







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Java开发全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Java开发知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024b (备注Java)

正文
防止重复
我们推送给第三方的数据肯定是不能重复推送的,必须要有一个机制保证各个线程推送数据的隔离。
这里有两个思路:
-
- 将所有数据取到集合(内存)中,然后进行切割,每个线程推送不同段的数据
-
- 利用 数据库分页的方式,每个线程取 [start,limit] 区间的数据推送,我们需要保证start的一致性
这里采用了第二种方式,因为考虑到可能数据量后续会继续增加,把所有数据都加载到内存中,可能会有比较大的内存占用。
失败机制
我们还得考虑到线程推送数据失败的情况。
如果是自己的系统,我们可以把多线程调用的方法抽出来加一个事务,一个线程异常,整体回滚。
但是是和第三方的对接,我们都没法做事务的,所以,我们采用了直接在数据库记录失败状态的方法,可以在后面用其它方式处理失败的数据。
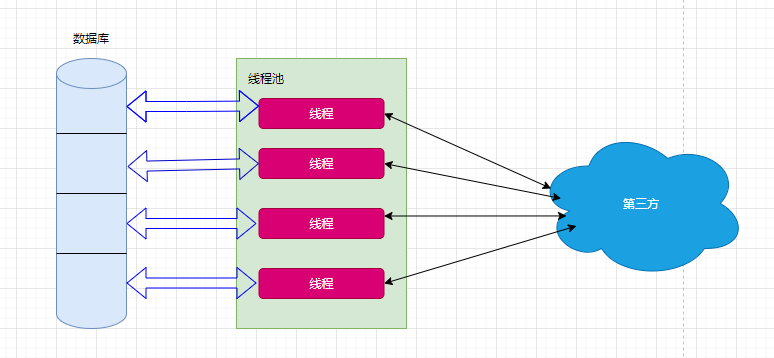
线程池选择
在实际使用中,我们肯定是要用到线程池来管理线程,关于线程池,我们常用 ThreadPoolExecutor提供的线程池服务,SpringBoot中同样也提供了线程池异步的方式,虽然SprignBoot异步可能更方便一点,但是使用ThreadPoolExecutor更加直观地控制线程池,所以我们直接使用ThreadPoolExecutor构造方法创建线程池。
大概的技术设计示意图:
上面叭叭了一堆,到了show you code的环节了。我将项目里的代码抽取出来,简化出了一个示例。
核心代码如下:
/**
-
@Author 三分恶
-
@Date 2021/3/5
-
@Description
*/
@Service
public class PushProcessServiceImpl implements PushProcessService {
@Autowired
private PushUtil pushUtil;
@Autowired
private PushProcessMapper pushProcessMapper;
private final static Logger logger = LoggerFactory.getLogger(PushProcessServiceImpl.class);
//每个线程每次查询的条数
private static final Integer LIMIT = 5000;
//起的线程数
private static final Integer THREAD_NUM = 5;
//创建线程池
ThreadPoolExecutor pool = new ThreadPoolExecutor(THREAD_NUM, THREAD_NUM * 2, 0, TimeUnit.SECONDS, new LinkedBlockingQueue<>(100));
@Override
public void pushData() throws ExecutionException, InterruptedException {
//计数器,需要保证线程安全
int count = 0;
//未推送数据总数
Integer total = pushProcessMapper.countPushRecordsByState(0);
logger.info(“未推送数据条数:{}”, total);
//计算需要多少轮
int num = total / (LIMIT * THREAD_NUM) + 1;
logger.info(“要经过的轮数:{}”, num);
//统计总共推送成功的数据条数
int totalSuccessCount = 0;
for (int i = 0; i < num; i++) {
//接收线程返回结果
List<Future> futureList = new ArrayList<>(32);
//起THREAD_NUM个线程并行查询更新库,加锁
for (int j = 0; j < THREAD_NUM; j++) {
synchronized (PushProcessServiceImpl.class) {
int start = count * LIMIT;
count++;
//提交线程,用数据起始位置标识线程
Future future = pool.submit(new PushDataTask(start, LIMIT, start));
//先不取值,防止阻塞,放进集合
futureList.add(future);
}
}
//统计本轮推送成功数据
for (Future f : futureList) {
totalSuccessCount = totalSuccessCount + (int) f.get();
}
}
//更新推送标志
pushProcessMapper.updateAllState(1);
logger.info(“推送数据完成,需推送数据:{},推送成功:{}”, total, totalSuccessCount);
}
/**
- 推送数据线程类
*/
class PushDataTask implements Callable {
int start;
int limit;
int threadNo; //线程编号
PushDataTask(int start, int limit, int threadNo) {
this.start = start;
this.limit = limit;
this.threadNo = threadNo;
}
@Override
public Integer call() throws Exception {
int count = 0;
//推送的数据
List pushProcessList = pushProcessMapper.findPushRecordsByStateLimit(0, start, limit);
if (CollectionUtils.isEmpty(pushProcessList)) {
return count;
}
logger.info(“线程{}开始推送数据”, threadNo);
for (PushProcess process : pushProcessList) {
boolean isSuccess = pushUtil.sendRecord(process);
if (isSuccess) { //推送成功
//更新推送标识
pushProcessMapper.updateFlagById(process.getId(), 1);
count++;
} else { //推送失败
pushProcessMapper.updateFlagById(process.getId(), 2);
}
}
logger.info(“线程{}推送成功{}条”, threadNo, count);
return count;
}
}
}
代码很长,我们简单说一下关键的地方:
- 线程创建:线程内部类选择了实现Callable接口,这样方便获取线程任务执行的结果,在示例里用于统计线程推送成功的数量
class PushDataTask implements Callable {
- 使用 ThreadPoolExecutor 创建线程池,
//创建线程池
ThreadPoolExecutor pool = new ThreadPoolExecutor(THREAD_NUM, THREAD_NUM * 2, 0, TimeUnit.SECONDS, new LinkedBlockingQueue<>(100));
主要构造参数如下:
- corePoolSize:线程核心参数选择了5
- maximumPoolSize:最大线程数选择了核心线程数2倍数
- keepAliveTime:非核心闲置线程存活时间直接置为0
- unit:非核心线程保持存活的时间选择了 TimeUnit.SECONDS 秒
- workQueue:线程池等待队列,使用 容量初始为100的 LinkedBlockingQueue阻塞队列
这里还有没写出来的线程池拒绝策略,采用了默认AbortPolicy:直接丢弃任务,抛出异常。
- 使用 synchronized 来保证线程安全,保证计数器的增加是有序的
synchronized (PushProcessServiceImpl.class) {
- 使用集合来接收线程的运行结果,防止阻塞
List<Future> futureList = new ArrayList<>(32);
好了,主要的代码和简单的解析就到这里了。
关于这个简单的demo,这里只是简单地做推送数据处理。考虑一下,这个实例是不是可以用在你项目的某些地方。例如监管系统的数据校验、审计系统的数据统计、电商系统的数据分析等等,只要是有大量数据处理的地方,都可以把这个例子结合到你的项目里,这样你就有了多线程开发的经验。
完整代码仓库地址在文章底部👇👇
=======================================================================
-
面试官:小伙子,不错,你这个整挺好。
-
老三:那是自然。
-
面试官:呦,小伙子,挺自信,那我得好好考考你。
-
老三:放马过来,但考无妨。

要说线程,必先说进程。
进程是程序的⼀次执⾏过程,是系统运⾏程序的基本单位,因此进程是动态的。系统运⾏⼀个程序即是⼀个进程从创建,运⾏到消亡的过程。
线程与进程相似,但线程是⼀个⽐进程更⼩的执⾏单位。⼀个进程在其执⾏的过程中可以产⽣多个线程。与进程不同的是同类的多个线程共享进程的堆和⽅法区资源,但每个线程有⾃⼰的程序计数器、虚拟机栈和本地⽅法栈,所以系统在产⽣⼀个线程,或是在各个线程之间作切换⼯作时,负担要⽐进程⼩得多,也正因为如此,线程也被称为轻量级进程。
Java里创建线程主要有三种方式:
-
继承 Thread类:Thread 类本质上是实现了 Runnable 接口的一个实例,代表一个线程的实例。启动线程的唯一方法就是通过 Thread 类的 start()实例方法。start()方法是一个 native 方法,它将启动一个新线程,并执行 run()方法。
-
实现 Runnable接口:如果自己的类已经 extends 另一个类,就无法直接 extends Thread,此时,可以实现一个Runnable 接口。
-
实现 Callable接口:实现Callable接口,重写call()方法,可以返回一个 Future类型的返回值。我在上面的例子里就是用到了这种方式。
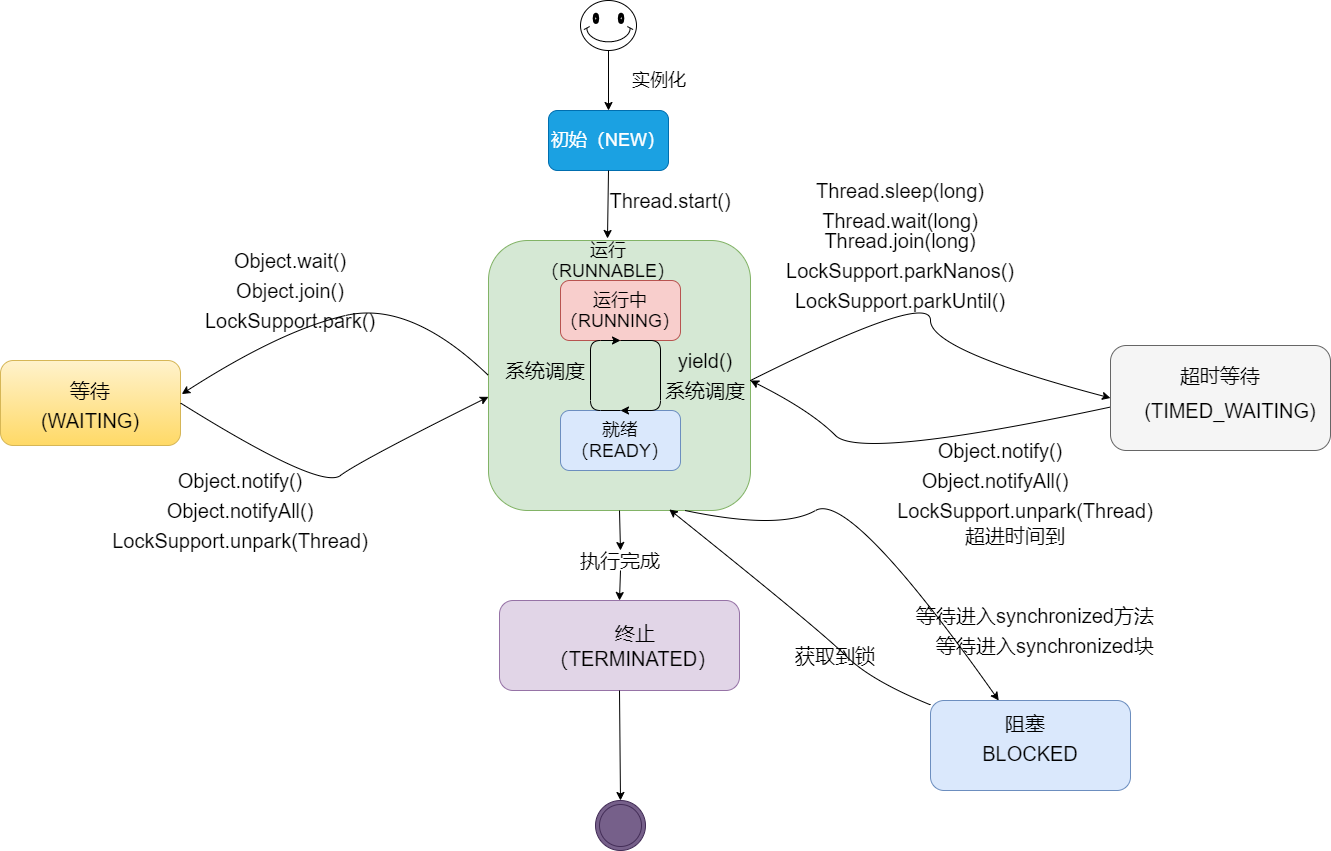
在Java中,线程共有六种状态:
| 状态 | 说明 |
| — | — |
| NEW | 初始状态:线程被创建,但还没有调用start()方法 |
| RUNNABLE | 运行状态:Java线程将操作系统中的就绪和运行两种状态笼统的称作“运行” |
| BLOCKED | 阻塞状态:表示线程阻塞于锁 |
| WAITING | 等待状态:表示线程进入等待状态,进入该状态表示当前线程需要等待其他线程做出一些特定动作(通知或中断) |
| TIME_WAITING | 超时等待状态:该状态不同于 WAITIND,它是可以在指定的时间自行返回的 |
| TERMINATED | 终止状态:表示当前线程已经执行完毕 |
线程在自身的生命周期中, 并不是固定地处于某个状态,而是随着代码的执行在不同的状态之间进行切换,Java线程状态变化如图示:
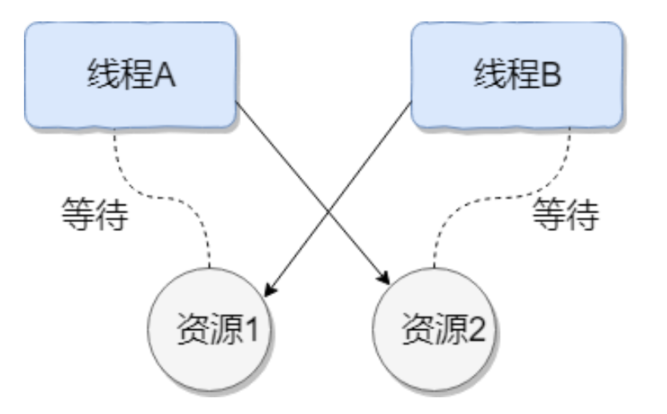
线程死锁描述的是这样⼀种情况:多个线程同时被阻塞,它们中的⼀个或者全部都在等待某个资源被释放。由于线程被⽆限期地阻塞,因此程序不可能正常终⽌。
如下图所示,线程 A 持有资源 2,线程 B 持有资源 1,他们同时都想申请对⽅的资源,所以这两个线程就会互相等待⽽进⼊死锁状态。
产生死锁必须满足四个条件:
-
互斥条件:该资源任意⼀个时刻只由⼀个线程占⽤。
-
请求与保持条件:⼀个进程因请求资源⽽阻塞时,对已获得的资源保持不放。
-
不剥夺条件:线程已获得的资源在末使⽤完之前不能被其他线程强⾏剥夺,只有⾃⼰使⽤完毕后才释放资源。
-
循环等待条件:若⼲进程之间形成⼀种头尾相接的循环等待资源关系。
我上⾯说了产⽣死锁的四个必要条件,为了避免死锁,我们只要破坏产⽣死锁的四个条件中的其中⼀个就可以了。
-
破坏互斥条件 :这个条件我们没有办法破坏,因为我们⽤锁本来就是想让他们互斥的(临界资源需要互斥访问)。
-
破坏请求与保持条件 :⼀次性申请所有的资源。
-
破坏不剥夺条件 :占⽤部分资源的线程进⼀步申请其他资源时,如果申请不到,可以主动释放它占有的资源。
-
破坏循环等待条件 :靠按序申请资源来预防。按某⼀顺序申请资源,释放资源则反序释放。破坏循环等待条件。
面试官:我看你的例子里用到了synchronized,说说 synchronized的用法吧
synchronized 关键字最主要的三种使⽤⽅式:
1.修饰实例⽅法: 作⽤于当前对象实例加锁,进⼊同步代码前要获得 当前对象实例的锁
synchronized void method() {
//业务代码
}
2.修饰静态⽅法: 也就是给当前类加锁,会作⽤于类的所有对象实例 ,进⼊同步代码前要获得当前 class 的锁。因为静态成员不属于任何⼀个实例对象,是类成员( static 表明这是该类的⼀个静态资源,不管 new 了多少个对象,只有⼀份)。所以,如果⼀个线程 A 调⽤⼀个实例对象的⾮静态 synchronized ⽅法,⽽线程 B 需要调⽤这个实例对象所属类的静态 synchronized ⽅法,是允许的,不会发⽣互斥现象,因为访问静态 synchronized ⽅法占⽤的锁是当前类的锁,⽽访问⾮静态 synchronized ⽅法占⽤的锁是当前实例对象锁。
synchronized void staic method() {
//业务代码
}
**3.**修饰代码块 :指定加锁对象,对给定对象/类加锁。 synchronized(this|object) 表示进⼊同步代码库前要获得给定对象的锁。 synchronized(类.class) 表示进⼊同步代码前要获得 当前 class 的锁
synchronized(this) {
//业务代码
}
在我的例子里使用synchronized修饰代码块,给PushProcessServiceImpl类加锁,进⼊同步代码前要获得 当前 class 的锁,防止PushProcessServiceImpl类的对象在控制层调用推送数据的方法。
面试官:除了使用synchronized,还有什么办法来加锁吗?详细说一下
可以使用juc包提供的锁。Lock接口主要相关的类和接口如下。
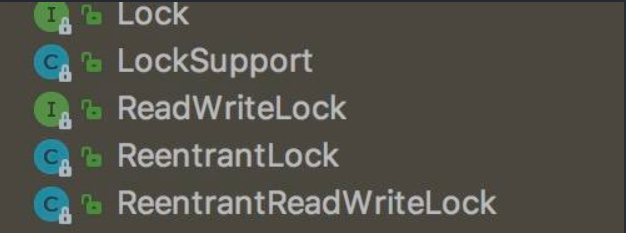
Lock中的主要方法:
-
lock:用来获取锁,如果锁被其他线程获取,进入等待状态。
-
lockInterruptibly:通过这个方法去获取锁时,如果线程正在等待获取锁,则这个线程能够响应中断,即中断线程的等待状态。
-
tryLock:tryLock方法是有返回值的,它表示用来尝试获取锁,如果获取成功,则返回true,如果获取失败(即锁已被其他线程获取),则返回false。
-
tryLock(long,TimeUnit):与tryLock类似,只不过是有等待时间,在等待时间内获取到锁返回true,超时返回false。
-
unlock:释放锁。
其它接口和类:
-
ReetrantLock(可重入锁):实现了Lock接口,可重入锁,内部定义了公平锁与非公平锁。可以完成synchronized 所能完成的所有工作。
-
ReadWriteLock(读写锁):
public interface ReadWriteLock {
Lock readLock(); //获取读锁
Lock writeLock(); //获取写锁
}
一个用来获取读锁,一个用来获取写锁。也就是说将文件的读写操作分开,分成2个锁来分配给线程,从而使得多个线程可以同时进行读操作。
- ReetrantReadWriteLock(可重入读写锁):ReetrantReadWriteLock同样支持公平性选择,支持重进入,锁降级。
| 类别 | synchronized | Lock |
| :-- | :-- | :-- |
| 存在层次 | Java的关键字,在jvm层面上 | 是一个接口,api级别 |
| 锁的释放 | 1、以获取锁的线程执行完同步代码,释放锁 2、线程执行发生异常,jvm会让线程释放锁 | 在finally中必须释放锁,不然容易造成线程死锁 |
| 锁的获取 | 假设A线程获得锁,B线程等待。如果A线程阻塞,B线程会一直等待 | 分情况而定,Lock有多个锁获取的方式,具体下面会说道,大致就是可以尝试获得锁,线程可以不用一直等待 |
| 锁状态 | 无法判断 | 可以判断 |
| 锁类型 | 可重入 不可中断 非公平 | 可重入 可判断 可公平(两者皆可) |
| 性能 | 少量同步 | 大量同步 |
面试官:你提到了synchronized基于jvm层面,对这个有了解吗?
synchronized是利用java提供的原⼦性内置锁(monitor 对象),每个对象中都内置了⼀个 ObjectMonitor 对象。这种内置的并且使⽤者看不到的锁也被称为监视器锁。
同步语句块
synchronized 同步语句块的实现使⽤的是 monitorenter 和 monitorexit 指令,其中monitorenter 指令指向同步代码块的开始位置monitorexit 指令则指明同步代码块的结束位置。
执⾏monitorenter指令时会尝试获取内置锁,如果对象没有被锁定或者已经获得了锁,锁的计数器+1。此时其他竞争锁的线程则会进⼊等待队列中。
执⾏monitorexit指令时则会把计数器-1,当计数器值为0时,则锁释放,处于等待队列中的线程再继续竞争锁。
synchronized 修饰⽅法
synchronized 修饰的⽅法并没有 monitorenter 指令和 monitorexit 指令,取得代之的确实是ACC_SYNCHRONIZED 标识,该标识指明了该⽅法是⼀个同步⽅法。JVM 通过该ACC_SYNCHRONIZED 访问标志来辨别⼀个⽅法是否声明为同步⽅法,从⽽执⾏相应的同步调⽤。
当然,二者细节略有不同,但本质上都是获取原子性内置锁。
再深入一点,synchronized实际上有两个队列waitSet和entryList。
-
当多个线程进⼊同步代码块时,⾸先进⼊entryList
-
有⼀个线程获取到monitor锁后,就赋值给当前线程,并且计数器+1
-
如果线程调⽤wait⽅法,将释放锁,当前线程置为null,计数器-1,同时进⼊waitSet等待被唤醒,调⽤notify或者notifyAll之后⼜会进⼊entryList竞争锁
-
如果线程执⾏完毕,同样释放锁,计数器-1,当前线程置为null
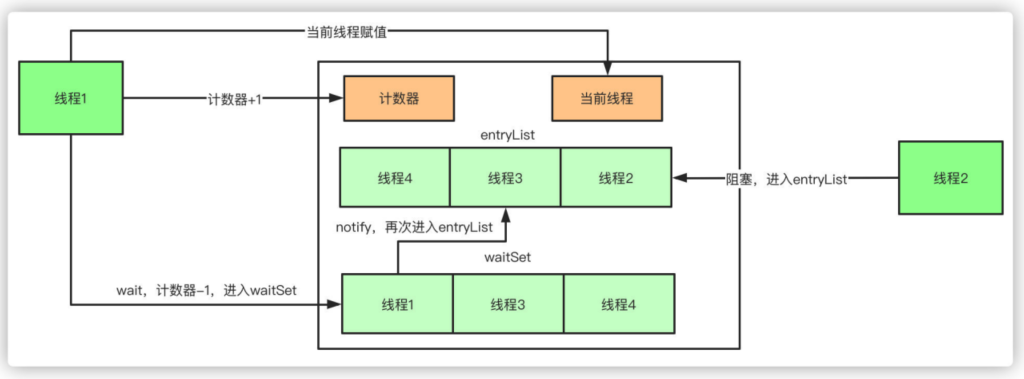
从JDK1.6版本之后,synchronized本身也在不断优化锁的机制,有些情况下他并不会是⼀个很重量级的锁。优化机制包括⾃适应锁、⾃旋锁、锁消除、锁粗化、偏向锁、轻量级锁。
锁的状态从低到⾼依次为⽆锁**->偏向锁->轻量级锁->**重量级锁,升级的过程就是从低到⾼。

自旋锁:由于⼤部分时候,锁被占⽤的时间很短,共享变量的锁定时间也很短,所有没有必要挂起线程,⽤户态和内核态的来回上下⽂切换严重影响性能。⾃旋的概念就是让线程执⾏⼀个忙循环,可以理解为就是啥也不⼲,防⽌从⽤户态转⼊内核态,⾃旋锁可以通过设置-XX:+UseSpining来开启,⾃旋的默认次数是10次,可以使⽤-XX:PreBlockSpin设置。
自适应锁:自适应锁就是自适应的自旋锁,自旋锁的时间不是固定时间,而是由前⼀次在同⼀个锁上的⾃旋时间和锁的持有者状态来决定。
锁消除:锁消除指的是JVM检测到⼀些同步的代码块,完全不存在数据竞争的场景,也就是不需要加锁,就会进⾏锁消除。
锁粗化:锁粗化指的是有很多操作都是对同⼀个对象进⾏加锁,就会把锁的同步范围扩展到整个操作序列之外。
偏向锁:当线程访问同步块获取锁时,会在对象头和栈帧中的锁记录⾥存储偏向锁的线程ID,之后这个线程再次进⼊同步块时都不需要CAS来加锁和解锁了,偏向锁会永远偏向第⼀个获得锁的线程,如果后续没有其他线程获得过这个锁,持有锁的线程就永远不需要进⾏同步,反之,当有其他线程竞争偏向锁时,持有偏向锁的线程就会释放偏向锁。可以⽤过设置-XX:+UseBiasedLocking开启偏向锁。
轻量级锁:JVM的对象的对象头中包含有⼀些锁的标志位,代码进⼊同步块的时候,JVM将会使⽤CAS⽅式来尝试获取锁,如果更新成功则会把对象头中的状态位标记为轻量级锁,如果更新失败,当前线程就尝试⾃旋来获得锁。
锁升级的过程非常复杂,简单点说,偏向锁就是通过对象头的偏向线程ID来对⽐,甚⾄都不需要CAS了,⽽轻量级锁主要就是通过CAS修改对象头锁记录和⾃旋来实现,重量级锁则是除了拥有锁的线程其他全部阻塞。
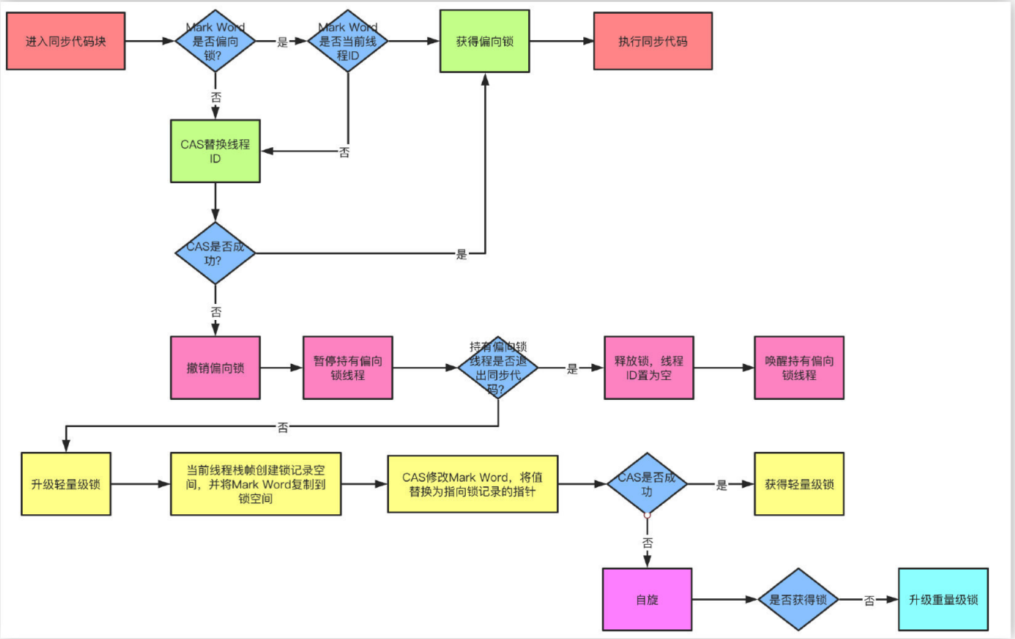
CAS(Compare And Swap/Set)比较并交换,CAS 算法的过程是这样:它包含 3 个参数CAS(V,E,N)。V 表示要更新的变量(内存值),E 表示预期值(旧的),N 表示新值。当且仅当 V 值等于 E 值时,才会将 V 的值设为 N,如果 V 值和 E 值不同,则说明已经有其他线程做了更新,则当前线程什么都不做。最后,CAS 返回当前 V 的真实值。
CAS是一种乐观锁,它总是认为自己可以成功完成操作。当多个线程同时使用 CAS 操作一个变量时,只有一个会胜出,并成功更新,其余均会失败。失败的线程不会被挂起,仅是被告知失败,并且允许再次尝试,当然也允许失败的线程放弃操作。基于这样的原理,CAS 操作即使没有锁,也可以发现其他线程对当前线程的干扰,并进行恰当的处理。
java.util.concurrent.atomic 包下的类大多是使用 CAS 操作来实现的 (AtomicInteger,AtomicBoolean,AtomicLong)。
- ABA 问题:
比如说一个线程 one 从内存位置 V 中取出 A,这时候另一个线程 two 也从内存中取出 A,并且 two 进行了一些操作变成了 B,然后 two 又将 V 位置的数据变成 A,这时候线程 one 进行 CAS 操作发现内存中仍然是 A,然后 one 操作成功。尽管线程 one 的 CAS 操作成功,但可能存在潜藏的问题。从 Java1.5 开始 JDK 的 atomic 包里提供了一个类 AtomicStampedReference 来解决 ABA 问题。
- 循环时间长开销大:
对于资源竞争严重(线程冲突严重)的情况,CAS 自旋的概率会比较大,从而浪费更多的 CPU 资源,效率低于 synchronized。
- 只能保证一个共享变量的原子操作:
当对一个共享变量执行操作时,我们可以使用循环 CAS 的方式来保证原子操作,但是对多个共享变量操作时,循环 CAS 就无法保证操作的原子性,这个时候就可以用锁。
ReentrantLock 是基于 Lock 实现的可重入锁,所有的 Lock 都是基于 AQS 实现的,AQS 和 Condition 各自维护不同的对象,在使用 Lock 和 Condition 时,其实就是两个队列的互相移动。它所提供的共享锁、互斥锁都是基于对 state 的操作。
AbstractQueuedSynchronizer,抽象的队列式的同步器,AQS 定义了一套多线程访问共享资源的同步器框架,许多同步类实现都依赖于它,如常用的
ReentrantLock/Semaphore/CountDownLatch。
AQS 核⼼思想是,如果被请求的共享资源空闲,则将当前请求资源的线程设置为有效的⼯作线程,并且将共享资源设置为锁定状态。如果被请求的共享资源被占⽤,那么就需要⼀套线程阻塞等待以及被唤醒时锁分配的机制,这个机制 AQS 是⽤ CLH 队列锁实现的,即将暂时获取不到锁的线程加⼊到队列中。
看个 AQS原理图:
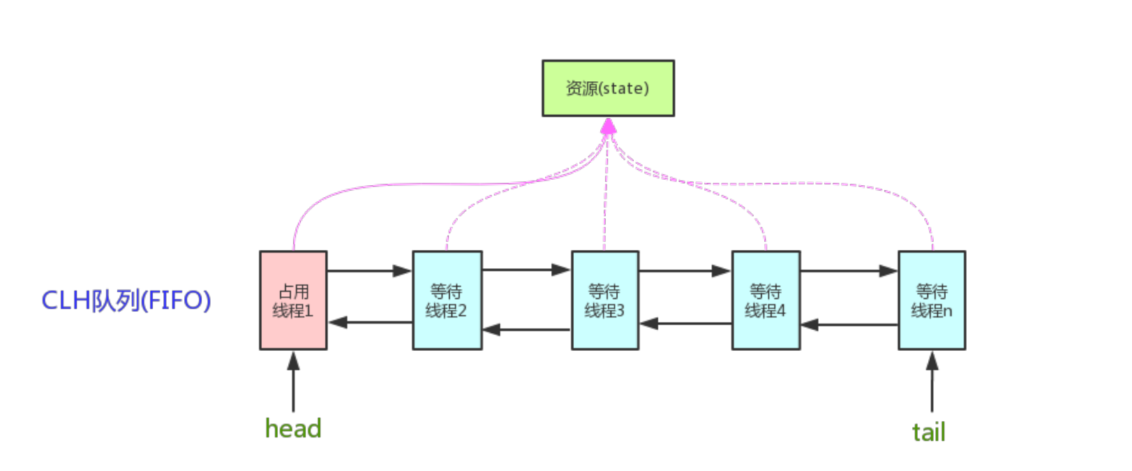
AQS 使⽤⼀个 int 成员变量来表示同步状态,通过内置的 FIFO 队列来完成获取资源线程的排队⼯作。AQS 使⽤ CAS 对该同步状态进⾏原⼦操作实现对其值的修改。
private volatile int state;//共享变量,使⽤volatile修饰保证线程可⻅性
状态信息通过 protected 类型的 getState,setState,compareAndSetState 进⾏操作
//返回同步状态的当前值
protected final int getState() {
return state; }
文末
我将这三次阿里面试的题目全部分专题整理出来,并附带上详细的答案解析,生成了一份PDF文档
- 第一个要分享给大家的就是算法和数据结构

- 第二个就是数据库的高频知识点与性能优化

- 第三个则是并发编程(72个知识点学习)

- 最后一个是各大JAVA架构专题的面试点+解析+我的一些学习的书籍资料

还有更多的Redis、MySQL、JVM、Kafka、微服务、Spring全家桶等学习笔记这里就不一一列举出来
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
成获取资源线程的排队⼯作。AQS 使⽤ CAS 对该同步状态进⾏原⼦操作实现对其值的修改。
private volatile int state;//共享变量,使⽤volatile修饰保证线程可⻅性
状态信息通过 protected 类型的 getState,setState,compareAndSetState 进⾏操作
//返回同步状态的当前值
protected final int getState() {
return state; }
文末
我将这三次阿里面试的题目全部分专题整理出来,并附带上详细的答案解析,生成了一份PDF文档
- 第一个要分享给大家的就是算法和数据结构
[外链图片转存中…(img-6PNn1vDa-1713179480285)]
- 第二个就是数据库的高频知识点与性能优化
[外链图片转存中…(img-VDEoeVwt-1713179480286)]
- 第三个则是并发编程(72个知识点学习)
[外链图片转存中…(img-VJtvAyx7-1713179480286)]
- 最后一个是各大JAVA架构专题的面试点+解析+我的一些学习的书籍资料
[外链图片转存中…(img-yteFsd2E-1713179480286)]
还有更多的Redis、MySQL、JVM、Kafka、微服务、Spring全家桶等学习笔记这里就不一一列举出来
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024b (备注Java)
[外链图片转存中…(img-p4oLNPaV-1713179480287)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 345
345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









