来是Unicode和UTF-8编码,请先记住这个重要的知识:
-
Unicode: 字符集
-
UTF-8: 编码规则
Unicode
Unicode 为世界上所有字符都分配了一个唯一的编号(码点),这个编号范围从 0x000000 到 0x10FFFF (十六进制),有 100 多万,每个字符都有一个唯一的 Unicode 编号,这个编号一般写成 16 进制,在前面加上 U+。例如:掘的 Unicode 是U+6398。
- U+0000到U+FFFF
最前面的65536个字符位,它的码点范围是从0一直到216-1。所有最常见的字符都放在这里。
- U+010000一直到U+10FFFF
剩下的字符都放着这里,码点范围从U+010000一直到U+10FFFF。
Unicode有平面的概念,这里就不拓展了。
Unicode只规定了每个字符的码点,到底用什么样的字节序表示这个码点,就涉及到编码方法。
UTF-8
UTF-8 是互联网使用最多的一种 Unicode 的实现方式。还有 UTF-16(字符用两个字节或四个字节表示)和 UTF-32(字符用四个字节表示)等实现方式。
UTF-8 是它是一种变长的编码方式, 使用的字节个数从 1 到 4 个不等,最新的应该不止4个, 这个1-4不等,是后面编码和解码的关键。
UTF-8的编码规则:
-
对于只有一个字节的符号,字节的第一位设为
0,后面 7 位为这个符号的 Unicode 码。此时,对于英语字母UTF-8 编码和 ASCII 码是相同的。 -
对于
n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 Unicode 码,如下表所示:
| Unicode 码点范围(十六进制) | 十进制范围 | UTF-8 编码方式(二进制) | 字节数 |
| — | — | — | — |
| 0000 0000 ~ 0000 007F | 0 ~ 127 | 0xxxxxxx | 1 |
| 0000 0080 ~ 0000 07FF | 128 ~ 2047 | 110xxxxx 10xxxxxx | 2 |
| 0000 0800 ~ 0000 FFFF | 2048 ~ 65535 | 1110xxxx 10xxxxxx 10xxxxxx | 3 |
| 0001 0000 ~ 0010 FFFF | 65536 ~ 1114111 | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx | 4 |
我们可能没见过字节数为2或者为4的字符, 字节数为2的可以去Unicode对应表[20]这里找,而等于4的可以去这看看Unicode® 13.0 Versioned Charts Index[21]
下面这些码点都处于0000 0080 ~ 0000 07FF, utf-8编码需要2个字节
下面这些码点都处于0001 0000 ~ 0010 FFFF, utf-8编码需要4个字节
可能这里光说不好理解,我们分别以英文字符a和中文字符掘来讲解一下:
为了验证结果,可以去 Convert UTF8 to Binary Bits \- Online UTF8 Tools[22]
英文字符a
先获得其码点,"a".charCodeAt(0) 等于 97
对照表格, 0~127, 需1个字节
97..toString(2) 得到编码 1100001
根据格式0xxxxxxx进行填充, 最终结果
01100001
中文字符掘
先获得其码点,"掘".charCodeAt(0) 等于 25496
对照表格,2048 ~ 65535 需3个字节
25496..toString(2) 得到编码 110 001110 011000
根绝格式1110xxxx 10xxxxxx 10xxxxxx进行填充, 最终结果如下
11100110 10001110 10011000
Convert UTF8 to Binary Bits \- Online UTF8 Tools[23]执行结果:完全匹配

image.png
抽象把字符转为utf8格式二进制的方法
基于上面的表格和转换过程,我们抽象一个方法,这个方法在之后的Base64编码和解码至关重要:
先看看功能,覆盖utf8编码1-3字节范围
console.log(to_binary(“A”)) // 11100001
console.log(to_binary(“س”)) // 1101100010110011
console.log(to_binary(“掘”)) // 111001101000111010011000
方法如下
function to_binary(str) {
const string = str.replace(/\r\n/g, “\n”);
let result = “”;
let code;
for (var n = 0; n < string.length; n++) {
//获取麻点
code = str.charCodeAt(n);
if (code < 0x007F) { // 1个字节
// 0000 0000 ~ 0000 007F 0 ~ 127 1个字节
// (code | 0b100000000).toString(2).slice(1)
result += (code).toString(2).padStart(8, ‘0’);
} else if ((code > 0x0080) && (code < 0x07FF)) {
// 0000 0080 ~ 0000 07FF 128 ~ 2047 2个字节
// 0x0080 的二进制为 10000000 ,8位,所以大于0x0080的,至少有8位
// 格式 110xxxxx 10xxxxxx
// 高位 110xxxxx
result += ((code >> 6) | 0b11000000).toString(2);
// 低位 10xxxxxx
result += ((code & 0b111111) | 0b10000000).toString(2);
} else if (code > 0x0800 && code < 0xFFFF) {
// 0000 0800 ~ 0000 FFFF 2048 ~ 65535 3个字节
最后
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数初中级Android工程师,想要提升技能,往往是自己摸索成长,自己不成体系的自学效果低效漫长且无助。
因此收集整理了一份《2024年Web前端开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Android开发知识点!不论你是刚入门Android开发的新手,还是希望在技术上不断提升的资深开发者,这些资料都将为你打开新的学习之门!
如果你觉得这些内容对你有帮助,需要这份全套学习资料的朋友可以戳我获取!!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
lice(1)
result += (code).toString(2).padStart(8, ‘0’);
} else if ((code > 0x0080) && (code < 0x07FF)) {
// 0000 0080 ~ 0000 07FF 128 ~ 2047 2个字节
// 0x0080 的二进制为 10000000 ,8位,所以大于0x0080的,至少有8位
// 格式 110xxxxx 10xxxxxx
// 高位 110xxxxx
result += ((code >> 6) | 0b11000000).toString(2);
// 低位 10xxxxxx
result += ((code & 0b111111) | 0b10000000).toString(2);
} else if (code > 0x0800 && code < 0xFFFF) {
// 0000 0800 ~ 0000 FFFF 2048 ~ 65535 3个字节
最后
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数初中级Android工程师,想要提升技能,往往是自己摸索成长,自己不成体系的自学效果低效漫长且无助。
因此收集整理了一份《2024年Web前端开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
[外链图片转存中…(img-zAZAsLjW-1715801453484)]
[外链图片转存中…(img-eLk9gV7f-1715801453485)]
[外链图片转存中…(img-dOgPCgcz-1715801453485)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Android开发知识点!不论你是刚入门Android开发的新手,还是希望在技术上不断提升的资深开发者,这些资料都将为你打开新的学习之门!
如果你觉得这些内容对你有帮助,需要这份全套学习资料的朋友可以戳我获取!!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!















 709
709

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









