







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注Java)

正文
- Base of nanosecond timings, to avoid wrapping
*/
private static final long NANO_ORIGIN = System.nanoTime();
/**
- Returns nanosecond time offset by origin
*/
final static long now() {
return System.nanoTime() - NANO_ORIGIN;
}
/**
-
Sequence number to break scheduling ties, and in turn to guarantee FIFO order among tied
-
entries.
*/
private static final AtomicLong sequencer = new AtomicLong(0);
/**
- Sequence number to break ties FIFO
*/
private final long sequenceNumber;
/**
- The time the task is enabled to execute in nanoTime units
*/
private final long time;
private final T item;
public DelayItem(T submit, long timeout) {
this.time = now() + timeout;
this.item = submit;
this.sequenceNumber = sequencer.getAndIncrement();
}
public T getItem() {
return this.item;
}
public long getDelay(TimeUnit unit) {
long d = unit.convert(time - now(), TimeUnit.NANOSECONDS); return d;
}
public int compareTo(Delayed other) {
if (other == this) // compare zero ONLY if same object return 0;
if (other instanceof DelayItem) {
DelayItem x = (DelayItem) other;
long diff = time - x.time;
if (diff < 0) return -1;
else if (diff > 0) return 1;
else if (sequenceNumber < x.sequenceNumber) return -1;
else
return 1;
}
long d = (getDelay(TimeUnit.NANOSECONDS) - other.getDelay(TimeUnit.NANOSECONDS));
return (d == 0) ?0 😦(d < 0) ?-1 :1);
}
}
以下是 Cache 的实现,包括了 put 和 get 方法
import javafx.util.Pair;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ConcurrentMap;
import java.util.concurrent.DelayQueue;
import java.util.concurrent.TimeUnit;
import java.util.logging.Level;
import java.util.logging.Logger;
public class Cache<K, V> {
private static final Logger LOG = Logger.getLogger(Cache.class.getName());
private ConcurrentMap<K, V> cacheObjMap = new ConcurrentHashMap<K, V>();
private DelayQueue<DelayItem<Pair<K, V>>> q = new DelayQueue<DelayItem<Pair<K, V>>>();
private Thread daemonThread;
public Cache() {
Runnable daemonTask = new Runnable() {
public void run() {
daemonCheck();
}
};
daemonThread = new Thread(daemonTask);
daemonThread.setDaemon(true);
daemonThread.setName(“Cache Daemon”);
daemonThread.start();
}
private void daemonCheck() {
if (LOG.isLoggable(Level.INFO)) LOG.info(“cache service started.”);
for (; ; ) {
try {
DelayItem<Pair<K, V>> delayItem = q.take();
if (delayItem != null) {
// 超时对象处理
Pair<K, V> pair = delayItem.getItem();
cacheObjMap.remove(pair.first, pair.second); // compare and remove
}
} catch (InterruptedException e) {
if (LOG.isLoggable(Level.SEVERE)) LOG.log(Level.SEVERE, e.getMessage(), e);
break;
}
}
if (LOG.isLoggable(Level.INFO)) LOG.info(“cache service stopped.”);
}
// 添加缓存对象
public void put(K key, V value, long time, TimeUnit unit) {
V oldValue = cacheObjMap.put(key, value);
if (oldValue != null) q.remove(key);
long nanoTime = TimeUnit.NANOSECONDS.convert(time, unit);
q.put(new DelayItem<Pair<K, V>>(new Pair<K, V>(key, value), nanoTime));
}
public V get(K key) {
return cacheObjMap.get(key);
}
}
测试 main 方法:
// 测试入口函数
public static void main(String[] args) throws Exception {
Cache<Integer, String> cache = new Cache<Integer, String>();
cache.put(1, “aaaa”, 3, TimeUnit.SECONDS);
Thread.sleep(1000 * 2);
{
String str = cache.get(1);
System.out.println(str);
}
Thread.sleep(1000 * 2);
{
String str = cache.get(1);
System.out.println(str);
}
}
输出结果为:
aaaa
null
我们看到上面的结果,如果超过延时的时间,那么缓存中数据就会自动丢失,获得就为 null。
● 非阻塞队列
首先我们要简单的理解下什么是非阻塞队列:
与阻塞队列相反,非阻塞队列的执行并不会被阻塞,无论是消费者的出队,还是生产者的入队。在底层,非阻塞队列使用的是 CAS(compare and swap)来实现线程执行的非阻塞。
● 非阻塞队列简单操作, 与阻塞队列相同,非阻塞队列中的常用方法,也是出队和入队。
● offer():Queue 接口继承下来的方法,实现队列的入队操作,不会阻碍线程的执行,插入成功返回 true; 出队方法:
● poll():移动头结点指针,返回头结点元素,并将头结点元素出队;队列为空,则返回 null;
● peek():移动头结点指针,返回头结点元素,并不会将头结点元素出队;队列为空,则返回 null;
首先我们需要了解悲观锁和乐观锁
悲观锁:假定并发环境是悲观的,如果发生并发冲突,就会破坏一致性,所以要通过独占锁彻底禁止冲突发生。
有一个经典比喻,“如果你不锁门,那么捣蛋鬼就回闯入并搞得一团糟”,所以“你只能一次打开门放进一个人,才能时刻盯紧他”。
乐观锁:假定并发环境是乐观的,即虽然会有并发冲突,但冲突可发现且不会造成损害,所以,可以不加任何保护,等发现并发冲突后再决定放弃操作还是重试。
可类比的比喻为,“如果你不锁门,那么虽然捣蛋鬼会闯入,但他们一旦打算破坏你就能知道”,所以“你大可以放进所有人,等发现他们想破坏的时候再做决定”。
通常认为乐观锁的性能比悲观所更高,特别是在某些复杂的场景。
这主要由于悲观锁在加锁的同时,也会把某些不会造成破坏的操作保护起来;
而乐观锁的竞争则只发生在最小的并发冲突处,如果用悲观锁来理解,就是“锁的粒度最小”。
但乐观锁的设计往往比较复杂,因此,复杂场景下还是多用悲观锁。
首先保证正确性,有必要的话,再去追求性能。
乐观锁的实现往往需要硬件的支持,多数处理器都都实现了一个CAS指令,实现“Compare And Swap”的语义(这里的swap是“换入”,也就是set),构成了基本的乐观锁。
CAS包含3个操作数:
需要读写的内存位置V
进行比较的值A
拟写入的新值B
当且仅当位置V的值等于A时,CAS才会通过原子方式用新值B来更新位置V的值;
否则不会执行任何操作。
无论位置V的值是否等于A,都将返回V原有的值。
一个有意思的事实是,“使用CAS控制并发”与“使用乐观锁”并不等价。
CAS只是一种手段,既可以实现乐观锁,也可以实现悲观锁。
乐观、悲观只是一种并发控制的策略。
七、ConcurrentLinkedQueue非阻塞无界链表队列
ConcurrentLinkedQueue是一个线程安全的队列,基于链表结构实现,是一个无界队列,理论上来说队列的长度可以无限扩大。
与其他队列相同,ConcurrentLinkedQueue也采用的是先进先出(FIFO)入队规则,对元素进行排序。
当我们向队列中添加元素时,新插入的元素会插入到队列的尾部;而当我们获取一个元素时,它会从队列的头部中取出。
因为ConcurrentLinkedQueue是链表结构,所以当入队时,插入的元素依次向后延伸,形成链表;而出队时,则从链表的第一个元素开始获取,依次递增;
值得注意的是,在使用ConcurrentLinkedQueue时,如果涉及到队列是否为空的判断,切记不可使用size()==0的做法,因为在size()方法中,是通过遍历整个链表来实现的,在队列元素很多的时候,size()方法十分消耗性能和时间,只是单纯的判断队列为空使用isEmpty()即可。
public class ConcurrentLinkedQueueTest {
public static int threadCount = 10;
public static ConcurrentLinkedQueue queue = new ConcurrentLinkedQueue();
static class Offer implements Runnable {
public void run() {
//不建议使用 queue.size()==0,影响效率。可以使用!queue.isEmpty()
if (queue.size() == 0) {
String ele = new Random().nextInt(Integer.MAX_VALUE) + “”;
queue.offer(ele);
System.out.println(“入队元素为” + ele);
}
}
}
static class Poll implements Runnable {
public void run() {
if (!queue.isEmpty()) {
String ele = queue.poll();
System.out.println(“出队元素为” + ele);
}
}
}
public static void main(String[] agrs) {
ExecutorService executorService = Executors.newFixedThreadPool(4);
for (int x = 0; x < threadCount; x++) {
executorService.submit(new Offer());
executorService.submit(new Poll());
}
executorService.shutdown();
}
}
一种输出:
入队元素为313732926
出队元素为313732926
入队元素为812655435
出队元素为812655435
入队元素为1893079357
出队元素为1893079357
入队元素为1137820958
出队元素为1137820958
入队元素为1965962048
出队元素为1965962048
出队元素为685567162
入队元素为685567162
出队元素为1441081163
入队元素为1441081163
出队元素为1627184732
入队元素为1627184732
ConcurrentLinkedQuere类图

如图ConcurrentLinkedQueue中有两个volatile类型的Node节点分别用来存在列表的首尾节点,其中head节点存放链表第一个item为null的节点,tail则并不是总指向最后一个节点。Node节点内部则维护一个变量item用来存放节点的值,next用来存放下一个节点,从而链接为一个单向无界列表。
public ConcurrentLinkedQueue(){
head=tail=new Node(null);
}
如上代码初始化时候会构建一个 item 为 NULL 的空节点作为链表的首尾节点。
Offer 操作offer 操作是在链表末尾添加一个元素,下面看看实现原理。
public boolean offer(E e) {
//e 为 null 则抛出空指针异常
checkNotNull(e);
//构造 Node 节点构造函数内部调用 unsafe.putObject,后面统一讲
final Node newNode = new Node(e);
//从尾节点插入
for (Node t = tail, p = t; ; ) {
Node q = p.next;
//如果 q=null 说明 p 是尾节点则插入
if (q == null) {
//cas 插入(1)
if (p.casNext(null, newNode)) {
//cas 成功说明新增节点已经被放入链表,然后设置当前尾节点(包含 head,1,3,5.。。个节点为尾节点)
if (p != t)// hop two nodes at a time
casTail(t, newNode); // Failure is OK. return true;
}
// Lost CAS race to another thread; re-read next
} else if (p == q)//(2)
//多线程操作时候,由于 poll 时候会把老的 head 变为自引用,然后 head 的 next 变为新 head,所以这里需要
//重新找新的 head,因为新的 head 后面的节点才是激活的节点
p = (t != (t = tail)) ? t : head;
else
// 寻找尾节点(3)
p = (p != t && t != (t = tail)) ? t : q;
}
}
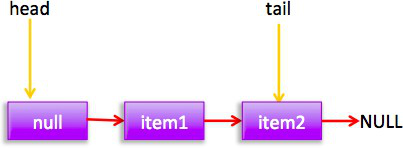
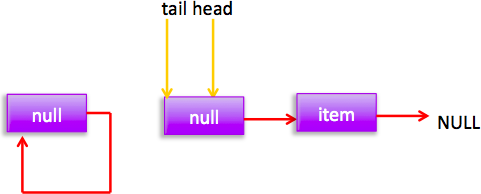
从构造函数知道一开始有个item为null的哨兵节点,并且head和tail都是指向这个节点。
如图首先查找尾节点,
qnull,p就是尾节点,
所以执行p.casNext通过cas设置p的next为新增节点,
这时候pt所以不重新设置尾节点为当前新节点。
由于多线程可以调用offer方法,所以可能两个线程同时执行到了(1)进行cas,
那么只有一个会成功(假如线程1成功了),成功后的链表为:

失败的线程会循环一次这时候指针为:

这时候会执行(3)所以 p=q,然后在循环后指针位置为:

所以没有其他线程干扰的情况下会执行(1)执行 cas 把新增节点插入到尾部,没有干扰的情况下线程 2 cas 会成功,然后去更新尾节点 tail,由于 p!=t 所以更新。这时候链表和指针为:
假如线程 2cas 时候线程 3 也在执行,那么线程 3 会失败,循环一次后,线程 3 的节点状态为:

这时候 p!=t ;并且 t 的原始值为 told,t 的新值为 tnew ,所以 told!=tnew,所以 p=tnew=tail
然后在循环一下后节点状态:

q==null 所以执行(1)。
现在就差 p==q 这个分支还没有走,这个要在执行 poll 操作后才会出现这个情况。poll 后会存在下面的状态
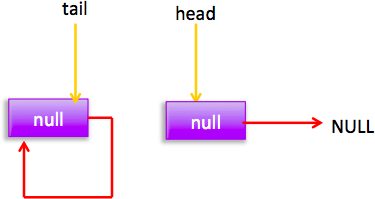
这个时候添加元素时候指针分布为:
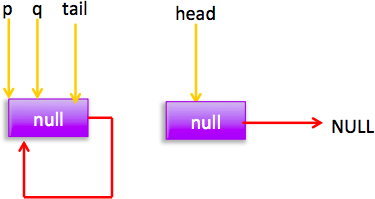
所以会执行(2)分支 结果 p=head,然后循环,循环后指针分布:
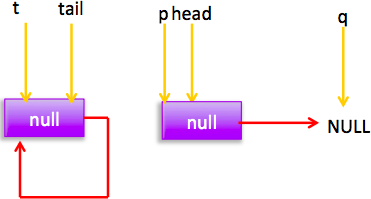
所以执行(1),然后 p!=t 所以设置 tail 节点。现在分布图:
自引用的节点会被垃圾回收掉。
● add 操作
add操作是在链表末尾添加一个元素,下面看看实现原理。
其实内部调用的还是 offer
public boolean add(E e) {
return offer(e);
}
● poll 操作
poll 操作是在链表头部获取并且移除一个元素,下面看看实现原理。
public E poll() {
restartFromHead:
// 死 循 环
for (; ; ) {
//死循环
for (Node h = head, p = h, q;
; ) {
//保存当前节点值
E item = p.item;
//当前节点有值则 cas 变为 null(1)
if (item != null && p.casItem(item, null)){
//cas 成功标志当前节点以及从链表中移除
if (p != h) // 类似 tail 间隔 2 设置一次头节点(2)
updateHead(h, ((q = p.next) != null) ? q : p);
return item;
}
//当前队列为空则返回 null(3)
else if ((q = p.next) == null) {
updateHead(h, p);
return null;
}
//自引用了,则重新找新的队列头节点(4)
else if (p == q)
continue restartFromHead;
else//(5)
p = q;
}
}
}
final void updateHead(Node h,Node p){
if(h!=p&&casHead(h,p))
h.lazySetNext(h);
}
● 当队列为空时候:

可知执行(3)这时候有两种情况,第一没有其他线程添加元素时候(3)结果为 true 然后因为 h!=p 为 false 所以直接返回 null。第二在执行 q=p.next 前,其他线程已经添加了一个元素到队列,这时候(3)返回 false,然后执行(5)p=q,然后循环后节点分布:

这时候执行(1)分支,进行 cas 把当前节点值值为 null,同时只有一个线程会成功,cas 成功 标示该节点从队列中移除了,然后 p!=h,调用 updateHead 方法,参数为 h,p;h!=p 所以把 p 变为当前链表 head 节点,然后 h 节点的 next 指向自己。现在状态为:
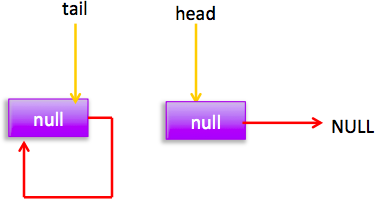
cas 失败 后 会再次循环,这时候分布图为:

这时候执行(3)返回 null.
现在还有个分支(4)没有执行过,那么什么时候会执行那?

这时候执行(1)分支,进行 cas 把当前节点值值为 null,同时只有一个线程 A 会成功,cas 成功 标示该节点从队列中移除了,然后 p!=h,调用 updateHead 方法,假如执行 updateHead 前另外一个线程 B 开始 poll 这时候它 p 指向为原来的 head 节点,然后当前线程 A 执行 updateHead 这时候 B 线程链表状态为:
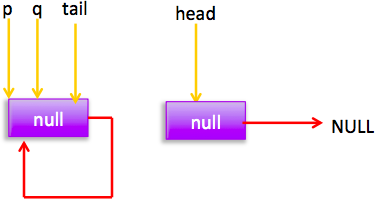
所以会执行(4)重新跳到外层循环,获取当前 head,现在状态为:
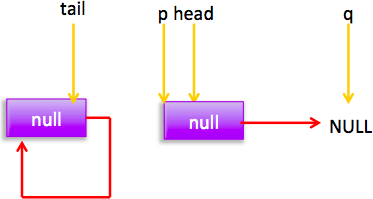
● peek 操作
peek 操作是获取链表头部一个元素(只读取不移除),下面看看实现原理。
代码与 poll 类似,只是少了 castItem.并且 peek 操作会改变 head 指向,offer 后 head 指向哨兵节点,第一次 peek 后 head 会指向第一个真的节点元素。
public E peek() {
restartFromHead:
for (; ; ) {
for (Node h = head, p = h, q; ; ) {
E item = p.item;
if (item != null || (q = p.next) == null) {
updateHead(h, p);
return item;
} else if (p == q)
continue restartFromHead;
else
p = q;
}
}
}
● size 操作
获取当前队列元素个数,在并发环境下不是很有用,因为使用 CAS 没有加锁所以从调用 size 函数到返回结果期间有可能增删元素,导致统计的元素个数不精确。
public int size() {
int count = 0;
for (Node p = first(); p != null; p = succ§)
if (p.item != null)
// 最大返回 Integer.MAX_VALUE
if (++count == Integer.MAX_VALUE) break;
return count;
}
//获取第一个队列元素(哨兵元素不算),没有则为 null
public void Node first() {
restartFromHead:
for (; ; ) {
for (Node h = head, p = h, q; ; ) {
boolean hasItem = (p.item != null);
if (hasItem || (q = p.next) == null) {
updateHead(h, p);
return hasItem ? p : null;
} else if (p == q)
continue restartFromHead;
else
p = q;
}
}
}
//获取当前节点的 next 元素,如果是自引入节点则返回真正头节点
public void final Node succ(Node p) {
Node next = p.next;
return (p == next) ? head : next;
}
● remove 操作
如果队列里面存在该元素则删除该元素,如果存在多个则删除第一个,并返回 true,否则返回 false
public boolean remove(Object o){
//查找元素为空,直接返回 false
if(o==null)return false;
Node pred=null;
for(Node p=first();p!=null;p=succ§){
E item=p.item;
//相等则使用 cas 值 null,同时一个线程成功,失败的线程循环查找队列中其他元素是否有匹配的。
if(item!=null&&o.equals(item)&&p.casItem(item,null)){
//获取 next 元素
Node next=succ§;
//如果有前驱节点,并且 next 不为空则链接前驱节点到 next,
if(pred!=null&&next!=null)
pred.casNext(p,next);
return true;
}
pred=p;
}
return false;
}
● contains 操作
判断队列里面是否含有指定对象,由于是遍历整个队列,所以类似 size 不是那么精确,有可能调用该方法时候元素还在队列里面,但是遍历过程中才把该元素删除了,那么就会返回 false.
public boolean contains(Object o) {
if (o == null) return false;
for (Node p = first(); p != null; p = succ§) {
E item = p.item;
if (item != null && o.equals(item)) return true;
}
return false;
}
关于ConcurrentLinkedQuere的offer方法有意思的问题:
offer 中有个 判断 t != (t = tail)假如 t=node1;tail=node2;并且 node1!=node2 那么这个判断是 true 还是 false 那,答案是 true,这个判断是看当前 t 是不是和 tail 相等,相等则返回 true 否者为 false,但是无论结果是啥执行后 t 的值都是 tail。
下面从字节码来分析下为啥。
举一个例子:
public static void main(String[] args){
int t=2;
int tail=3;
System.out.println(t!=(t=tail));
}
结果为:true
我们从上面main方法的字节码文件中分析
一开始栈为空:
栈
第0行指令作用是把值2入栈栈顶元素为2

栈
第1行指令作用是将栈顶int类型值保存到局部变量t中
栈
第2行指令作用是把值3入栈栈顶元素为3

栈
第3行指令作用是将栈顶int类型值保存到局部变量tail中。
栈
第4调用打印命令
第7行指令作用是把变量t中的值入栈

栈
第8行指令作用是把变量tail中的值入栈

栈
现在栈里面的元素为3、2,并且3位于栈顶
第9行指令作用是当前栈顶元素入栈,所以现在栈内容3,3,2

栈
第10行指令作用是把栈顶元素存放到t,现在栈内容3,2

栈
一线互联网大厂Java核心面试题库

正逢面试跳槽季,给大家整理了大厂问到的一些面试真题,由于文章长度限制,只给大家展示了部分题目,更多Java基础、异常、集合、并发编程、JVM、Spring全家桶、MyBatis、Redis、数据库、中间件MQ、Dubbo、Linux、Tomcat、ZooKeeper、Netty等等已整理上传,感兴趣的朋友可以看看支持一波!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
栈
第1行指令作用是将栈顶int类型值保存到局部变量t中
栈
第2行指令作用是把值3入栈栈顶元素为3
栈
第3行指令作用是将栈顶int类型值保存到局部变量tail中。
栈
第4调用打印命令
第7行指令作用是把变量t中的值入栈
栈
第8行指令作用是把变量tail中的值入栈
栈
现在栈里面的元素为3、2,并且3位于栈顶
第9行指令作用是当前栈顶元素入栈,所以现在栈内容3,3,2
栈
第10行指令作用是把栈顶元素存放到t,现在栈内容3,2
栈
一线互联网大厂Java核心面试题库
[外链图片转存中…(img-B51IK2vu-1713544796825)]
正逢面试跳槽季,给大家整理了大厂问到的一些面试真题,由于文章长度限制,只给大家展示了部分题目,更多Java基础、异常、集合、并发编程、JVM、Spring全家桶、MyBatis、Redis、数据库、中间件MQ、Dubbo、Linux、Tomcat、ZooKeeper、Netty等等已整理上传,感兴趣的朋友可以看看支持一波!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)
[外链图片转存中…(img-2QgQUlao-1713544796826)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!














 698
698











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









