







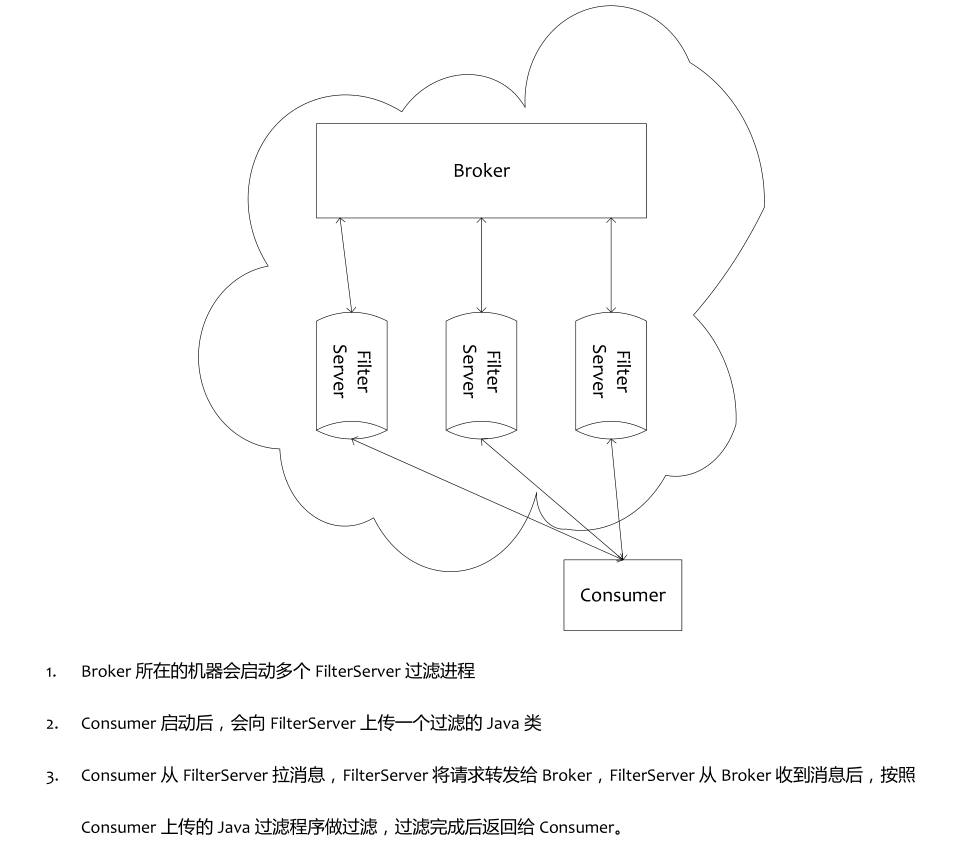

通过官方文档,我们基本可以知道,消息的过滤机制与服务端息息相关,更细一点的讲,与拉取消息实现过程脱离不了关系,事实上也的确如此,MessageFilter 的使用者也就是 DefaultMessageStore#getMessage 方法,为了弄清楚消息过滤机制,我们先看一下 MessageFilter 接口,然后详细再浏览一下消息拉取实现细节。
MessageFilter 接口类:
boolean isMatchedByConsumeQueue(final Long tagsCode, final ConsumeQueueExt.CqExtUnit cqExtUnit);
boolean isMatchedByCommitLog(final ByteBuffer msgBuffer,final Map<String, String> properties);
isMatchedByConsumeQueue 、isMatchedByCommitLog 的区别是什么?从字面上理解,一个过滤基于 ConsumeQueue,一个基于CommitLog 过滤,为什么需要这样呢?请带着上面的问题开始后面的探索。
2、 DefaultMessageStore#getMessage
=================================
public GetMessageResult getMessage(final String group, final String topic, final int queueId, final long offset,
final int maxMsgNums,
final MessageFilter messageFilter) { // @1
if (this.shutdown) {
log.warn(“message store has shutdown, so getMessage is forbidden”);
return null;
}
if (!this.runningFlags.isReadable()) {
log.warn("message store is not readable, so getMessage is forbidden " + this.runningFlags.getFlagBits());
return null;
}
long beginTime = this.getSystemClock().now();
GetMessageStatus status = GetMessageStatus.NO_MESSAGE_IN_QUEUE;
long nextBeginOffset = offset; // @2
long minOffset = 0;
long maxOffset = 0;
GetMessageResult getResult = new GetMessageResult();
final long maxOffsetPy = this.commitLog.getMaxOffset(); // @3
ConsumeQueue consumeQueue = findConsumeQueue(topic, queueId); // @4
if (consumeQueue != null) {
minOffset = consumeQueue.getMinOffsetInQueue();
maxOffset = consumeQueue.getMaxOffsetInQueue(); // @5
// @6
if (maxOffset == 0) {
status = GetMessageStatus.NO_MESSAGE_IN_QUEUE;
nextBeginOffset = nextOffsetCorrection(offset, 0);
} else if (offset < minOffset) {
status = GetMessageStatus.OFFSET_TOO_SMALL;
nextBeginOffset = nextOffsetCorrection(offset, minOffset);
} else if (offset == maxOffset) {
status = GetMessageStatus.OFFSET_OVERFLOW_ONE;
nextBeginOffset = nextOffsetCorrection(offset, offset);
} else if (offset > maxOffset) {
status = GetMessageStatus.OFFSET_OVERFLOW_BADLY;
if (0 == minOffset) {
nextBeginOffset = nextOffsetCorrection(offset, minOffset);
} else {
nextBeginOffset = nextOffsetCorrection(offset, maxOffset);
}
} else {
SelectMappedBufferResult bufferConsumeQueue = consumeQueue.getIndexBuffer(offset); // @7
if (bufferConsumeQueue != null) {
try {
status = GetMessageStatus.NO_MATCHED_MESSAGE;
long nextPhyFileStartOffset = Long.MIN_VALUE; // @8
long maxPhyOffsetPulling = 0;
int i = 0;
final int maxFilterMessageCount = Math.max(16000, maxMsgNums * ConsumeQueue.CQ_STORE_UNIT_SIZE);
final boolean diskFallRecorded = this.messageStoreConfig.isDiskFallRecorded();
ConsumeQueueExt.CqExtUnit cqExtUnit = new ConsumeQueueExt.CqExtUnit();
for (; i < bufferConsumeQueue.getSize() && i < maxFilterMessageCount; i += ConsumeQueue.CQ_STORE_UNIT_SIZE) { // @9
long offsetPy = bufferConsumeQueue.getByteBuffer().getLong();
int sizePy = bufferConsumeQueue.getByteBuffer().getInt();
long tagsCode = bufferConsumeQueue.getByteBuffer().getLong(); // @10
maxPhyOffsetPulling = offsetPy; // @11
if (nextPhyFileStartOffset != Long.MIN_VALUE) { // @12
if (offsetPy < nextPhyFileStartOffset)
continue;
}
boolean isInDisk = checkInDiskByCommitOffset(offsetPy, maxOffsetPy); // @13
if (this.isTheBatchFull(sizePy, maxMsgNums, getResult.getBufferTotalSize(), getResult.getMessageCount(),
isInDisk)) {
break;
} // @14
boolean extRet = false;
if (consumeQueue.isExtAddr(tagsCode)) {
extRet = consumeQueue.getExt(tagsCode, cqExtUnit);
if (extRet) {
tagsCode = cqExtUnit.getTagsCode();
} else {
// can’t find ext content.Client will filter messages by tag also.
log.error(“[BUG] can’t find consume queue extend file content!addr={}, offsetPy={}, sizePy={}, topic={}, group={}”,
tagsCode, offsetPy, sizePy, topic, group);
}
}
if (messageFilter != null
&& !messageFilter.isMatchedByConsumeQueue(tagsCode, extRet ? cqExtUnit : null)) { // @15
if (getResult.getBufferTotalSize() == 0) {
status = GetMessageStatus.NO_MATCHED_MESSAGE;
}
continue;
}
SelectMappedBufferResult selectResult = this.commitLog.getMessage(offsetPy, sizePy); // @16
if (null == selectResult) {
if (getResult.getBufferTotalSize() == 0) {
status = GetMessageStatus.MESSAGE_WAS_REMOVING;
}
nextPhyFileStartOffset = this.commitLog.rollNextFile(offsetPy); // @17
continue;
}
if (messageFilter != null
&& !messageFilter.isMatchedByCommitLog(selectResult.getByteBuffer().slice(), null)) { // @18
if (getResult.getBufferTotalSize() == 0) {
status = GetMessageStatus.NO_MATCHED_MESSAGE;
}
// release…
selectResult.release();
continue;
}
this.storeStatsService.getGetMessageTransferedMsgCount().incrementAndGet();
getResult.addMessage(selectResult); // @19
status = GetMessageStatus.FOUND;
nextPhyFileStartOffset = Long.MIN_VALUE;
}
if (diskFallRecorded) { // @20
long fallBehind = maxOffsetPy - maxPhyOffsetPulling;
brokerStatsManager.recordDiskFallBehindSize(group, topic, queueId, fallBehind);
}
nextBeginOffset = offset + (i / ConsumeQueue.CQ_STORE_UNIT_SIZE);
long diff = maxOffsetPy - maxPhyOffsetPulling; // @21
long memory = (long) (StoreUtil.TOTAL_PHYSICAL_MEMORY_SIZE
- (this.messageStoreConfig.getAccessMessageInMemoryMaxRatio() / 100.0));
getResult.setSuggestPullingFromSlave(diff > memory);
} finally {
bufferConsumeQueue.release();
}
} else {
status = GetMessageStatus.OFFSET_FOUND_NULL;
nextBeginOffset = nextOffsetCorrection(offset, consumeQueue.rollNextFile(offset));
log.warn("consumer request topic: " + topic + "offset: " + offset + " minOffset: " + minOffset + " maxOffset: "
- maxOffset + “, but access logic queue failed.”);
}
}
} else {
status = GetMessageStatus.NO_MATCHED_LOGIC_QUEUE;
nextBeginOffset = nextOffsetCorrection(offset, 0);
}
if (GetMessageStatus.FOUND == status) {
this.storeStatsService.getGetMessageTimesTotalFound().incrementAndGet();
} else {
this.storeStatsService.getGetMessageTimesTotalMiss().incrementAndGet();
}
long eclipseTime = this.getSystemClock().now() - beginTime;
this.storeStatsService.setGetMessageEntireTimeMax(eclipseTime);
getResult.setStatus(status); // @22
getResult.setNextBeginOffset(nextBeginOffset);
getResult.setMaxOffset(maxOffset);
getResult.setMinOffset(minOffset);
return getResult;
}
代码@1: 先相信介绍一下参数的含义。
- final String group
消费组名称。
- final String topic
消息主题。
- final int queueId
消息队列ID。
- final long offset
拉取的消息队列偏移量。
- final int maxMsgNums
一次拉取消息条数,默认为32,可通过消费者设置 pullBatchSize ,这个参数和 consumeMessageBatchMaxSize=1 是有区别的。
- final MessageFilter messageFilter
消息过滤器。
代码@2 :设置拉取偏移量,从 PullRequest 中获取,初始从消费进度中获取。
代码@3:获取 commitlog 文件中的最大偏移量。
代码@4 :根据 topic、queueId 获取消息队列(ConsumeQueue)。
代码@5:获取该消息队列中最小偏移量(minOffset)\最大偏移量(maxOffset)。
代码@6:根据需要拉取消息的偏移量 与 队列最小,最大偏移量进行对比)。

- maxOffset = 0 表示队列中没有消息。
计算下一次拉取拉取的开始偏移量: nextBeginOffset = nextOffsetCorrection(offset, 0);
1)如果是主节点,或者是从节点但开启了offsetCheckSlave的话,下次从头开始拉取。
2)如果是从节点,并不开启 offsetCheckSlave,则使用原先的 offset,因为考虑到主从同步延迟的因素,导致从节点consumequeue并没有同步到数据。offsetCheckInSlave设置为false保险点,当然默认该值为false。返回状态码: NO_MESSAGE_IN_QUEUE。
- offset < minOfset
表示要拉取的偏移量小于队列最小的偏移量此时如果是主节点,或开启了offsetCheckSlave的话,设置下一次拉取的偏移量为minOffset,如果是从节点,并且没有开启offsetCheckSlave,则保持原先的offset,这样的处理应该不合适,因为总是无法满足这个要求 ,返回status : OFFSET_TOO_SMALL,估计会在消息消费拉取端重新从消费进度处获取偏移量,重新拉取。
- offset == maxOffset
表示超出一个,返回状态:OFFSET_OVERFLOW_ONE,offset 保持不变。
- 如果offset > maxOffset
表示超出,返回状态:OFFSET_OVERFLOW_BADLY,此时,如果为从节点并未开启 offsetCheckSlave,则使用原偏移量,这个是正常的,等待消息到达从服务器。如果是主节点:表示offset是一个非法的偏移量,如果minOffset=0,则设置下一个拉取偏移量为0,否则设置为最大,我感觉设置为0,重新拉取,有可能消息重复,设置为最大可能消息会丢失?什么时候会offset > maxOffset(在主节点)拉取完消息,进行第二次拉取时,重点看一下这些状态下,应该还有第二次修正消息的处理。
- offset 大于minOffset 并小于maxOffset,正常情况。
代码@7:从 consuequeue 中从当前 offset 到当前 consueque 中最大可读消息内存。代码来源于 ConsumeQueue#getIndexBuffer。
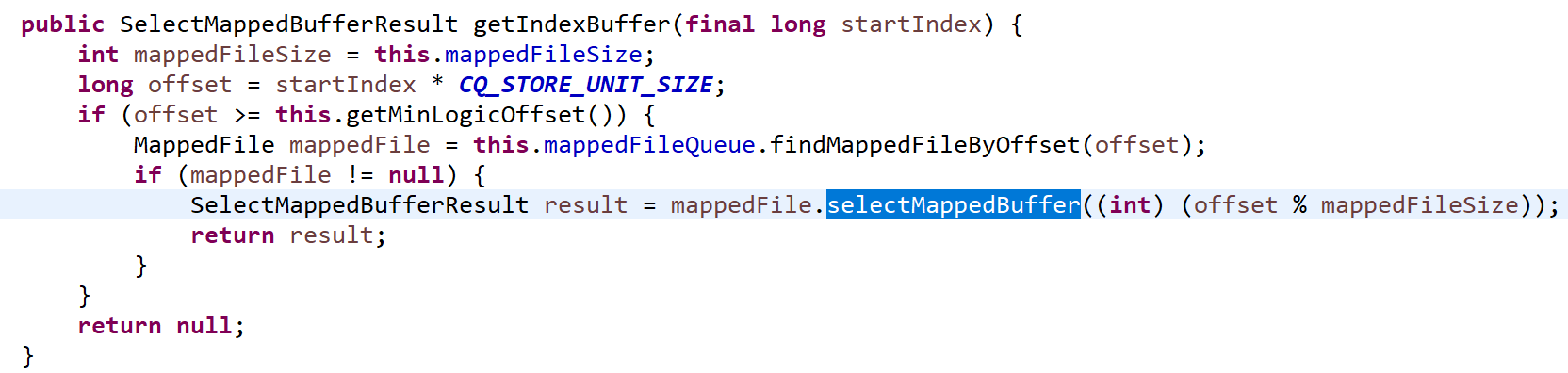
MappedFile#selectMappedBuffer(int pos) 从pos开始,readPosition(当前写指针,表示当前最大的有效数据)。
SelectMappedBufferResult 里面封装了从pos 到 readPosition 的数据段(ByteBuffer)。
代码@8:初始化基本变量。
-
nextPhyFileStartOffset = Long.MIN_VALUE 下一个开始offset
-
maxPhyOffsetPulling = 0
-
maxFilterMessageCount :最大过滤消息字节数,max(16000, maxMsgNums * 20)
代码@9 :for (; i < bufferConsumeQueue.getSize() && i < maxFilterMessageCount; i += ConsumeQueue.CQ_STORE_UNIT_SIZE)。
结合这个循环条件我们分析一下为什么 maxFilterMessageCount 要取 16000 与 maxMsgNums * 20 的最大值,我们不是指定拉取 maxMsgNums 条消息吗?为什么不直接 maxFilterMessageCount = maxMsgNums * 20 ,因为拉取到的消息,可能不满足过滤条件,导致拉取的消息小于maxMsgNums,那这里一定会返回maxMsgNums条消息吗?不一定,这里是尽量返回这么多条消息。
代码@10:解析一条 consumeQueue。
-
offsetPy : commitlog 偏移量。
-
sizePy : 消息总长度。
-
tagsCode : 消息tag hashcode。
代码@11 :当前拉取的物理偏移量。
代码@12:如果拉取到的消息偏移量小于下一个要拉取的物理偏移量的话,直接跳过该条消息。
代码@13:检查该offsetPy,拉取的偏移量是否在磁盘上。
private boolean checkInDiskByCommitOffset(long offsetPy, long maxOffsetPy) {
long memory = (long) (StoreUtil.TOTAL_PHYSICAL_MEMORY_SIZE * (this.messageStoreConfig.getAccessMessageInMemoryMaxRatio() / 100.0));
return (maxOffsetPy - offsetPy) > memory;
}
-
offsetPy : 待拉取的消息偏移量
-
maxOffsetPy : 当前commitlog文件最大的偏移量
-
MessageStoreConfig accessMessageInMemoryMaxRatio
消息存储在物理内存中占用的最大比例,memory = 物理内存 * 这个比例,如果 maxOffsetPy-offsetPy > memory 的话,说明 offsetPy 这个偏移量的消息已经从内存中置换到磁盘中了。
代码@14:判断本次拉取任务是否完成。
private boolean isTheBatchFull(int sizePy, int maxMsgNums, int bufferTotal, int messageTotal, boolean isInDisk) {
if (0 == bufferTotal || 0 == messageTotal) {
return false;
}
if (maxMsgNums <= messageTotal) {
return true;
}
if (isInDisk) {
if ((bufferTotal + sizePy) > this.messageStoreConfig.getMaxTransferBytesOnMessageInDisk()) {
return true;
}
if (messageTotal > this.messageStoreConfig.getMaxTransferCountOnMessageInDisk() - 1) {
return true;
}
} else {
if ((bufferTotal + sizePy) > this.messageStoreConfig.getMaxTransferBytesOnMessageInMemory()) {
return true;
}
if (messageTotal > this.messageStoreConfig.getMaxTransferCountOnMessageInMemory() - 1) {
return true;
}
}
return false;
}
首先对参数进行一个说明:
-
sizePy :当前消息的字节长度
-
maxMsgNums : 本次拉取消息条数
-
bufferTotal : 已拉取消息字节总长度,不包含当前消息
-
messageTotal : 已拉取消息总条数
-
isInDisk :当前消息是否存在于磁盘中
具体处理逻辑:
-
如果 bufferTotal 和messageTotal 都等于0,显然本次拉取任务才刚开始,本批拉取任务未完成,返回 false。
-
如果maxMsgNums <= messageTotal,返回true,表示已拉取完毕。
接下来根据是否在磁盘中,会区分对待:
1、如果该消息存在于磁盘而不是内存中:如果已拉取消息字节数 + 待拉取消息的长度 > maxTransferBytesOnMessageInDisk
(MessageStoreConfig),默认64K,则不继续拉取该消息,返回拉取任务结束。如果已拉取消息条数 > maxTransferCountOnMessageInDisk (MessageStoreConfig)默认为8,也就是,如果消息存在于磁盘中,一次拉取任务最多拉取8条。
2、如果该消息存在于内存中,对应的参数为maxTransferBytesOnMessageInMemory、maxTransferCountOnMessageInMemory,其逻辑与上述一样。
代码@14:isTheBatchFull 主要就是本次是否已拉取到足够的消息。
代码@15:执行消息过滤,如果符合过滤条件。则直接进行下一条的拉取,如果不符合过滤条件,则进入继续执行,并如果最终符合条件,则将该消息添加到拉取结果中。具体过滤逻辑暂时跳过,下文会专门研究其机制。
代码@16:从 commitlog 文件中读取消息,根据偏移量与消息大小。
代码@17:如果该偏移量没有找到正确的消息,则说明已经到文件末尾了,下一次切换到下一个 commitlog 文件读取。
public long rollNextFile(final long offset) {
int mappedFileSize =
this.defaultMessageStore.getMessageStoreConfig().getMapedFileSizeCommitLog();
return offset + mappedFileSize - offset % mappedFileSize;
}
代码@18:从commitlog(全量消息)再次过滤,consumeque 中只能处理 TAG 模式的过滤,SQL92 这种模式无法过滤,因为SQL92 需要依赖消息中的属性,故在这里再做一次过滤。如果消息符合条件,则加入到拉取结果中。
代码@19 将消息加入到拉取结果中。
代码@20 diskFallRecorded,是否记录磁盘活动图,默认为false。
代码@21:如果当前commitlog中的偏移量 - 当前最大拉取消息偏移量 > 允许消息在内存中存在大小时,建议下一次拉取任务从从节点拉取。
代码@22:设置下一次拉取偏移量,然后返回拉取结果。
上述反映了在服务端根据偏移量拉取消息的全过程,包括消息过滤调用入口,现在我们再回去消费者根据消息拉取结果采取的措施。
3、消息拉取
======
代码入口:DefaultMQPushConsumerImpl#pullMessage
switch (pullResult.getPullStatus()) {
case FOUND: // @1
long prevRequestOffset = pullRequest.getNextOffset();
pullRequest.setNextOffset(pullResult.getNextBeginOffset());
long pullRT = System.currentTimeMillis() - beginTimestamp;
DefaultMQPushConsumerImpl.this.getConsumerStatsManager().incPullRT(pullRequest.getConsumerGroup(),
pullRequest.getMessageQueue().getTopic(), pullRT);
long firstMsgOffset = Long.MAX_VALUE;
if (pullResult.getMsgFoundList() == null || pullResult.getMsgFoundList().isEmpty()) {
DefaultMQPushConsumerImpl.this.executePullRequestImmediately(pullRequest);
} else {
firstMsgOffset = pullResult.getMsgFoundList().get(0).getQueueOffset();
DefaultMQPushConsumerImpl.this.getConsumerStatsManager().incPullTPS(pullRequest.getConsumerGroup(),
pullRequest.getMessageQueue().getTopic(), pullResult.getMsgFoundList().size());
boolean dispathToConsume = processQueue.putMessage(pullResult.getMsgFoundList());
DefaultMQPushConsumerImpl.this.consumeMessageService.submitConsumeRequest(
pullResult.getMsgFoundList(),
processQueue,
pullRequest.getMessageQueue(),
dispathToConsume);
if (DefaultMQPushConsumerImpl.this.defaultMQPushConsumer.getPullInterval() > 0) {
DefaultMQPushConsumerImpl.this.executePullRequestLater(pullRequest,
DefaultMQPushConsumerImpl.this.defaultMQPushConsumer.getPullInterval());
} else {
DefaultMQPushConsumerImpl.this.executePullRequestImmediately(pullRequest);
}
}
if (pullResult.getNextBeginOffset() < prevRequestOffset
|| firstMsgOffset < prevRequestOffset) {
log.warn(
“[BUG] pull message result maybe data wrong, nextBeginOffset: {} firstMsgOffset: {} prevRequestOffset: {}”,
pullResult.getNextBeginOffset(),
firstMsgOffset,
prevRequestOffset);
}
break;
case NO_NEW_MSG: // @2
pullRequest.setNextOffset(pullResult.getNextBeginOffset());
DefaultMQPushConsumerImpl.this.correctTagsOffset(pullRequest);
DefaultMQPushConsumerImpl.this.executePullRequestImmediately(pullRequest);
break;
case NO_MATCHED_MSG:
pullRequest.setNextOffset(pullResult.getNextBeginOffset());
DefaultMQPushConsumerImpl.this.correctTagsOffset(pullRequest);
DefaultMQPushConsumerImpl.this.executePullRequestImmediately(pullRequest);
break;
case OFFSET_ILLEGAL:
log.warn(“the pull request offset illegal, {} {}”,
pullRequest.toString(), pullResult.toString());
pullRequest.setNextOffset(pullResult.getNextBeginOffset());
pullRequest.getProcessQueue().setDropped(true);
DefaultMQPushConsumerImpl.this.executeTaskLater(new Runnable() {
@Override
public void run() {
try {
DefaultMQPushConsumerImpl.this.offsetStore.updateOffset(pullRequest.getMessageQueue(),
pullRequest.getNextOffset(), false);
DefaultMQPushConsumerImpl.this.offsetStore.persist(pullRequest.getMessageQueue());
DefaultMQPushConsumerImpl.this.rebalanceImpl.removeProcessQueue(pullRequest.getMessageQueue());
log.warn(“fix the pull request offset, {}”, pullRequest);
} catch (Throwable e) {
log.error(“executeTaskLater Exception”, e);
}
}
}, 10000);
break;
default:
break;
}
代码@1:找到消息直接将这一批(默认32条)先丢到 ProceeQueue 中,然后直接将该批 submit 到 ConsumeMessageService的线程池,在 submitConsumeRequest 会根据 consumeMessageBatchMaxSize 分批提交给消费线程去消费消息,consumeMessageBatchMaxSize 默认为1。
那么如何才能正确的掌握Redis呢?
为了让大家能够在Redis上能够加深,所以这次给大家准备了一些Redis的学习资料,还有一些大厂的面试题,包括以下这些面试题
-
并发编程面试题汇总
-
JVM面试题汇总
-
Netty常被问到的那些面试题汇总
-
Tomcat面试题整理汇总
-
Mysql面试题汇总
-
Spring源码深度解析
-
Mybatis常见面试题汇总
-
Nginx那些面试题汇总
-
Zookeeper面试题汇总
-
RabbitMQ常见面试题汇总
JVM常频面试:

Mysql面试题汇总(一)

Mysql面试题汇总(二)

Redis常见面试题汇总(300+题)

log.warn(“fix the pull request offset, {}”, pullRequest);
} catch (Throwable e) {
log.error(“executeTaskLater Exception”, e);
}
}
}, 10000);
break;
default:
break;
}
代码@1:找到消息直接将这一批(默认32条)先丢到 ProceeQueue 中,然后直接将该批 submit 到 ConsumeMessageService的线程池,在 submitConsumeRequest 会根据 consumeMessageBatchMaxSize 分批提交给消费线程去消费消息,consumeMessageBatchMaxSize 默认为1。
那么如何才能正确的掌握Redis呢?
为了让大家能够在Redis上能够加深,所以这次给大家准备了一些Redis的学习资料,还有一些大厂的面试题,包括以下这些面试题
-
并发编程面试题汇总
-
JVM面试题汇总
-
Netty常被问到的那些面试题汇总
-
Tomcat面试题整理汇总
-
Mysql面试题汇总
-
Spring源码深度解析
-
Mybatis常见面试题汇总
-
Nginx那些面试题汇总
-
Zookeeper面试题汇总
-
RabbitMQ常见面试题汇总
JVM常频面试:
[外链图片转存中…(img-wAkmJdOa-1714752548714)]
Mysql面试题汇总(一)
[外链图片转存中…(img-ArsFaJKo-1714752548715)]
Mysql面试题汇总(二)
[外链图片转存中…(img-q5gWKMUZ-1714752548715)]
Redis常见面试题汇总(300+题)
[外链图片转存中…(img-2KhHC8eD-1714752548715)]















 2087
2087











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









