







实现:
- 让js最后加载就是将js脚本代码放在文档底端,实现js脚本代码的最后加载
问题:
- 当项目中有大量的js代码时,可能会带来显著的性能消耗
6.2.2 defer属性
实现:
<script src="...." defer></script>
说明:
-
使用defer属性的原理即是,使得带有defer属性的js脚本在页面完全加载之后再执行js脚本代码,便不会阻塞页面的加载
-
多个defer属性的脚本按照页面中出现的顺序执行
6.2.3 async属性
实现:
<script src="...." async></script>
说明:
- 使用async属性,使得HTML和js脚本一并加载(异步),即不会阻塞页面的解析;即浏览器遇到async时不会阻塞页面的解析,而是直接下载和解析
问题:
-
由于使用async的脚本也是加载完成之后立即执行的,这个时候如果文档还没解析完成的话同样会堵塞,并且多个acsync属性的脚本的执行时顺序是不可预测的;
-
所以当多个js脚本代码独立,且不依赖于页面的任何脚本时,使用async最优!
6.2.4 总结defer与async的异同以及使用场景
- 相同点:
-
不会堵塞页面的加载
-
不适用于内部的js(即是再页面中引入外部文件时使用)
-
这两个属性的js脚本代码不能使用document.write()方法
2)不同点
-
defer是HTML4中script的属性
-
async是HTML5中script中的属性
-
使用了defer属性的脚本代码是在页面完全加载完毕之后再执行
-
使用了async属性的脚本代码和页面一并加载(异步),当该js脚本下载完成时立即执行
3)使用场景
-
如果脚本需要等待页面解析,且依赖于其他js脚本,那么使用defer属性,使用时将脚本按所需顺序放置于html中
-
如果脚本不需要等待页面解析,且不依赖于其他脚本,那么使用async;即表示使用了async的你脚本会在下载完成后立即执行,也会在window.onload执行之前执行
6.2.5 使用动态创建DOM的方式
实现:
- 即我们可以对文档的加载事件设置事件监听,当文档加载完成后再动态创建script标签引入js脚本
代码如下:
//这些代码应被放置在标签前(接近HTML文件底部)
6.2.6 使用定时器setTimeout的方式
代码如下:
6.2.7 使用jQuery中的getscript函数
getScript() 方法通过 HTTP GET 请求载入并执行 JavaScript 文件。
语法:jQuery.getScript(url,success(response,status))
url(必写):将要请求的 URL 字符串
success(response,status)(可选):规定请求成功后执行的回调函数。
其中的参数
response - 包含来自请求的结果数据
status - 包含请求的状态(“success”, “notmodified”, “error”, “timeout” 或 “parsererror”)
//加载并执行 test.js:
$.getScript(“test.js”);
//加载并执行 test.js ,成功后显示信息
$.getScript(“test.js”, function(){
alert(“Script loaded and executed.”);
});
7. Ajax是什么?如何创建一个Ajax?
详细解析看我写的写篇文章:深入了解XMLHttpRequest对象
是什么:
-
我的理解时Ajax是一种进行异步通信的方法,Ajax的核心是XMLHttpRequest对象。使用Ajax方法请求数据,可以使得页面不重新刷新或者跳转的情况下加载更新数据。
-
其通过直接由js脚本向服务器发送http请求,然后服务器返回响应数据,更新网页相应的部分
怎么创建:
1)首先是创建一个异步调用对象,即XMLHttpRequest()对象;
2)然后调用open()方法建立与服务器的连接,open()方法接收三个参数,第一个参数是method即请求的方法(get、post、put等),第二个参数是请求url,第三个参数接收一个布尔值,用来表示是否发送异步请求;此时嗲用open()方法并不是真正的向服务器发送了请求,而是一个准备阶段;
3)在发送请求前,我们可以为这个对象添加一些信息和监听函数,比如可以通过setRequestHeader方法来添加请求头信息等。一个XMLHttpRequest对象一共有五种状态,为这个对象状态的变化添加监听函数。由于向服务器发送了请求之后,响应状态时一直在改变的,且每一次改变,都会触发触发onreadstatechange事件,通常情况下对readySteta=4时进行判断,代表服务器返回的数据全部接收完成;同时判断服务器的响应状态码大于等于200或者小于300时代表返回值横穿,我们便可以对服务器返回的数据进行相应的处理。进而对页面进行更新;(以上也可以使用onload事件进行判断)
3)当对象的属性和监听函数设置完成之后,调用send()方法,向服务器发送请求。send()方法可以接收参数作为发送的数据体,该参数类型可以为json、blob等,当你不需要向服务器发送数据时,传入null值;
创建:
//一般实现
const xhr = new XMLHttpRequest();
xhr.open(‘get’, ‘/server’, true);
//设置响应类型
xhr.responseType = ‘json’
//设置请求头信息
xhr.setRequestHeader(‘MyHeader’, ‘MyValue’);
//设置请求失败监听函数
xhr.onload = function () {
console.log(‘请求失败了…’)
}
//为XMLHttpRequest对象的状态设置监听事件(监听onreadystatechange)
xhr.onreadystatechange = function () {
if (this.readyState !== 4) {
return;
}
if (this.status >= 200 && this.status < 300) {
//响应正常
console.log(this.responseText)
} else {
console.log(this.statusText)
}
}
//发送请求
xhr.send(null);
8.解决Ajax中浏览器缓存问题
说明:
-
Ajax能提高页面的加载速度主要原因是通过Ajax减少了重复数据的载入,也即在载入数据的同时将数据缓存到内存中,一旦数据被加载,只要没有刷新页面,这些数据就会一直被缓存在内存中。
-
当提交的URL与历史的URL一致时,就不需要提交给服务器,即不需要从服务器中获取数据,这样虽然降低了服务器的负载,提高了用户的的体验,但不能及时更新数据。
-
为了保证读取的数据是最新的,需要禁止其缓存功能
解决思路:
1.禁掉缓存
2.更新请求URL(但不是改变URL),因为只要URL不变,那么浏览器就不会取检查服务器是否已经更新,那么浏览器用的数据仍是换粗中的数据
解决:
1)在ajax发送请求前加上
//本质是让缓存过期
anyAjaxObj.setRequestHeader(“If-Modified-Since”,“0”);
2)在ajax发送请求前加上
//本质是设置不允许产生缓存
anyAjaxObj.setRequestHeader(“Cache-Control”,“no-cache”);
3)在URL上加上一个随机数,
“fresh”=Math.random()
4)在URL上加上时间戳
“nowtime”=+new Date().getTime();
//如:request.jsp?q=q&date=(new Date()).getTime()
//运用实例:
//例如在用户登录验证的时候,点击验证码更新,只需要在发送验证码的请求上加上时间戳或者随机数的形式以更行URL,那么就可以请求得到新的数据
//又如短信发送的状态,如果隔几秒查询以此,URL不变的话,显示出来的状态则不会发生改变
5)如果是使用jQuery,直接适应$.ajacSetuo({cache:false})。这样页面的所有ajax就会执行这条语句就不需要保存缓存记录;
9.同步和异步的区别
-
同步就是值当一个进程在执行某个请求的时候,当这个请求需要等待一定的时间才能返回数据,那么这个进程就会一直处于等待状态,直到这个请求返回信息才继需往下执行
-
异步是指当在一个进程中执行某个请求时,且这个请求也需要等待一定的时间才能返回,而此时这个进程会继续往下执行,即不会堵塞等待信息的返回,
通俗的讲,同步是值客户端向服务端发送请求,在等待客户端响应请求时,客户端不能进行其他操作,直到服务器返回请求;
异步就是客户端向服务器发送请求,在等待服务端响应的时候,客户端不必等到服务端响应结束,可以进行其他操作;
10. 如何解决跨域问题
详细解析可以参看我写的这篇文章:前端常见的跨域解决方法
11.简单谈一下cookie?
详细解析可以查看我写的这篇文章:聊一聊cookie
在这里主要描述一下面试时应该如何回答:
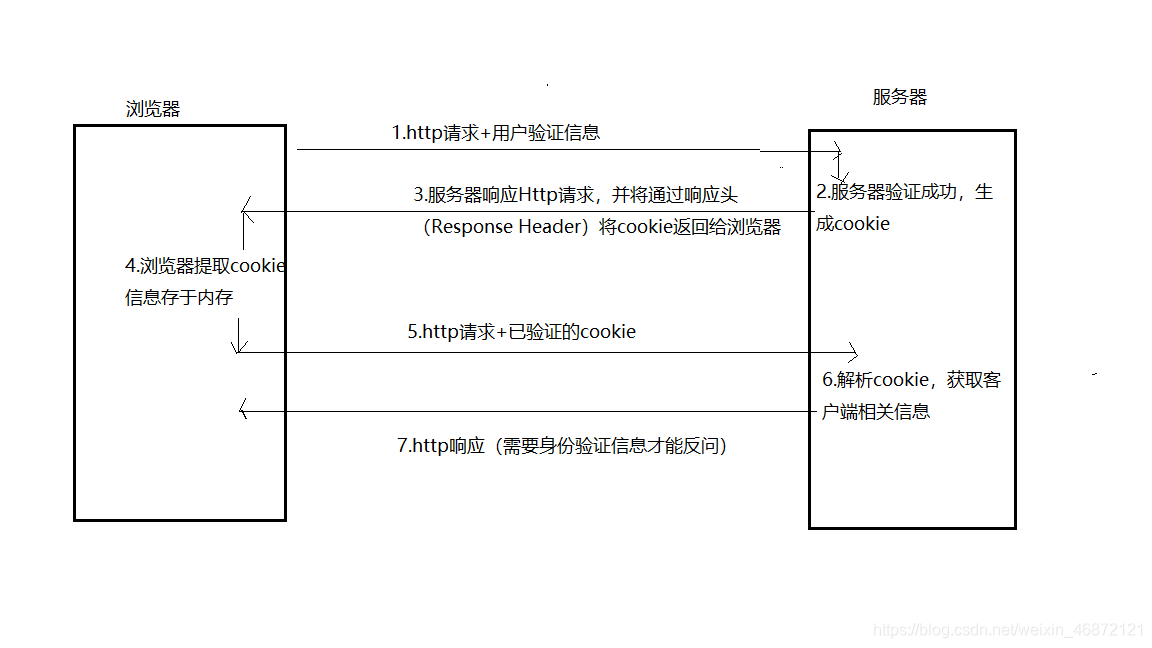
-
我的理解是,cookie是服务端用来维护会话状态信息的数据。当浏览器向服务器发送带有验证的请求时,服务器进行验证,生成cookie;然后服务器响应请求,并通过响应头的set-Cookie字段将生成的cookie返回给浏览器,那次浏览器提取cookie,然会将其保存在本地内存中。当下次再请求时,则将已经验证的cookie发送至服务器,服务器验证通过便响应请求;这样一来便可以实现一些用户登录状态等功能;
-
cookie的大小一般为4kb,并且只能够被同源的页面共享访问
-
服务器可以适应set-Cookie的相应头来配置cookie信息,一个cookie包括了5个属性。分别为expires、domain、path、secure、HttpOnly。其中expries定义的cookie的期限,domain是域名、path是路径,domain和path共同约束了cookie可以被哪些url访问。secure定义cookie是否在安全协议下发送,HttpOnly规定cookie只能被服务器反问,浏览器的js不能访问cookie。
-
在发送xhr跨域请求时,cookie不会自动添加到请求头部(Request Header),但是可以通过服务器和客户端进行限行设置
12.JS中几种模块化规范
对于CommonJS、AMD、CMD以及ES6 Module模块规范详细解析可以参考我写的这篇文章:JS中的几种模块化规范
在这里再总结一下:
-
第一种是Commonjs模块化规范:CommonJS模块化规范,它通过Require来引入模块,通过module.exports来定义模块的输出接口。其主要在服务端使用(比如Nodejs),因为其原理是同步加载,再服务端js代码都是存储在本地内存的,所以读取较快。而在浏览器中的模块的加载往往是需要通过网络请求,往往是需要通过异步加载的方式实现;
-
第二种是AMD方案:AMD方案使用的原理是异步加载模块,且其遵循的是依赖前置,即在定义模块时就要定义相关的依赖,并且这些模块会在加载完成之后直接执行,require.js实现了AMD规范
-
第三种是CMD模块,CMD模块加载模块的原理也是异步加载的,其遵循的是就近原则,对于需要加载的模块使用reqire path引入即可,并且模块的执行也是遇到requie才执行。
-
第四种是ES6 Module模块,其使用export形式定义模块,使用import的方式导入模块,ES6模块的加载时在编译时加载
13 Require.js的核心原理是什么?
- 概念
requireJS时基于AMD模块化加载规范,使用回调函数来解决模块化加载问题
- 原理
requireJS是使用script元素,通过script元的的src属性来引入模块
- 特点
实现js文件的异步加载
管理模块之间的依赖,便于代码的编程和维护
总:requireJS的核心原理是通过动态创建script脚本来异步引入模块,然后对每个脚本的load事件进行监听,如果每个脚本都加载完成了,再调用回调函数执行模块!
14.ECMScript6中怎样写class,为什么会出现class?
1.class的基本语法
创建类实例对象不同于构造方法,需要使用new关键字来创建
class Point{
constrctor(){}
}
let p=new Point();
2.class是ES6新增的语法,我的理解是为了补充js中缺少的一些面向对象语言的特性。通过class可以有利于我们更好的组织代码,但class还是具有原型继承的思想,比如class中属性和方法可以添加在原型上,为所有类的实例对象所共享;
再详细一点关于ES6中class的说明可以参考我写的这篇文章:
15. document.write和innerHTML的区别
-
使用document.write的内容会替代掉整个文档的内容,即会重写整个页面
-
使用innerHTML只是替代指定元素的内容,只会重写页面中部分内容
-
使用
document.write(‘xxxx’);
element.innerHTML=“xxxx”;
16.javascript中类数组对象的定义
1)类对象:拥有length属性和若干索引属性的对象都可以被称为类数组;
2)类数组对象和数组对象类似,只是类数组对象不能使用数组对象特有的方法(若想使用,需要将类数组对象转换为数组对象)
3)常见的数组是对象:arguments、DOM方法返回结果(NodeList、HTMLCollection)
17.类数组对象转换为数组对象的常见的方法
-
Array.prototype.slice.call(类数组);
-
[].slice.call(类数组);
-
Array.from(类数组)
-
[…类数组]----扩展运算符
function fun() {
console.log(‘arguments’, arguments);
//Array.prototype.slice.call(类数组);
const arr1 = Array.prototype.slice.call(arguments)
console.log(‘arr1’, arr1)
//[].slice.call(类数组);
const arr2 = [].slice.call(arguments)
console.log(‘arr2’, arr2)
//Array.from
const arr3 = Array.from(arguments)
console.log(‘arr3’, arr3)
//扩展运算符
const arr4 = […arguments]
console.log(‘arr4’, arr4)
}
fun(1, 2, 3, 4)
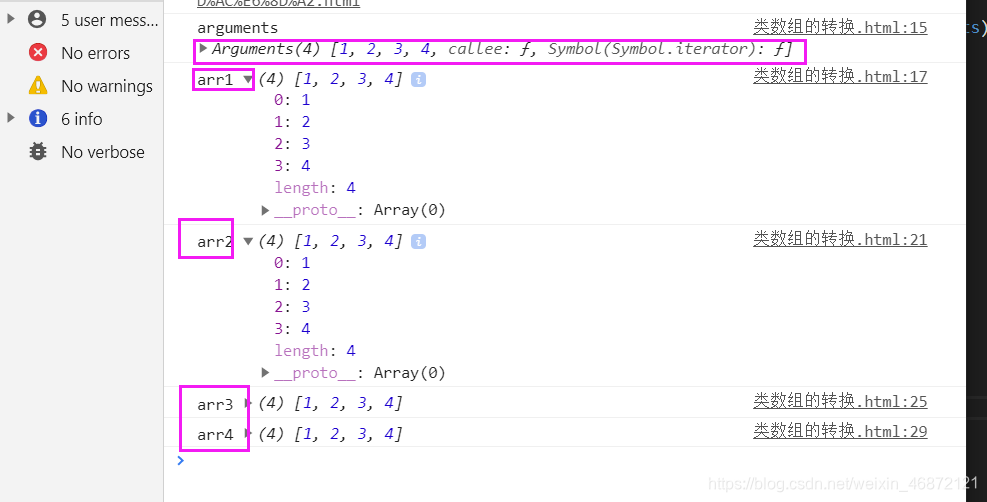
18.数组中有哪些原生的方法,举例以下?
-
数组和字符串的转换方法:
toString(),join(),其中join可以接收特定字符串参数,将作为将数组转换为字符串时的分割符 -
数组尾部操作的方法:
pop(),push() -
数组首部操作方法:
unshift(),shift() -
数组重排序的方法:
reverse(),sort(),其中sort几首一个函数作为参数,该函数规定了排序的方式 -
数组中的迭代方法:
every(),forEach(),filter(),map() -
数组中查找特定索引的方法:
indexOf(),indexLastOd() -
数组链接方法:
concat(),返回的是拼接好的数组,不影响原数组 -
数组中截取方法:
slice(),用于截取数组的一部分返回,不影响原数组 -
数组插入方法:
splice(),影响原数组
19. 哪些操作会造成内存泄漏
19.1意外的全部变量的使用
即当我们使用一个未声明的变量时,实质上意外的创建了一个全局变量,而这个变量会一直留在内存中无法被收回
- 示例1:
Javascript处理未定义变量的方式比较宽松:未定义的变量会在全局对象创建一个新变量,在浏览器中,全局变量时window。
function foo(arg) {
bar = “this is a hidden global variable”;
}
真相是:
function foo(arg) {
window.bar = “this is an explicit global variable”;
}
函数foo内部忘记使用var,意外创建了一个全局变量,而使这个变量一直保存在内存中;
- 示例2:
另一种意外的全局变量可能由this创建:
function foo() {
this.variable = “potential accidental global”;
}
// Foo 调用自己,this 指向了全局对象(window)
// 而不是 undefined
foo();
如何避免这种情况呢?
在javascript文件头部加上’use strict‘,可以避免此类错误的发生。使用严格模式解析javascript,避免意外的全局变量
19.2被遗忘的定时器或回调函数
即当我们设置了定时器如setInterval,而忘记取消它的时候,如果循环函数有对外局部变量的引用的话,那么这个变量会一直保存再保存着
19.3脱离DOM的引用
即是当我们获取一个DOM元素的引用的时候,而后面这个DOM元素被删除,我由于我们一直保留着这个元素的引用,所以它也无法被回收
19.4闭包
闭包的不合理使用,从而导致某些变量一直被留在内存中
20. 如何判断当前脚本运行在浏览器(browser)还是在node环境种?
if(typeof window !== ‘undefined’){
console.log(‘browser’);
}
if(typeof global !== ‘undefined’){
console.log(‘node’);
}
或者
this===window?console.log(‘browser’):console.log(‘node’);
通过判断Global对象是否未window,使window则允许再浏览器种,如果为undefined,则当前脚本运行再node环境下
21.移动端的点击事件有延迟,时间 是多少,为什么会有?怎么解决这个问题?
移动端的点击延迟
移动端的点击延迟时间是300ms,因为移动端有默认的双击缩放操作,浏览器通过判断用户第一个此点击与第二次点击的时间,来确认用户是否是需要进行双击缩放的操作。(即浏览器点击后要等待300ms,看用户有没有下一次点击,来判断是不是双击)
怎么解决点击延迟
1)使用meta标签来禁用页面的缩放
ps:但是这种方式的缺点是牺牲了页面的缩放,我们不想要的只是双击双击缩放行为,我们还是希望能够通过双指来实现缩放的,
2)调用FastClick库
FastClick库的相关介绍:FastClick是专门为解决移动端浏览器300毫秒点击延迟问题所开发的一个轻量级的库。FastClick的实现原理是在检测到touched事件的时候,会通过DOM自定义事件立即触发模拟一个click事件,并把浏览器在300ms之后的click事件阻止掉,实现如下:
//引入fastclick
// 原生js初始化
if (‘addEventListener’ in document) {
document.addEventListener(‘DOMContentLoaded’, function() {
FastClick.attach(document.body);
}, false);
}
总:使用FastClick是最好的方案,不存在点击创投现象(对于点击穿透不熟悉的可以自行查一下资料)
可以参考这篇文章:https://blog.csdn.net/qq_42532128/article/details/106176195
22. 什么是“前端路由”?什么时候适合使用”前端路由”?“前端路由”有哪些优缺点?
1.前端路由:前端路由就是把路由对应的内容或者页面的任务交给前端来做,以前是通过服务器根据url的不同返回不同的页面实现的。
2.使用:在单页面应用中,大部分页面结构不变,只改变内容的使用。
3.一般有两种形式的前端路由,一是hash模式(#),二是pushState的方式
4.优缺点:
-
优点:用户体验好,不需要每次都从服务器获取,快速展现给用户
-
缺点:单页面无法记住之前滚动的位置,无法在前进、后退的时候记住滚动的位置
23.检测浏览器版本有哪些方式?
有两种方式:
1.通过检测window.navigator.userAgent的值,但是这种方式不是很可靠,因此这个值可以被改变(如早期的ei会伪装userAgent的值为Mozilla来躲过服务器的检测)
2.可以通过功能检测,根据每个浏览器独有的特性进行判断,如ie下独有的ActiveAObject
24. 什么是Ployfill
- Ployfill的作用是为了解决API的兼容问题,比如在不同的浏览器中,支持的API有所差异,但是若想在不支持某API的浏览器中实现这个功能,则需要引入Ployfill(当然也可以自己写)
举个例子:(有些旧的浏览器不支持Number.isNan方法mPloyfill可以是这样的:)
if(!Number.isNaN){
Number.isNaN=function(num){
//(假如浏览器没有Number.isNan方法,那么就给它添加上去)
return (num!=num)
}
}
25.使用JS实现获取文件扩展名
- 方式1(使用split与pop方法)
获得扩展名
- 方式2 使用正则表达式
###Vue部分
https://zhuanlan.zhihu.com/p/111310865
26. 介绍以下js中的节流和防抖
26.1 节流(通过设置perTime与nowTime)
节流技术是用于设定在固定事件内,执行特定的功能代码,如果同一单位事件内某事件被多次触发,那么只有一次生效(节流可以用在scroll函数的事件监听上,通过事件节流来降低事件调用的频率)
26.2 防抖(通过定时器)
-
在时间触发n秒后再执行回调,如果这n秒内事件又被触发,则重新计时
-
比如在搜索功能时,用户输入关键字搜索,不用每次输入都发送请求显示数据,只有等待用户停止输入后等待一定的时间(确保用户不再输入),再执行特定功能的代码。
所用的技术是定时器,和闭包技术
1.防抖的实现
//防抖的实现
function debounce(fun, wait) {
let timer = null;
//所以下面的匿名函数适应的函数外部的变量,这里是闭包的作用
return function () {
//清空计时器是为了当事件又被触发时,重新计时
clearInterval(timer)
timer = setInterval(() => {
fun.apply(this)
}, wait)
}
}
var result = debounce(fun1, 1000)
result()
2.节流的实现
function limtfun(fun, wait) {
var perTime = 0;
return function () {
var nowTime = new Date()
if (nowTime - perTime > wait) {
fun.call(this)
perTime = nowTime//由于闭包的原因,这里的nowTime不会被清空
}
}
}
27. Object.is()与原来的比较操作符“=” 与“”的区别
-
“==”两等号在进行比较时,若两边的类型不一致,则会进行隐式的类型转换(比如‘1’->1、true->1,false->0、{}->[Object Object]
-
三等号比较时不进行隐式类型转换,类型和值有一不同则会返回false
-
而Object.is()则是在三等好的判别基础上做了特殊的处理,使得-0和+0不再相当,而NaN与NaN会返回true
-
Object.is()被认为具有特殊用途,但不能说时Object.is()比其他的相等对比更加严格或者宽松
28.浏览器中的事件循环机制(Event Looping)
JS在执行的过程中会产生一个执行环境,js的代码在这个执行环境中按顺序执行,当遇到异步代码时,会被挂起到事件队列中(Task),对于这个队列中的任务则会涉及到微任务和宏任务,当执行栈的为空时,由于事件循环机制,就会从事件队列中拿出需要执行的代码到执行栈中执行,此时执行的循序时先执行微任务,当微任务执行完毕之后,再执行宏任务。
29.instanceof的原理
-
instanceof可以正确判断对象的类型
-
用于判断某个实例是否属于某个构造函数
-
在继承关系中用来判断一个实例是否属于它的父类型或者祖先类型的实例;
-
实现原理是通过判断实例对象的原型属性__proto__和构造函数或者父类的原型对象prototype是否相等,循环遍历,相等则返回true;(简单的说就是只要左边的变量原型链上有右边变量的prototype属性即可)
1)语法
var obj=new Object()
obj instanceof Object //true
2)底层原理
function myInstanceof(left, right) {
left = left.proto;
right = right.prototype;
while (true) {
if (left === null || left === undefined) {
return false
}
if (left === right) {
return true
}
//即上面均不满足时,继续往原型链上查找
left = left.proto;
}
}
参考文章:https://zhuanlan.zhihu.com/p/105487552
30. 手写封装一个jsonp
function jsonp(url, data, callback) {
//产出随机的回调函数名(因为可能有多个请求,这里可以区别开来)
var funcName = ‘jsonp_’ + Date.now() + Math.random().toString().substr(2, 5);
//如果存在其他传入参数,需要进行拼接
if (typeof data === ‘object’) {
var tempArr = [];
for (var key in data) {
var value = data[key];
tempArr.push(key + ‘=’ + value)
}
//将数组以&拼接成字符串,如name=h$age=21
data = tempArr.join(‘&’)
}
var script = document.createElement(‘script’)
script.src = url + ‘?’ + data + ‘callback=’ + funcName
document.body.appendChild(script);
//这里得到请求的数据,在回调函数中执行处理
window[funcName] = function (data) {
callback(data)
}
}
//使用
jsonp(‘http:127.0.0.1:3000/api’, {}, function (res) {
console.log(res)
})
参考文章:
https://blog.csdn.net/weixin_40483654/article/details/106434990
31.有几种方式可以实现存储功能?分别有什么有优缺点?什么是Service Worker?
31.1 实现的存储功能
实现存储功能:Cookie、localStorage、sessionStorage、indexDB
| 特性 | Cookie | localStroage | sessionStorage | indexDB |
| — | — | — | — | — |
| 数据生命周期 | 一般由服务器生成,可以设置过期事件 | 除非被清理,否则一直存在 | 页面关闭时就被清理 | 除非被清理,否则一直存在 |
| 数据存储大小 | 4kb | 5mb | 5mb | 无限 |
| 与服务端的通信 | 会一直携带在请求头 | 不参与下 | 不参与 | 不参与 |
PS:没有大量的数据需求的话,可以使用localStorage和sessionStorage,对于不怎么改变的数据,尽量使用localStorage。
31.2 什么是Service Worker
-
Service Worker是运行在浏览器背后的独立线程,一般可以用来实现缓存功能,使用Service Worker的话,传输协议必须使用HTTPS。
-
使用Service Worker实现缓存一般分为三个步骤:
1)首先要注册Service
2)监听install,拿到需要缓存的文件
3)下次用户访问的时候就可以通过拦截请求方式查询是否存在缓存,存在缓存的话就可以直接读取缓存文件,否则就去请求数据
32.浏览器中的缓存机制
-
缓存可以是性能优化中简单高效的一种方式
-
对于一个数据请求,分为3个阶段,分为网络请求、后端处理、浏览器响应。浏览器缓存可以帮助我们在第一和第三步中优化性能。比如直接使用缓存而不发请求,或者发请求但后端的数据与前端一致,那么就没有必要再将数据回传回来,这样就减少可数据响应。
接下来我们将通过以下几个方面来探讨浏览器的缓存机制
-
缓存位置
-
缓存策略
-
实际场景应用缓存策略
32.1 缓存位置
我知道的浏览器的缓存位置有Service Worker、网络请求,并且有各自的优先级,当一次查找缓存并且都没有命中的时候,才会请求网络。
32.2 缓存策略
通常浏览器的缓存策略可以分为两种:强缓存和协商缓存。并且这两种缓存策略都是通过设置 HTTP Header 来实现的
1)强缓存(有两种设置方式)
-
Expires:缓存受限于本地的时间
-
Cache-Control:通过max-age来设置缓存的时间期限
2)协商缓存(两种设置方式)
简单的说,如果缓存过了,就需要发起请求验证资源是否更新。即当浏览器发送请求验证时,如果资源没有发生改变,那么服务器就返回304状态码,并更新浏览器的缓存有效期。(相当于浏览器和服务器进行协商,是否返回新的数据)
- Last-Modified
Last-Modified表示本地文件最后修改日期,当 Last-Modified的值发送给服务器,循环服务器在该日期后资源是否有变更,有则返回新的资源,否则返回304状态码
- ETag
当ETag的值发送给服务器,询问该资源是否有更新,有则返回新的资源(并且ETag的资源比Last-Modified高)
32.3 实际场景应用缓存策略
一般来说,现在都会使用工具来打包代码,那么我们可以对文件名进行哈希处理,只有当代码修改之后生产新的文件名。基于此,我们就可以给代码设置缓存有效期一年Cache-Control:max-age=3153600,这样只有html文件中引入的文件名发生了改变,才回去下载新的代码,否则就一直使用缓存。
33. 插入几万个DOM,如何实现页面不卡顿?
-
使用分页技术
-
若不分页,则使用虚拟滚动技术(比如elment-ui中的scrollbar可以实现)
虚拟滚动:原理时只渲染可视区域内的内容,非可视区的则不渲染,当用户在滚动的时候就实时去替换渲染的内容。
34.什么情况下会产生渲染堵塞?
我们知道,在浏览器的渲染线程和JS引擎线程时互斥的,因此在渲染时,若遇到script标签时,则此时会渲染会停止下来,等待script代码加载完毕,再从暂停的地方重新渲染。也就是说,当你想首屏渲染越快,那么就不应该再首屏加载js文件,也就是建议将script标签放在body标签底部的原因。当然,你也可以给script标签添加defer或者async属性,那么此时的script可以放在任意位置,因为此时js文件会并行下载,若时defer,会等待页面渲染结束才执行,而async会在加载完毕之后立即执行。
只是defer和async表示js文件的加载和解析不会阻塞渲染。‘
35. 重绘和回流
-
重绘是节点更改了外观而不影响布局,比如更改元素的color属性
-
回流是改变了节点的布局或者几何属性,比如改变元素的宽高等属性
-
回流必然发生重绘,重绘不一定引发回流。
36. 减少重绘和回流
1.使用transform替换top
2.使用visibility替换display:none,因为前者只会引发重绘,而后者会引发回流
3.少用table布局,因为table布局很小的一个改动会引发整个table的重新布局
4.将频繁重绘或者回流的节点设置为图层,图层能够阻止该节点的渲染行为影响别的节点。(比如video标签,浏览器会自动将该节点变为图层)
37. 什么是XSS攻击?如何防止XSS攻击?
1.XSS攻击
-
XSS(Cross-Site Scripting)—跨站脚本攻击,简称XSS,是一种代码注入攻击,攻击者通过在目标网址注入恶意脚本,使之在用户的的浏览器上运行。利用这些恶意脚本,攻击者获取用户敏感信息如Cookie、SessionID等,进而危害数据安全
-
XSS的本质:恶意代码未经过滤,与网站正常的代码混在一起;浏览器无法分辨哪些脚本是可信的,导致恶意脚本被执行
最后
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数初中级Android工程师,想要提升技能,往往是自己摸索成长,自己不成体系的自学效果低效漫长且无助。
因此收集整理了一份《2024年Web前端开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。


既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Android开发知识点!不论你是刚入门Android开发的新手,还是希望在技术上不断提升的资深开发者,这些资料都将为你打开新的学习之门!
如果你觉得这些内容对你有帮助,需要这份全套学习资料的朋友可以戳我获取!!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!
cript标签时,则此时会渲染会停止下来,等待script代码加载完毕,再从暂停的地方重新渲染。也就是说,当你想首屏渲染越快,那么就不应该再首屏加载js文件,也就是建议将script标签放在body标签底部的原因。当然,你也可以给script标签添加defer或者async属性,那么此时的script可以放在任意位置,因为此时js文件会并行下载,若时defer,会等待页面渲染结束才执行,而async会在加载完毕之后立即执行。
只是defer和async表示js文件的加载和解析不会阻塞渲染。‘
35. 重绘和回流
-
重绘是节点更改了外观而不影响布局,比如更改元素的color属性
-
回流是改变了节点的布局或者几何属性,比如改变元素的宽高等属性
-
回流必然发生重绘,重绘不一定引发回流。
36. 减少重绘和回流
1.使用transform替换top
2.使用visibility替换display:none,因为前者只会引发重绘,而后者会引发回流
3.少用table布局,因为table布局很小的一个改动会引发整个table的重新布局
4.将频繁重绘或者回流的节点设置为图层,图层能够阻止该节点的渲染行为影响别的节点。(比如video标签,浏览器会自动将该节点变为图层)
37. 什么是XSS攻击?如何防止XSS攻击?
1.XSS攻击
-
XSS(Cross-Site Scripting)—跨站脚本攻击,简称XSS,是一种代码注入攻击,攻击者通过在目标网址注入恶意脚本,使之在用户的的浏览器上运行。利用这些恶意脚本,攻击者获取用户敏感信息如Cookie、SessionID等,进而危害数据安全
-
XSS的本质:恶意代码未经过滤,与网站正常的代码混在一起;浏览器无法分辨哪些脚本是可信的,导致恶意脚本被执行
最后
自我介绍一下,小编13年上海交大毕业,曾经在小公司待过,也去过华为、OPPO等大厂,18年进入阿里一直到现在。
深知大多数初中级Android工程师,想要提升技能,往往是自己摸索成长,自己不成体系的自学效果低效漫长且无助。
因此收集整理了一份《2024年Web前端开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友,同时减轻大家的负担。
[外链图片转存中…(img-Sk0uMmQJ-1715712015448)]
[外链图片转存中…(img-WQPGV1SE-1715712015449)]
[外链图片转存中…(img-OsXm9OlV-1715712015449)]
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,基本涵盖了95%以上Android开发知识点!不论你是刚入门Android开发的新手,还是希望在技术上不断提升的资深开发者,这些资料都将为你打开新的学习之门!
如果你觉得这些内容对你有帮助,需要这份全套学习资料的朋友可以戳我获取!!
由于文件比较大,这里只是将部分目录截图出来,每个节点里面都包含大厂面经、学习笔记、源码讲义、实战项目、讲解视频,并且会持续更新!















 5565
5565

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









