







 文章分享了互联网行业的流行技术学习大纲,包括性能调优、分布式实战、架构师基础知识、技术框架解析、面试技巧等内容,同时介绍了JavaNIO中的缓冲区概念,以及直接与非直接缓冲区的区别,附带了系统化的Java面试题和核心架构学习资源。
文章分享了互联网行业的流行技术学习大纲,包括性能调优、分布式实战、架构师基础知识、技术框架解析、面试技巧等内容,同时介绍了JavaNIO中的缓冲区概念,以及直接与非直接缓冲区的区别,附带了系统化的Java面试题和核心架构学习资源。
分享
首先分享一份学习大纲,内容较多,涵盖了互联网行业所有的流行以及核心技术,以截图形式分享:
(亿级流量性能调优实战+一线大厂分布式实战+架构师筑基必备技能+设计思想开源框架解读+性能直线提升架构技术+高效存储让项目性能起飞+分布式扩展到微服务架构…实在是太多了)
其次分享一些技术知识,以截图形式分享一部分:
Tomcat架构解析:

算法训练+高分宝典:

Spring Cloud+Docker微服务实战:

最后分享一波面试资料:
切莫死记硬背,小心面试官直接让你出门右拐
1000道互联网Java面试题:

Java高级架构面试知识整理:

数组合并
关于数组合并,我们还会经常用到,commons-lang3.jar包中的ArrayUtils类的addAll(),其功能是添加一个字节数组或者添加一个字节到原先的字节数组中。
public static byte[] addAll(byte[] array1, byte… array2) {
if (array1 == null) {
return clone(array2);
} else if (array2 == null) {
return clone(array1);
} else {
byte[] joinedArray = new byte[array1.length + array2.length];
System.arraycopy(array1, 0, joinedArray, 0, array1.length);
System.arraycopy(array2, 0, joinedArray, array1.length, array2.length);
return joinedArray;
}
}
=======================================================================
在开始之前,我觉得有必要充分理解一下缓冲区的作用及使用方法。
在NIO技术的缓冲区中,存在4个核心技术点,分别是:
❑capacity(容量)
❑limit(限制)
❑position(位置)
❑mark(标记)
这4个技术点之间值的大小关系如下:0≤mark≤position≤limit≤capacity。
由于ByteBuffer、CharBuffer、DoubleBuffer、FloatBuffer、IntBuffer、LongBuffer和ShortBuffer是抽象类,wrap()就相当于创建这些缓冲区的工厂方法。最终对应的类型分别为java.io.HeapByteBuffer、java.io.HeapCharBuffer、java.io.HeapDoubleBuffe等。
limit
限制(limit)代表第一个不应该读取或写入元素的index,缓冲区的limit不能为负,并且limit不能大于其capacity。如果position大于新的limit,则将position设置为新的limit。如果mark已定义且大于新的limit,则丢弃该mark。
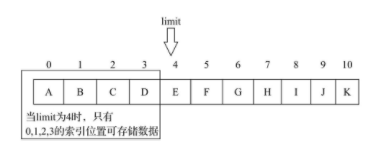
public class BufferTest {
@Test
public void bufferLimitTest(){
char[] charArray = new char[]{‘a’,‘b’,‘c’,‘d’,‘e’};
CharBuffer buffer = CharBuffer.wrap(charArray);
System.out.println(“A capacity()=” + buffer.capacity() + “,limit=”+buffer.limit());
buffer.limit(3);
System.out.println(“B capacity()=” + buffer.capacity() + “,limit=”+buffer.limit());
buffer.put(0,‘o’);
buffer.put(1,‘p’);
buffer.put(2,‘q’);
buffer.put(3,‘r’);//index == 3,第一个不可读不可写的索引
buffer.put(4,‘s’);
buffer.put(5,‘t’);
buffer.put(6,‘u’);
}
}
position(位置)
什么是位置呢?它代表“下一个”要读取或写入元素的index(索引),缓冲区的position(位置)不能为负,并且position不能大于其limit。如果mark已定义且大于新的position,则丢弃该mark。
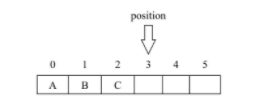
@Test
public void bufferLimitTest(){
char[] charArray = new char[]{‘a’,‘b’,‘c’,‘d’,‘e’};
CharBuffer buffer = CharBuffer.wrap(charArray);
System.out.println(“A capacity()=” + buffer.capacity() + “,limit=”+buffer.limit()+ “,position=”+buffer.position());
buffer.limit(3);
System.out.println(“B capacity()=” + buffer.capacity() + “,limit=”+buffer.limit() + “,position=”+buffer.position());
buffer.put(0,‘o’);
buffer.put(1,‘p’);
buffer.put(2,‘q’);
buffer.put(3,‘r’);//index == 3,第一个不可读不可写的索引
buffer.put(4,‘s’);
buffer.put(5,‘t’);
buffer.put(6,‘u’);
}
运行结果如下:
A capacity()=5,limit=5,position=0
B capacity()=5,limit=5,position=2
a
b
Z
d
e
mark(标记)
标记有什么作用呢?缓冲区的标记是一个索引,在调用reset()方法时,会将缓冲区的position位置重置为该索引。标记(mark)并不是必需的。定义mark时,不能将其定义为负数,并且不能让它大于position。
-
如果定义了mark,则在将position或limit调整为小于该mark的值时,该mark被丢弃,丢弃后mark的值是-1。
-
如果未定义mark,那么调用reset()方法将导致抛出
InvalidMarkException异常。
简而言之,buffer的reset()方法,可以根据mark()的位置,把位置重置为mark()调用时的位置。
其他的一些关系:
- 如果position大于新的limit,则position的值就是新limit的值。
非直接缓冲区
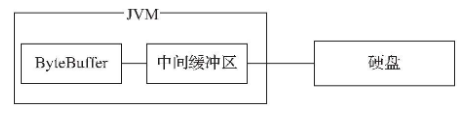
通过ByteBuffer向硬盘存取数据时是需要将数据暂存在JVM的中间缓冲区,如果有频繁操作数据的情况发生,则在每次操作时都会将数据暂存在JVM的中间缓冲区,再交给ByteBuffer处理,这样做就大大降低软件对数据的吞吐量,提高内存占有率,造成软件运行效率降低,这就是非直接缓冲区保存数据的过程,所以非直接缓冲区的这个弊端就由直接缓冲区解决了。
直接缓冲区
Java核心架构进阶知识点
面试成功其实都是必然发生的事情,因为在此之前我做足了充分的准备工作,不单单是纯粹的刷题,更多的还会去刷一些Java核心架构进阶知识点,比如:JVM、高并发、多线程、缓存、Spring相关、分布式、微服务、RPC、网络、设计模式、MQ、Redis、MySQL、设计模式、负载均衡、算法、数据结构、kafka、ZK、集群等。而这些也全被整理浓缩到了一份pdf——《Java核心架构进阶知识点整理》,全部都是精华中的精华,本着共赢的心态,好东西自然也是要分享的



内容颇多,篇幅却有限,这就不在过多的介绍了,大家可根据以上截图自行脑补
[外链图片转存中…(img-49G2b9E4-1714958943935)]
[外链图片转存中…(img-s6EMi8O5-1714958943935)]
内容颇多,篇幅却有限,这就不在过多的介绍了,大家可根据以上截图自行脑补















 1925
1925











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









