







最后
对于很多Java工程师而言,想要提升技能,往往是自己摸索成长,不成体系的学习效果低效漫长且无助。
整理的这些资料希望对Java开发的朋友们有所参考以及少走弯路,本文的重点是你有没有收获与成长,其余的都不重要,希望读者们能谨记这一点。
再分享一波我的Java面试真题+视频学习详解+技能进阶书籍

coll1.add(“CC”);
coll.addAll(coll1);
System.out.println(coll);
//3. isEmpty():判断当前集合是否为空(不是判断是null,是判断集合中是否有元素)
System.out.println(coll.isEmpty());//false
Collection coll2 = new ArrayList();
coll2.add(null);
System.out.println(coll2.isEmpty());//false
//4. clear():清空集合元素
coll.clear();
System.out.println(coll.isEmpty());
}
}

注意事项:
-
add()方法只能填对象。
-
向Collection接口的实现类的对象中添加数据obj时,要求obj所在类要重写equals()方法(不然像contain()进行比较时,比较的就是地址,而不是值)。
package com.holmes.java07;
import org.junit.Test;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collection;
public class CollectionTest {
@Test
public void test1(){
Collection coll = new ArrayList();
//这里的123是一个对象
coll.add(123);
coll.add(456);
coll.add(new String(“Tom”));
coll.add(false);
coll.add(new Person(“hello”,22));
Person p = new Person(“Jerry”,20);
coll.add§;
//1. contains(Object obj):判断当前集合中是否包含obj
boolean contains = coll.contains(123);
System.out.println(contains);//true
//当然contain()方法比较的不是地址,如创建了两个不同地址,相同内容的String,结果就返回了true。
//原因呢,就是因为String类中重写了equals方法,就是比较内容,所以这里返回true
//额外说一下,equals比较是从头到尾进行比较,比较多少次得看位置在哪里。
System.out.println(coll.contains(new String(“Tom”)));//true
//对于自己定义的类,如果自己没有重写equals方法,那么就是默认调用父类Object的方法,那就是用 == 判断 , 不是用equals判断, 那就比较的是地址。
System.out.println(coll.contains(new Person(“hello”,22)));//false
System.out.println(coll.contains§);//true
//2. containsAll(Collection coll1):判断形参coll1中的所有元素是否都存在于当前集合中。
//Arrays.asList的作用是将数组转化为list。
Collection coll1 = Arrays.asList(123,456);
System.out.println(coll.containsAll(coll1));
}
}
class Person{
private String name;
private int age;
public Person() {
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
public void setName(String name) {
this.name = name;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return “Person{” +
“name='” + name + ‘’’ +
“, age=” + age +
‘}’;
}
}
package com.holmes.java07;
import org.junit.Test;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collection;
public class CollectionTest {
@Test
public void test2(){
//3. remove(Object obj):从当前集合中移除obj元素。
Collection coll = new ArrayList();
coll.add(123);
coll.add(456);
coll.add(new String(“Tom”));
coll.add(new Person(“hello”,22));
coll.add(false);
coll.remove(123);
System.out.println(coll);
//4. removeAll(Collection collName):从当前集合中移除collName中所有的元素
//意思就是:除去双方交集。
Collection coll1 = Arrays.asList(456, new String(“Tom”));
coll.removeAll(coll1);
System.out.println(coll);
}
@Test
public void test3(){
Collection coll = new ArrayList();
coll.add(123);
coll.add(456);
coll.add(new String(“Tom”));
coll.add(new Person(“hello”,22));
coll.add(false);
Collection coll1 = Arrays.asList(123,456,789);
//5. coll.retainAll(collName):取coll和collName的交集,并把交集返给当前集合(coll)
coll.retainAll(coll1);
System.out.println(coll);
//6. equals(Object obj):
Collection coll2 = new ArrayList();
coll2.add(new String(“Tom”));
coll2.add(123);
Collection coll3 = new ArrayList();
coll3.add(new String(“Tom”));
coll3.add(123);
System.out.println(coll2.equals(coll1));
//需要注意的是equals()方法对于String等类型,都是重写后的比较值,如果用的是Object类型的equals那就是比较地址。
//这样比较是要另外判断
System.out.println(coll3.equals(coll2));
}
}
集合转数组,数组转集合等等:
package com.holmes.java07;
import org.junit.Test;
import java.util.ArrayList;
import java.util.Arrays;
import java.util.Collection;
import java.util.List;
public class CollectionTest3 {
@Test
public void test(){
Collection coll = new ArrayList();
coll.add(123);
coll.add(456);
coll.add(new String(“Tom”));
coll.add(new Person(“hello”,22));
coll.add(false);
//7. hashCode():返回当前对象的哈希值。
System.out.println(coll.hashCode());
//8. 集合 ==》 数组 toArray():
Object[] arr = coll.toArray();
for (int i=0;i<arr.length;i++){
System.out.println(arr[i]);
}
//9. 数组 ==》 集合 Arrays.asList() 调用Arrays类的静态方法asList():
List list = Arrays.asList(new String[]{“AA”, “BB”, “CC”});
System.out.println(list);//[AA, BB, CC]
//int这种写法会将123,456整体认为是一个元素
List ints = Arrays.asList(new int[]{123, 456});
System.out.println(ints);
System.out.println(ints.size());//1
//Integer包装类写法就不会
List ints2 = Arrays.asList(new Integer[]{123, 456});
System.out.println(ints2.size());
//再个就是传入两个对象,那就是两个元素,不能混淆!
List ints4 = Arrays.asList(new String[]{“abc”,“efg”},new String[]{“hig”,“kml”});
System.out.println(ints4);
System.out.println(ints4.size());
List ints3 = Arrays.asList(123,456);
System.out.println(ints3);
//9. iterator(): 返回Iterator接口的实例,用于遍历集合元素。
System.out.println(coll.iterator());
}
}
============================================================================
Collection接口继承了java.lang.Iterable接口,该接口有一个iterator()方法,自然实现了Collection接口的结合都有一个iterator()方法,用来返回一个实现了Iterator接口的对象。

Iterator接口的方法有三个:
-
hasNext()方法:该方法用来判断是否还有下一个元素。
-
next()方法:指针下移,将下移以后集合位置上的元素返回。
-
iterator.remove()方法:这个是迭代器的remove,它也可以删除集合中的元素,但不同于集合的remove方法,一定注意。
集合遍历一般如下:
package com.holmes.java07;
import org.junit.Test;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class Testset {
@Test
public void test(){
Collection col = new ArrayList();
col.add(123);
col.add(456);
col.add(new String(“江山如画”));
col.add(false);
//使用iterator遍历集合内容:
Iterator iterator = col.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
}
//iterator的remove()方法:
Iterator iterator1= col.iterator();
while (iterator1.hasNext()){
Object obj = iterator1.next();
if (“江山如画”.equals(obj)){
//iterator.remove()方法:也可以移除集合中的元素
iterator1.remove();
}
}
System.out.println(col);
}
}
迭代器remove的两种错误用法:
-
开始不能一上来就用remove,不然开始指针还没指向第一个集合元素,无法确定移除谁?
-
再者就是调用了一次remove就不能调用第二次了,因为调用一次当前remove直接移除,再调用一次指针仍然指向已经移除的位置自然就会报错。
package com.holmes.java07;
import org.junit.Test;
import java.util.ArrayList;
import java.util.Collection;
import java.util.Iterator;
public class Testset {
@Test
public void test(){
Collection col = new ArrayList();
col.add(123);
col.add(456);
col.add(new String(“江山如画”));
col.add(false);
Iterator iterator= col.iterator();
//第一种情况:
//报错!java.lang.IllegalStateException
//while (iterator.hasNext()){
// iterator.remove();
// System.out.println(iterator.next());
//}
//第二种情况:
while (iterator.hasNext()){
iterator.remove();
System.out.println(iterator.next());
iterator.remove();//这里也是不对的!!报错!java.lang.IllegalStateException
}
}
}
迭代器执行原理:

通过for遍历集合:

同样也可以遍历数组:

========================================================================================
list接口下,类定义下,元素存储有序,且可重复。
list接口下有三个类:
-
ArrayList类:作为List接口的主要实现类;线程不安全的,效率高。底层使用Object[] elementData存储。
-
LinkedList类:底层使用双向链表存储,对于频繁的插入,删除操作,使用此类效率比ArrayList要高。
-
Vector类:作为List接口的古老实现类;线程安全的,效率低。底层使用Object[] elementData存储。

ArrayList类:作为List接口的主要实现类;线程不安全的,效率高。底层使用Object[] elementData存储。
ArrayList源码分析:
jdk 7:
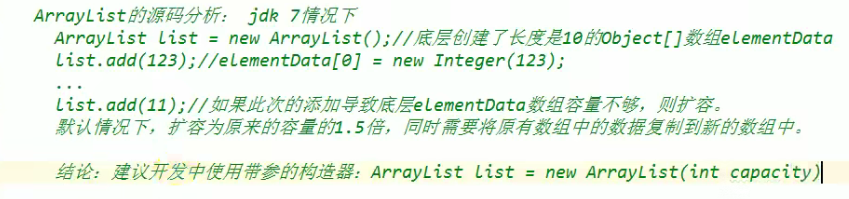
jdk 8:

LinkedList类:底层使用双向链表存储,对于频繁的插入,删除操作,使用此类效率比ArrayList要高。
因为双向链式,修改插入起来更加灵活。

Vector类:作为List接口的古老实现类;线程安全的,效率低。底层使用Object[] elementData存储。

package com.holmes.java07;
import org.junit.Test;
import java.util.*;
public class Testset {
@Test
public void test(){
ArrayList list = new ArrayList();
list.add(123);
list.add(456);
list.add(new String(“江山如画”));
list.add(false);
//list.add(int index , Object element):在index位置插入element元素
list.add(1,“AAA”);
System.out.println(list);
//list.addAll(int index , Collection elements):从index位置开始将elements中的所有元素添加刀集合中
List list2 = Arrays.asList(1,2,3,4);
list.addAll(3,list2);
System.out.println(list);
//list.indexOf(Object obj):查询obj在集合中的位置返回索引。
int index = list.indexOf(456);
System.out.println(index);
//list.lastIndexOf(Object obj):返回obj在当前集合中末次出现的位置。
list.add(0,“江山如画”);
int index2 = list.lastIndexOf(“江山如画”);
System.out.println(index2);
//list.remove(int index)方法:移除指定index位置的元素,并返回此元素。
Object obj = list.remove(2);
System.out.println(obj);
System.out.println(list);
//list.set(int index , Object element)方法:设置指定index位置的元素为element。
list.set(0,“三国演义”);
System.out.println(list);
//list.subList(int fromIndex , int toIndex):返回从fromIndex到toIndex位置的子集合。
List list1 = list.subList(1, 3);
System.out.println(list1);
//list.size():返回当前集合长度
System.out.println(list.size());
//list.get(Int index):返回当前index位置的元素
System.out.println(list.get(0));
}
}
=======================================================================================
set接口是Colection的子接口,它不允许包含相同的元素,同时它是无序的。
Set接口的实现类:
- HashSet:作为Set接口的主要实现类;线程不安全,可以存储null值。
LinkedHashSet:作为HashSet的子类;遍历其内部数据时,可以按照添加的顺序遍历。
- TreeSet:可以按照添加对象的指定属性,进行排序。
Set接口中没有额外定义的新方法,使用的都是Collection中声明过的方法。
Set接口的无序性:
- 无序性 不等于随机,存储数据在底层不是按照索引添加来确定顺序,而是根据数据的哈希值确定。
Set接口的不可重复性:
- 保证添加的元素按照equals()判断时,不能返回true。即:相同的元素只能添加一个。
add()方法添加元素的原理如下:(重要)
它是先查看存放位置是否相同,不相同直接添加;位置相同的话,就比较hash值相同不相同,hash值不相同就添加;如果hash值相同的话,再比较equals想不想同,不想相同就添加。

Set实现类HashSet的扩容方式:

6.2 Set中重写hashCode() 和 equals()方法
hashCode()方法作用详解:

Set容器中的对象,对应的类一定要重写equals()和hashCode(Object obj)方法,以实现对象相等规则。即 “相等的对象必须具有相等的散列码” 。

平时,我们创建的类,最好通过系统直接重写equals()和hashCode()方法:

class Person01 {
private String name;
private int age;
public Person01(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Person01 person01 = (Person01) o;
return age == person01.age && Objects.equals(name, person01.name);
}
@Override
public int hashCode() {
return Objects.hash(name, age);
}
}
6.3 HashSet 和 LinkedHashSet(HashSet的子类)
HashSet:作为Set接口的主要实现类;线程不安全,可以存储null值。
LinkedHashSet:作为HashSet的子类,每个数据还维护了两个引用,记录此数据前一个数据和后一个数据。
优点:对于频繁的遍历操作,LinkedHashSet效率高于HashSet。
package com.holmes.java07;
import org.junit.Test;
import java.util.*;
public class SetTest {
@Test
public void test(){
Set set = new HashSet();
set.add(456);
set.add(123);
set.add(“AA”);
set.add(“CC”);
System.out.println(set);
Set set2 = new LinkedHashSet();
set2.add(456);
set2.add(123);
set2.add(“AA”);
set2.add(“CC”);
System.out.println(set2);
}
}
首先,TreeSet不能添加不同类的对象!不然报错java.lang.ClassCastException。只能添加相同类的属性。
TreeSet遍历要配合重写toString方法,不然返回的就是地址值。
6.4.1 TreeSet 自然排序
自然排序就要对TreeSet中的类,让该类实现comparable接口,重写compareTo方法和toString()方法。
package com.holmes.java07;
import org.junit.Test;
import java.util.*;
public class SetTest {
@Test
public void test(){
TreeSet set = new TreeSet();
set.add(new User(“Tom”,22));
set.add(new User(“Aerry”,24));
set.add(new User(“Mim”,49));
set.add(new User(“Mim”,36));
set.add(new User(“Jack”,12));
Iterator iterator = set.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
}
}
}
class User implements Comparable{
private String name;
private int age;
public User(String name, int age) {
this.name = name;
this.age = age;
}
@Override
public int compareTo(Object o) {
//按照姓名从小到大排序
if (o instanceof User){
User user = (User)o;
int compare = this.name.compareTo(user.name);
//如果姓名大小相同,则就比较年龄
if (compare != 0){
return compare;
}else {
//这里有Integer的compare比较方法牢记!!
return Integer.compare(this.age,user.age);
}
}else {
throw new RuntimeException(“输入的类型不匹配”);
}
}
@Override
public String toString() {
return “User{” +
“name='” + name + ‘’’ +
“, age=” + age +
‘}’;
}
}
6.4.2 TreeSet 定制排序
定制排序就是定义comparator作为参数,传给TreeSet。
package com.holmes.java07;
import org.junit.Test;
import java.util.*;
public class SetTest {
@Test
public void test2(){
Comparator comparator = new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//按照年龄排序:
if (o1 instanceof User && o2 instanceof User){
User u1 = (User) o1;
User u2 = (User) o2;
return Integer.compare(u1.getAge(),u2.getAge());
}else {
throw new RuntimeException(“输入的数据类型不匹配”);
}
}
};
TreeSet set = new TreeSet(comparator);
set.add(new User(“Tom”,22));
set.add(new User(“Aerry”,24));
set.add(new User(“Mim”,49));
set.add(new User(“Mim”,36));
set.add(new User(“Jack”,12));
Iterator iterator = set.iterator();
while (iterator.hasNext()){
System.out.println(iterator.next());
}
}
}
class User {
private String name;
private int age;
public User(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return “User{” +
“name='” + name + ‘’’ +
“, age=” + age +
‘}’;
}
}
======================================================================
Map接口:双列数据,存储key-value对的数据 , 类似于数学中的y和x对应。
Map接口实现类:
- HashMap:作为Map的主要实现类;线程不安全的,效率高;能存储null的key和value。
LinkedHashMap:它是HashMap的子类,在原有的HashMap底层结构基础上,添加一对指针,指向前一个和后一个元素。对于频繁的遍历操作,此类执行效率高于HashMap。
- Hashtable:(注意这里时小写t) 作为古老的实现类;线程安全的,效率低;不能存储null的key和value。
Properties:常用来处理配置文件,key和value都是String类型。(例如jdbc的Properties文件)。
- TreeMap:保证按照添加的key-value对进行排序,实现排序遍历此时要考虑key的自然排序或定制排序。
Map 的结构原理:
-
Map中的key:无序的,不可重复的,使用Set存储所有的key。
-
Map中的value:无序的,可重复的,使用Collection存储所有value。
-
一个键值对:key-value构成一个Entry对象。Map中的entry:无序的,不可重复的,使用Set存储所有的entry。
JDK 7:

扩容问题,既然涉及到数组,必然有扩容的问题,HashMap默认的扩容方式:扩容为原来容量的2倍,并将原有的数据复制过来。
JDK 8:

LinkedHashMap的底层实现原理?

Map的基本操作方法:
package com.holmes.java07;
import org.junit.Test;
import java.util.HashMap;
import java.util.Map;
我的面试宝典:一线互联网大厂Java核心面试题库
以下是我个人的一些做法,希望可以给各位提供一些帮助:
整理了很长一段时间,拿来复习面试刷题非常合适,其中包括了Java基础、异常、集合、并发编程、JVM、Spring全家桶、MyBatis、Redis、数据库、中间件MQ、Dubbo、Linux、Tomcat、ZooKeeper、Netty等等,且还会持续的更新…可star一下!

283页的Java进阶核心pdf文档
Java部分:Java基础,集合,并发,多线程,JVM,设计模式
数据结构算法:Java算法,数据结构
开源框架部分:Spring,MyBatis,MVC,netty,tomcat
分布式部分:架构设计,Redis缓存,Zookeeper,kafka,RabbitMQ,负载均衡等
微服务部分:SpringBoot,SpringCloud,Dubbo,Docker

还有源码相关的阅读学习

扩容问题,既然涉及到数组,必然有扩容的问题,HashMap默认的扩容方式:扩容为原来容量的2倍,并将原有的数据复制过来。
JDK 8:
LinkedHashMap的底层实现原理?
Map的基本操作方法:
package com.holmes.java07;
import org.junit.Test;
import java.util.HashMap;
import java.util.Map;
我的面试宝典:一线互联网大厂Java核心面试题库
以下是我个人的一些做法,希望可以给各位提供一些帮助:
整理了很长一段时间,拿来复习面试刷题非常合适,其中包括了Java基础、异常、集合、并发编程、JVM、Spring全家桶、MyBatis、Redis、数据库、中间件MQ、Dubbo、Linux、Tomcat、ZooKeeper、Netty等等,且还会持续的更新…可star一下!
[外链图片转存中…(img-boZBx3zd-1715629574025)]
283页的Java进阶核心pdf文档
Java部分:Java基础,集合,并发,多线程,JVM,设计模式
数据结构算法:Java算法,数据结构
开源框架部分:Spring,MyBatis,MVC,netty,tomcat
分布式部分:架构设计,Redis缓存,Zookeeper,kafka,RabbitMQ,负载均衡等
微服务部分:SpringBoot,SpringCloud,Dubbo,Docker
[外链图片转存中…(img-Jpz7rLlu-1715629574026)]
还有源码相关的阅读学习
[外链图片转存中…(img-tnpQtkKA-1715629574026)]















 625
625

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









