







《一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码》,点击传送门,即可获取!
| LTRIM(str) | 去掉str左边的空格 |
| RTRIM(str) | 去掉str右边的空格 |
| LPAD(str1,n,str2) | 使用字符串str2对字符串str1最左边进行填充,直到长度为n个字符长度 |
| RPAD(str1,n,str2) | 使用字符串str2对字符串str1最右边进行填充,直到长度为n个字符长度 |
| REPEAT(str,x) | 返回字符串str重复x次的结果 |
| REPLACE(str,a,b) | 使用字符串b替换字符串str中所有出现的字符串a |
| STRCMP(str1,str2) | 比较字符串str1和str2,如果相同会返回0,不同会返回-1。 |
| TRIM(str) | 去掉字符串行头和行尾的空格 |
| SUBSTRING(str,x,y) | 返回字符串str中从x位置起y个字符串长度的字符串 |
| 函数 | 描述 |
| — | — |
| NOW() | 返回当前时间,格式为YYYY-MM-DD HH:MM:SS ,返回值数据类型为DATETIME |
| DATE(DATETIME) | 参数为DATETIME类型的数据或字段,返回值格式为YYYY-MM-DD,返回值数据类型为DATE类型 |
| TIME(DATETIME) | 参数为DATETIME类型的数据或字段,返回值格式为HH:MM:SS,返回值数据类型为TIME类型 |
| YEAR(DATETIME) | 参数为DATETIME类型的数据或字段。返回一个数值,某年。该数值可直接拿去参与计算。 |
| MONTH(DATETIME) | 参数为DATETIME类型的数据或字段。返回一个数值,某月。该数值可直接拿去参与计算。 |
| DAY(DATETIME) | 参数为DATETIME类型的数据或字段。 返回一个数值,某日。该数值可直接拿去参与计算。 |
| ------------------------ | -------------- |
| CURRENT_DATE() | 无参数,返回当前日期,YYYY-MM-DD格式,相当于DATE(NOW()) |
| CURRENT_TIME() | 无参数,返回当前时间,HH:MM:SS格式,相当于TIME(NOW()) |
| CURRENT_TIMESTAMP() | 无参数,相当于now() |
| ------------------------ | ------------- |
| ADDTIME(t1,t2) | 返回两个时间相加的和,参数t1,t2为DATETIME类型的数值或字段,如果结果大于24小时,则会不会跳转到下一天,会存在25:00:00的结果。 |
| DATE_ADD(t1,T) | 返回DATETIME类型的数值或字段滞后一定时间后的结果,结果为DATETIME类型,T的格式见下方示例 |
| DATE_SUB(t1,T) | 返回DATETIME类型的数值或字段超前一定时间后的结果,结果为DATETIME类型,用法同上 |
| DATEDIFF(t1,t2) | 返回t1比t2滞后的天数(t1-t2),参数可以是YYYY-MM-DD HH:MM:SS,也可以是YYYY-MM-DD,也可以是介于其之间的格式(必须有DD。) |
DATE_ADD(t1,T)与DATE_SUB(t1,T)示例
SELECT DATE_ADD(now(),interval 1 DAY);
SELECT DATE_ADD(now(),interval 1 MONTH);
SELECT DATE_ADD(now(),interval 1 YEAR);
SELECT DATE_ADD(now(),interval 1 hour);
SELECT DATE_ADD(now(),interval 1 minute);
SELECT DATE_ADD(now(),interval 1 second);
SELECT DATE_SUB(now(),interval 1 DAY);
SELECT DATE_SUB(now(),interval 1 MONTH);
SELECT DATE_SUB(now(),interval 1 YEAR);
SELECT DATE_SUB(now(),interval 1 hour);
SELECT DATE_SUB(now(),interval 1 minute);
SELECT DATE_SUB(now(),interval 1 second);
SELECT DATEDIFF(‘2022-02-07’,‘2021-12-01’);
SELECT DATEDIFF(‘2022-02-07 12:00’,‘2021-12-01 12:00’);
SELECT DATEDIFF(DATE_ADD(now(),interval 1 day),now())
| 函数 | 描述 |
| — | — |
| IF(expr,μ1,μ2) | 条件判断函数,如果expr成立则执行μ1,否则执行μ2 |
| IFNULL(μ1,μ2) | 如果μ1不为空则返回μ1,否则返回μ2 |
| VERSION() | 获取MySQL版本号 |
示例
select if(score>85,‘优秀’,‘普通’) from table1;
============================================================================
sql语句中的注释写法:两个“-”符号加一个空格。
– xxxxxxxxxxxxxxx
🍷꧔ꦿ查看所有数据库
show databases;
🍷꧔ꦿ创建一个数据库
create database database_name;
🍷꧔ꦿ创建一个数据库并先判断是否存在:
如果用一个已经存在的数据库的名字来创建,则会报错。
可以用以下命令解决,如果存在则不再创建,如果不存在则去创建。
create database if not exists database_name;
🍷꧔ꦿ创建名字含特殊字符的数据库
如果数据库的名称含有除数字、字母、下划线之外的特殊字符,应在名称两边用``标注。
`符号在tab键上方,不是引号。
以短横线-为例:
create database database1-name;
🍷꧔ꦿ删除数据库
drop database database1-name
🍷꧔ꦿ选择某个数据库
选择某个数据库后,以便后边执行关于该数据库中数据表的命令时不用再声明数据库。
use database_name;
🍷꧔ꦿ查看当前使用的数据库
select database()
执行完选择数据库命令后:
🍷꧔ꦿ查看所有表格
show tables;
🍷꧔ꦿ创建一个数据表
创建一个数据表时,至少需要指定一个字段及其数据类型。
(这里指定字段id为例,类型为int):
create table table_name(id int);
数据表中的括号中,填写字段属性。规则为先写字段名,然后空一格写字段值的数据类型 ,接着写以下一系列属性:
| 属性 | 简写 | 描述 |
| — | — | — |
| primary key | PK | 主键 |
| not null | NN | 非空 |
| unique | UQ | 唯一索引 |
| binary | BIN | 二进制数据 |
| unsigned | UN | 无符号(非负数) |
| zero fill | ZF | 填充0(即2在int(5)中显示为00002) |
| auto increment | AI | 自增 |
| Generated Column | G | |
| Default/Experession | 无 | 默认值 |
不同字段之间,用英文逗号隔开。
以创建一个名为“students”的表格为例
其中 字段id为int类型,且非空,主键,自增;
字段name为varchar类型,长度上限为30个字节;
字段age为tinyint类型,且非负,默认为18;
字段high为decimal类型,总长度为5位,保留二位小数;
字段gender为枚举类型,可以选择的值有’男’,‘女’,‘保密’。且默认为保密。
字段cls_id为int类型。
sql代码如下:
create table students(
id int not null primary key auto_increment,
name varchar(30),
age tinyint unsigned default 18,
high decimal(5,2),
gender enum(‘男’,‘女’,‘保密’) default ‘保密’,
cls_id int
);
非空、自增这些属性之间,不要求顺序。代码中不可以使用其简写形式。
在MySQL WorkBench中操作时,如果是手动创建,则也可以去勾选以上表格中的简写。
🍷꧔ꦿ查看表结构
desc students;
或
describe students;
会显示表中每个字段的属性。
🍷꧔ꦿ添加表字段
- alter table 数据表名 add 字段名 字段类型
以在students表格中添加一个名为birthday的字段为例,字段类型为DATE类型:
alter table students add birthday DATE;
🍷꧔ꦿ修改表字段
①只修改字段的数据类型及约束,不能修改字段名:
- alter table 表格名 modify 字段名 字段类型 约束
以把birthday字段的默认值修改为’1900-01-01’为例:
alter table students modify birthday DATE default ‘1900-01-01’;
②修改字段名及其他
- alter table 表格名 change 旧字段名 新字段名 字段类型 约束
以把字段birthday修改我bdy为例,同时修改默认值为’1912-01-01’为例:
alter table students change birthday bdy DATE default ‘1912-01-01’;
🍷꧔ꦿ删除字段
- alter table 数据表名 drop 字段名;
以删除字段high为例。
alter table students drop high;
🍷꧔ꦿ添加一条数据
当前的students表格,经过上述操作,所剩字段依次为:
| id | name | age | gender | cls_id | bdy |
| — | — | — | — | — | — |
添加一条数据时,必须依次写入,即使有默认值代码中也不能缺少。必须一一对应。
insert into students values(1,‘张三’,20,‘男’,5,‘2002-01-01’);
🍷꧔ꦿ添加多条数据
即在添加一条数据的基础上:
- insert into students values(),(),()
每行数据的括号之间用逗号隔开。
🍷꧔ꦿ添加指定字段数据
以只添加name和cls_id两个字段为例:
insert into students (name,cls_id) values (‘朱元璋’,3);
添加指定字段时必须用括号括着字段名。
添加多行指定字段的数据时同样使用逗号隔开括号:,
insert into students (name,cls_id) values (‘xx’,3),(‘xx’,4);
🍷꧔ꦿ通过下标添加枚举类型数据
添加枚举类型数据时可以直接添加,也可以通过下标添加
以添加字段gender为例,该字段为枚举类型,值依次有“男,女,保密”:
insert into students (name,gender) values (‘judy’,1);
下标从1开始计数。
🍷꧔ꦿ修改数据
以将cls_id全部改为8为例:
update students set cls_id=8;
将name为张三的cls_id改为9:
update students set cls_id =8 where name=‘张三’;
修改数据执行此两行命令时,可能会遇到报错:
- Error Code: 1175. You are using safe update mode and you tried to update a table without a WHERE that uses a KEY column. To disable safe mode, toggle the option in Preferences -> SQL Editor and reconnect.
就是说mysql在safe-updates模式中,如果没有where或者where后边跟的不是主键,就不允许这样修改数据,这样太不安全。
可以使用以下语句退出安全修改模式:
SET SQL_SAFE_UPDATES = 0;
也可以将where约束条件换为:where name=‘张三’ and id>=1即可解决。
如果要修改多个字段,以将name为张三的cls_id修改为1,gender修改为’女’为例:
update students set cls_id =1,gender=‘女’ where name=‘张三’;
🍷꧔ꦿ删除数据
不加where约束条件,则删除全部数据。不建议轻易尝试。
delete from students;
删除name为张三的数据。
delete from students where name=‘张三’;
🍷꧔ꦿ逻辑删除
上边的删除数据为物理删除,可能会造成数据紊乱,影响与其他表格的数据关联。
一般更好用的是逻辑删除,不是物理删除。
即新添加一个字段,把想要删除的字段值标记为0,把保留的字段值标记为1.
以添加一个is_del字段为例,默认为1:
alter table students add is_del INT DEFAULT 1;
将name为’朱元璋’的is_del标记为0。
update students set is_del=0 where name=‘朱元璋’;
🍷꧔ꦿ查询表所有数据
* 表示所有,from后边加表明。
select * from students;
🍷꧔ꦿ查询指定字段
字段之间用 英文逗号 隔开。
select name,age from students;
🍷꧔ꦿ字段重命名
查询时给字段重命名可以方便展示
select name as ‘姓名’,gender as ‘性别’ from students;
🍷꧔ꦿ表重命名
多表查询时会用到这种写法。
select s.gender from students as s;
🍷꧔ꦿ查询时去重
🍹去重一个字段:
select distinct 字段名 from 表名;
select distinct name from students;
🍹去重多个字段
去重多个字段,是指一整行的目标字段都相同时才去重,而不是分别去重。
select distinct name,age from students;
🍷꧔ꦿwhere 子句与逻辑运算符
| 逻辑运算符 | 含义 | 符号 |
| — | — | — |
| and | 逻辑与 | && |
| or | 逻辑或 | || |
| not | 逻辑非 | ! |
– 从students表格查询id是1的name
select name from students where cls_id=1;
– 从students表格查询cls_id>3的name和age
select name,age from students where cls_id>3;
– 从students表格查询cls_id>3且age>18的name和age
select name,age from students where cls_id>3 and age>18;
– 从students表格查询name不是张三的name,age和cls_id
select name,age,cls_id from students where name!=‘张三’;
– 从students表格查询name不是张三且gender(枚举类型字段)是其第一个索引值 的 name,age和cls_id
select name,age,cls_id from students where not name=‘张三’ and gender=1;
🍷꧔ꦿ模糊查询
% 表示任意多个字符
一个_ (下划线)表示一个字符
查询name以“张”开头的数据
select * from students where name like ‘张%’;
查询name含有“张”的字符的数据
select * from students where name like ‘%张%’;
查询name只有两个字符的数据
select * from students where name like ‘__’;
查询name至少有三个字符的数据
select * from students where name like ‘___%’;
🍷꧔ꦿ范围查询
查询id为1,2,4的数据
select * from students where id in (1,2,4);
查询年龄不是18和20的数据
select * from students where age not in (18,20)
查询id是3-5的数据(包括两端)
select * from students where id between 3 and 5;
查询id是3-5,且gender为“男”(枚举类型字段的第一个索引值)的数据
select * from students where (id between 3 and 5) and (gender=1);
查询年龄不在18到20的数据
select * from students where (age not between 18 and 20);
🍷꧔ꦿ空判断
查询cls_id为空的数据
select * from students where cls_id is null;
查询cls_id不为空的数据
select * from students where cls_id is not null;
🍷꧔ꦿ聚合函数应用
查询数据记录总条数
select count(*) from students ;
查询gender为“男”(枚举类型字段的第一个索引值)的数据记录条数
select count(*) from students where gender=1;
查询age最大值
select max(age) from students ;
🍷꧔ꦿ分组查询
group by
查询gender不同类别的个数
– 只查询
select count(*) from students group by gender;
– 同时显示出类别
select gender,count(*) from students group by gender;
– 显示出类别并重命名其字段名 as可以省略
select gender’性别’,count(*) from students group by gender;
🍹group_concat
– 同时显示出某个字段分组的详细信息,以name为例
select gender’性别’,group_concat(name),count(*) from students group by gender;
效果示例:
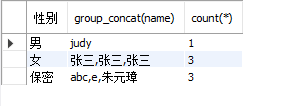
查询组内数据的某属性,以每个name对应的age为例,可以在group_concat后边的括号中放入多个字段,用逗号隔开:
select gender’性别’,group_concat(name,‘:’,age),count(*) from students group by gender;

🍹with rollup 分组后在最后一行显示总计
select gender’性别’,count(*)‘人数’ from students group by gender with rollup;
结果展示如图:
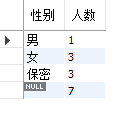
这样性别的最后一个值,是空值。为了更直观,常常给予其填充:
使用“总计”填充空值:
select ifnull(gender,‘总计’) as ‘性别’,count(*) from students group by gender with rollup;
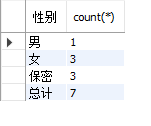
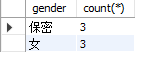
🍷꧔ꦿhaving 对结果集进行筛选
where的约束条件是建立在对原数据的基础上,而对非原数据进行约束需要使用having
以筛选出gender中数量大于2的计数为例,
即对通过gender分组后得到的“男”、“女”、“保密”三个值的计数进行约束,
筛选出值大于2的。此时如果使用where会报错,需要把where换成having。
select gender,count() from students group by gender having count()>2;
结果示例如下:
查询gender为“男”或“女”,且平均age大于18,的gender和name
select gender,avg(age),group_concat(name) from students group by gender having avg(age)>18 and (gender=1 or gender=2);
🍷꧔ꦿorder by 排序查询
查询age在18-26之间,且gender为“女”的数据,并按age从小到大排列
也可以在字段后添加关键词asc,这里省略了。因为默认也是从小到大,升序。
select * from students where (age between 18 and 26) and gender=2 order by age;
降序排列(从大到小):
使用关键词desc
select * from students where (age between 18 and 26) and gender=2 order by age desc;
也可以在order by 后边加上多个字段,功能是,当前一个字段相同时,按后一个字段进行排序
select * from students order by age desc,cls_id desc;
🍷꧔ꦿlimit
- limit [start,] count
其中,start为起始值,从0开始计数,且默认为0
取前三条数据
select * from students limit 3;
从第3条数据开始取4条数据
select * from students limit 2,3;
-
limit只能写在末尾。
-
limt不能包含有数学表达式,如limit 1+1,5 是不合规的。
准备数据,创建一个table1和一个table2,并写入一些数据
– 创建table1
create table table1(
id int not null primary key auto_increment,
name varchar(30),
age tinyint unsigned default 18,
high decimal(5,2),
gender enum(‘男’,‘女’),
cls_id int
);
– 创建table2
create table table2(
num int not null primary key auto_increment,
name varchar(30),
score int
);
– 写入数据
insert into table1 values
(1,‘张三’,20,180,‘男’,3),
(2,‘朱元璋’,30,175,‘男’,2),
(3,‘斯大林’,45,172,‘男’,3),
(4,‘武则天’,40,165,‘女’,2),
(5,‘梁非凡’,35,174,‘男’,1),
(6,‘花千骨’,18,166,‘女’,2),
(7,‘东方不败’,28,165,‘女’,3),
(8,‘东方子弦’,40,170,‘男’,2),
(9,‘戈尔巴乔夫’,85,177,‘男’,1),
(10,‘刘华强’,37,178,‘男’,1)
(11,‘西门庆’,30,180,‘男’,3),
(12,‘艾伦耶格尔’,18,178,‘男’,1),
(13,‘陈圆圆’,17,160,‘女’,2),
(14,‘张大炮’,22,168,‘男’,3),
(15,‘侯小啾’,21,178,‘男’,2)
;
insert into table2 values
(1,‘张三’,100),
(2,‘朱元璋’,75),
(3,‘斯大林’,71),
(4,‘武则天’,90),
(5,‘梁非凡’,82),
(6,‘花千骨’,77),
(7,‘东方不败’,66),
(8,‘东方子弦’,88),
(9,‘戈尔巴乔夫’,60),
(10,‘刘华强’,50)
(11,‘西门庆’,68),
(12,‘艾伦耶格尔’,73),
(13,‘陈圆圆’,80),
(14,‘张大炮’,84),
(15,‘侯小啾’,90)
;
数据准备好了:

总结
以上是字节二面的一些问题,面完之后其实挺后悔的,没有提前把各个知识点都复习到位。现在重新好好复习手上的面试大全资料(含JAVA、MySQL、算法、Redis、JVM、架构、中间件、RabbitMQ、设计模式、Spring等),现在起闭关修炼半个月,争取早日上岸!!!
下面给大家分享下我的面试大全资料
- 第一份是我的后端JAVA面试大全

后端JAVA面试大全
- 第二份是MySQL+Redis学习笔记+算法+JVM+JAVA核心知识整理

MySQL+Redis学习笔记算法+JVM+JAVA核心知识整理
- 第三份是Spring全家桶资料

MySQL+Redis学习笔记算法+JVM+JAVA核心知识整理
《一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码》,点击传送门,即可获取!
o table1 values
(1,‘张三’,20,180,‘男’,3),
(2,‘朱元璋’,30,175,‘男’,2),
(3,‘斯大林’,45,172,‘男’,3),
(4,‘武则天’,40,165,‘女’,2),
(5,‘梁非凡’,35,174,‘男’,1),
(6,‘花千骨’,18,166,‘女’,2),
(7,‘东方不败’,28,165,‘女’,3),
(8,‘东方子弦’,40,170,‘男’,2),
(9,‘戈尔巴乔夫’,85,177,‘男’,1),
(10,‘刘华强’,37,178,‘男’,1)
(11,‘西门庆’,30,180,‘男’,3),
(12,‘艾伦耶格尔’,18,178,‘男’,1),
(13,‘陈圆圆’,17,160,‘女’,2),
(14,‘张大炮’,22,168,‘男’,3),
(15,‘侯小啾’,21,178,‘男’,2)
;
insert into table2 values
(1,‘张三’,100),
(2,‘朱元璋’,75),
(3,‘斯大林’,71),
(4,‘武则天’,90),
(5,‘梁非凡’,82),
(6,‘花千骨’,77),
(7,‘东方不败’,66),
(8,‘东方子弦’,88),
(9,‘戈尔巴乔夫’,60),
(10,‘刘华强’,50)
(11,‘西门庆’,68),
(12,‘艾伦耶格尔’,73),
(13,‘陈圆圆’,80),
(14,‘张大炮’,84),
(15,‘侯小啾’,90)
;
数据准备好了:
总结
以上是字节二面的一些问题,面完之后其实挺后悔的,没有提前把各个知识点都复习到位。现在重新好好复习手上的面试大全资料(含JAVA、MySQL、算法、Redis、JVM、架构、中间件、RabbitMQ、设计模式、Spring等),现在起闭关修炼半个月,争取早日上岸!!!
下面给大家分享下我的面试大全资料
- 第一份是我的后端JAVA面试大全
[外链图片转存中…(img-knyInnRX-1714711367375)]
后端JAVA面试大全
- 第二份是MySQL+Redis学习笔记+算法+JVM+JAVA核心知识整理
[外链图片转存中…(img-I1ocXi9X-1714711367376)]
MySQL+Redis学习笔记算法+JVM+JAVA核心知识整理
- 第三份是Spring全家桶资料
[外链图片转存中…(img-VyZC7nmy-1714711367376)]
MySQL+Redis学习笔记算法+JVM+JAVA核心知识整理
《一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码》,点击传送门,即可获取!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









