







REPEAT #循环
SET i = i + 1; #赋值
INSERT INTO student (stuno, name ,age ,classId ) VALUES
((START+i),rand_string(6),rand_num(1,50),rand_num(1,1000));
UNTIL i = max_num
END REPEAT;
COMMIT; #提交事务
END //
DELIMITER ;
#假如要删除
#drop PROCEDURE insert_stu;
创建往class表中插入数据的存储过程
#执行存储过程,往class表添加随机数据
DELIMITER //
CREATE PROCEDURE insert\_class( max_num INT )
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO class ( classname,address,monitor ) VALUES
(rand_string(8),rand_string(10),rand_num(1,100000));
UNTIL i = max_num
END REPEAT;
COMMIT;
END //
DELIMITER ;
#假如要删除
#drop PROCEDURE insert_class;
### (5)调用存储过程
往class表添加1万条数据
#执行存储过程,往class表添加1万条数据
CALL insert_class(10000);
往stu表添加50万条数据,这个时间会稍微有点长,请耐心等待哟。
#执行存储过程,往stu表添加50万条数据
CALL insert_stu(100000,500000);
查询下数据是否插入成功。
SELECT COUNT(*) FROM class;
SELECT COUNT(*) FROM student;
### (6)删除某表上的索引
创建删除索引存储过程。这是为了方便我们的学习,因为我们在演示某个索引的效果时,可能需要删除其它索引,如果需要一个个手工删除,就太费劲了。
DELIMITER //
CREATE PROCEDURE proc\_drop\_index(dbname VARCHAR(200),tablename VARCHAR(200))
BEGIN
DECLARE done INT DEFAULT 0;
DECLARE ct INT DEFAULT 0;
DECLARE _index VARCHAR(200) DEFAULT ‘’;
DECLARE _cur CURSOR FOR SELECT index_name FROM
information_schema.STATISTICS WHERE table_schema=dbname AND table_name=tablename AND
seq_in_index=1 AND index_name <>‘PRIMARY’ ;
#每个游标必须使用不同的declare continue handler for not found set done=1来控制游标的结束
DECLARE CONTINUE HANDLER FOR NOT FOUND set done=2 ;
#若没有数据返回,程序继续,并将变量done设为2
OPEN _cur;
FETCH _cur INTO _index;
WHILE _index<>‘’ DO
SET @str = CONCAT("drop index " , _index , " on " , tablename );
PREPARE sql_str FROM @str ;
EXECUTE sql_str;
DEALLOCATE PREPARE sql_str;
SET _index=‘’;
FETCH _cur INTO _index;
END WHILE;
CLOSE _cur;
END //
DELIMITER ;
执行存储过程(可以先保留不执行)
CALL proc_drop_index(“dbname”,“tablename”);
## 3️⃣索引失效的情况
这里我们以InnoDB的B+树的索引结构作为讲解的重点,讲解索引失效的案例(3.1讲解索引最佳的实践)。之所以会出现索引失效的情况,其实是因为我们的优化器经过了成本开销的计算,决定不用索引。用不用索引都是优化器说了算,Sql语句是否会使用索引,跟**数据库版本**、**数据量**和**数据选择度**都有关系。
### 3.1 全值匹配我最爱(索引最佳)
全值匹配可以充分的利用组合索引。
在没有建立索引时会进行数据查询速度会比较慢。
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30 AND classId=4;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30 AND classId=4 AND NAME = ‘abcd’;
`SQL_NO_CACHE`表示不使用查询缓存。
下图是在没有创建索引的情况下,第一条sql的执行效果。其查询时间是0.048s。

下面建立下索引。
CREATE INDEX idx_age ON student(age);
CREATE INDEX idx_age_classid ON student(age,classId);
CREATE INDEX idx_age_classid_name ON student(age,classId,NAME);
>
> 💌Q 上面三个索引有什么区别,为什么这么建立索引?
> 上面建立索引是与三条sql的使用场景对应的,遵守了全值匹配的规则,就是说建立几个复合索引字段,最好就用上几个字段。且按照顺序来用。
>
>
>
再次执行查询sql,就可以使用到索引idx\_age。并且其查询耗时会变短为0.024s。

执行如下sql。选择的索引则是:`idx_age_classid`。思考下为什么?
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age=30 AND classId=4;
这是因为我们在构建索引`idx_age_classid`的B+树时,会先按照age排序,在按照calssId排序,对于这个sql来说,更加高效。
但是上面的索引可能不生效哦,在数据量较大的情况下,我们进行全值匹配`SELECT *`,优化器可能经过计算发现,我们使用索引查询所有的数据后,还需要对查找到的数据进行回表操作,性能还不如全表扫描。这里我们没有造这么多数据,所以就不演示效果咯。
### 3.2 不遵守最左前缀匹配原则
运行如下sql。
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.name=‘abcd’;
将使用索引idx\_age。
下面的sql不会使用索引,因为我没没有创建classId或者name的索引。或者
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.classId=4 AND student.name=‘abcd’;
>
> Q:为什么不会使用idx\_age\_classid索引?
> 索引idx\_age\_classid的B+树会先使用age排序,在使用classId给age相同的数据排序,这个索引根本用不上哟。这就是下面的最左前缀原则。
>
>
>
在 MySQL 建立联合索引时会遵守最佳左前缀匹配原则,即最左优先,在检索数据时从联合索引的最左边开始匹配。
MySQL 可以为多个字段创建索引,一个索引可以包括 16 个字段,对于多列字段,过滤条件要使用所以那必须按照索引建立时的顺序,依次满足,一旦跳过某个字段,索引后面的字段都无法使用。如果查询条件中没有使用这些字段中的第一个字段时,多列索引不会被使用。
>
> 💞拓展:Alibaba《Java开发手册》
> 索引文件具有 B-Tree 的最左前缀匹配特性,如果左边的值未确定,那么无法使用此索引。
>
>
>
下面的sql查询就是遵守这一原则的正确打开方式。
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age = 30 AND student.classId=4 AND student.name=‘abcd’;
思考:下面sql会不会使用索引呢?
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.classId=4 AND student.age = 30 AND student.name=‘abcd’;
答案是会!因为优化器会执行优化的哦,会调整查询条件的顺序。不过在开发过程中我们还是要保持良好的开发习惯哟。
思考:删去索引`idx_age_classid`和`idx_age`,只保留`idx_age_classid_name`
DROP INDEX idx_age_classid ON student;
DROP INDEX idx_age ON student;
执行如下sql,会不会使用索引?
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age = 30 AND student.name=‘abcd’;
答案是会,但是只会用一部分。看看执行结果。

使用了`idx_age_classid_name`,但是`key_len`是5,也就是说只使用了age部分的排序,因为age是int类型,4个字节加上null值列表一共5个字节哦。想想就知道,B+树是先按照age排序,再按照classid排序,最后按照name排序,因此不能跳过classId的排序直接就使用name的排序哦。
### 3.3 不按照递增顺序插入主键
对于一个使用 InnoDB 存储引擎的表来说,在我们没有显式的创建索引时,表中的数据实际上都是存储在 聚簇索引 的叶子节点的。而记录又是存储在数据页中,数据页和记录又是按照 记录主键值从小到大 的顺序进行排序,所以如果我们 插入 的记录的 主键是依次增大 的话,那我们每插满一个数据页就换到下一个数据页继续插,而如果我们插入的 主键值忽大忽小 的话,就比较麻烦了,假设某个数据页存储的记录已经满了,它存储的主键值在 1~100 之间:
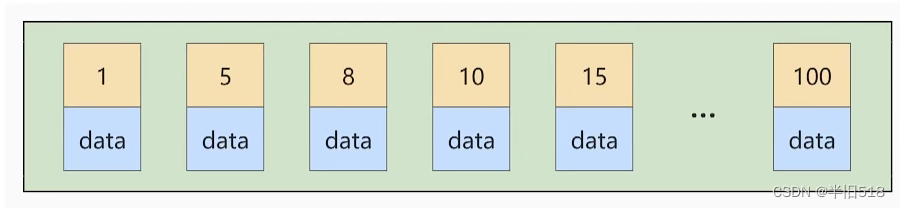
如果此时再插入一条主键值为 9 的记录,那它插入的位置就如下图:
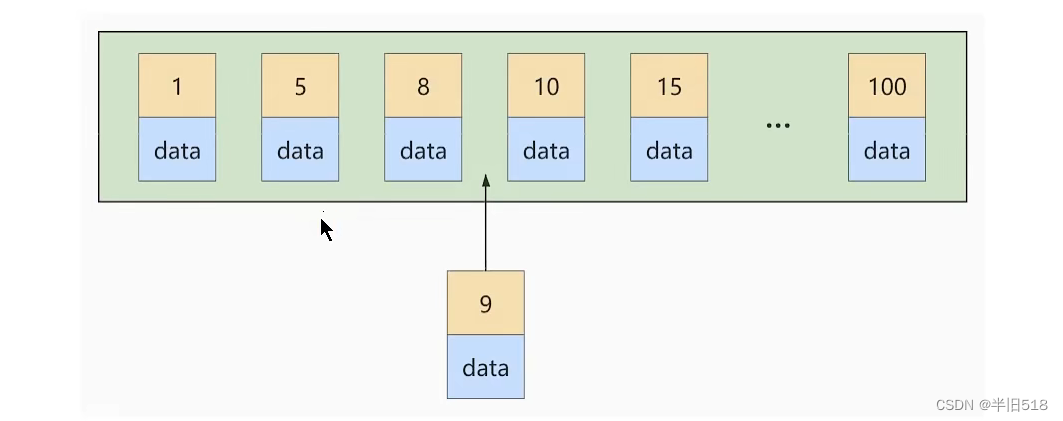
可这个数据页已经满了,再插进来咋办呢?我们需要把当前 页面分裂 成两个页面,把本页中的一些记录移动到新创建的这个页中。页面分裂和记录移位意味着什么?意味着:性能损耗!所以如果我们想尽量避免这样无谓的性能损耗,最好让插入的记录的 主键值依次递增 ,这样就不会发生这样的性能损耗了。 所以我们建议:让主键具有 AUTO\_INCREMENT ,让存储引擎自己为表生成主键,而不是我们手动插入
我们自定义的主键列 id 拥有 AUTO\_INCREMENT 属性,在插入记录时存储引擎会自动为我们填入自增的主键值。这样的主键占用空间小,顺序写入,减少页分裂。
>
> 🎀Tips:
> 我们一般将主键策略设置为自动递增`AUTO_INCREMENT`哦!(核心业务表除外,后面会介绍这种情况)
>
>
>
### 3.4 计算、函数、类型转换(自动或手动)导致索引失效
思考:这两条 sql 哪种写法更好?
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name LIKE ‘abc%’;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name,3) = ‘abc’;
从执行结果上说,上面sql执行结果没有区别。但是从运行效率上说,第1条sql比之后的要好,因为第一条可以使用上索引!而因为第二条使用了函数,即使建立索引也会导致索引失效。
为何使用函数时优化器会使索引失效呢?您想想,我们只是对`student.name`字段建立了索引,但并没有对LEFT(student.name,3)建立索引,使用函数后的关键字跟我们建立的B+树可对应不来,怎么能使用B+树优化查询呢?
### 3.5 类型转换导致索引失效
未使用到索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name=123;
使用到索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE name=‘123’;
name = 123 发生类型转换,索引失效,原因与使用函数也一样,其实类型转换就是使用了隐式的类型转换函数。
### 3.6 范围条件右边的列索引失效
我们先调用下前面准备的存储过程删除除主键索引外的其它索引。
CALL proc_drop_index(‘atguigu_db2’,‘student’);
SHOW INDEX FROM student;
创建联合索引。
CREATE INDEX idx_age_classId_name ON student(age,classId,NAME);
执行查询。
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.age=30 AND student.classId>20 AND student.name = ‘abc’ ;
执行结果如下。

注意到`key_len`是10,说明值使用到了`idx_age_classId_name`索引中的`age`与`classId`部分,而`name`则没有用上。这是因为classId>20是范围查询,导致其右边的列索引失效。
如果想要完全使用到索引,需要按如下方式创建索引:先写等值查询的列,再写范围查询的列。
create index idx_age_name_classid on student(age,name,classid);
>
> 🎨Q:为什么条件查询会导致范围条件后面的列索引失效?
> 比如说有三个字段 a b c,建立复合索引a\_b\_c
> 此时叶子节点的数据排序后可能为
> (a=1 b=1 c=1) (a=1 b=2 c=1) (a=1 b=2 c=3)
> (a=2 b=2 c=3) (a=2 b=2 c=5) (a=2 b=5 c=1) (a=2 b=5 c=2)
> (a=3 b=0 c=1) (a=3 b=3 c=5) (a=3 b=8 c=6)
> 假设查找 select a,b,c from table where a = 2 and b = 5 and c = 2
> 此时先根据a = 2找到第二行的四条数据
> (a=2 b=2 c=3) (a=2 b=2 c=5) (a=2 b=5 c=1) (a=2 b=5 c=2)
> 然后根据b=5查到两条
> (a=2 b=5 c=1) (a=2 b=5 c=2)
> 最后根据c=2查到目标数据
> (a=2 b=5 c=2)
> 接下来 假设使用了范围条件
> select a,b,c from table where a = 2 and b >1 and c = 2
> 此时先根据a = 2找到第二行的四条数据
> (a=2 b=2 c=3) (a=2 b=2 c=5) (a=2 b=5 c=1) (a=2 b=5 c=2)
> 然后根据b>1查到四条数据
> (a=2 b=2 c=3) (a=2 b=2 c=5) (a=2 b=5 c=1) (a=2 b=5 c=2)
> 此时要查找c=2了 但是我们发现 这四条数据的c分别是
> 3,5,1,2 是无序的 所以索引失效了
> 总结:
> 因为前一个条件相同的情况下,后续列才会是有序的。
>
>
>
>
> 🎃Tips:
> 应用开发中范围查询,例如:金额查询,日期查询往往都是范围查询。应将查询条件放置where语句最后。(创建的联合索引中,务必把范围设计到的字段写在最后)
>
>
>
### 3.7 不等于(!= 或者 <>)索引失效
为name字段创建索引
CREATE INDEX idx_name ON student(NAME);
查看索引是否失效
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name <> ‘abc’ ;
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE student.name != ‘abc’ ;
执行结果如下。

没有失效!!!这个原因还不是特别明确,可能mysql高版本中优化器又做了升级(毕竟不等于不过是等于的取反,确实可以实现优化)?笔者的mysql版本为8.2.06,如果有知道的大佬可以在评论区留言讨论。不过在实际生产或者面试中,这仍然可以作为一种需要关注的特殊情形。
### 3.8 is null可以使用索引,is not null无法使用索引
原因和原理一模一样。
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NULL;

EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE age IS NOT NULL;
同样的,在低版本中索引会失效,高版本中,索引也不会失效哦。

>
> 🎑结论:最好在设计数据库的时候就将 字段设置为 NOT NULL 约束。比如可以将 INT 类型的字段,默认设置为 0。将字符串的默认值设置为空字符串(“”)。
> 扩展:同理,在查询中使用 not like 也无法使用索引,导致全表扫描
>
>
>
### 3.9 like 以通配符 % 开头索引失效
在使用 LIKE 关键字进行查询的查询语句中,如果匹配字符串的第一个字符为“%”,索引就不会其作用。只有“%”不在第一个位置,索引才会起作用。
使用到索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE NAME LIKE ‘ab%’;
## 最后
**码字不易,觉得有帮助的可以帮忙点个赞,让更多有需要的人看到**
又是一年求职季,在这里,我为各位准备了一套Java程序员精选高频面试笔试真题,来帮助大家攻下BAT的offer,题目范围从初级的Java基础到高级的分布式架构等等一系列的面试题和答案,用于给大家作为参考
以下是部分内容截图

类型的字段,默认设置为 0。将字符串的默认值设置为空字符串(“”)。
> 扩展:同理,在查询中使用 not like 也无法使用索引,导致全表扫描
>
>
>
### 3.9 like 以通配符 % 开头索引失效
在使用 LIKE 关键字进行查询的查询语句中,如果匹配字符串的第一个字符为“%”,索引就不会其作用。只有“%”不在第一个位置,索引才会起作用。
使用到索引
EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE NAME LIKE ‘ab%’;
## 最后
**码字不易,觉得有帮助的可以帮忙点个赞,让更多有需要的人看到**
又是一年求职季,在这里,我为各位准备了一套Java程序员精选高频面试笔试真题,来帮助大家攻下BAT的offer,题目范围从初级的Java基础到高级的分布式架构等等一系列的面试题和答案,用于给大家作为参考
以下是部分内容截图
[外链图片转存中...(img-tKVS1gwg-1714428545534)]
> **本文已被[CODING开源项目:【一线大厂Java面试题解析+核心总结学习笔记+最新讲解视频+实战项目源码】](https://bbs.csdn.net/topics/618154847)收录**















 1059
1059











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









