






5、await 模型
…
在Java中,多线程 处理 并发编程 是 主要的处理方式。
线程安全问题 又称 竞态条件 问题。
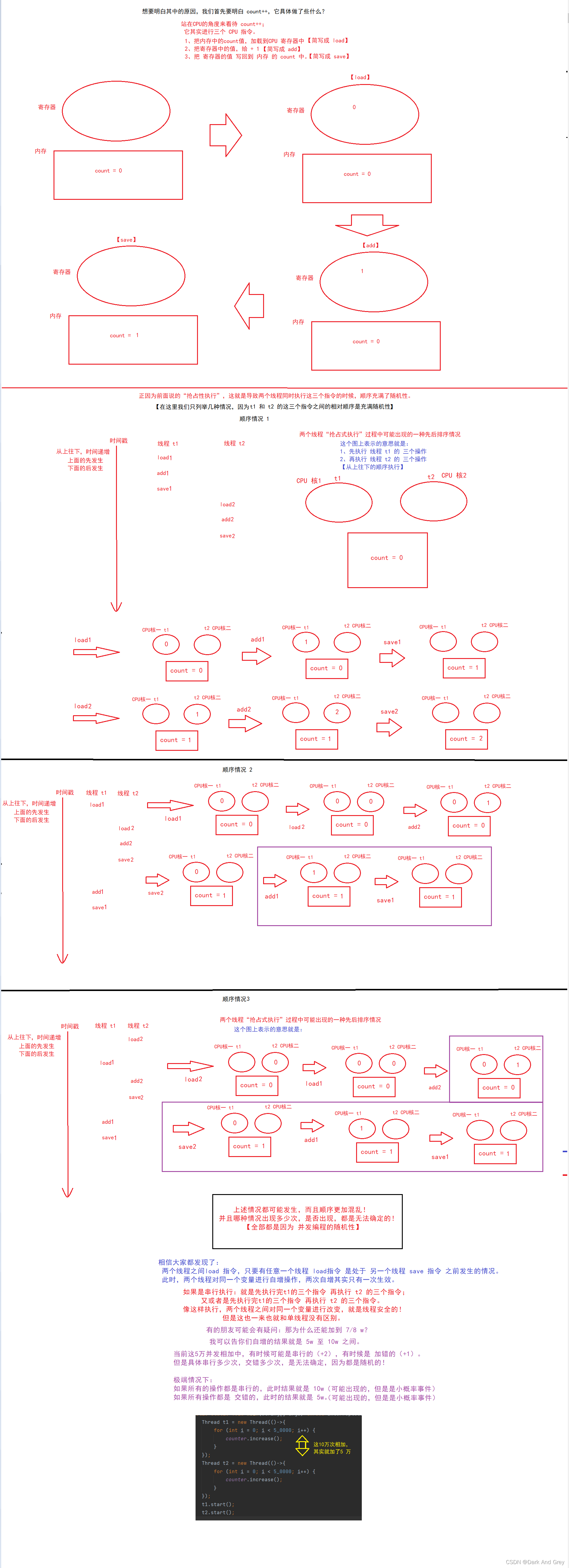
我们可以这么去认为:操作系统调度线程的时候,是随机的(抢占式执行)。
正是因为这样的随机性,就可能导致程序在执行的时候出现一些bug。
如果因为这样的调度随机性 引入了 bug,就认为代码是线程不安全的!
如果是因为这样的调度随机性,也没有带来bug,就认为代码是线程安全的!!
总得来说:衡量线程安全的关键,就是有没有bug。有bug 就是不安全的,无bug就是安全的.【在于代码本身的安全性】
跟我们平时谈到的“安全”是不一样。平时提到的 “安全”,主要是指 黑客 是不是会入侵你的计算机,破坏你的系统。
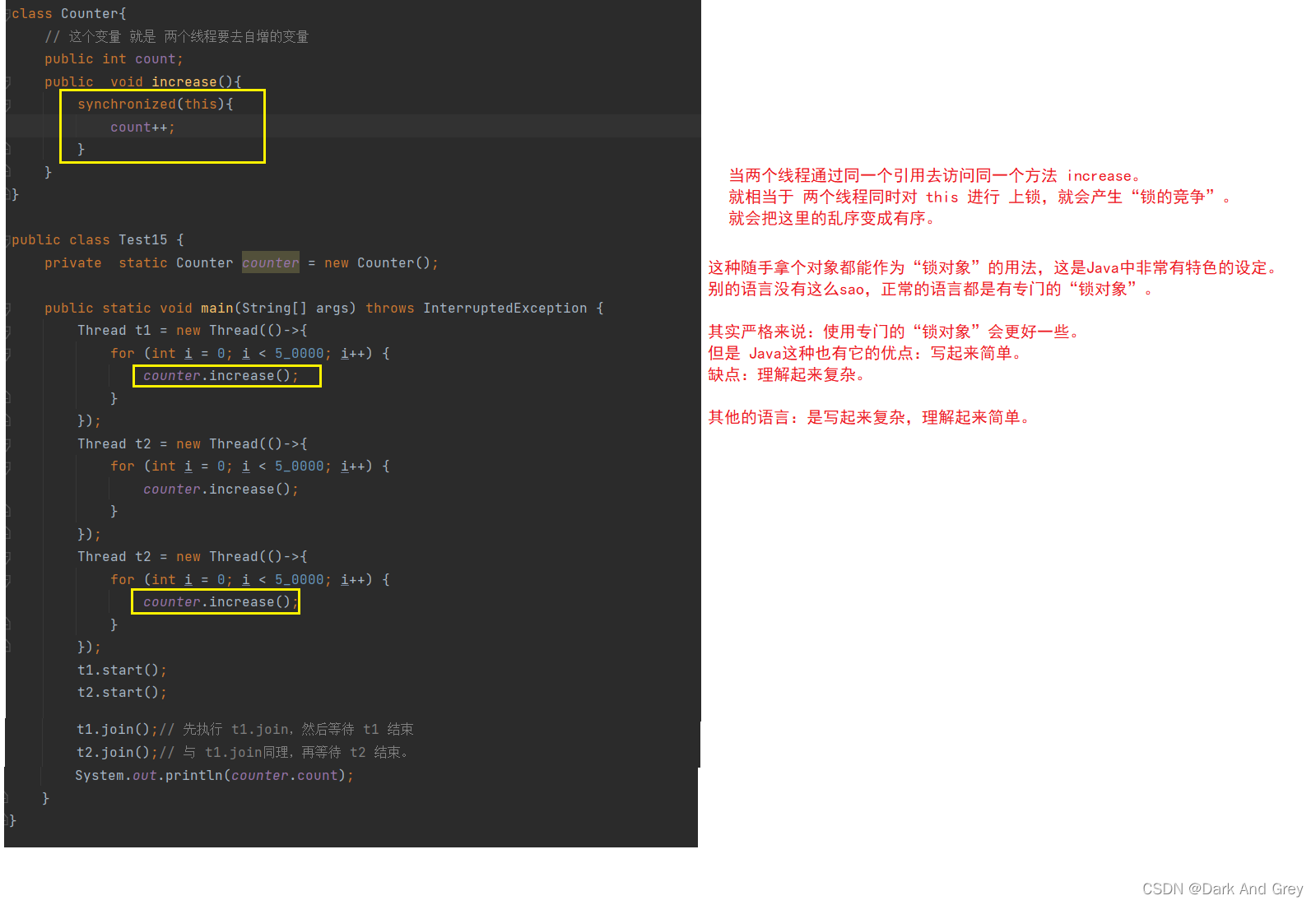
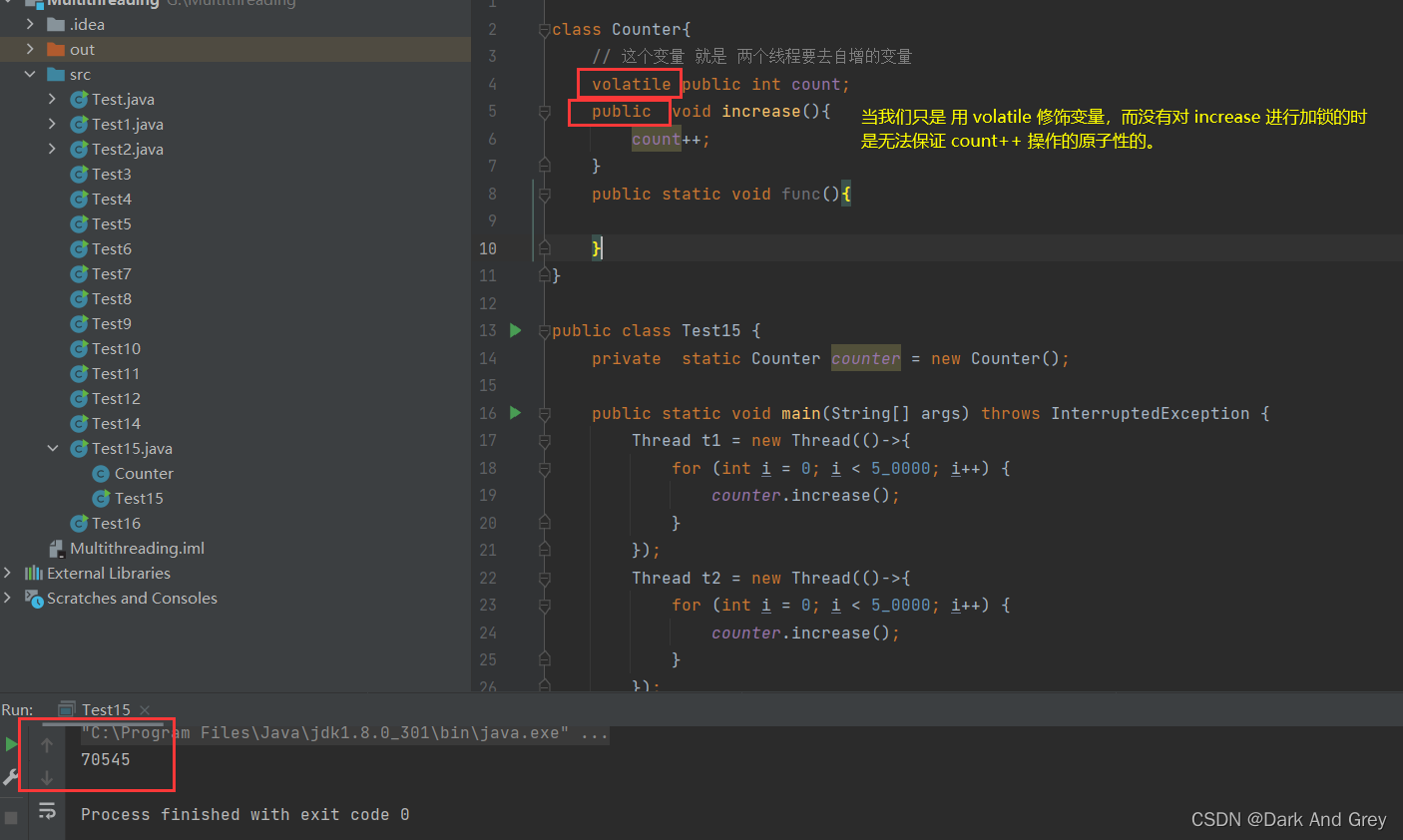
使用两个线程,对同一个整形变量 进行自增操作。
【每个线程对这个变量进行自增五万次,看最终结果】
class Counter{
// 这个变量 就是 两个线程要去自增的变量
public int count;
public void increase(){
count++;
}
}
public class Test15 {
private static Counter counter = new Counter();
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(()->{
for (int i = 0; i < 5_0000; i++) {
counter.increase();
}
});
Thread t2 = new Thread(()->{
for (int i = 0; i < 5_0000; i++) {
counter.increase();
}
});
t1.start();
t2.start();
// 为了保证得到的count的结果,是两个线程执行完毕后的结果
// 我们需要使用 join 来等待 线程 执行结束
// 这样在 main 线程中,打印的 count 的 结果,才是两个线程对 count 的 自增最终结果
// 因为 三个线程之间关系 为 并发关系。
// 如果不使用 join, main下城压根就不会等 t1 和 t2 自增完,直接输出count。
// 使用 join 之后,只有 t1 和 t2 线程都结束了之后,main线程才能结束。
t1.join();// 先执行 t1.join,然后等待 t1 结束
t2.join();// 与 t1.join同理,再等待 t2 结束。
// 这两个join,谁在前,谁在后,都无所谓!
//由于 这个线程调度 是随机的,我们也不能确定 是 t1 先结束,还是t2先结束。
// 就算 是 t2 先结束,t2.join也要等t1结束之后,t2.join才能返回。
// 当这两个线程结束后,main线程才会执行sout语句。
// 在 main 线程中 打印一下两个线程自增完成之后,得到的count的结果
System.out.println(counter.count);
}
}
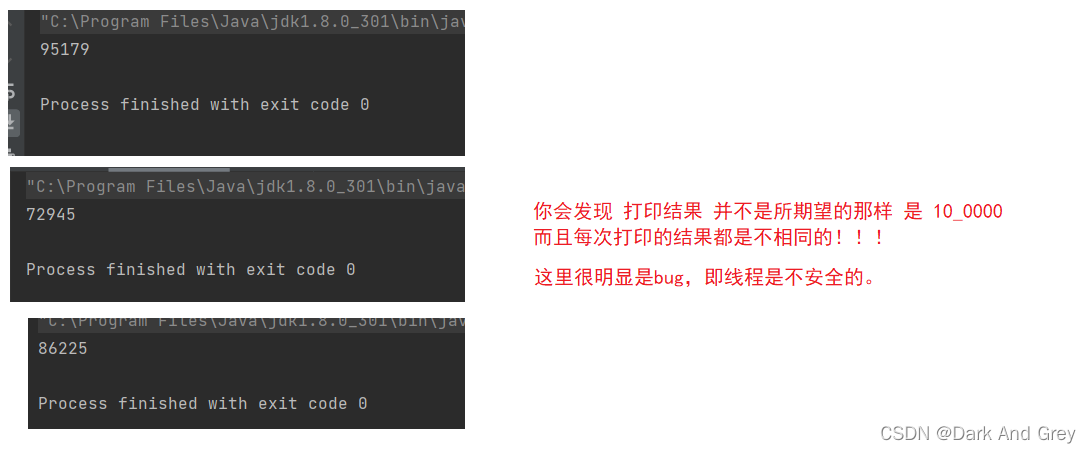
当两个线程之间 同时 对 同一个变量(与其变量的静态属性没有关系),进行并发自增操作的时候,就会出现一些情况。
这是因为 t1 和 t2 线程同时 对 count 进行加 1,照理说count应该被加上2了,但是实际上 count 值 只加了一个1。
【简单来说:两次 自增,count只加了1】
加锁 - synchronized

我们 通过 关键字 synchronized, 我们确实解决了代码的线程安全。
代码执行的结果也达到了我们的期望值。
标题也可以理解为:什么样子的代码会产生中线程不安全问题呢?
首先,我们要知道:不是所有的多线程代码都要加锁。
如果每个多线程的代码都进行加锁操作(synchronized),那么多线程的并发能力就跟没有一样。还不如直接写一个单线程代码的好。
产生线程不安全的原因如下:
1、线程是抢占式执行,线程间的调度充满着随机性。【造成线程不安全的直接原因,而且是无法解决的问题】
正是因为“抢占式执行” 才导致了 线程安全问题的出现。
假设,我们线程之间,不是 “抢占式执行”的,而是其它的调度方式。
那么,很可能就没有线程安全的问题了。
另外,拓展一下:
其实在操作系统中,不仅仅有 抢占式执行,还有 协商式执行的。
协商式:在调度线程的时候,让多个线程之间进行商量,看让那个线程来执行。
然后,在调度这个线程之前,先去让 正在 CPU 上执行的线程先去完成一些基本的工作,把该做的事做完了,再去调度。
但是目前大多数电脑的操作系统的执行方式都是 抢占式执行。
2、多个线程对同一个变量进行修改操作。
如果是 多个线程针对不同的变量进行修改操作,线程安全没有问题。
如果是多个线程针对同一个变量进行读取操作,线程安全也没有问题。
解决办法
放在代码中,我们可以通过调整 代码结构,来使不同的线程操作不同变量。
但是还是需要根据场景来判断使用,因为有些场景是不适合使用的。
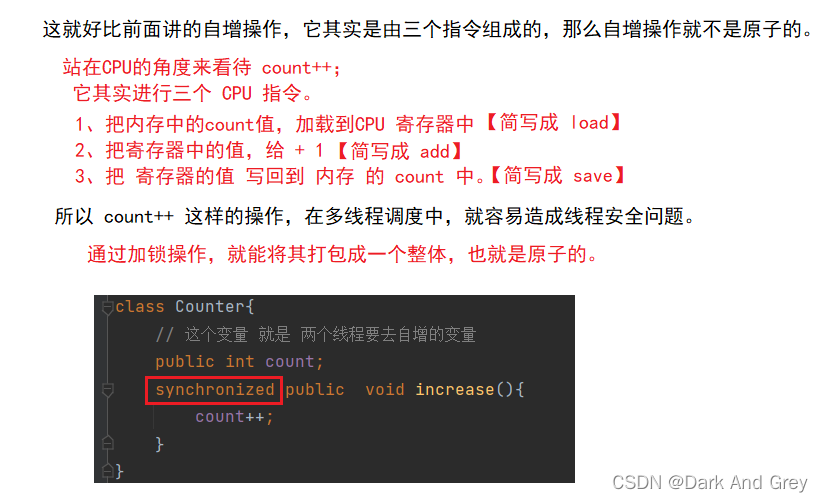
3、针对变量的操作不是原子的
在讲数据库MySQL的事务的时候,我们讲到过 将 几个操作打包成一个整体,要么就全部执行,要么就一个都不执行。
我们多线程中 “原子性” 也是一样的。
针对有些操作:
1、比如 读取变量的值,这个读操作只是对应一条 机器指令(这也是为什么说多个线程针对同一个变量读是安全的),此时这样的操作本身就可以是视为是原子的。
2、通过加锁操作,也就是把好几个指令给打包成一个原子的了。
这种方法是最长使用的一个操作。
通过 加锁操作,把这里的多个操作打包成一个原子的操作。
如果操作是原子的,那么线程安全就没有问题了。
4、内存可见性,也会影响到线程安全。
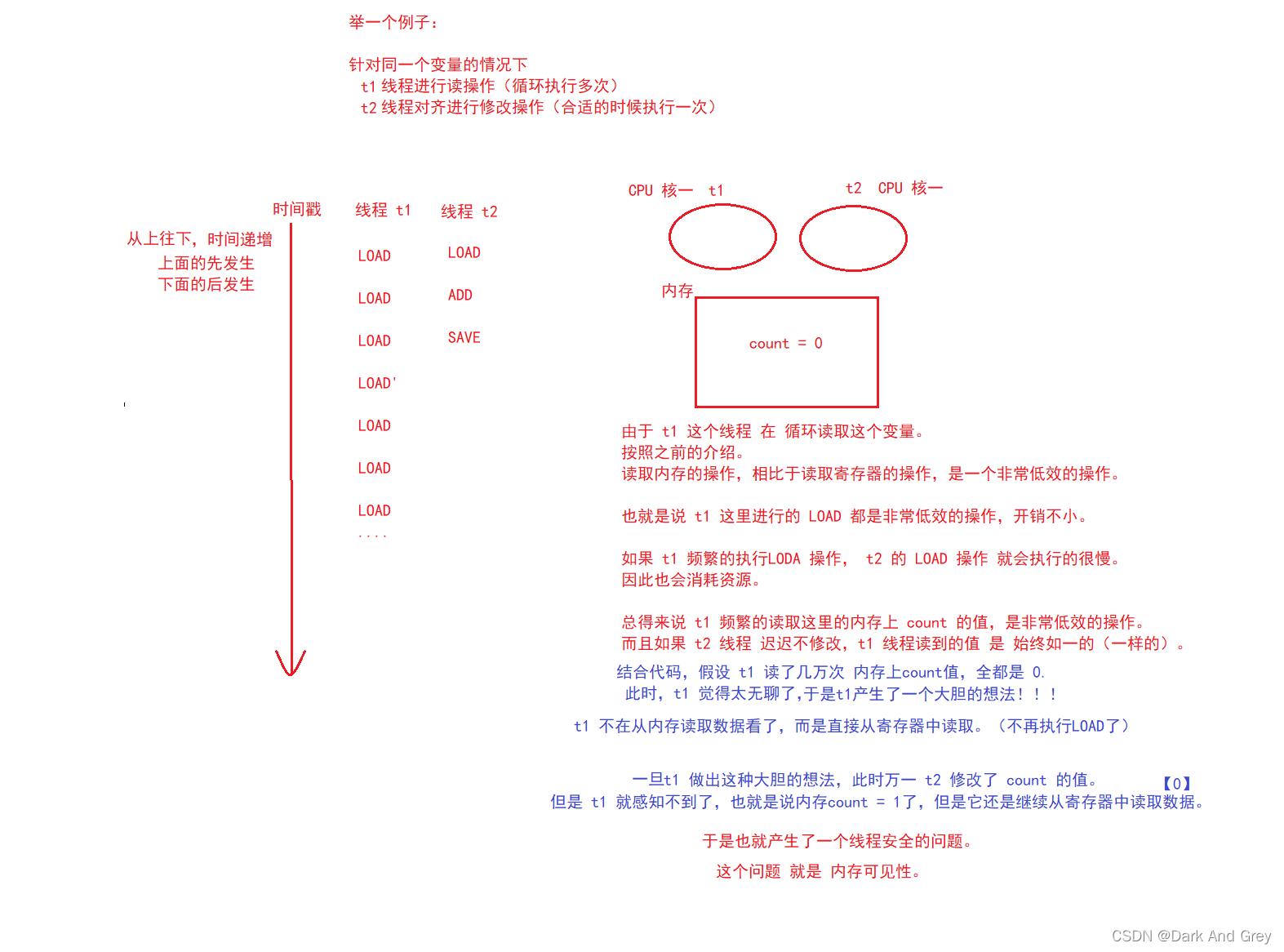
t1 这个大胆的操作 是 客观存在的!
是 Java编译器 进行代码优化 产生的结果。
现代编译器都会有这样优化功能,并且不止是 Java,还有C++、Python、各种主流的语里面都充满了 各种非常神奇的 “编译器优化操作”.
存在这样的优化机制,是因为 编译器不信任程序员。
换个说法:编译器假设这个程序员非常的垃圾,写的代码惨不忍睹。
编译器 就会 对 程序员 写的代码做出一些调整,在保证原有逻辑不变的前提下,提升程序执行的效率。【而且是大大提升!!!】
【实现编译器的程序员都是 大佬中的大佬】
但是! “编译器优化操作”在保证原有逻辑不变的前提下,提升程序执行的效率。
这个保证原有逻辑不变的前提下,大部分情况都是可以的。
但是在多线程中,是可能翻车的。
因为多线程代码中。它是一个并发执行,执行的时候充满着不确定性。
编译器在编译阶段,是很难预知到 执行 行为的!!
进行的优化,可能就会发生误判!!!
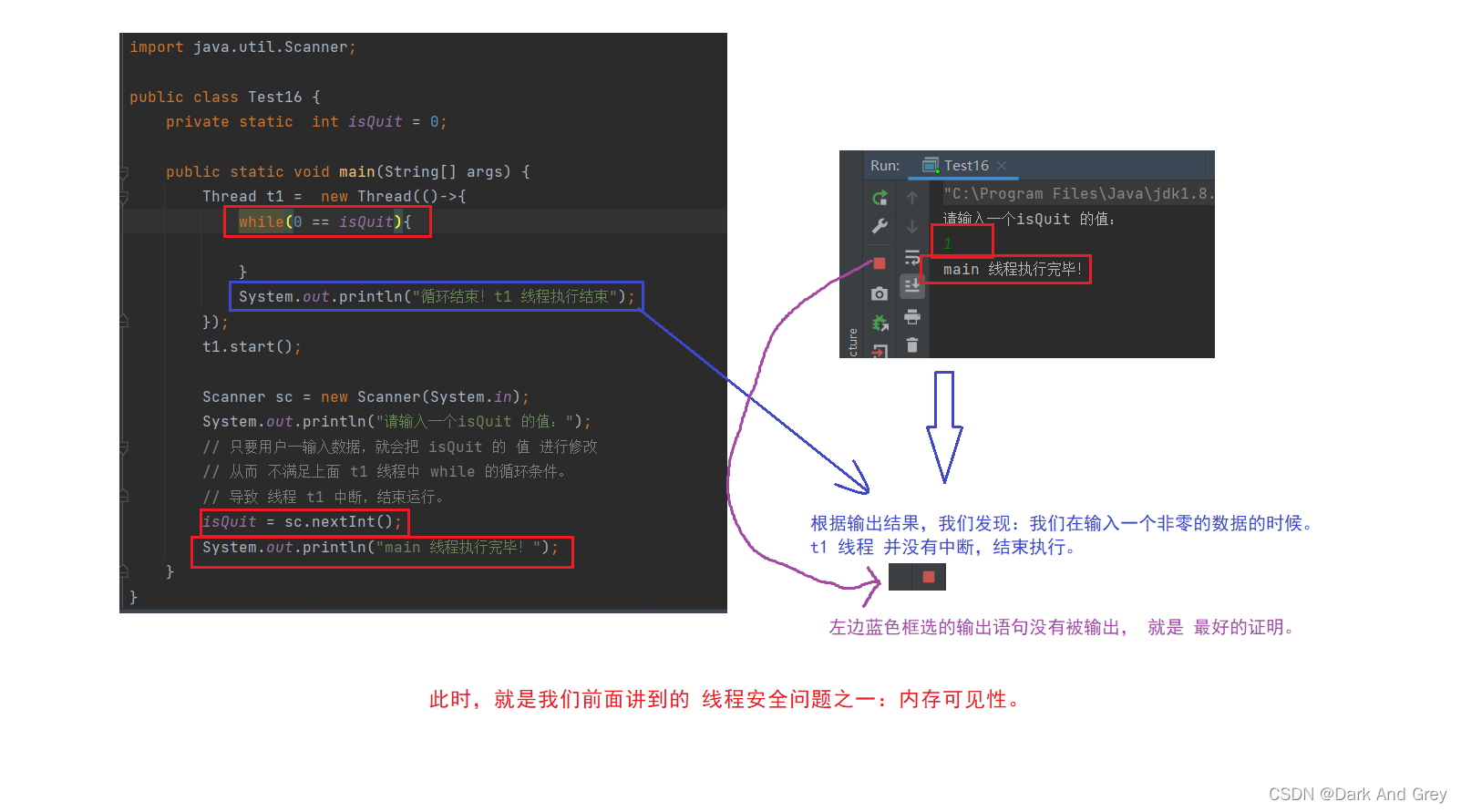
代码示例:针对 内存可见性 的线程安全问题
import java.util.Scanner;
public class Test16 {
private static int isQuit = 0;
public static void main(String[] args) {
Thread t1 = new Thread(()->{
while(0 == isQuit){
}
System.out.println("循环结束!t1 线程执行结束");
});
t1.start();
Scanner sc = new Scanner(System.in);
System.out.println("请输入一个isQuit 的值:");
// 预期理想情况:
// 只要用户一输入数据,就会把 isQuit 的 值 进行修改
// 从而 不满足上面 t1 线程中 while 的循环条件。
// 导致 线程 t1 中断,结束运行。
isQuit = sc.nextInt();
System.out.println("main 线程执行完毕!");
}
}
造成 线程安全问题之一 的 内存可见性 原因是:
t1 线程中 run 任务,正在不断的从内存读取数据。【我电脑的主频是2.8GHz,也就是说: 1s 可以执行 28 亿条 指令】
而这种操作,我们知道是非常低效的!
所以 t1 线程 做出那个大胆的想法(假设isQuit值不会再被改变),不再从内存中读取数据了。
改从 寄存器中读取数据,效率大大提升【寄存器的读取速度 大约是 内存的读取的 万倍左右】
所以 在 我们输入 1 来改变 isQuit 值的时候,此时 编译器已经是处在读取 寄存器中数据了,所以我们对 isQuit 值 的 改动,它是感知不到的内存中 isQuit变化!!!
从而 线程 t run 方法 的 循环条件 一直都是满足条件的,所以 run 继续执行,t1线程也就没有被中断。
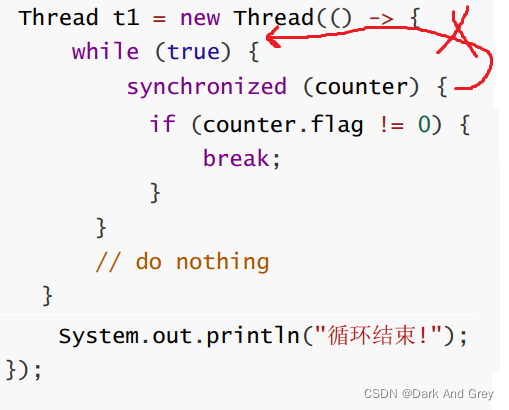
解决办法
1、加锁操作:使用 synchronized 关键字
synchronized 并不能保证内存可见性。
而是通过给循环里面进行加锁操作,导致循环的速度降低了。
因此没有处罚相关的优化操作,算是一种技巧吧。
如果,我们将 synchronized 加锁操作 放到 while外面,将 while循环包裹在内。
此时,再执行这个程序,就会发现:另一个线程修改了 flag, if 语句的条件判断也是感知不到的。
2、volatile 关键字 - 必须会读会写这个关键字

volatile 和 原子性无关,但是能够保证内存可见性。
换个说法:禁止编译器对其做出上述的优化操作,编译器每一次进行 判定相等的时候,都会重新从内存中读取 isQuit 的 值。
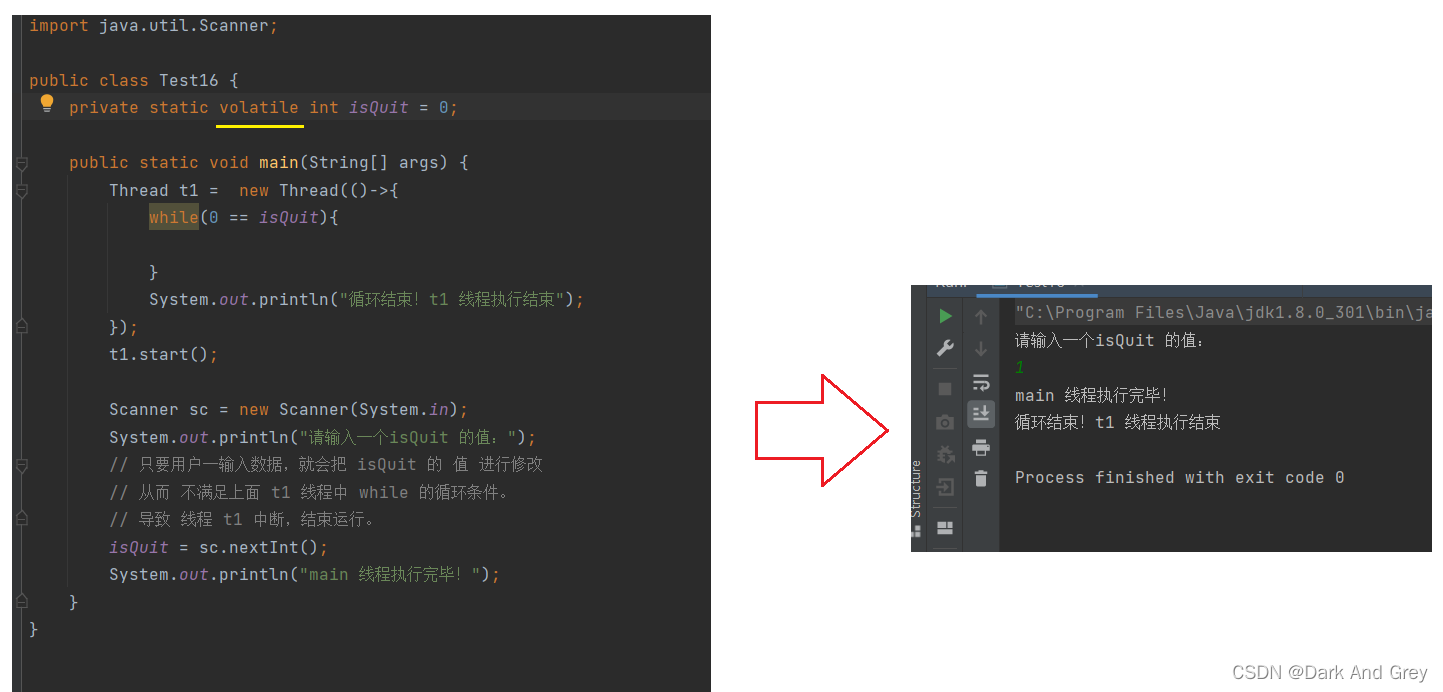
内存可见性 是属于编译器优化范围中的一个典型案例。
编译器优化机制,本身就是一个玄学问题,对于普通程序员来说:什么时候不优化,什么时候优化都是一个问题!
再将上面的那个列子改动一下
1、没有 volatile 关键字 来 修饰 isQuit
2、run方法中 while循环中添加了操作。
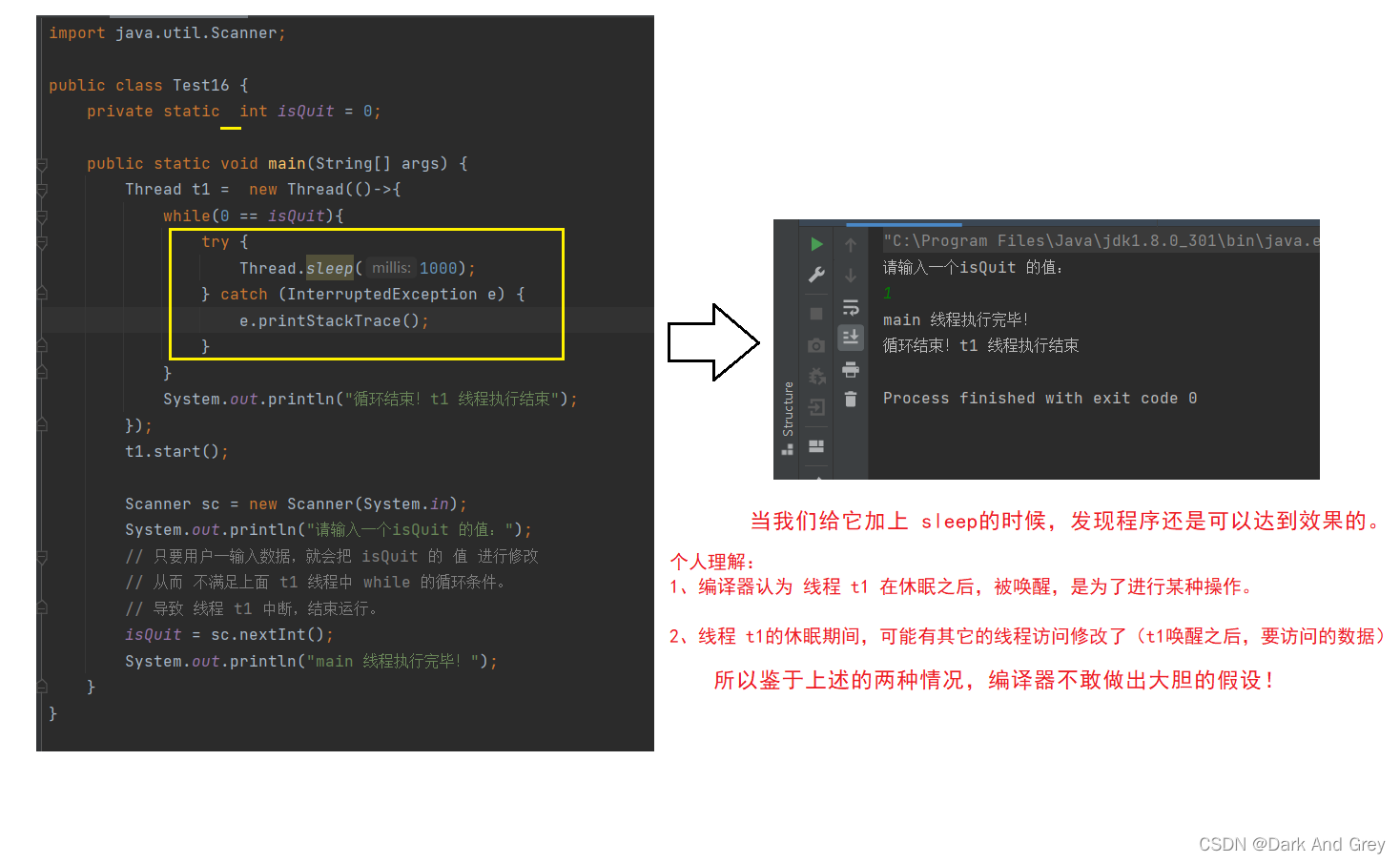
简单来说:就是像这种类型的代码,在循环中加上 sleep,编译器的优化机制就消失了。 也就没有内存可见性问题了、
其实还有一个最可能 不进行优化的原因:是因为 加上sleep(1000)之后,1s读一次,对于编译器来说,调用频率就不是很高了。所以也就没必要进行优化了。
5、指令重排序
指令重排序 也是编译器优化中的一种操作。
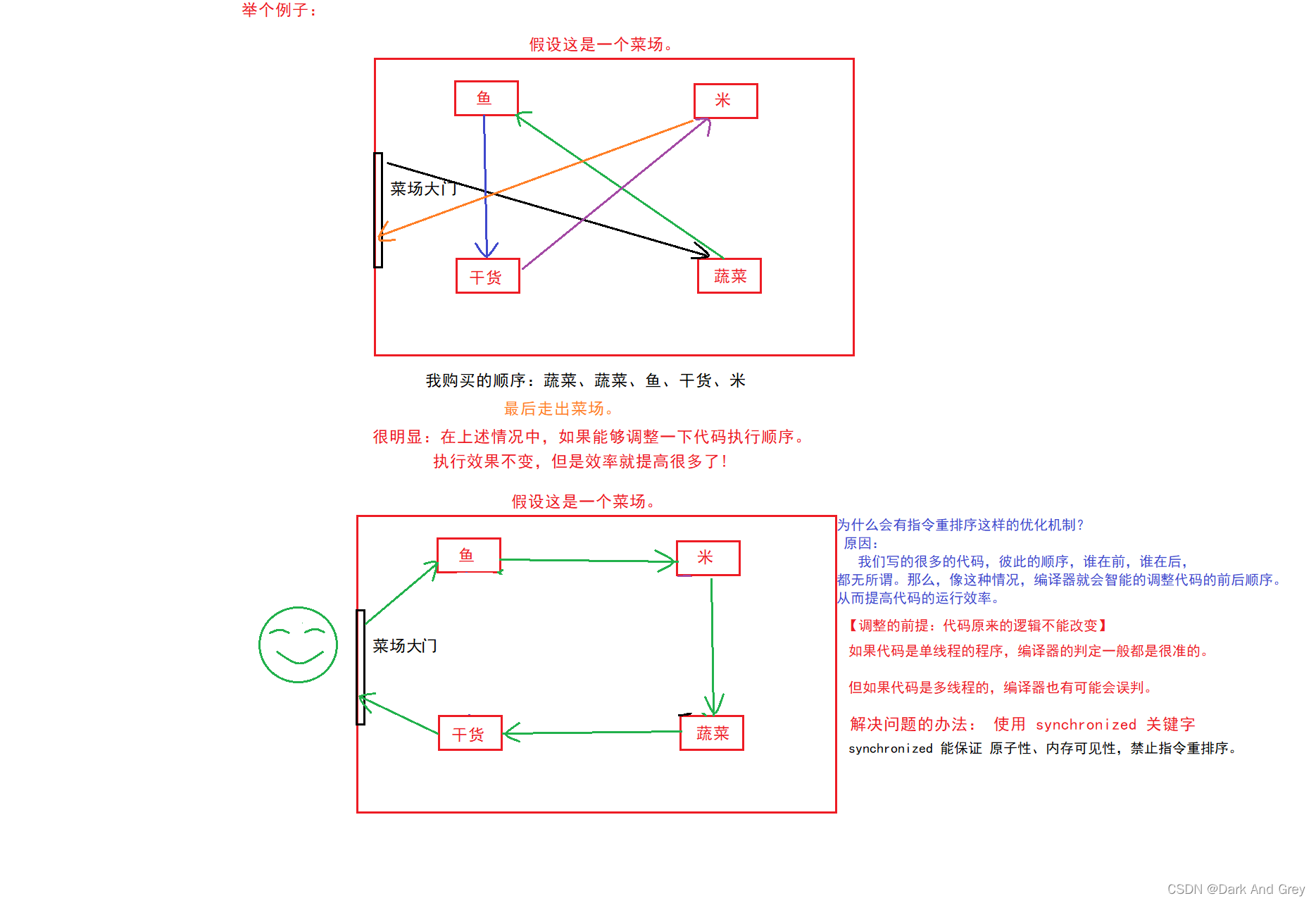
小结
上述介绍的五种情况,都是线程不安全的原因!
这几个原因都必须掌握!!
因为这些都是日常代码密切相关的!!!
重点解析 - synchronized 关键字 - 监视器锁 monitor lock
==========================================================================================================
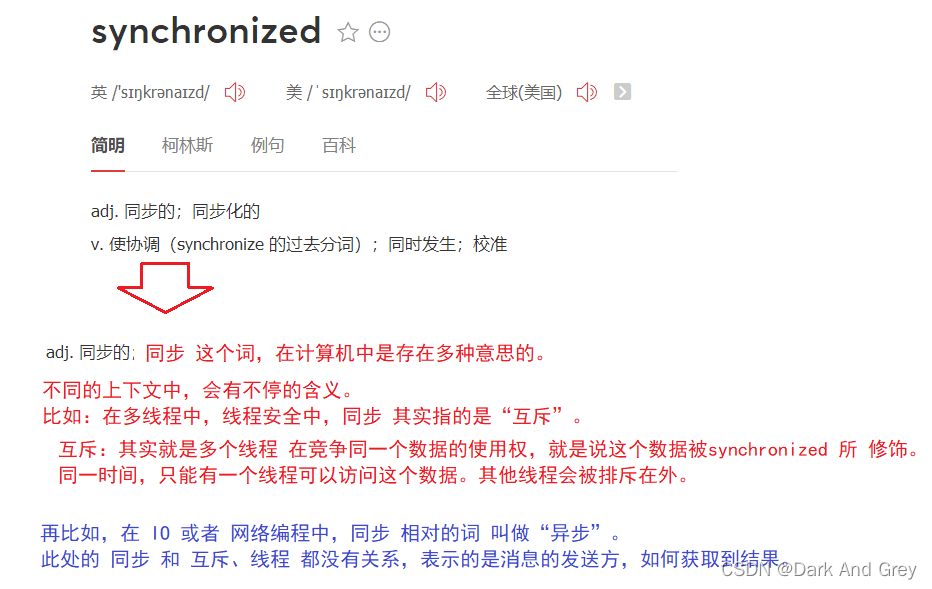
使用 synchronized 的时候,本质上是在针对某个“对象” 进行加锁。
什么意思呢?
这就要涉及到synchronized背后的一些故事。
其实我们的 synchronized 相当于是 针对 对象里的一个 对象头中的一个属性进行了一个设置。

1、直接修饰 普通方法。
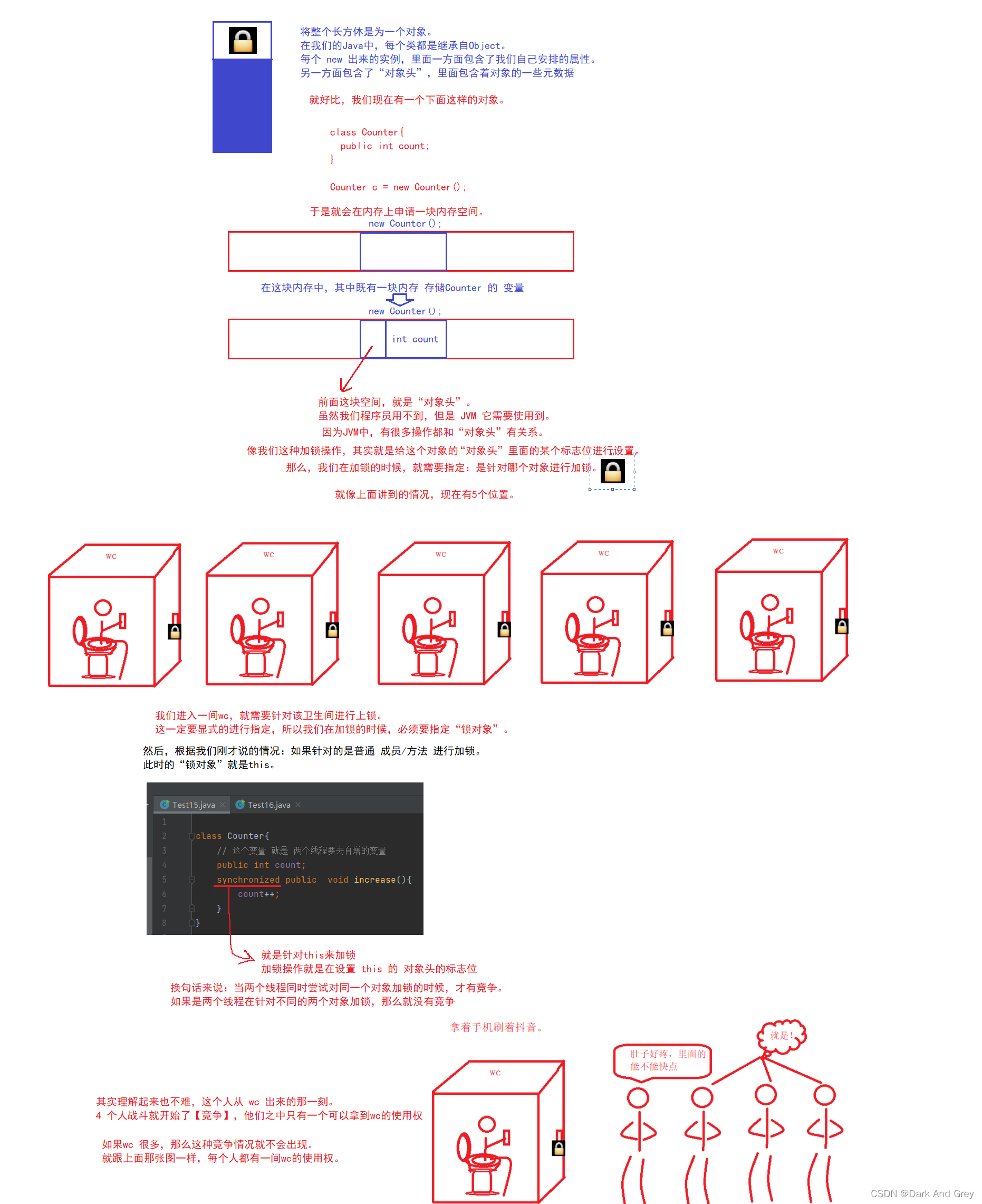
2、修饰一个代码块
需要显示指定针对哪个对象进行加锁。
Java中的任意对象都可以作为锁对象
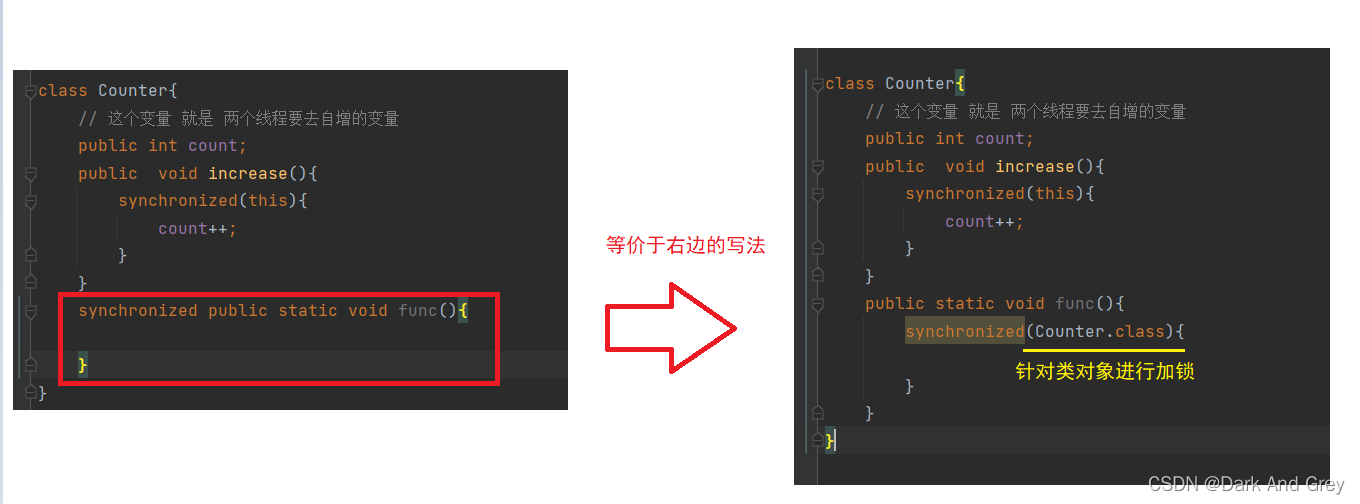
3、修饰一个静态方法
相当于针对当前类的类对象进行加锁。
例如
Counter.class (反射)
另外,思考一个问题:静态方法,有this吗?【没有】
更具体的来说:
所谓的“静态方法”,更严谨的叫法,应该叫做“类方法”。【通过类来调用】
普通方法,更严谨的叫法,应该叫做“实例方法”。【通过new实例化,才能访问】
回过头来,既然静态方法是没有this的,那么synchronized修饰一个静态方法,就是在针对类对象加锁。
小拓展:类对象是什么?
类对象就是,就是我们在运行程序的时候的 .class 文件 被加载到 JVM 内存中的模样。
就好比一个人,他很多“面”, 面对不同的人或事物,他的表现都不一样。
对于 .class文件 来说,它也具有很多面。
它原本存放在磁盘当中文件,但是当我们运行程序的时候,它就会加载到 内存中,而内存中的模样 就像 这样的 类名 .class 的类对象。
这样的类对象里面就包含这 .class文件的一切信息。
后续我们运行代码,访问这里面的属性 都和这里的.class文件 密不可分,甚至说我们创建实例的时候,也跟它有着密切的联系。
正是因为有了 类对象中的这些信息,进一步的,我们才能有 反射机制。
而反射机制都是来自于 .class 赋予的“力量”。
也就是说 你想要反射,就必须先要有类对象,才能进行下一步操作。
【反射中获取类对象 :”Class<?> c = Class.forName(“文件名”)】
标题提到 synchronized 又称 监视器锁 monitor lock。
对于这个 monitor lock,大家要有所印象!
有些时候,代码中的异常信息,可能会提到 monitor 这个词。
synchronized 的工作过程
1、 获得互斥锁
2、 从主内存拷贝变量的最新副本到工作的内存
3、 执行代码
4、 将更改后的共享变量的值刷新到主内存
5、 释放互斥锁
这也是为什么前面 synchronized 可以解决 内存可见性的线程问题。
直观来说:同一个线程针对同一个锁,连续加锁两次。
如果出现了死锁,就是不可重入,如果不会死锁,就是可重入。
死锁 其实非常容易理解,直白来说就是卡bug。
举个例子:
假设,路人甲 在 某一个厂里工作。
有一天他工作回来,准备回宿舍睡觉。
但是!走到宿舍门口后,被保安拦下来了。
他说:“由于疫情原因,我需要检查一下你的厂牌,否则不能进!”
路人甲,摸了摸自己的口袋,发现没有,与此同时他想起来今天没有带,厂牌还在宿舍里。
于是说:“能不能先让我进去,我进寝室里拿厂牌给你,我可以把手机压在这里。”
解雇这保安是一个死脑子,说:“没有厂牌是吧,那不能进!”
路人甲就急了,你不让我进去,我怎么拿厂牌给你看,而且我还把手机在这里!
而这保安就是死活不听,非要看到厂牌,否则不让进。
此时这两个人,再怎么争执,也没有用。两个人就在这里卡bug。
这种情况就是 “死锁”。

放在实际情况中,这种代码还是很有可能会写出来的。如果没有进行特殊处理,这种代码也确实非常容易死锁。
如果代码真的死锁了,岂不是实程序员的 bug 就太多太多了。
实现 JVM 的大佬们显然也注意到了这一点,就把 synchronized 实现成了可重入锁。
对于 可重入锁来说:上图中连续加锁的操作,不会导致死锁。
可重入锁内部,会记录当前的所被哪个线程占用,同时也会记录一个“加锁次数”。
假设: 线程 a 针对锁,第一次加锁的时候,肯定是能加锁成功。
此时锁内部记录了,当前占用锁的线程是 a,同时加锁次数为 1。
后续再对 a 进行 加锁,此时就不是真的加锁,而是单纯的把 加锁次数进行自增。
【后续的加锁操作 是没有实质的影响的】
最后解锁的时候,每解一次锁,就是将 加锁次数进行 - 1。
当 加锁次数 减到 0 的 时候,就是真的解锁了。
可重入锁的意义就是降低了程序员的负担。
降低了使用成本,提高了开发效率。
但是也需要付出代价,代码需要更多的内存开销,来维护锁 属于哪个线程,并且加减计数。
也就是说: 降低了使用成本,提高了代码的开发效率的同时,也降低了代码的运行效率。
小拓展:开发效率 和 运行效率 谁更重要?【两者是不能共存的,需要作出取舍】
这就涉及到 程序员的 “核心价值观”。
程序员也是要追求幸福感的!
程序员的幸福感,具体体现在 2 个 方面:
1、挣得多【月入2w 肯定比月入 4、5千要幸福的多】
2、加班少【朝九晚五,甚是美哉】
结合上面的 开发效率 和 运行效率,那个更能提升我们的幸福感?显然是 开发效率,但是执行效率就低了。
理由:
拿重入锁来举例,如果我们使用的是不可重入锁,此时的开发效率就低了(一不小心,代码就死锁了,线上程序出现了问题,就意味着要加班修bug,同时bug比较严重,年终奖可能就要没了),但是运行的效率提高。
从另一方面来说:程序员的主要工作就是 驱使机器做事。我们能让机器多做一点事,就让机器多做一点,让人少做一点点,都是好的!!
不光是 程序员 举的开发效率高更好。
同时公司(组本家) 也觉得开发效率更好,在互联网圈子中,人力成本是非常高的!!
拓展 :死锁的其他场景
1、一个线程。一把锁
就是我们上面讲的那个。

两个线程,两把锁

N个线程了,M把锁。
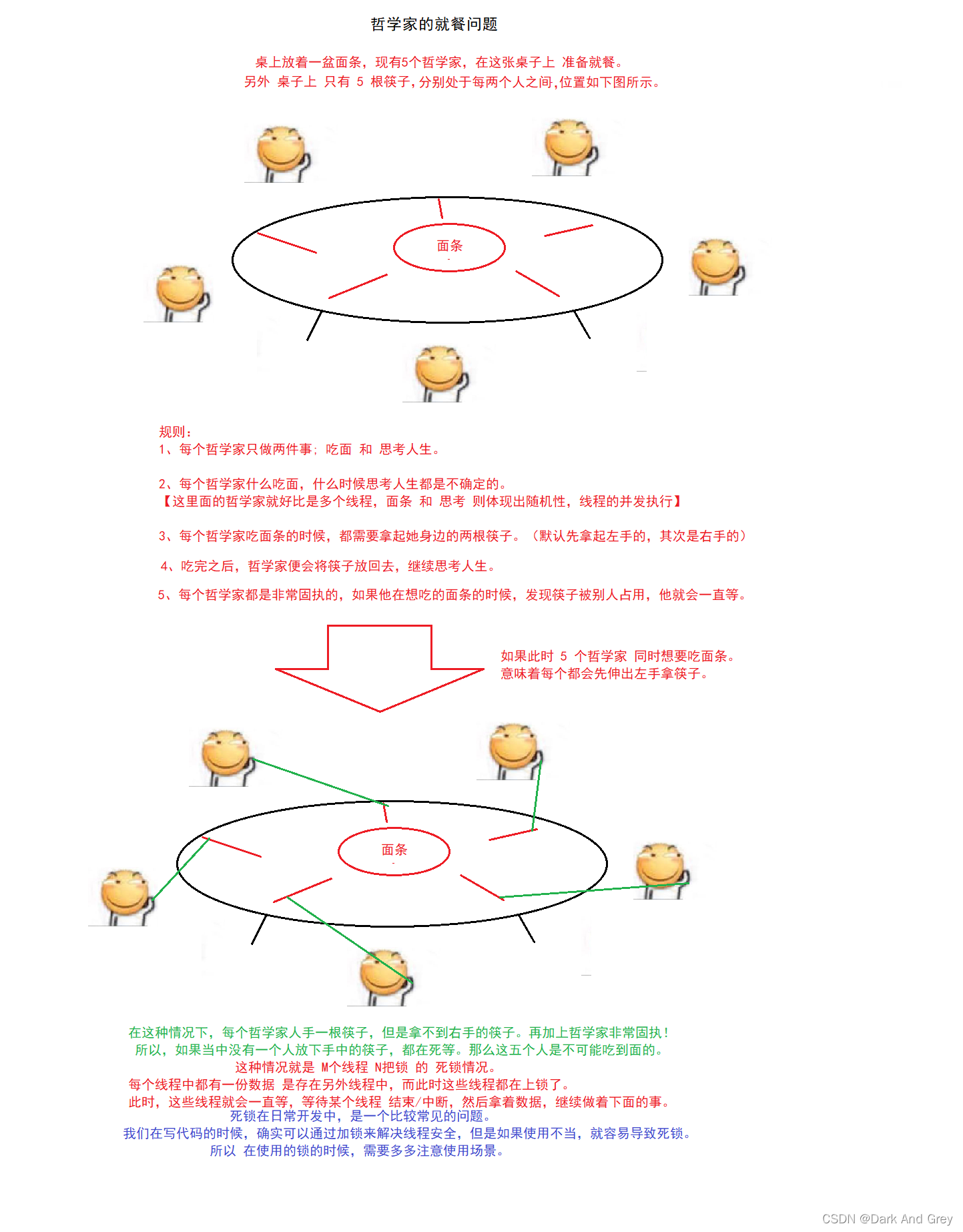
这个情况更复杂,我们来使用一个教科书上的经典案例。
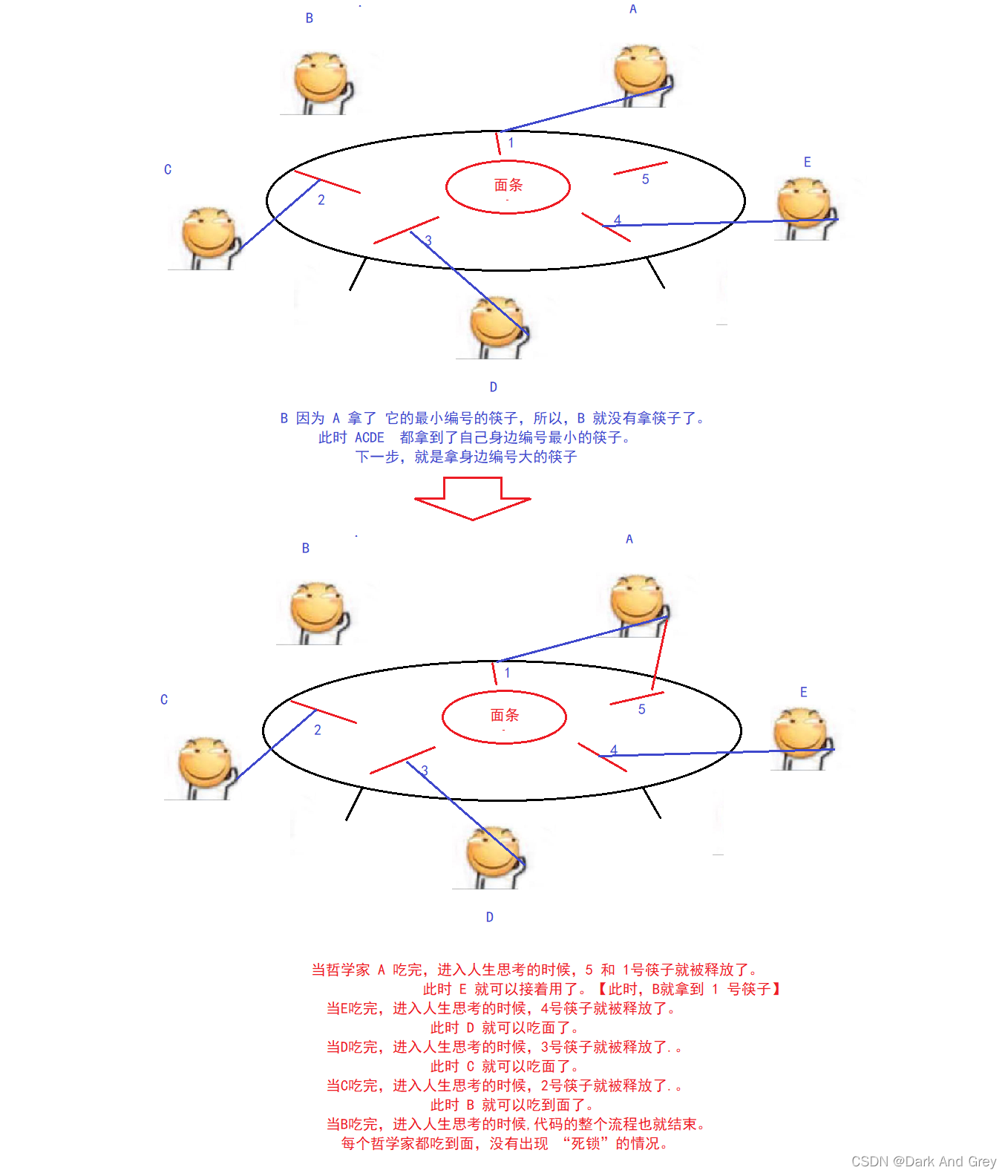
解决方法
但是在实际开发中,很少出现这种一个线程需要锁里再套锁的情况
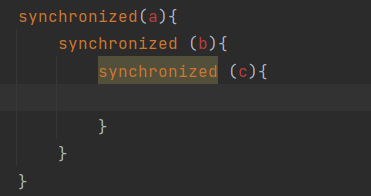
如果不嵌套使用锁,也就没那么容易死锁了。
如果我们的使用场景,不得不进行嵌套的时候,大家一定要记得,一定要约定好加锁的顺序。
所有的线程都按照 a->b->c 这样的顺序进行加锁。
千万别有的线程 a->b->c,有的线程 c->b->a,这样就很容易出现循环等待。
小结:死锁的四个必要条件
1、互斥使用:一个所被一个线程占用了之后,其它线程占用不了。【锁的本质:保证原子性】
2、不可抢占:一个锁被一个线程占用了之后,其它的线程不能把这个锁给抢走。
3、请求和保持:当一个线程占据了多把锁之后,除非显式的释放锁,否则这些锁始终都是被该线程持有的。
4、环路等待:等待关系形成了一个环 。【A 等 B,B 等C,C 又等 A】
前三条 都是属于 锁本身的特点。
实际开发中要想避免死锁,关键点还是从 4 个条件出发进行切入。
如何避免出现环路等待?
只要约定好,针对多把锁加锁的时候,有固定的顺序即可。
所有的线程都遵守同样的规则顺序,就不会出现环路等待。
=============================================================================
Java有很多线程的类,有些是线程安全的,有些是不安全。
在多线程环境下,如果使用线程不全的类,就徐亚谨慎。
ArrayList
LinkedList
HashMap
TreeMap
HashSet
TreeSet
StringBuilder
Vector (不推荐使用)
HashTable (不推荐使用)
ConcurrentHashMap
StringBuffer
String
前四个类是线程安全的,是因为在一些关键方法上都有 synchronized 修饰 / 加锁。
有了这个操作,就可以保证在多线程环境下,修改同一个对象,就没有大问题。
Vector 对标的是 ArrayList 。
HashTable 和 ConcurrentHashMap对标的是 HashMap。
【更推荐使用 ConcurrentHashMap,因为HashTabe 存在一些性能上的问题】
StringBuffer 和 StringBuilder 功能上都一样的。只是StringBuffer 加上了 synchronized,适用于多线程,而StringBuilder没有synchronized的,适用于单线程。
至于第五个 String 虽然也是线程安全的,但是与前4个类不同,它有些特殊。
它没有 synchronized。
String 是 不可变对象,故无法在多个线程中同时改同一个String。
哪怕是在单线程中也无法改 String、【要想改变只能创建一个新的,来代替旧的】
拓展:
不可变对象 和 常量 / final 之间没有必然联系。
不可变对象 之所以不可变,是因为对象中没有提供 public 的 修改属性的操作。
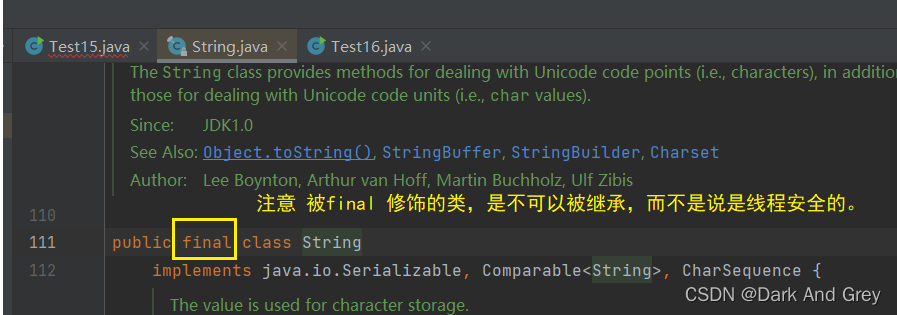
而且你可以自己去翻一下 String 底层的方法,就可以发现没有一个可以修改字符串里面内容的 public 方法。
正因为不可变对象有这样的特性,有的编程语言,就天然把所有的对象来设计成不可变。然后,这样的语言就更方便处理并发问题。
比如: Erlang,这个语言就是如此,里面就没有变量这个东西,都是属于不可变的量。
===========================================================================
volatile 修饰的变量,能够保证“内存可见性”。
换个说法:禁止编译器优化,保证内存可见性。
前面也讲到了,之所以存在 “内存可见性”问题,是因为我们的计算机的硬件所决定的。

volatile 关键字 只能保证“内存可见性”,但不能保证原子性。
volatile 只是处理 一个线程度,一个线程写的情况。
synchronized 都能处理。
volatile 和 synchronized 的区别 - 面试会问到。
这两个本来就没有什么联系。
只是在 Java 中 恰好都是关键字。
其他语言,加锁不是关键字,C++中的锁就是一个单独的普通类而已
拓展:
synchronized 不能 无脑使用,凡事都是有代价的。
代价就是一旦使用synchronized 很容易使线程阻塞,一旦线程阻塞(放弃CPU),下次回到CPU的时间就不可控了。【可能就是一辈子,因为 可能有几个线程在卡bug】
如果调度不回来,自然对应的任务执行时间也就是拖慢了。
用一句话来说 synchronized:一旦使用了 synchronized,这个代码大概率就和“高性能无缘了。
开发效率高,固然好,但有些时候还是需要考虑执行效率的。
volatile 就不会引起线程阻塞。
=====================================================================================
wait 和 notify 为了处理线程调度随机性的问题。
还是那句话,多线程的调度,因为它的随机性,就导致代码谁先执行,谁后执行,存在太多的变数。
而我们程序员是不喜欢随机性,我们喜欢确定的东西。
需要能够让线程彼此之间,有一个固定的顺序。
举个例子:打篮球
篮球里面有一个典型的操作:传球,上篮。
那么我们肯定得先传球,再上篮。需要两个队员的相互配合。
两个队员也就是两个线程。
如果是先做个上篮动作,但是球没到,也就上了个寂寞。
一般最稳的方法,都是先传球再上篮。
像这样的顺序,在我们实际开发中也是非常需要的。
因此我们就需要有手段去控制!
前面讲到的 join 也是一种控制顺序的方式,但是join更倾向于控制线程结束。因此 join 是有使用的局限性。
就不像 wait 和 notify 用起来更加合适。
wait 和 notify 都是 Object 对象的方法。
调用 wait 方法的线程,就会陷入阻塞,阻塞到有其它线程通过 notify 来通知。
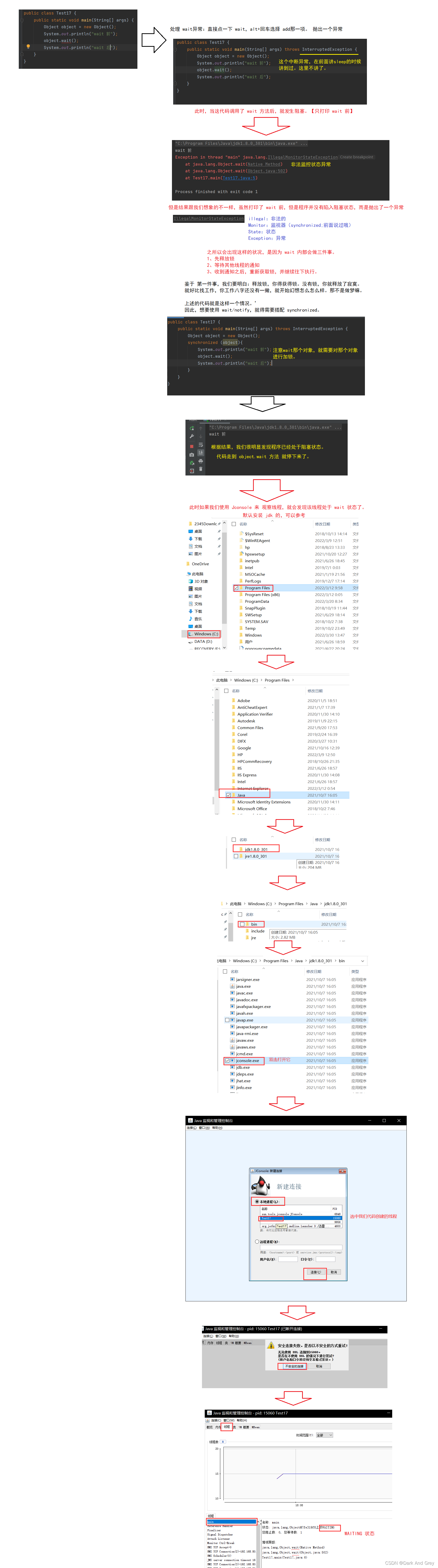
目前,我们只是使用了 wait 方法,
接下来 我们来实践一下: notify 和 wait 的组合使用
wait 使线程处于阻塞状态,notify 来唤醒 调用wait 方法陷入睡眠的线程。
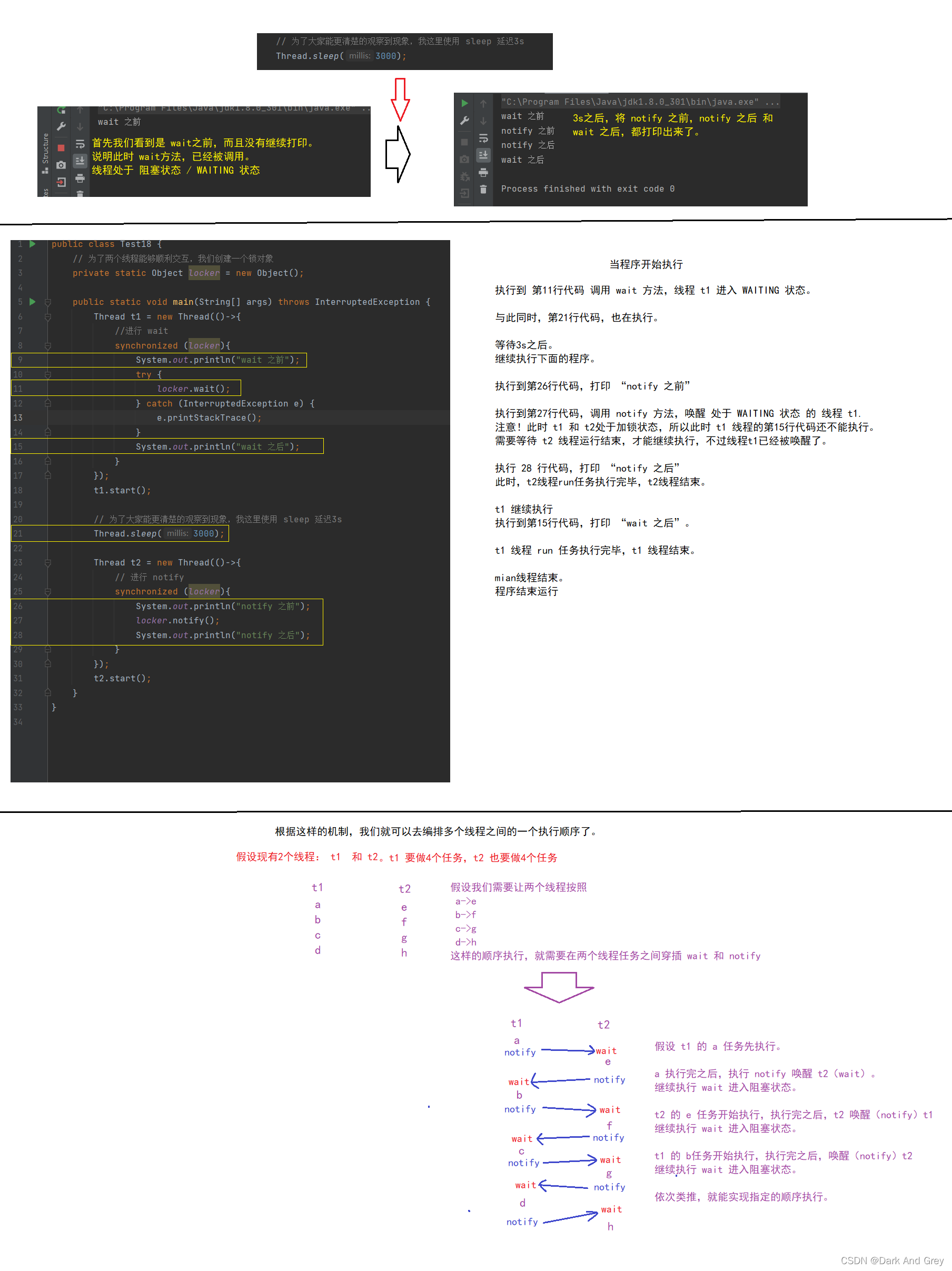
public class Test18 {
// 为了两个线程能够顺利交互,我们创建一个锁对象
private static Object locker = new Object();
public static void main(String[] args) throws InterruptedException {
Thread t1 = new Thread(()->{
//进行 wait
synchronized (locker){
System.out.println("wait 之前");
try {
locker.wait();
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println("wait 之后");
}
});
t1.start();
// 为了大家能更清楚的观察到现象,我这里使用 sleep 延迟3s
Thread.sleep(3000);
Thread t2 = new Thread(()->{
// 进行 notify
synchronized (locker){
System.out.println("notify 之前");
locker.notify();
System.out.println("notify 之后");
}
});
t2.start();
}
}
前面说的 wait 和 notify 都是针对同一个对象来操作。
例如:
现在有一个对象 o,被 10个线程调用了 o.wait。
此时 10 个 线程都是阻塞状态。
如果调用了 o.notify,就会把 10个线程中的一个给唤醒。【随机唤醒:不确定下一个被唤醒的线程是哪一个】
被唤醒的线程就会继续往下执行。其他线程仍处于阻塞状态。
如果调用的 o.notifyAll,就会把所有的线程全部唤醒。
wait 在被唤醒之后,会重新尝试获取到锁,这个过程就会发生竞争。
也就是说:唤醒所有的线程,都去抢锁。
抢到的,才可以继续往下执行。
没抢到的线程,继续等待,等待下一次的 notifyAll。
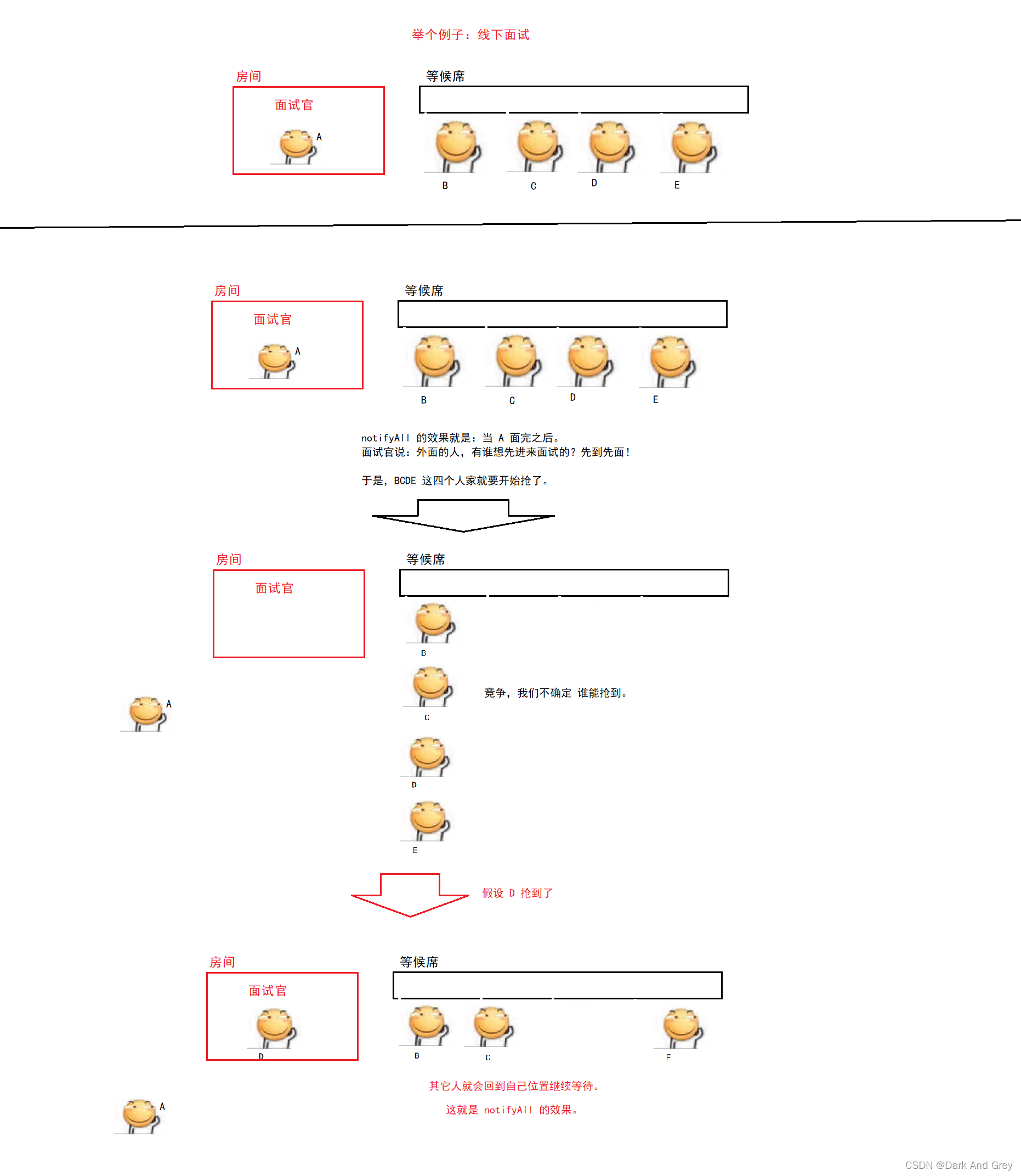
其实不难发现:与其notifyAll一次唤醒全部线程,还不如notify一个接着一个人唤醒。
因为 一次唤醒全部线程会造成竞争,不缺定下一个占用锁的是哪一个线程8。
而 一次唤醒一个,既能保证执行顺序,又可以不发生竞争。
对于日常使用来说:notify 更常用!
=================================================================
目前为止,我们讲了
1、线程的基本概念
2、Thread 类
2.1、创建线程
2.2、中断线程
2.3、等待线程
2.4、获取线程实例
2.5、线程休眠
3、线程状态
4、线程安全问题(最重要)
5、内存可见性
6、wait / notify
掌握这些,就可以完成一些多线程的开发任务了。
=======================================================================
线程安全,我们已经知道了。
但是 单例模式又是一个新的东西。
单例模式:设计模式之一。
设计模式:可以理解为“棋谱”,就是说:设计模式就是一些固定的代码套路。
当下棋,下到一种程度。都会去学习棋谱,也就是学习下棋的招数 和 应对之法。
代码中,有很多经典场景。
经典场景中,也就有一些经典的应对手段。
一些大佬们就把这些常见的应对手段,给收集整理起来,起了个名字,就叫“设计模式”。
不要想得太nb,就是收集资料整理得出的结果,俗称套路。
这些套路就可以让程序员(哪怕是新手),按照套路去写,就不至于把代码写的太差。(就像做PPT一样,下一个模板,自己去填充)
从客观角度出发,可能很多的程序水平一般。
因此,如何才能保证 即使程序员水平一般,也能代码写好?
那就需要通过 设计模式 来去做出规范。
另外,关于“设计模式”的书,有不少。
我推荐是不着急去学习更多关于“设计模式” 的东西。
我们当前需要解决的问题是从无到有。
直白点说 就是 从不会写,到能写出来。
这是因为 “设计模式” 这个东西,它从 有 到 优。
就是说:我们本来就会写,只是写得不是很好。现在就可以通过设计模式,来进行进一步的优化代码。
所以话说回来,我们目前的重点:是从无到有,从不会写到会写。
不过也别着急,等我们工作了,有了一定工作经验,这些东西你都会遇到的。
而且只要代码敲得多了,问题也就不存在了。
虽然 “设计模式” 不着急学。
但是!我们不能完全不会!
至少校招中,有两种“设计模式”是常提问的。
1、单例模式
2、工厂模式
这个我后面都会讲,这里先关注于 “单例模式”。
单例模式
要求我们代码中的某个类,只能有一个实例,不能有多个实例。
实例就是对象。
就是说某个类只能new 一个对象,不能new多个对象。
这种单例模式,在实际开发中是非常常见的,也是非常有用的。
开发中的很多“概念”,天然就是单例的。
比如说:我前面写的MySQL 的 JDBC编程 里面,有一个DataSource(数据源)类,像数据源这样的对象就应该是单例的。
毕竟作为一个程序,数据源应该只有一个。
有一个源就可以了,我们只要描述这些数据只来自于 一个 数据源, 就行了。
像这种,就应该像是一个单例。
我在讲 JDBC 并没讲那么多,现在我来说一下:在真实情况下,像这种数据库的数据源都会被设计成单例模式的。
大部分跟数据有关的东西,服务器里面只存一份。那么,就都可以使用“单例模式”来进行表示。
单例模式的两种典型实现
单例模式中有两个典型实现:
1、饿汉模式
2、懒汉模式
我们来通过一个生活上的例子来给大家讲讲什么是饿汉模式,什么是懒汉模式。
洗碗,这件事不陌生把?
第一种情况:
假设我们中午吃饭的时候,一家人用了4个碗。然后吃完之后,马上就把碗给洗了。
这种情况,就是饿汉模式。
注意!饿汉模式的 “饿” 指的是着急的意思,不是肚子饿。
第二种情况
中午吃饭的时候,一家人用了4个碗。然后吃完之后,碗先放着,不着急洗。
等待晚上吃饭的时候,发现只需要2个碗。
那么就将 4个没洗的碗 中,洗出2个碗,拿来用。吃完之后,碗先放着,不着急洗。
如果下一顿只用一个玩,就洗出1个碗。
简单来说:就是用多少,拿多少。少的不够,多的不要。
这就是懒汉模式
懒汉模式不推荐现实生活中使用,挺砸吧的。。
但是在计算机中,普遍认为 懒汉模式 比 饿汉模式好。
主要因为 懒汉模式 的效率更高
也很好理解:洗 2 个 碗,肯定比洗4个碗轻松。
所以用几个洗几个。
根据需要,进行操作。
“懒” 这个字一般 在计算机中,是一个褒义词。
1、饿汉模式
饿汉的单例模式,是比较着急的去进行创建实例的。
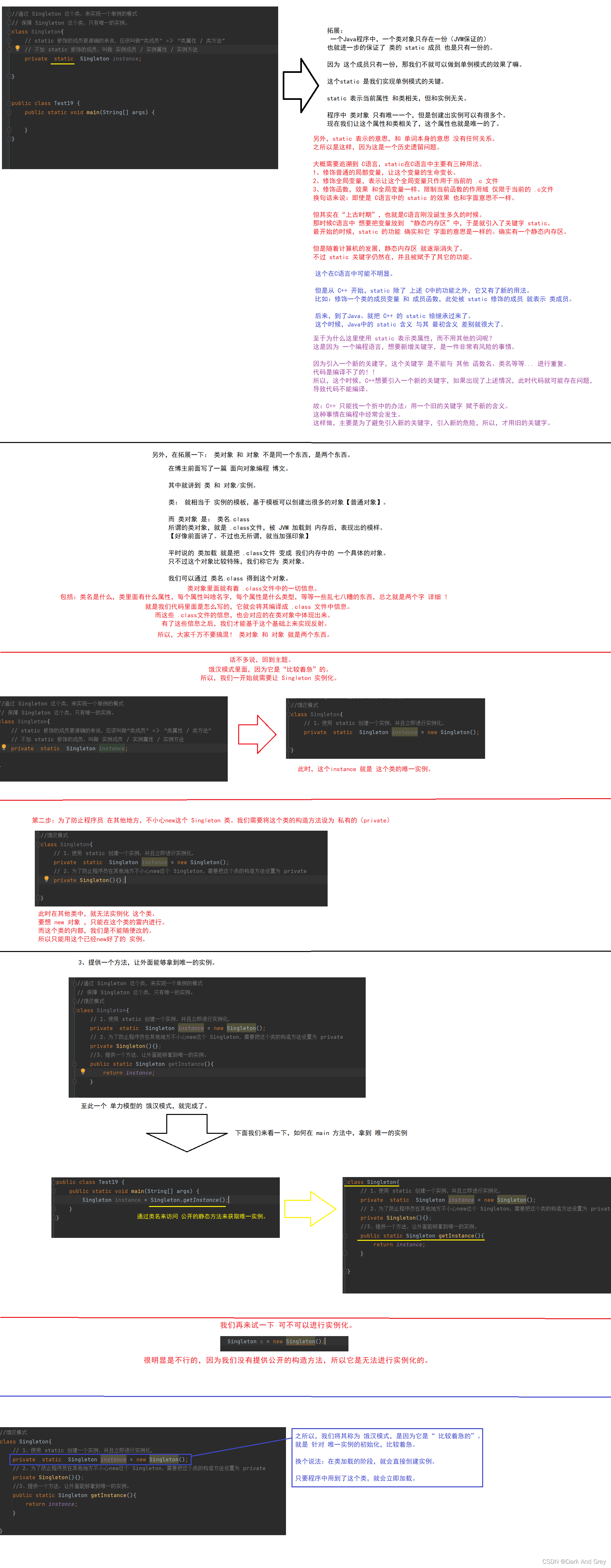
//饿汉模式
class Singleton{
// 1、使用 static 创建一个实例,并且立即进行实例化,
private static Singleton instance = new Singleton();
// 2、为了防止程序员在其他地方不小心new这个 Singleton,需要把这个类的构造方法设置为 private
private Singleton(){};
//3、提供一个方法,让外面能够拿到唯一的实例。
public static Singleton getInstance(){
return instance;
}
}
2、懒汉模式
懒汉的单例模式,是不太着急的去进行创建实例的,只有在用的时候,才真正创建实例。
懒汉模式的代码 和 饿汉模式的代码非常相似。
//单例模式 - 懒汉模式
class Singleton2{
//1、现在就不是立即初始化实例
private static Singleton2 instance;// 默认值:Null
//2、把构造方法设为 private
private Singleton2(){};
//3、提供一个公开的方法,来获取这个 单例模式的唯一实例
public static Singleton2 getInstance(){
// 只有当我们真正用到这个实例的时候,才会真正去创建这个实例
if(instance == null){
instance = new Singleton2();
}
return instance;
}
}
public class Test20 {
public static void main(String[] args) {
Singleton2 instance = Singleton2.getInstance();
}
}
饿汉模式 和 懒汉模式 的唯一区别就在于 创建实例的时机不一样。
饿汉模式 是 类加载时,创建。
懒汉模式 是 首次使用时,创建。
所以懒汉模式就更懒一些,不用的时候,不创建;等到用用的时候,再去创建。
这样做的目的,就是节省资源。
如果像 饿汉模式一样,一开始就实例化对象。
此时这个对象就存储在堆上。【这是需要耗费资源】
我们也不确定 这个 对象 什么时候会被用到。
那么,我们一直不调用,这资源还是一直挂在那里。
这就不就是浪费嘛!
如果像 懒汉模式一样,到了真正用到的时候,才会去实例化唯一的对象。
拓展:进一步帮助你们理解 饿汉 和 懒汉模式
其实在计算机很多其它场景中,也会涉及这情况。
一个典型的案例:
notepad 这样的程序(记事本软件),在打开大文件的时候是很慢的。
假如,你要打开一个 1G 大小的文件,此时 notepad 就会尝试把这 1 G 的 所有内容都读到内存中。
将 1G 的数据量 存入 内存,显然是非常慢的。
不管你要不要,全部都给你。
这就是 饿汉模式。
问题也随之而来:这些数据,我们真的能全部用得到吗?显示是不太可能的。
因此就会浪费很多资源.
像一些其他的程序,在打开大文件的时候就有优化。
假设也是打开 1G的文件,但是只先加载这一个屏幕中能显示出来的部分。
看到哪,加载到哪里。这样不会用空间上的浪费。
这就是 懒汉模式。
回过头,以上这些只是作为铺垫,真正要解决的问题是 实现一个线程安全的单例模式
接下来,我们来观察一下,上面讲到的两种单例模式谁是线程安全的。
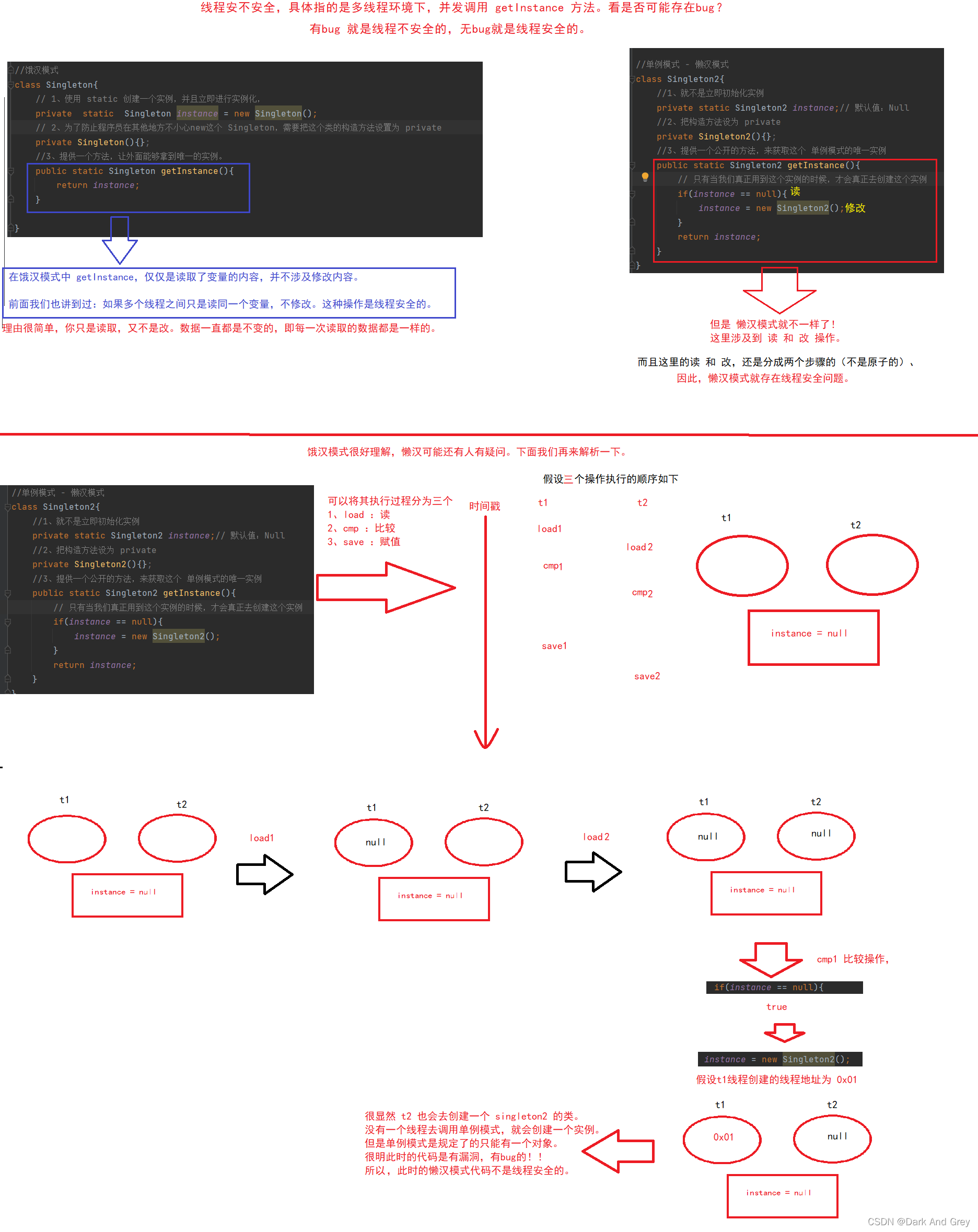
现在,我们再来针对这里的懒汉模式代码,使它线程安全,
说到让一个代码线程安全,我们自然而然的就想到加锁!
但是问题就在于:在哪个地方加锁合适呢?
其实也很好观察,将 if 语句的执行操作 给 加锁,使其两个操作为原子性。
直白来说: 就是 if 语句 打包成“一个整体”,就跟前面分析 count++ 一样。
一致性执行完。
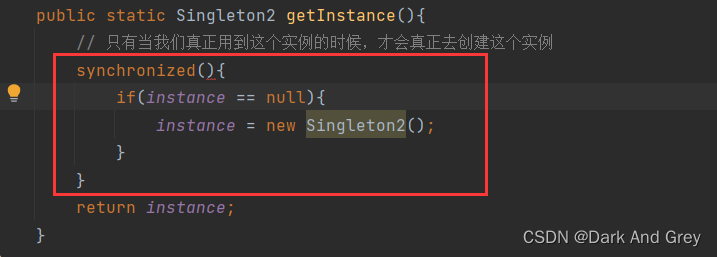
加锁范围 一定要包含 if 语句!!!
要不然没有效果,就像下面这样!
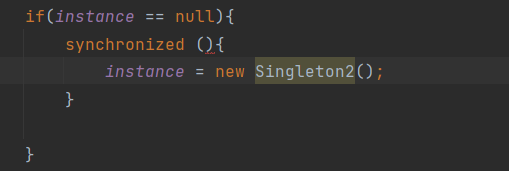
本来我们是想将 读 和 写 操作,打包成一个整体,
但是现在只是 针对写操作进行加锁,这时候就跟没加锁 一样,是没有区别的。
请大家注意!并不是代码中有 synchronized,一定就是线程安全的。
这需要看 synchronized 加的位置,也要正确。
所以 synchronized 写的位置。不能随便。
回过头来,我们再来看一下 synchronized 锁的对象写我们应该些什么。

虽然我们确实通过上述加锁操作,解决了 if 语句 的原子性问题。
但是!这样的程序,还存在这几个问题!
1、代码执行效率问题
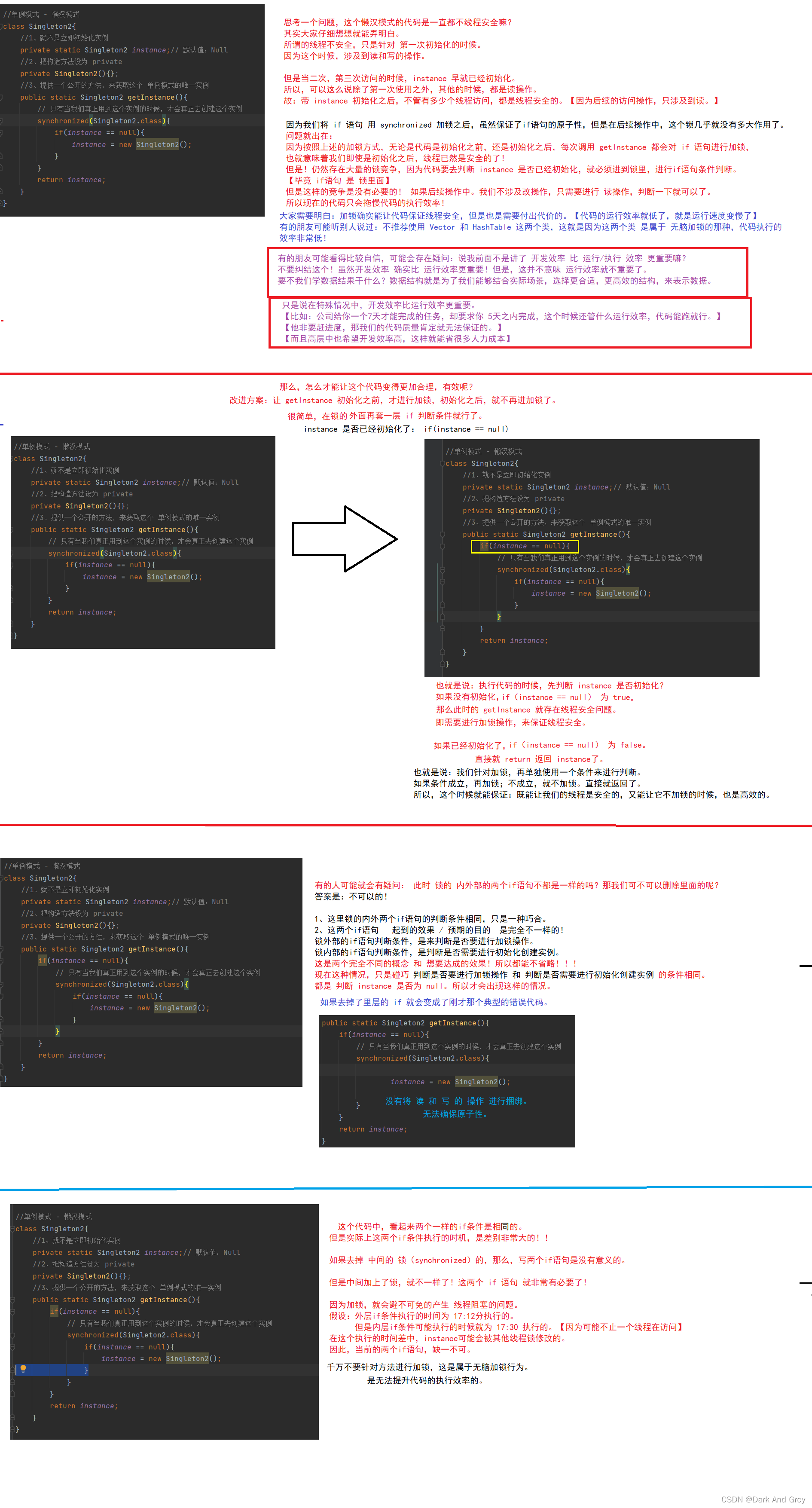
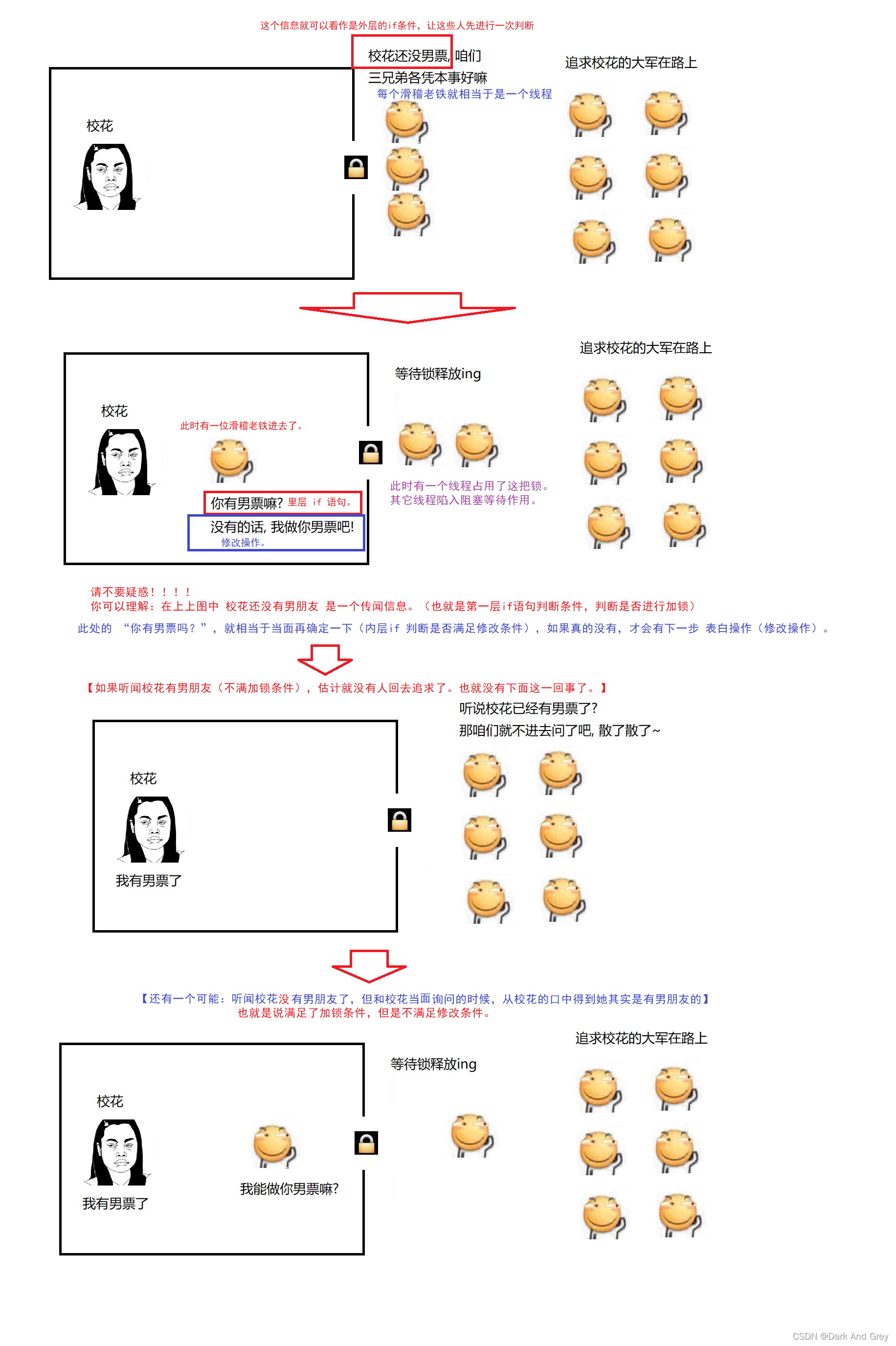
再举一个形象的例子
2、指令重排序
虽然其他线程再调用 单例线程的时候,也是加了 synchronized 的。
减缓了循环速度,从而保证了 内存可见性。
但是!还有一个问题,来看下面。

此时,我们才完成一个线程安全的单例模式 - 懒汉模式
1、正确的位置加锁
2、双重if判定
3、volatile关键字
//单例模式 - 懒汉模式
class Singleton2{
//1、就不是立即初始化实例
private static volatile Singleton2 instance;// 默认值:Null
//2、把构造方法设为 private
private Singleton2(){};
//3、提供一个公开的方法,来获取这个 单例模式的唯一实例
public static Singleton2 getInstance(){
if(instance == null){
// 只有当我们真正用到这个实例的时候,才会真正去创建这个实例
synchronized(Singleton2.class){
if(instance == null){
instance = new Singleton2();
}
}
}
return instance;
}
}
阻塞队列 与 普通队列 的特性一样的:先进先出。
但是呢,相比于普通队列,阻塞队列也有着一些其它方面的功能!!!
1、线程安全
2、产生阻塞效果
2.1 如果队列为空,尝试出队一个元素,就会触发阻塞,一直阻塞到队列不为空为止。
2.2 如果队列为满,尝试入队一个元素,就会触发阻塞,一直阻塞到队列不为满为止。
基于上述特性,就可以实现“生产者消费者模型”。
生产者消费者模型 是日常开发中,处理多线程问题的一个典型方式。
举个例子:过年,吃饺子
既然吃饺子,就需要包饺子这件事。
而包出一个完美的饺子这件事很麻烦。
【和面,擀饺子皮,包饺子,煮/蒸。大概是这么一个流程,其中细节是非常多的】
如果数量非常多,就需要多人分工进行协作。
其中 和面 和 煮饺子 不太好进行分工。【一般和面是一个人负责,煮饺子也是一个人】
毕竟和面这件事,一坨面一起和。没有说拆成两个部分来和面的。那样口感就不一样了。
煮饺子,那就更简单了,一个人拿着勺子不停的搅拌锅里的饺子,等到煮熟了,直接捞起来就行了。
擀饺子皮 和 包饺子 就比较好分工了。
毕竟面皮是一张一张擀出来了,饺子也是一个一个包的。
我们主要考虑擀面皮 和 包饺子的过程。
假设 现有 A、B、C 三个人一起来擀饺子皮 + 包饺子。
协作方式1:
A、B、C 分别每个人都是先擀一张皮,然后再包一个饺子。
这种方式肯定是有效率的,毕竟三个人一起擀面皮和包饺子。肯定是比一个人要快的。
但是这种方式存在一定的问题,锁冲突比较激烈.
注意!擀饺子皮,需要一个重要的道具 “擀面杖”

问题就出在这里!擀面杖这个东西,普通家庭一般只会买一个。
那么,如果此时A、B、C 三个都来擀面皮,故 三个人中,只能有一个人可以使用擀面杖,同时其他两个人,就需要等待,等待这个人使用完,让出来。然后,另外两个人就会出现竞争。
所以这个时候就会出现一系列的阻塞等待。擀起面皮就很难受了,要等。
协作方式2:
A专门负责擀饺子皮,B和C专门负责包饺子。
这是一个常见情况
因为 擀饺子皮的人,现在只有一个人。
所以没有人跟他抢擀面杖。(也就不会有锁的竞争了,同时也不会有阻塞等待的情况发生。
此时,A就是饺子皮的生产者,要不断的生成一个些饺子皮。
B和C就是饺子皮的消费者,他们需要不断的 使用/消耗 饺子皮。
这种就是生产者消费者模型。
在这个模型中,既有生产者负责生产数据,消费者负责使用数据。
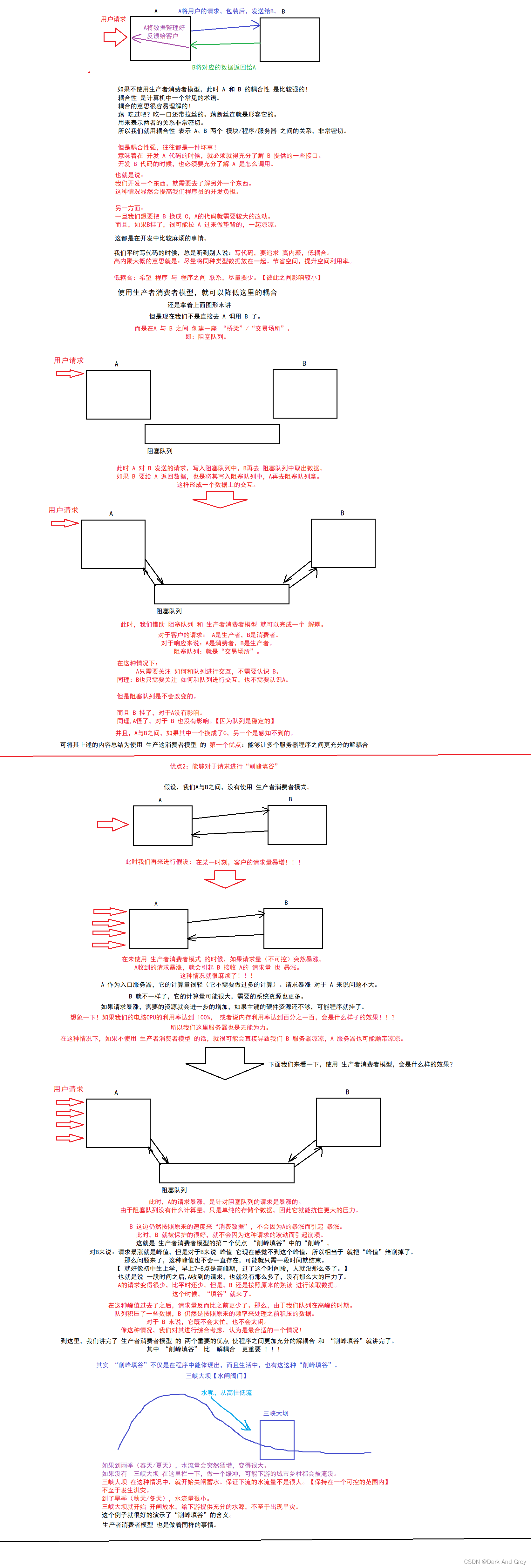
那么,生产者 和 消费者之间,需要有一个“桥梁” 来去进行沟通交互。
我们将 “桥梁” 称其为 “交易场所”。
放在 饺子 事件中,“交易场所” 就相当于 用来放饺子的那个“盖帘”。
A将生产出来的饺子皮放在盖帘上,B、C消耗的饺子皮,要从盖帘上面拿。
得有这样的一个空间来存放饺子皮,得有这样的一个空间来存储需要使用的数据。
这就是“交易场所”。
阻塞队列 就可以作为 生产者消费者模型 中的 “交易场所”。
生产者消费者模型,是实际开发中非常有用的一种多线程开发手段!!!
尤其是在服务器开发的场景中。
假设:
有两个服务器A、B。
A 作为入口服务器直接接收用户的网络请求。
B 作为应用服务器,来给A提供一些数据。
细节拓展:阻塞队列
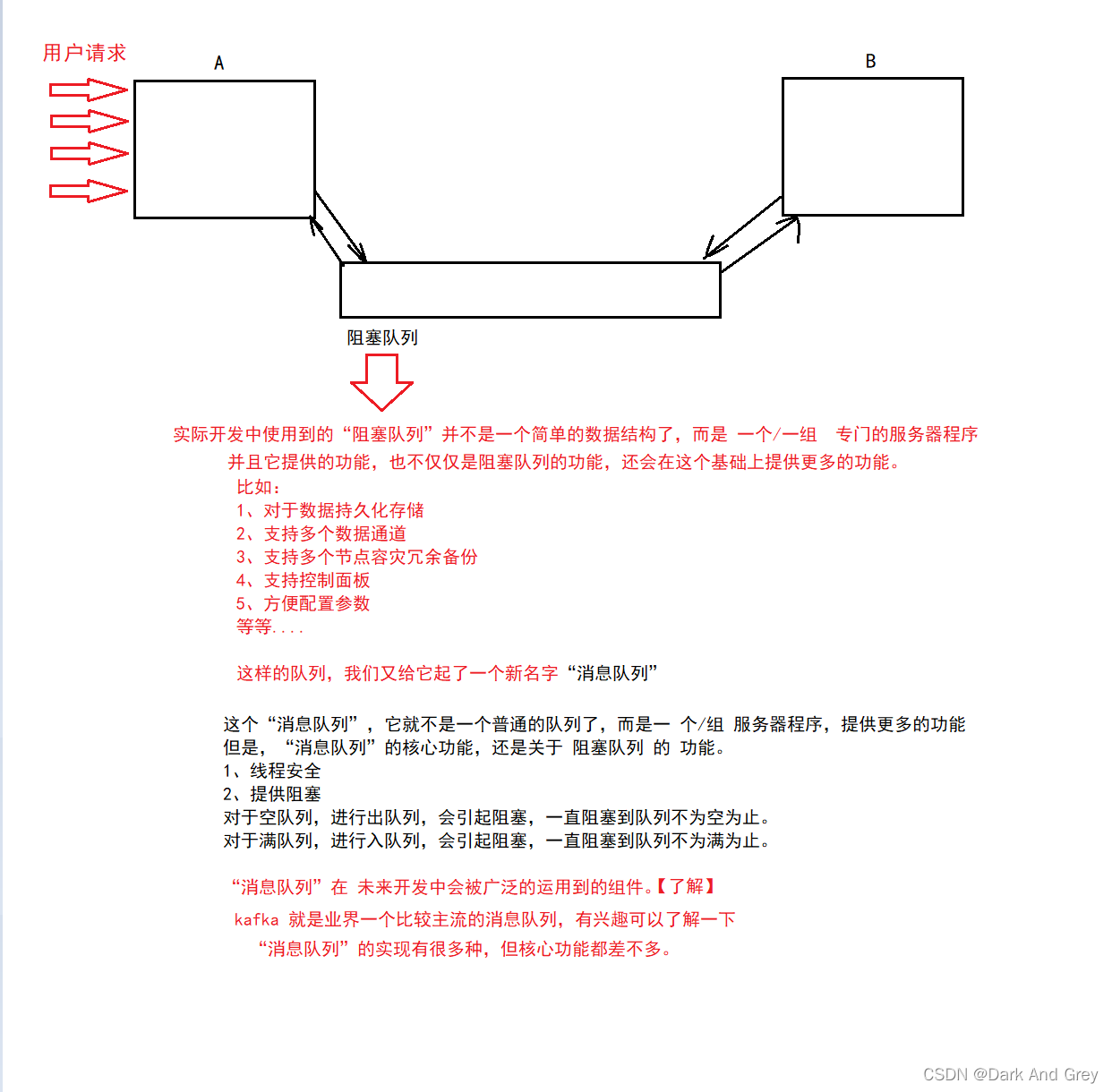
了解Java中 阻塞队列 的一些主要用法
这里我们只是说一个 Java中内置阻塞队列是哪一个,顺带将一个常用的入队和出队方法。
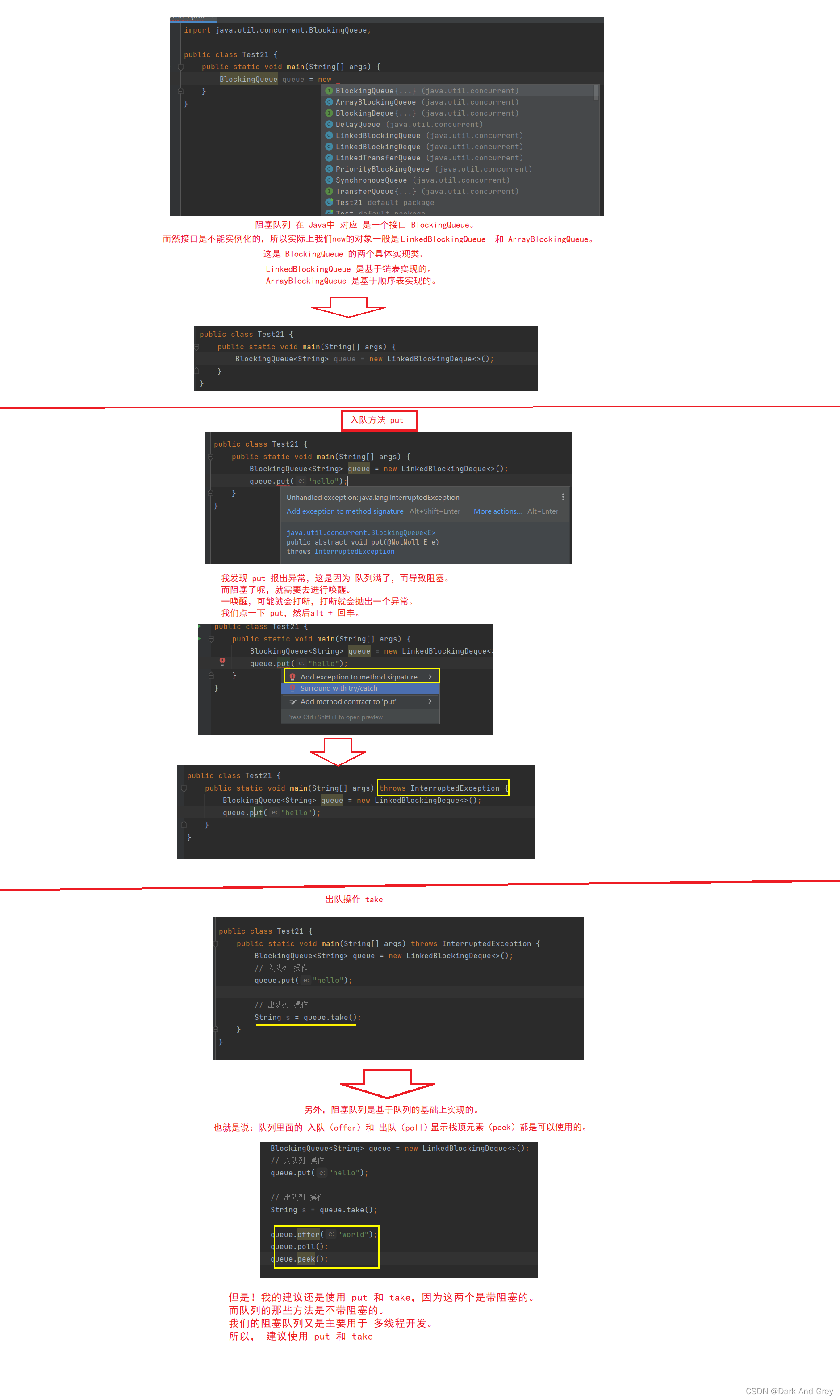
模拟实现阻塞队列
1、先实现一个普通队列
2、加上线程安全
3、加上阻塞功能
因此 阻塞队列 是可以基于链表,也可以基于数组来实现、
但是基于数组来实现阻塞队列更简单,所以我们就直接写一个数组版本的阻塞队列。
数组实现队列的重点就在于 循环队列。
可参考我的这篇文章栈 和 队列

下面我们正式开始
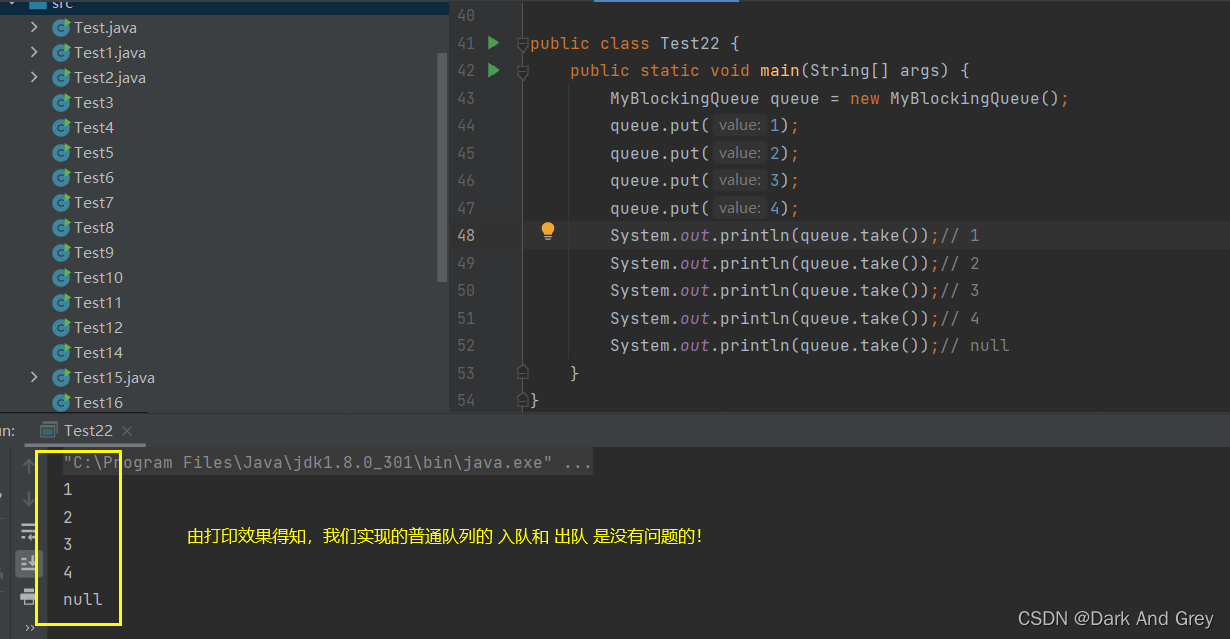
1、先实现一个队列
class MyBlockingQueue{
// 保存数据的本体
private int[] data = new int[1000];
// 有效元素个数
private int usedSize;
// 队头下标位置
private int head;
// 队尾下标位置
private int rear;
// 入队列
public void put(int value){
if(usedSize == this.data.length){
// 如果队列满了,暂时先返回。
return;
}
data[rear++] = value;
//处理 rear 到达数组末尾的情况。
if(rear >= data.length){
rear = 0;
}
usedSize++;// 入队成功,元素个数加一。
}
// 出队列
public Integer take(){
if(usedSize == 0){
// 如果队列为空,就返回一个 非法值
return null;
}
int tmp = data[head];
head++;
if(head == data.length){
head = 0;
}
usedSize--;
return tmp;
}
}
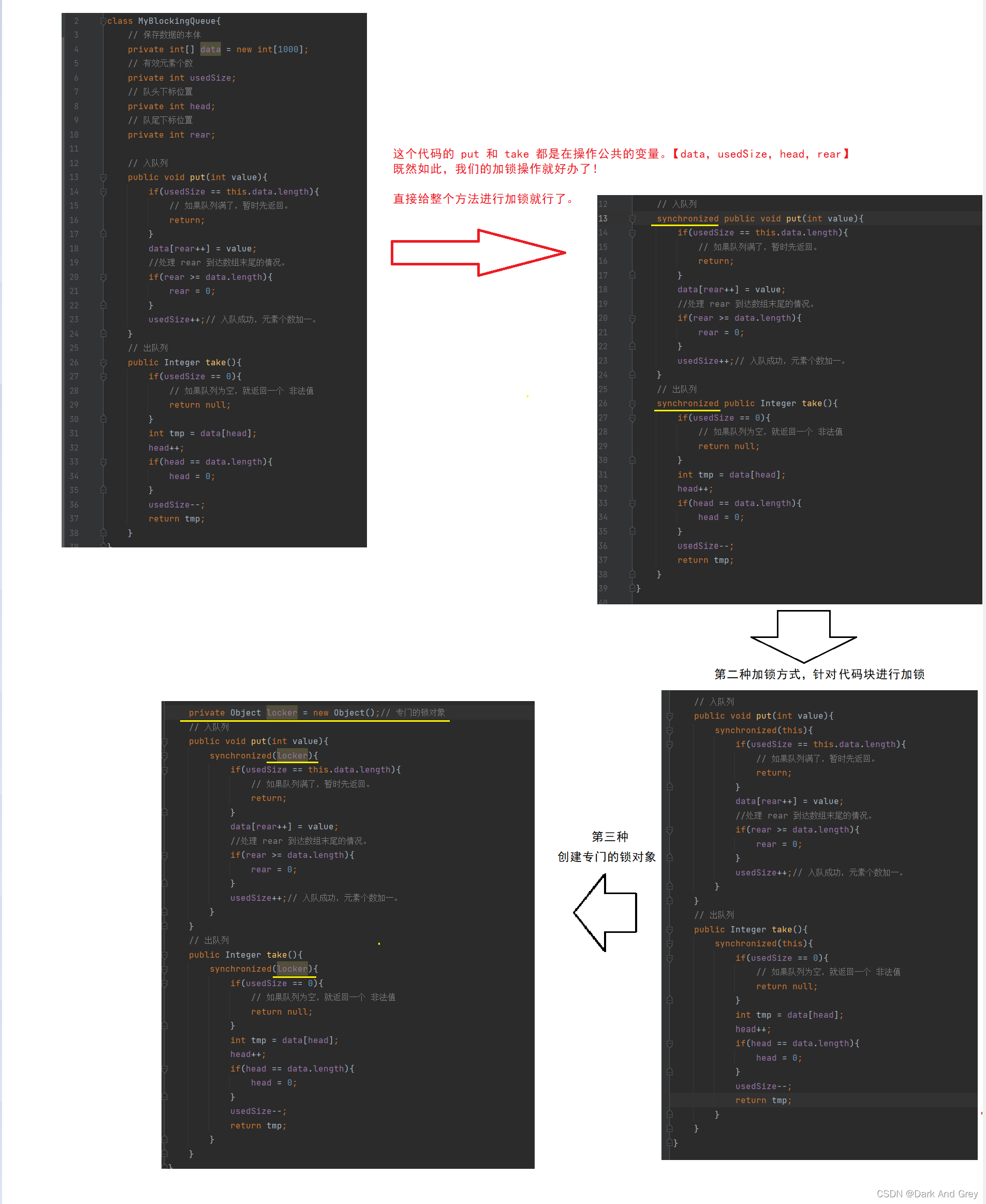
2、让队列在支持线程安全
保证多线程环境下,调用这里的put 和 take 是没有问题的。
使用加锁操作 synchronized
3、实现阻塞
关键要点:使用 wait 和 notify机制。
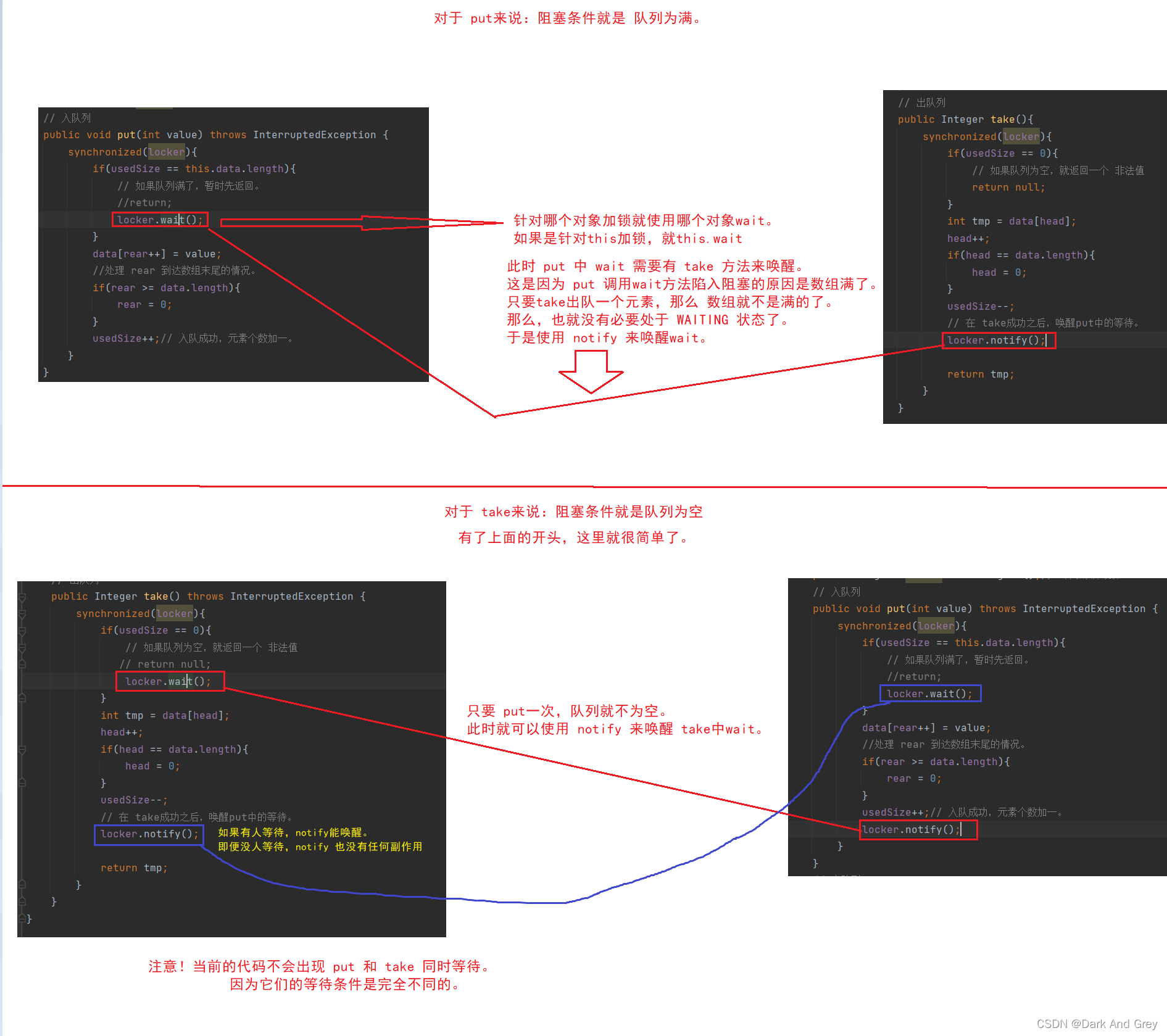
拓展:
如果这里有三个线程都是使用的同一个 锁对象, notify 是 不可能实现精准唤醒 指定 wait 的。
notify 只能唤醒随机的一个等待的线程,不能做到精准。
如果想要精准,就必须使用不同的 锁对象。
想精准唤醒 t1,就必须专门为它创建一个锁对象 locker1,让t1 调用 locker1.wait。再对其进行 locker1.notify 才能唤醒
想精准唤醒 t2,就必须专门为它创建一个锁对象 locker2,让t2 调用 locker2.wait。再对其进行 locker2.notify 才能唤醒.
这样才能达到精准唤醒的效果。
总程序
class MyBlockingQueue{
// 保存数据的本体
private int[] data = new int[1000];
// 有效元素个数
private int usedSize;
// 队头下标位置
private int head;
// 队尾下标位置
private int rear;
private Object locker = new Object();// 专门的锁对象
// 入队列
public void put(int value) throws InterruptedException {
synchronized(locker){
if(usedSize == this.data.length){
// 如果队列满了,暂时先返回。
//return;
locker.wait();
}
data[rear++] = value;
//处理 rear 到达数组末尾的情况。
if(rear >= data.length){
rear = 0;
}
usedSize++;// 入队成功,元素个数加一。
locker.notify();
}
}
// 出队列
public Integer take() throws InterruptedException {
synchronized(locker){
if(usedSize == 0){
// 如果队列为空,就返回一个 非法值
// return null;
locker.wait();
}
int tmp = data[head];
head++;
if(head == data.length){
head = 0;
}
usedSize--;
// 在 take成功之后,唤醒put中的等待。
locker.notify();
return tmp;
}
}
}
为了观察程序的效果,我们再利用 阻塞队列 来构造一个 生产者和消费者模型
我通过构造两个线程,来实现一个简易的消费者生产者模型。
public class Test22 {
private static MyBlockingQueue queue = new MyBlockingQueue();
public static void main(String[] args) {
// 实现一个 生产者消费者模型
Thread producer = new Thread(()->{
int num = 0;
while (true){
try {
System.out.println("生产了" + num);
queue.put(num);
num++;
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
producer.start();
Thread customer = new Thread(()->{
while (true){
try {
int num = queue.take();
System.out.println("消费了"+num);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
customer.start();
}
}
当前的场景中,只有一个消费者 和 一个 生产者。
如果多个生产者 和 消费者,那我们就多创建线程就行了。
为了更好看到效果,我们在给这这个程序中的“生产者”加上一个sleep。
让它生产的慢一些,此时消费者就只能跟生产的步伐走。
生产者生成一个,消费者就消费一个。
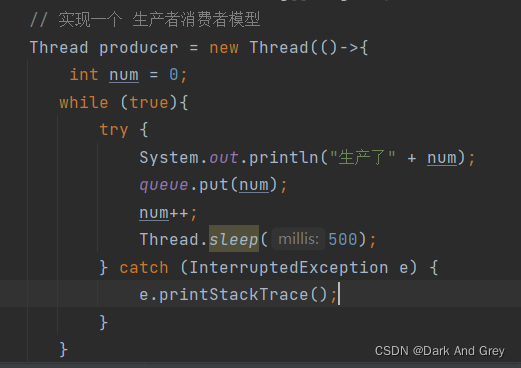
下面我们来看一下执行效果。【生产的速度 没有消费速度快】
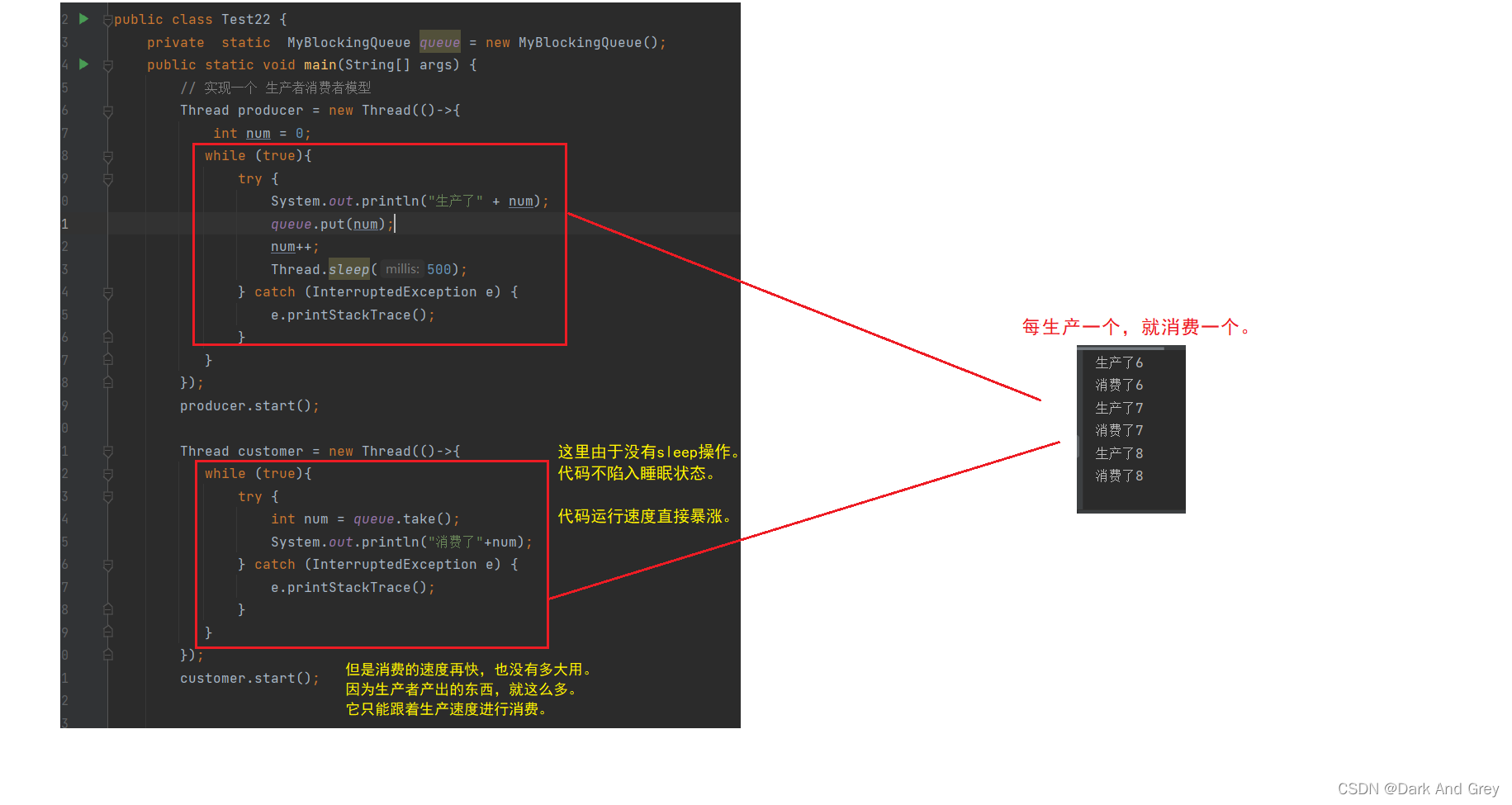
我们再来将sleep代码的位置换到 消费者 代码中。
此时就是消费速度 没有生产速度快。
来看下面的效果
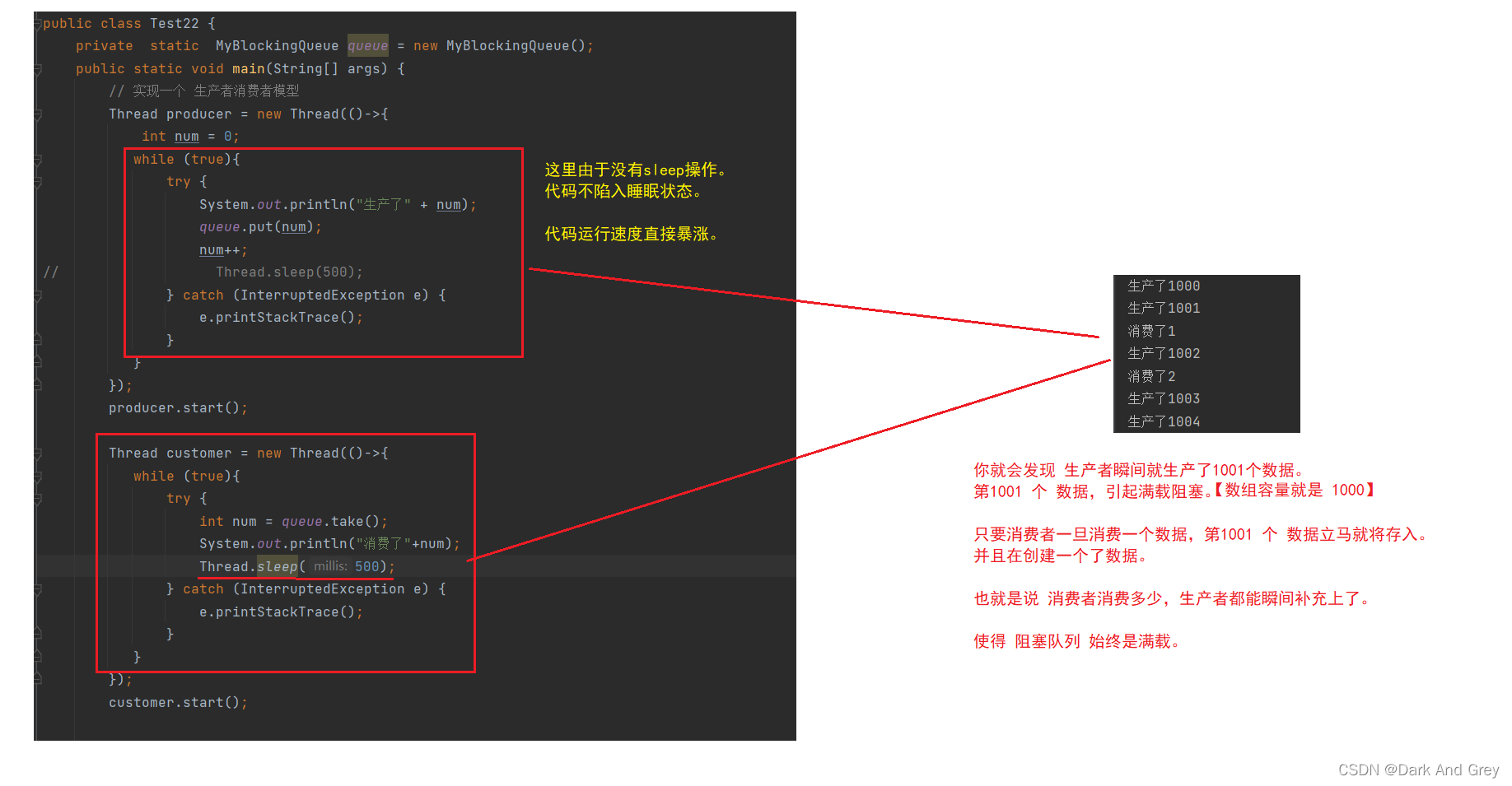
下面这个程序,是 生产速度非常,消费速度很慢。
取决于你给谁加上sleep
class MyBlockingQueue{
// 保存数据的本体
private int[] data = new int[1000];
// 有效元素个数
private int usedSize;
// 队头下标位置
private int head;
// 队尾下标位置
private int rear;
private Object locker = new Object();// 专门的锁对象
// 入队列
public void put(int value) throws InterruptedException {
synchronized(locker){
if(usedSize == this.data.length){
// 如果队列满了,暂时先返回。
//return;
locker.wait();
}
data[rear++] = value;
//处理 rear 到达数组末尾的情况。
if(rear >= data.length){
rear = 0;
}
usedSize++;// 入队成功,元素个数加一。
locker.notify();
}
}
// 出队列
public Integer take() throws InterruptedException {
synchronized(locker){
if(usedSize == 0){
// 如果队列为空,就返回一个 非法值
// return null;
locker.wait();
}
int tmp = data[head];
head++;
if(head == data.length){
head = 0;
}
usedSize--;
// 在 take成功之后,唤醒put中的等待。
locker.notify();
return tmp;
}
}
}
public class Test22 {
private static MyBlockingQueue queue = new MyBlockingQueue();
public static void main(String[] args) {
// 实现一个 生产者消费者模型
Thread producer = new Thread(()->{
int num = 0;
while (true){
try {
System.out.println("生产了" + num);
queue.put(num);
num++;
// Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
producer.start();
Thread customer = new Thread(()->{
while (true){
try {
int num = queue.take();
System.out.println("消费了"+num);
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
customer.start();
}
}
类似于一个闹钟,可以进行定时,在一定时间之后,被唤醒并执行某个之间设定好的任务。
举个例子
在我们打开浏览器,随便打开一个网页
如果顺利,马上就能进入网站

但是!有时候由于网络不稳定,或者网站的服务器崩了。
那么,此时这里就会一直转圈圈加载。
但是浏览器不会一直都在这里等待访问的网站反馈信息。
它里面其实有一个等待 的“超时时间”,过了这个时间,它就不会再等待,直接跟你说“访问失败 / 网站不见了”
此时我们很快就能想到 join,有一个用法,在括号里添加指定的 “超时时间”。
sleep也可以达到这个效果,sleep(指定休眠时间) 。
join 和 sleep 都是基于系统内部的定时器,来实现的。
那么,我们就可以使用 代码中的定时器,来实现类似的功能。
下面先介绍标准库的定时器用法,然后再看看如何自己实现一个定时器
标准库的定时器用法,
这里就需要提到 java.util 这个包。
这个包里的类,都是一些非常实用的类。
几乎我们平常用到的类,都在这个包里。
切入主题,我想介绍的是这个包里面的 Timer【java.util.Timer】
它的核心方法就一个 :schedule‘(中文意思:安排)
schedule,它的功能就跟 它 中文意思一样。
每调用一次 schedule‘,就会’给定时器 安排一个任务。
通过这个方法,就可以把 任务 注册到 定时器内部。
而计数器内部是支持 注册 多个任务的。
schedule方法,有两个参数:
1、任务是什么
2、多长时间之后执行

如何自己实现一个定时器
首先,思考一个问题:Timer 类 的内部需要什么东西?
从Timer 的 工作内容入手
1、管理很多的任务
2、执行时间到了的任务
管理任务又可以细分为 2个:
1、描述任务(创建一个专门的类来表示一个定时器中的任务【Timer Task】)
2、组织任务(使用一定的数据及结构进行组织数据,把一些任务放到一起。)
具体任务顺序为
1、描述任务(创建一个专门的类来表示一个定时器中的任务【Timer Task】)
2、组织任务(使用一定的数据及结构进行组织数据,把一些任务放到一起。)
3、执行时间到了的任务
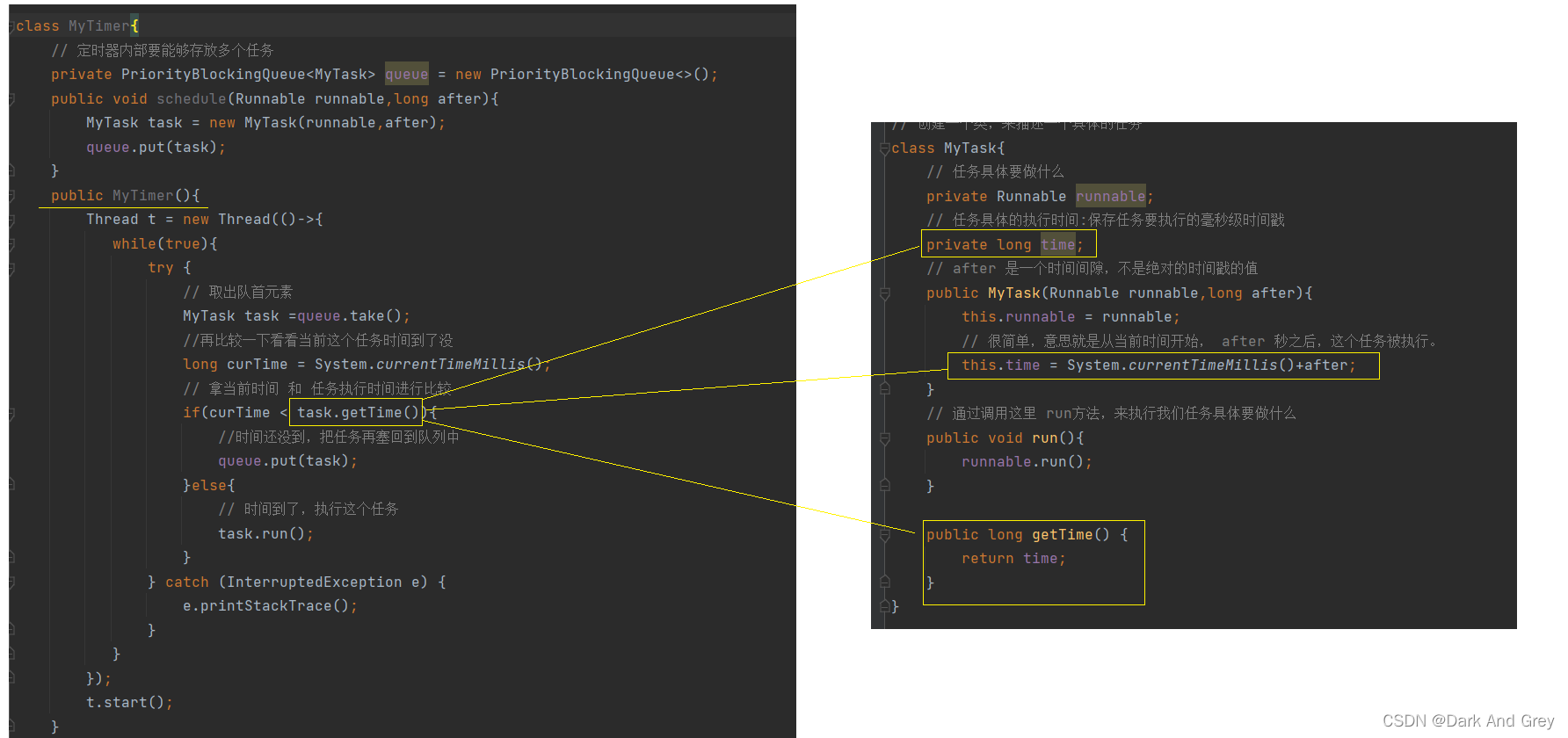
1、描述任务
// 创建一个类,来描述一个具体的任务
class MyTask{
// 任务具体要做什么
private Runnable runnable;
// 任务具体的执行时间:保存任务要执行的毫秒级时间戳
private long time;
// after 是一个时间间隙,不是绝对的时间戳的值
public MyTask(Runnable runnable,long after){
this.runnable = runnable;
// 很简单,意思就是从当前时间开始, after 秒之后,这个任务被执行。
this.time = System.currentTimeMillis()+after;
}
// 通过调用这里 run方法,来执行我们任务具体要做什么
public void run(){
runnable.run();
}
}
组织任务
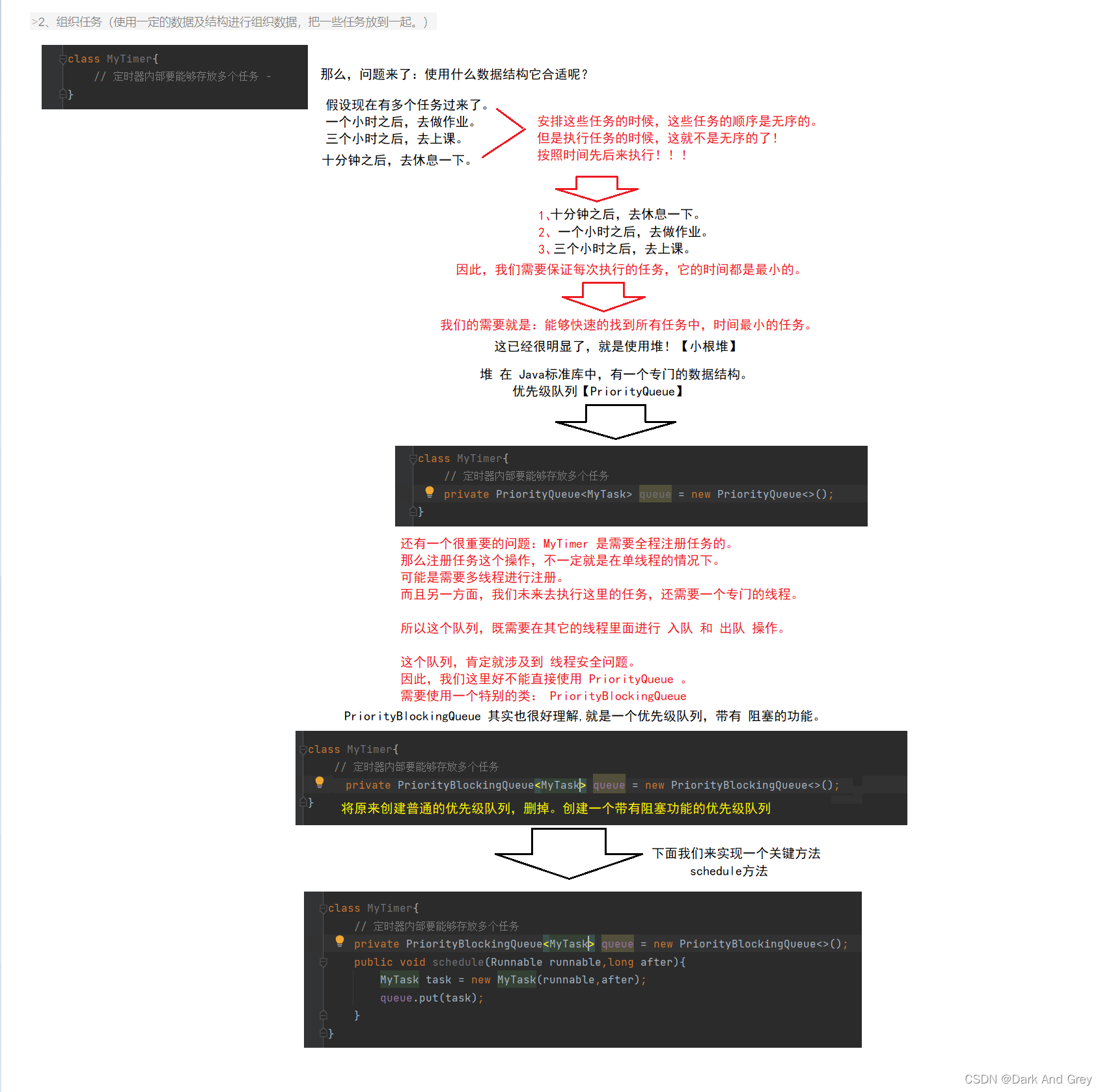
3、执行时间到了的任务
需要先执行时间最靠前的任务
比如:十分钟后,大家去休息一下。
但是,当前的我们无法判断这个时间,所以我们需要用一个线程去不断的去检查当前优先队列的首元素,看看当前最靠前的这个任务是不是时间到了。
通过 自己构造的 Mytimer 计时器类 的 构造方法。
创建一个线程,帮助我们来进行一个检查
有的人可能会说,为什么不用peek?
拿出来,有放进去,多麻烦,还会有多余的开销。
确实,peek 更好一些,但是这里的 take 也没有什么开销。
所以,这个点不重要。
堆里面的调整时间复杂度是 log2 N,近似视为 O(1).
N = 10w 和 N = 100w,log2 N 的结果差不了多少。【大概十几】
再来想一下:一个定时器里面能有10w个任务吗?
猛虎王表示:你放屁!
这显然是不科学的。
如果只是 千八百个,那也就是大概d调整个 5次左右,和 O(1) 没什么区别。
我们通常认为 O(log2 N) 和 O(1) 级别的,都是非常高效的。
然后 N 级别的,效率一般般。
最后 像N^2、以N作为指数的方式,这种都是非常低效的。
写到这里,上述代码中存在两个非常严重的问题!!!
我们直接给它安排一个任务,来看看效果
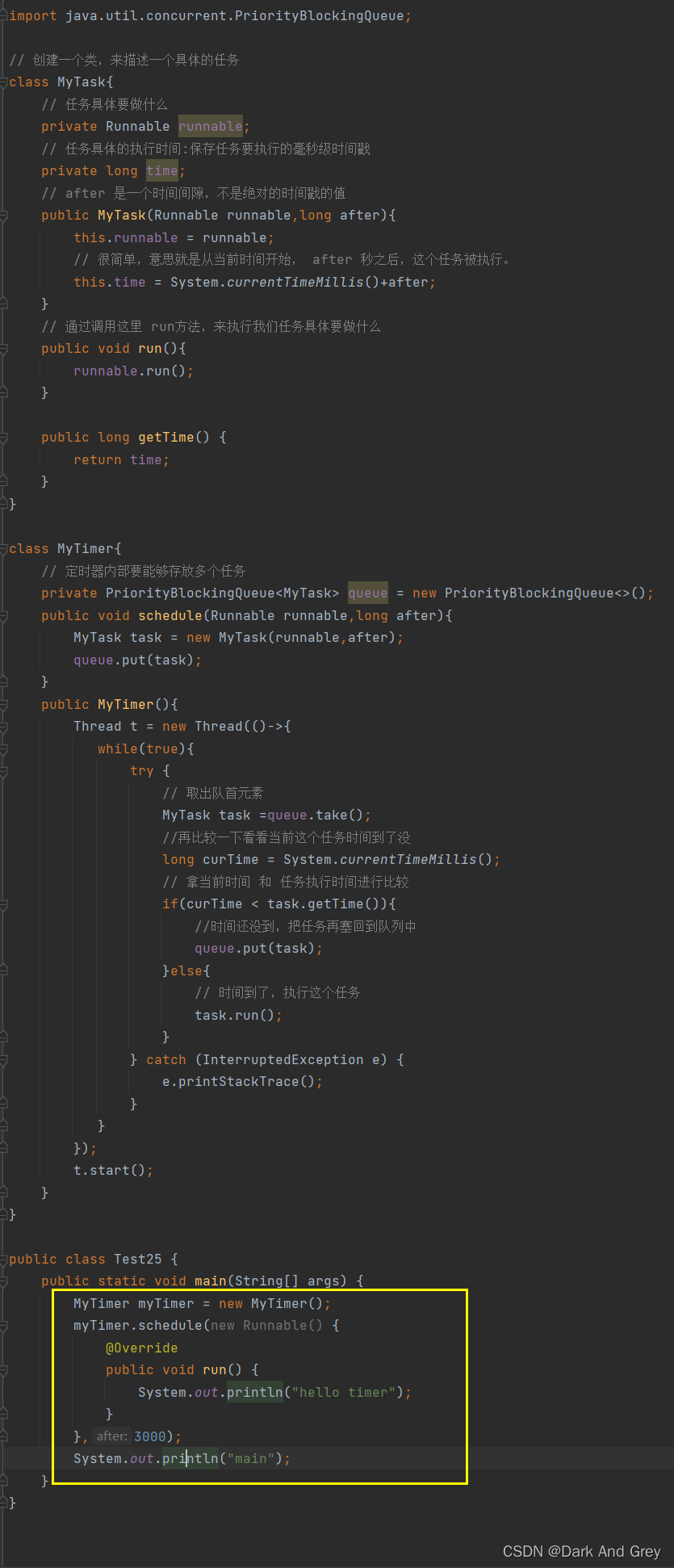
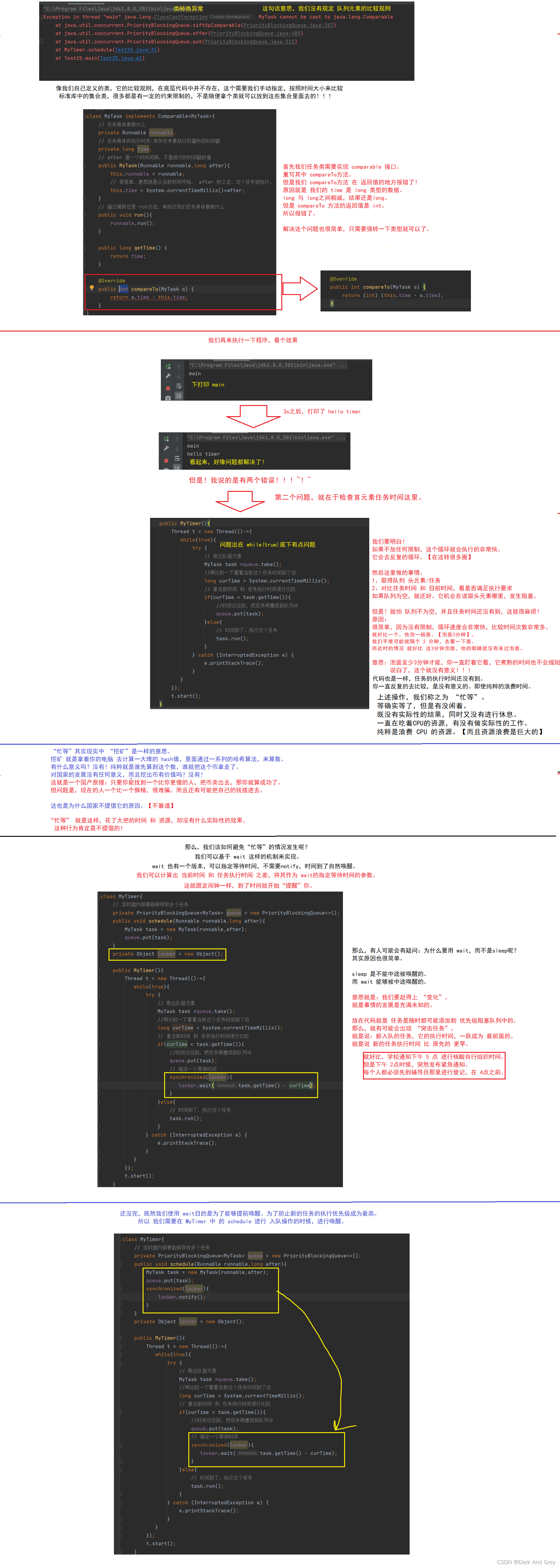
总程序
import java.util.concurrent.PriorityBlockingQueue;
// 创建一个类,来描述一个具体的任务
class MyTask implements Comparable<MyTask>{
// 任务具体要做什么
private Runnable runnable;
// 任务具体的执行时间:保存任务要执行的毫秒级时间戳
private long time;
// after 是一个时间间隙,不是绝对的时间戳的值
public MyTask(Runnable runnable,long after){
this.runnable = runnable;
// 很简单,意思就是从当前时间开始, after 秒之后,这个任务被执行。
this.time = System.currentTimeMillis()+after;
}
// 通过调用这里 run方法,来执行我们任务具体要做什么
public void run(){
runnable.run();
}
public long getTime() {
return time;
}
@Override
public int compareTo(MyTask o) {
return (int) (this.time - o.time);
}
}
class MyTimer{
// 定时器内部要能够存放多个任务
private PriorityBlockingQueue<MyTask> queue = new PriorityBlockingQueue<>();
public void schedule(Runnable runnable,long after){
MyTask task = new MyTask(runnable,after);
queue.put(task);
synchronized(locker){
locker.notify();
}
}
private Object locker = new Object();
public MyTimer(){
Thread t = new Thread(()->{
while(true){
try {
// 取出队首元素
MyTask task =queue.take();
//再比较一下看看当前这个任务时间到了没
long curTime = System.currentTimeMillis();
// 拿当前时间 和 任务执行时间进行比较
if(curTime < task.getTime()){
//时间还没到,把任务再塞回到队列中
queue.put(task);
// 指定一个等待时间
synchronized(locker){
locker.wait(task.getTime() - curTime);
}
}else{
// 时间到了,执行这个任务
task.run();
}
} catch (InterruptedException e) {
e.printStackTrace();
# 最后
学习视频:

大厂面试真题:

0w个任务吗?
> > 猛虎王表示:你放屁!
> > 这显然是不科学的。
> > 如果只是 千八百个,那也就是大概d调整个 5次左右,和 O(1) 没什么区别。
> >
> > 我们通常认为 O(log2 N) 和 O(1) 级别的,都是非常高效的。
> > 然后 N 级别的,效率一般般。
> > 最后 像N^2、以N作为指数的方式,这种都是非常低效的。
* * *
#### []( )写到这里,上述代码中存在两个非常严重的问题!!!
> 我们直接给它安排一个任务,来看看效果
> [知识点:Java 对象 的 比较]( )
> 
> 
* * *
### []( )总程序
import java.util.concurrent.PriorityBlockingQueue;
// 创建一个类,来描述一个具体的任务
class MyTask implements Comparable{
// 任务具体要做什么
private Runnable runnable;
// 任务具体的执行时间:保存任务要执行的毫秒级时间戳
private long time;
// after 是一个时间间隙,不是绝对的时间戳的值
public MyTask(Runnable runnable,long after){
this.runnable = runnable;
// 很简单,意思就是从当前时间开始, after 秒之后,这个任务被执行。
this.time = System.currentTimeMillis()+after;
}
// 通过调用这里 run方法,来执行我们任务具体要做什么
public void run(){
runnable.run();
}
public long getTime() {
return time;
}
@Override
public int compareTo(MyTask o) {
return (int) (this.time - o.time);
}
}
class MyTimer{
// 定时器内部要能够存放多个任务
private PriorityBlockingQueue<MyTask> queue = new PriorityBlockingQueue<>();
public void schedule(Runnable runnable,long after){
MyTask task = new MyTask(runnable,after);
queue.put(task);
synchronized(locker){
locker.notify();
}
}
private Object locker = new Object();
public MyTimer(){
Thread t = new Thread(()->{
while(true){
try {
// 取出队首元素
MyTask task =queue.take();
//再比较一下看看当前这个任务时间到了没
long curTime = System.currentTimeMillis();
// 拿当前时间 和 任务执行时间进行比较
if(curTime < task.getTime()){
//时间还没到,把任务再塞回到队列中
queue.put(task);
// 指定一个等待时间
synchronized(locker){
locker.wait(task.getTime() - curTime);
}
}else{
// 时间到了,执行这个任务
task.run();
}
} catch (InterruptedException e) {
e.printStackTrace();
最后
学习视频:
[外链图片转存中…(img-73MACdn0-1714194015035)]
大厂面试真题:
[外链图片转存中…(img-MvTKcJ7n-1714194015035)]














 786
786











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









