







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注Java)

正文
-
3.5.Vuex中如何异步修改状态
-
3.6.Vuex中actions和mutations的区别
-
3.7.怎么在组件中批量使用Vuex的state状态?
-
3.8.Vuex中状态是对象时,使用时要注意什么?
-
四、Router
-
- 4.1.vue-router 路由模式有几种
-
4.2.vue-router如何定义嵌套路由
-
4.3.vue-router有哪几种导航钩子?
-
4.4. $ route和$ router的区别
-
4.5.路由之间跳转的方式
-
4.6.active-class是哪个组件的属性
-
4.7.vue-router实现路由懒加载(动态加载路由)
-
4.8.怎么定义vue-router的动态路由以及如何获取传过来的动态参数?
==============================================================
之前博主有分享过Vue学习由浅到深的文章(Vue学习之从入门到神经) 现在Vue学的好的话马内真的不必后端差 所以今天博主就汇总下有关Vue的相关面试题
========================================================================

核心实现类:
Observer : 它的作用是给对象的属性添加 getter 和 setter,用于依赖收集和派发更新
Dep : 用于收集当前响应式对象的依赖关系,每个响应式对象包括子对象都拥有一个 Dep 实例(里面 subs 是 Watcher 实例数组),当数据有变更时,会通过 dep.notify()通知各个 watcher。
Watcher : 观察者对象 , 实例分为渲染 watcher (render watcher),计算属性 watcher (computed watcher),侦听器 watcher(user watcher)三种
Watcher 和 Dep 的关系:
watcher 中实例化了 dep 并向 dep.subs 中添加了订阅者,dep 通过 notify 遍历了 dep.subs 通知每个 watcher 更新。
依赖收集:
initState 时,对 computed 属性初始化时,触发 computed watcher 依赖收集
initState 时,对侦听属性初始化时,触发 user watcher 依赖收集
render()的过程,触发 render watcher 依赖收集
re-render 时,vm.render()再次执行,会移除所有 subs 中的 watcer 的订阅,重新赋值。
派发更新:
组件中对响应的数据进行了修改,触发 setter 的逻辑
调用 dep.notify()
遍历所有的 subs(Watcher 实例),调用每一个 watcher 的 update 方法。
原理:
当创建 Vue 实例时,vue 会遍历 data 选项的属性,利用 Object.defineProperty 为属性添加 getter 和 setter 对数据的读取进行劫持(getter 用来依赖收集,setter 用来派发更新),并且在内部追踪依赖,在属性被访问和修改时通知变化。
每个组件实例会有相应的 watcher 实例,会在组件渲染的过程中记录依赖的所有数据属性(进行依赖收集,还有 computed watcher,user watcher 实例),之后依赖项被改动时,setter 方法会通知依赖与此 data 的 watcher 实例重新计算(派发更新),从而使它关联的组件重新渲染。
一句话总结:
vue.js 采用数据劫持结合发布-订阅模式,通过 Object.defineproperty 来劫持各个属性的 setter,getter,在数据变动时发布消息给订阅者,触发响应的监听回调
易用: 简单,易学,上手快
灵活: (渐进式)不断繁荣的生态系统,可以在一个库和一套完整框架之间自如伸缩。
高效: 20kB min+gzip 运行大小;超快虚拟 DOM;最省心的优化
双向绑定:开发效率高
基于组件的代码共享
Web项目工程化,增加可读性、可维护性
Vue.js 2.0 采用数据劫持(Proxy 模式)结合发布者-订阅者模式(PubSub 模式)的方式,通过 Object.defineProperty()来劫持各个属性的 setter,getter,在数据变动时发布消息给订阅者,触发相应的监听回调。
每个组件实例都有相应的watcher程序实例,它会在组件渲染的过程中把属性记录为依赖,之后当依赖项的setter被调用时,会通知watcher重新计算,从而致使它关联的组件得以更新。
Vue.js 3.0, 放弃了Object.defineProperty ,使用更快的ES6原生 Proxy (访问对象拦截器, 也称代理器)
步骤:
1.需要observe的数据对象进行递归遍历,包括子属性对象的属性,都加上setter和getter这样的话,给这个对象的某个值赋值,就会触发setter,那么就能监听到了数据变化
2.compile解析模板指令,将模板中的变量替换成数据,然后初始化渲染页面视图,并将每个指令对应的节点绑定更新函数,添加监听数据的订阅者,一旦数据有变动,收到通知,更新视图
3.Watcher订阅者是Observer和Compile之间通信的桥梁,主要做的事情是: ①在自身实例化时往属性订阅器(dep)里面添加自己 ②自身必须有一个update()方法 ③待属性变动dep.notice()通知时,能调用自身的update()方法,并触发Compile中绑定的回调,则功成身退。
4.MVVM作为数据绑定的入口,整合Observer、Compile和Watcher三者,通过Observer来监听自己的model数据变化,通过Compile来解析编译模板指令,最终利用Watcher搭起Observer和Compile之间的通信桥梁,达到数据变化 -> 视图更新;视图交互变化(input) -> 数据model变更的双向绑定效果。
比如现在需要监控data中, obj.a 的变化。Vue中监控对象属性的变化你可以这样:
watch: {
obj: {
handler (newValue, oldValue) {
console.log(‘obj changed’)
},
deep: true
}
deep属性表示深层遍历,但是这么写会监控obj的所有属性变化,并不是我们想要的效果,所以做点修改:
watch: {
‘obj.a’: {
handler (newName, oldName) {
console.log(‘obj.a changed’)
}
}
}
还有一种方法,可以通过computed 来实现,只需要:
computed: {
a1 () {
return this.obj.a
}
}
利用计算属性的特性来实现,当依赖改变时,便会重新计算一个新值。
1.5.Vue.js 3.0 放弃defineProperty, 使用Proxy的原因
Object.defineProperty缺陷
1.监控到数组下标的变化时,开销很大。所以Vue.js放弃了下标变化的检测;
2.Object.defineProperty只能劫持对象的属性,而Proxy是直接代理对象。3.Object.defineProperty需要遍历对象的每个属性,如果属性值也是对象,则需要深度遍历。而 Proxy 直接代理对象,不需要遍历操作。
4.Object.defineProperty对新增属性需要手动进行Observe。vue2时需要使用 vm.$set 才能保证新增的属性也是响应式
5.Proxy支持13种拦截操作,这是defineProperty所不具有的
6.Proxy 作为新标准,长远来看,JS引擎会继续优化 Proxy,但 getter 和 setter 基本不会再有针对性优化
1.6.Vue 2 中给 data 中的对象属性添加一个新的属性时会发生什么?如何解决?
视图并未刷新。这是因为在Vue实例创建时,新属性并未声明,因此就没有被Vue转换为响应式的属性,自然就不会触发视图的更新,这时就需要使用Vue的全局 api $set():
this.$set(this.obj, ‘new_property’, ‘new_value’)
computed 计算属性 : 依赖其它属性值,并且 computed 的值有缓存,只有它依赖的 属性值发生改变,下一次获取 computed 的值时才会重新计算 computed 的值。
watch 侦听器 : 更多的是观察的作用,无缓存性,类似于某些数据的监听回调,每 当监听的数据变化时都会执行回调进行后续操作。
运用场景:
1.当我们需要进行数值计算,并且依赖于其它数据时,应该使用 computed,因为可以利用 computed 的缓存特性,避免每次获取值时,都要重新计算。
2.当我们需要在数据变化时执行异步或开销较大的操作时,应该使用 watch,使用 watch 选项允许我们执行异步操作 ( 访问一个 API ),限制我们执行该操作的频率, 并在我们得到最终结果前,设置中间状态。这些都是计算属性无法做到的。
3.多个因素影响一个显示,用Computed;一个因素的变化影响多个其他因素、显示,用Watch;
1.computed: 计算属性是基于它们的依赖进行缓存的,只有在它的相关依赖发生改变时才会重新求值对于 method ,只要发生重新渲染,
2.method 调用总会执行该函数
1.让我们不用直接操作DOM元素,只操作数据便可以重新渲染页面
2.虚拟dom是为了解决浏览器性能问题而被设计出来的
当操作数据时,将改变的dom元素缓存起来,都计算完后再通过比较映射到真实的dom树上
3.diff算法比较新旧虚拟dom。如果节点类型相同,则比较数据,修改数据;如果节点不同,直接干掉节点及所有子节点,插入新的节点;如果给每个节点都设置了唯一的key,就可以准确的找到需要改变的内容,否则就会出现修改一个地方导致其他地方都改变的情况。比如A-B-C-D, 我要插入新节点A-B-M-C-D,实际上改变的了C和D。但是设置了key,就可以准确的找到B C并插入
1.具备跨平台的优势
2.操作 DOM 慢,js运行效率高。我们可以将DOM对比操作放在JS层,提高效率。
3.提升渲染性能
在Vue中使用filters来过滤(格式化)数据,filters不会修改数据,而是过滤(格式化)数据,改变用户看到的输出(计算属性 computed ,方法 methods 都是通过修改数据来处理数据格式的输出显示。
使用场景: 比如需要处理时间、数字等的的显示格式;
1)
.stop:等同于 JavaScript 中的 event.stopPropagation() ,防止事件冒泡;
2)
.prevent:等同于 JavaScript 中的 event.preventDefault() ,防止执行预设的行为(如果事件可取消,则取消该事件,而不停止事件的进一步传播);
3)
.capture:当元素发生冒泡时,先触发带有该修饰符的元素。若有多个该修饰符,则由外而内触发。如 div1中嵌套div2中嵌套div3.capture中嵌套div4,那么执行顺序为:div3=》div4=》div2=》div1
4)
.self:只会触发自己范围内的事件,不包含子元素;
5)
.once:只会触发一次。
v-show 仅仅控制元素的显示方式,将 display 属性在 block 和 none 来回切换;而v-if会控制这个 DOM 节点的存在与否。当我们需要经常切换某个元素的显示/隐藏时,使用v-show会更加节省性能上的开销;当只需要一次显示或隐藏时,使用v-if更加合理。
作用在表单元素上v-model="message"等同于v-bind:value=“message” v-on:input=“message= e v e n t . t a r g e t . v a l u e " 作 用 在 组 件 上 , 本 质 是 一 个 父 子 组 件 通 信 的 语 法 糖 , 通 过 p r o p 和 event.target.value” 作用在组件上, 本质是一个父子组件通信的语法糖,通过prop和 event.target.value"作用在组件上,本质是一个父子组件通信的语法糖,通过prop和.emit实现, 等同于:value="message" @input=" $emit('input', $event.target.value)"
JavaScript中的对象是引用类型的数据,当多个实例引用同一个对象时,只要一个实例对这个对象进行操作,其他实例中的数据也会发生变化。
而在Vue中,我们更多的是想要复用组件,那就需要每个组件都有自己的数据,这样组件之间才不会相互干扰。
所以组件的数据不能写成对象的形式,而是要写成函数的形式。数据以函数返回值的形式定义,这样当我们每次复用组件的时候,就会返回一个新的data,也就是说每个组件都有自己的私有数据空间,它们各自维护自己的数据,不会干扰其他组件的正常运行。
1.16.Vue template 到 render 的过程
1.调用parse方法将template转化为ast(抽象语法树, abstract syntax tree)
2.对静态节点做优化。如果为静态节点,他们生成的DOM永远不会改变,这对运行时模板更新起到了极大的优化作用。
3.生成渲染函数. 渲染的返回值是VNode,VNode是Vue的虚拟DOM节点,里面有(标签名,子节点,文本等等)
1.17.Vue template 到 render 的过程
调用parse方法将template转化为ast(抽象语法树, abstract syntax tree)
对静态节点做优化。如果为静态节点,他们生成的DOM永远不会改变,这对运行时模板更新起到了极大的优化作用。
生成渲染函数. 渲染的返回值是VNode,VNode是Vue的虚拟DOM节点,里面有(标签名,子节点,文本等等)
易用、简洁且高效的http库, 支持node端和浏览器端,支持Promise,支持拦截器等高级配置。
sass是一种CSS预编译语言安装和使用步骤如下。
1.用npm安装加载程序( sass-loader、 css-loader等加载程序)。
2.在 webpack.config.js中配置sass加载程序。
Vue. js提供了一个v-cloak指令,该指令一直保持在元素上,直到关联实例结束编译。当和CSS一起使用时,这个指令可以隐藏未编译的标签,直到实例编译结束。用法如下
在开发业务时,经常会岀现异步获取数据的情况,有时数据层次比较深,如以下代码: <span 'v-text=“a.b.c.d”>, 可以使用vm.$set手动定义一层数据:
vm.$set(“demo”,a.b.c.d)
1.22.在 Vue. js开发环境下调用API接口,如何避免跨域
config/ index.js内对 proxyTable项配置代理。
Vue 在修改数据后,视图不会立刻更新,而是等同一事件循环中的所有数据变化完成之后,再统一进行视图更新。
换句话说,只要观察到数据变化,就会自动开启一个队列,并缓冲在同一个事件循环中发生的所以数据改变。在缓冲时会去除重复数据,从而避免不必要的计算和 DOM 操作。
1.vue 用异步队列的方式来控制 DOM 更新和 nextTick 回调先后执行
2.microtask 因为其高优先级特性,能确保队列中的微任务在一次事件循环前被执行完毕
因为组件是可以复用的,JS 里对象是引用关系,如果组件 data 是一个对象,那么子组件中的 data 属性值会互相污染。
所以一个组件的 data 选项必须是一个函数,因此每个实例可以维护一份被返回对象的独立的拷贝。
由于v-for的优先级比v-if高,所以导致每循环一次就会去v-if一次,而v-if是通过创建和销毁dom元素来控制元素的显示与隐藏,所以就会不停的去创建和销毁元素,造成页面卡顿,性能下降。
解决办法:
1.在v-for的外层或内层包裹一个元素来使用v-if
2.用computed处理
1.v-model 多用于表单元素实现双向数据绑定(同angular中的ng-model)
2.v-bind 动态绑定 作用: 及时对页面的数据进行更改
3.v-on:click 给标签绑定函数,可以缩写为@,例如绑定一个点击函数 函数必须写在methods里面
4.v-for 格式: v-for=“字段名 in(of) 数组json” 循环数组或json(同angular中的ng-repeat)
5.v-show 显示内容 (同angular中的ng-show)
6.v-hide 隐藏内容(同angular中的ng-hide)
7.v-if 显示与隐藏 (dom元素的删除添加 同angular中的ng-if 默认值为false)
8.v-else-if 必须和v-if连用
9.v-else 必须和v-if连用 不能单独使用 否则报错 模板编译错误
10.v-text 解析文本
11.v-html 解析html标签
12.v-bind:class 三种绑定方法 1、对象型 ‘{red:isred}’ 2、三元型 ‘isred?“red”:“blue”’ 3、数组型 ‘[{red:“isred”},{blue:“isblue”}]’
13.v-once 进入页面时 只渲染一次 不在进行渲染
14.v-cloak 防止闪烁
15.v-pre 把标签内部的元素原位输出
1.父传子:子组件通过props[‘xx’] 来接收父组件传递的属性 xx 的值
2.子传父:子组件通过 this.$emit(‘fnName’,value) 来传递,父组件通过接收 fnName 事件方法来接收回调
3.其他方式:通过创建一个bus,进行传值
4.使用Vuex
当 Vue.js 用 v-for 正在更新已渲染过的元素列表时,它默认用“就地复用”策略。如果数据项的顺序被改变,Vue 将不会移动 DOM 元素来匹配数据项的顺序, 而是简单复用此处每个元素,并且确保它在特定索引下显示已被渲染过的每个元素。key的作用主要是为了高效的更新虚拟DOM
1.31.为什么在 Vue3.0 采用了 Proxy,抛弃了 Object.defineProperty?
Object.defineProperty 本身有一定的监控到数组下标变化的能力,但是在 Vue 中,从性能/体验的性价比考虑,尤大大就弃用了这个特性(Vue 为什么不能检测数组变动 )。为了解决这个问题,经过 vue 内部处理后可以使用以下几种方法来监听数组
push();
pop();
shift();
unshift();
splice();
sort();
reverse();
由于只针对了以上 7 种方法进行了 hack 处理,所以其他数组的属性也是检测不到的,还是具有一定的局限性。
Object.defineProperty 只能劫持对象的属性,因此我们需要对每个对象的每个属性进行遍历。Vue 2.x 里,是通过 递归 + 遍历 data 对象来实现对数据的监控的,如果属性值也是对象那么需要深度遍历,显然如果能劫持一个完整的对象是才是更好的选择。
Proxy 可以劫持整个对象,并返回一个新的对象。Proxy 不仅可以代理对象,还可以代理数组。还可以代理动态增加的属性。
JS 运行机制
JS 执行是单线程的,它是基于事件循环的。事件循环大致分为以下几个步骤:
所有同步任务都在主线程上执行,形成一个执行栈(execution context stack)。
主线程之外,还存在一个"任务队列"(task queue)。只要异步任务有了运行结果,就在"任务队列"之中放置一个事件。
一旦"执行栈"中的所有同步任务执行完毕,系统就会读取"任务队列",看看里面有哪些事件。那些对应的异步任务,于是结束等待状态,进入执行栈,开始执行。
主线程不断重复上面的第三步。
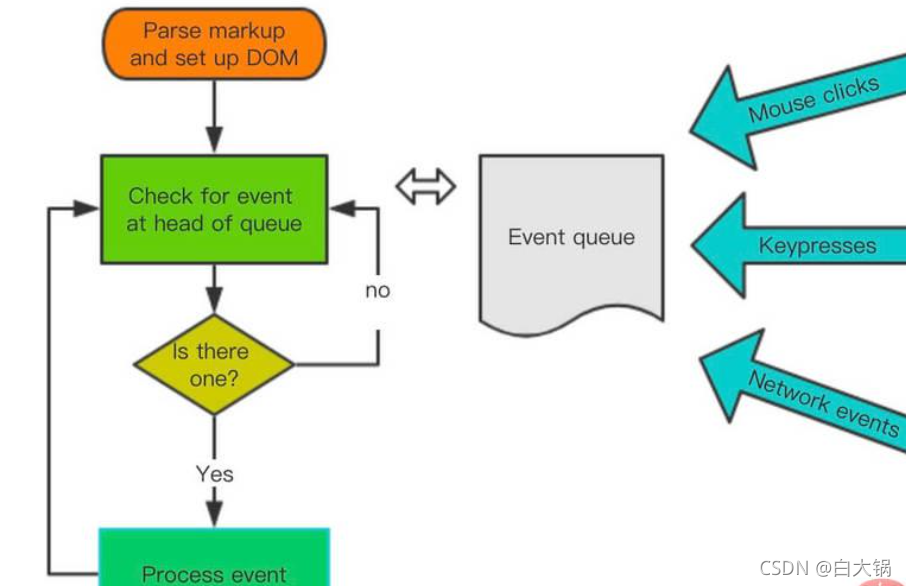
主线程的执行过程就是一个 tick,而所有的异步结果都是通过 “任务队列” 来调度。 消息队列中存放的是一个个的任务(task)。 规范中规定 task 分为两大类,分别是 macro task 和 micro task,并且每个 macro task 结束后,都要清空所有的 micro task。
for (macroTask of macroTaskQueue) {
// 1. Handle current MACRO-TASK
handleMacroTask();
// 2. Handle all MICRO-TASK
for (microTask of microTaskQueue) {
handleMicroTask(microTask);
}
}
在浏览器环境中 :
常见的 macro task 有 setTimeout、MessageChannel、postMessage、setImmediate
常见的 micro task 有 MutationObsever 和 Promise.then
异步更新队列
可能你还没有注意到,Vue 在更新 DOM 时是异步执行的。只要侦听到数据变化,Vue 将开启一个队列,并缓冲在同一事件循环中发生的所有数据变更。
如果同一个 watcher 被多次触发,只会被推入到队列中一次。这种在缓冲时去除重复数据对于避免不必要的计算和 DOM 操作是非常重要的。
然后,在下一个的事件循环“tick”中,Vue 刷新队列并执行实际 (已去重的) 工作。
Vue 在内部对异步队列尝试使用原生的 Promise.then、MutationObserver 和 setImmediate,如果执行环境不支持,则会采用 setTimeout(fn, 0) 代替。
在 vue2.5 的源码中,macrotask 降级的方案依次是:setImmediate、MessageChannel、setTimeout
vue 的 nextTick 方法的实现原理:
vue 用异步队列的方式来控制 DOM 更新和 nextTick 回调先后执行
microtask 因为其高优先级特性,能确保队列中的微任务在一次事件循环前被执行完毕
考虑兼容问题,vue 做了 microtask 向 macrotask 的降级方案
1.33.谈谈 Vue 事件机制,手写 o n , on, on,off, e m i t , emit, emit,once
Vue 事件机制 本质上就是 一个 发布-订阅 模式的实现。
class Vue {
constructor() {
// 事件通道调度中心
this._events = Object.create(null);
}
$on(event, fn) {
if (Array.isArray(event)) {
event.map(item => {
this.$on(item, fn);
});
} else {
(this._events[event] || (this._events[event] = [])).push(fn);
}
return this;
}
$once(event, fn) {
function on() {
this.$off(event, on);
fn.apply(this, arguments);
}
on.fn = fn;
this.$on(event, on);
return this;
}
$off(event, fn) {
if (!arguments.length) {
this._events = Object.create(null);
return this;
}
if (Array.isArray(event)) {
event.map(item => {
this.$off(item, fn);
});
return this;
}
const cbs = this._events[event];
if (!cbs) {
return this;
}
if (!fn) {
this._events[event] = null;
return this;
}
let cb;
let i = cbs.length;
while (i–) {
cb = cbs[i];
if (cb === fn || cb.fn === fn) {
cbs.splice(i, 1);
break;
}
}
return this;
}
$emit(event) {
let cbs = this._events[event];
if (cbs) {
const args = [].slice.call(arguments, 1);
cbs.map(item => {
args ? item.apply(this, args) : item.call(this);
});
}
return this;
}
}
三种:
一种是全局导航钩子:router.beforeEach(to,from,next),作用:跳转前进行判断拦截。第二种:组件内的钩子;第三种:单独路由独享组件
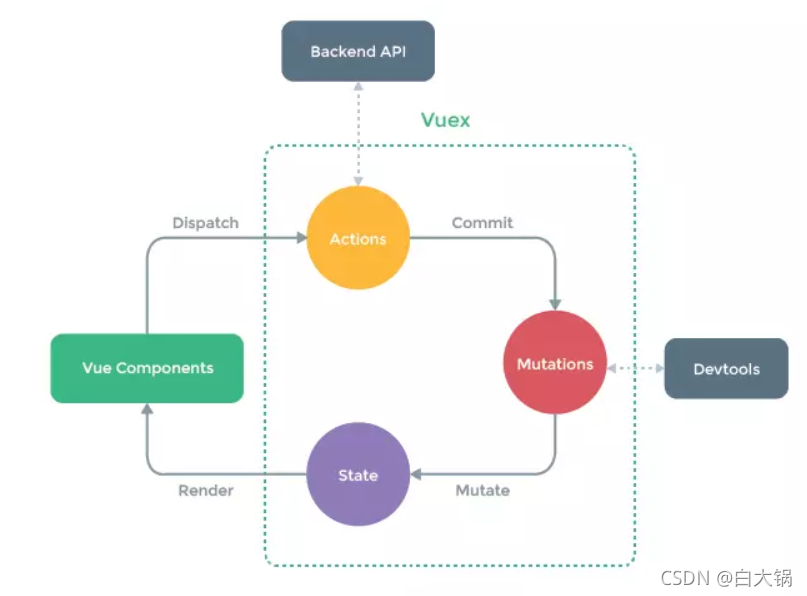
vue框架中状态管理。在main.js引入store,注入。新建了一个目录store,…… export 。
场景有:单页应用中,组件之间的状态。音乐播放、登录状态、加入购物车
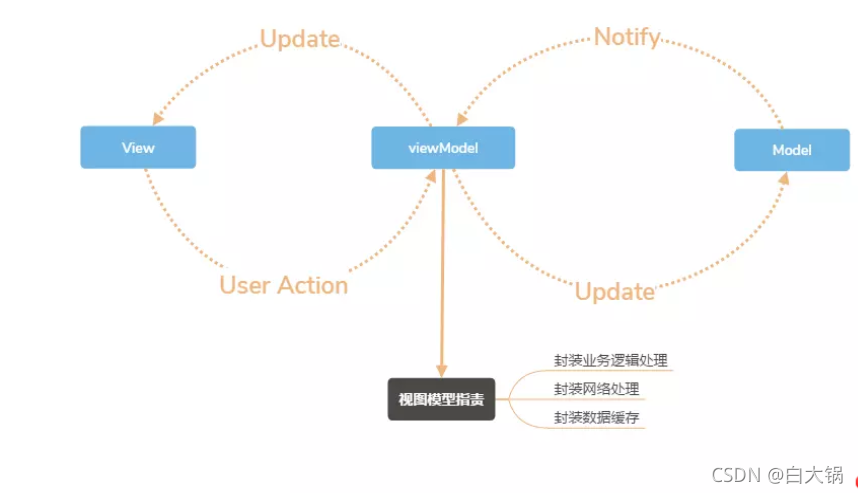
1.36.MVVM和MVC区别?和其他框架(jquery)区别?那些场景适用?
MVVM和MVC都是一种设计思想,主要就是MVC中的Controller演变成ViewModel,,MVVM主要通过数据来显示视图层而不是操作节点,解决了MVC中大量的DOM操作使页面渲染性能降低,加载速度慢,影响用户体验问题。主要用于数据操作比较多的场景。
场景:数据操作比较多的场景,更加便捷
简而言之,就是先转化成AST树,再得到的渲染函数返回VNODE(Vue公司的虚拟DOM节点)
详情步骤:
首先,通过编译编译器把模板编译成AST语法树(抽象语法树即源代码的抽象语法结构的树状表现形式),编译是createCompiler的返回值,createCompiler是用以创建编译器的。负责合并选项。
然后,AST会经过生成(将AST语法树转化成渲染功能字符串的过程)得到渲染函数,渲染的返回值是VNode,VNode是Vue的虚拟DOM节点,里面有(标签名,子节点,文本等等)
1.38.< keep-alive>< /keep-alive>的作用是什么,如何使用?
答:包裹动态组件时,会缓存不活动的组件实例,主要用于保留组件状态或避免重新渲染;
使用:简单页面时
缓存: < keep-alive include=”组件名”>< /keep-alive>
不缓存: < keep-alive exclude=”组件名”>< /keep-alive>
相同点:都鼓励组件化,都有’props’的概念,都有自己的构建工具,Reat与Vue只有框架的骨架,其他的功能如路由、状态管理等是框架分离的组件。
不同点:React:数据流单向,语法—JSX,在React中你需要使用setState()方法去更新状态。Vue:数据双向绑定,语法–HTML,state对象并不是必须的,数据由data属性在Vue对象中进行管理。适用于小型应用,但对于对于大型应用而言不太适合。
参照大神文章:vue笔记 - 生命周期第二次学习与理解
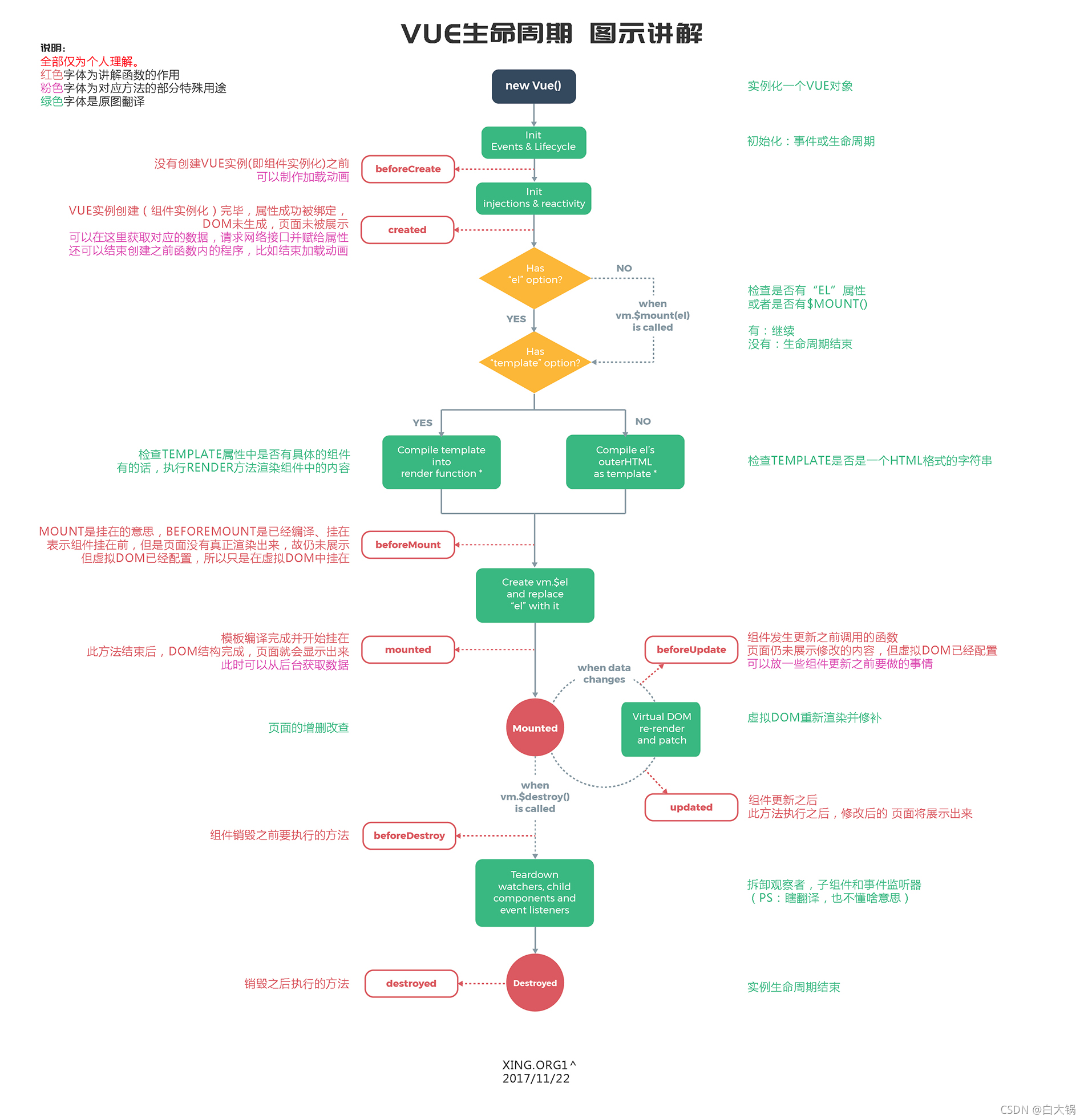
beforeCreate是new Vue()之后触发的第一个钩子,在当前阶段data、methods、computed以及watch上的数据和方法都不能被访问。
created在实例创建完成后发生,当前阶段已经完成了数据观测,也就是可以使用数据,更改数据,在这里更改数据不会触发updated函数。可以做一些初始数据的获取,在当前阶段无法与Dom进行交互,如果非要想,可以通过vm.$nextTick来访问Dom。
beforeMount发生在挂载之前,在这之前template模板已导入渲染函数编译。而当前阶段虚拟Dom已经创建完成,即将开始渲染。在此时也可以对数据进行更改,不会触发updated。
mounted在挂载完成后发生,在当前阶段,真实的Dom挂载完毕,数据完成双向绑定,可以访问到Dom节点,使用$refs属性对Dom进行操作。
beforeUpdate发生在更新之前,也就是响应式数据发生更新,虚拟dom重新渲染之前被触发,你可以在当前阶段进行更改数据,不会造成重渲染。
updated发生在更新完成之后,当前阶段组件Dom已完成更新。要注意的是避免在此期间更改数据,因为这可能会导致无限循环的更新。
beforeDestroy发生在实例销毁之前,在当前阶段实例完全可以被使用,我们可以在这时进行善后收尾工作,比如清除计时器。
destroyed发生在实例销毁之后,这个时候只剩下了dom空壳。组件已被拆解,数据绑定被卸除,监听被移出,子实例也统统被销毁。
1.41.Vue2.x和Vue3.x渲染器的diff算法分别说一下
简单来说,diff算法有以下过程
1.同级比较,再比较子节点
2.先判断一方有子节点一方没有子节点的情况(如果新的children没有子节点,将旧的子节点移除)
3.比较都有子节点的情况(核心diff)
3.递归比较子节点
正常Diff两个树的时间复杂度是O(n^3),但实际情况下我们很少会进行跨层级的移动DOM,所以Vue将Diff进行了优化,从O(n^3) -> O(n),只有当新旧children都为多个子节点时才需要用核心的Diff算法进行同层级比较。
Vue2的核心Diff算法采用了双端比较的算法,同时从新旧children的两端开始进行比较,借助key值找到可复用的节点,再进行相关操作。相比React的Diff算法,同样情况下可以减少移动节点次数,减少不必要的性能损耗,更加的优雅。
Vue3.x借鉴了
在创建VNode时就确定其类型,以及在 mount/patch 的过程中采用位运算来判断一个VNode的类型,在这个基础之上再配合核心的Diff算法,使得性能上较Vue2.x有了提升。(实际的实现可以结合Vue3.x源码看。)
该算法中还运用了动态规划的思想求解最长递归子序列。
编码阶段
1.尽量减少data中的数据,data中的数据都会增加getter和setter,会收集对应的2.watcher
3.v-if和v-for不能连用
4.如果需要使用v-for给每项元素绑定事件时使用事件代理
5.SPA 页面采用keep-alive缓存组件
6.在更多的情况下,使用v-if替代v-show
7.key保证唯一
8.使用路由懒加载、异步组件
9.防抖、节流
10.第三方模块按需导入
11.长列表滚动到可视区域动态加载
12.图片懒加载
SEO优化
1.预渲染
2.服务端渲染SSR
打包优化
1.压缩代码
2.Tree Shaking/Scope Hoisting
3.使用cdn加载第三方模块
4.多线程打包happypack
总结
三个工作日收到了offer,头条面试体验还是很棒的,这次的头条面试好像每面技术都问了我算法,然后就是中间件、MySQL、Redis、Kafka、网络等等。
- 第一个是算法
关于算法,我觉得最好的是刷题,作死的刷的,多做多练习,加上自己的理解,还是比较容易拿下的。
而且,我貌似是将《算法刷题LeetCode中文版》、《算法的乐趣》大概都过了一遍,尤其是这本
《算法刷题LeetCode中文版》总共有15个章节:编程技巧、线性表、字符串、栈和队列、树、排序、查找、暴力枚举法、广度优先搜索、深度优先搜索、分治法、贪心法、动态规划、图、细节实现题

《算法的乐趣》共有23个章节:


- 第二个是Redis、MySQL、kafka(给大家看下我都有哪些复习笔记)
基本上都是面试真题解析、笔记和学习大纲图,感觉复习也就需要这些吧(个人意见)

- 第三个是网络(给大家看一本我之前得到的《JAVA核心知识整理》包括30个章节分类,这本283页的JAVA核心知识整理还是很不错的,一次性总结了30个分享的大知识点)

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
11.长列表滚动到可视区域动态加载
12.图片懒加载
SEO优化
1.预渲染
2.服务端渲染SSR
打包优化
1.压缩代码
2.Tree Shaking/Scope Hoisting
3.使用cdn加载第三方模块
4.多线程打包happypack
总结
三个工作日收到了offer,头条面试体验还是很棒的,这次的头条面试好像每面技术都问了我算法,然后就是中间件、MySQL、Redis、Kafka、网络等等。
- 第一个是算法
关于算法,我觉得最好的是刷题,作死的刷的,多做多练习,加上自己的理解,还是比较容易拿下的。
而且,我貌似是将《算法刷题LeetCode中文版》、《算法的乐趣》大概都过了一遍,尤其是这本
《算法刷题LeetCode中文版》总共有15个章节:编程技巧、线性表、字符串、栈和队列、树、排序、查找、暴力枚举法、广度优先搜索、深度优先搜索、分治法、贪心法、动态规划、图、细节实现题
[外链图片转存中…(img-fGt7qiub-1713205296035)]
《算法的乐趣》共有23个章节:
[外链图片转存中…(img-yvf7hIYL-1713205296035)]
[外链图片转存中…(img-XhDvhkub-1713205296036)]
- 第二个是Redis、MySQL、kafka(给大家看下我都有哪些复习笔记)
基本上都是面试真题解析、笔记和学习大纲图,感觉复习也就需要这些吧(个人意见)
[外链图片转存中…(img-qfDEcpeI-1713205296036)]
- 第三个是网络(给大家看一本我之前得到的《JAVA核心知识整理》包括30个章节分类,这本283页的JAVA核心知识整理还是很不错的,一次性总结了30个分享的大知识点)
[外链图片转存中…(img-BMo5XgDh-1713205296036)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)
[外链图片转存中…(img-eO0tCSgq-1713205296037)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 519
519











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









