







收集整理了一份《2024年最新Python全套学习资料》免费送给大家,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。






既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Python知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来
如果你需要这些资料,可以添加V无偿获取:hxbc188 (备注666)

正文
num = 10 / 0
finally:
print( “>>>>>>finally”)
if f:
f.close()
输出结果

输出结果说明,尽管with代码块中出现了异常,但是”>>>>>>finally“ 信息还是被打印了,说明finally代码块被执行,即文件关闭操作被执行。但是结果中错误信息还是被输出了,因此还是建议用一个完成的try...except...finally语句对异常信息进行捕获和处理。
#### 3. 最佳实践
为了避免忘记或者为了避免每次都要手动关闭文件,我们可以使用with语句(一种语法糖,语法糖语句通常是为了简化某些操作而设计的)。with语句会在其代码块执行完毕之后自动关闭文件。因此我们可以这样来改写上面的程序:
with open(“song.txt”, ‘r’, encoding="utf-8’ ) as f:
print(f.read())
print(f.closed)
输出结果:

是不是变得简介多了,代码结构也比较清晰了。with之后打印的f.closed属性值为True,说明文件确实被关闭了。
**思考:**
with语句会帮我们自动处理异常信息吗?
要回答这个问题就要提到“上下文管理器” 和 with语句的工作流程。
with语句不仅仅可以用于文件操作,它实际上是一个很通用的结构,允许使用所谓的上下文管理器(context manager)。上下文管理器是一种支持\_\_enter\_\_()和\_\_exit\_\_()这两个方法的对象。\_\_enter\_\_()方法不带任何参数,它在进入with语句块的时候被调用,该方法的返回值会被赋值给as关键字之后的变量。\_\_exit\_\_()方法带有3个参数:type(异常类型), value(异常信息), trace(异常栈),当with语句的代码块执行完毕或执行过程中因为异常而被终止都会调用\_\_exit\_\_()方法。正常退出时该方法的3个参数都为None,异常退出时该方法的3个参数会被分别赋值。如果\_\_exit\_\_()方法返回值(真值测试结果)为True则表示异常已经被处理,命令执行结果中就不会抛出异常信息了;反之,如果\_\_exit\_\_()方法返回值(真值测试结果)为False,则表示异常没有被处理并且会向外抛出该异常。
现在我们应该明白了,异常信息会不会被处理是由with后的语句返回对象的\_\_exit\_\_()方法决定的。文件可以被用作上下文管理器。它的\_\_enter\_\_方法返回文件对象本身,\_\_exit\_\_方法会关闭文件并返回None。我们看下file类中关于这两个方法的实现:
def enter(self): # real signature unknown; restored from doc
“”“enter -> self. “””
return self
def exit_(self,*excinfo): # real signature unknown; restored from doc
“”“exit(*excinfo) -> None.Closes the file.”“”
pass
可见,file类的\_\_exit\_\_()方法的返回值为None,None的真值测试结果为False,因此用于文件读写的with语句代码块中的异常信息还是会被抛出来,需要我们自己去捕获并处理。
#更多Python相关视频、资料加群857662006免费获取
with open(“song.txt”, ‘r’, encoding=" utf-8") as f:
print(f.read())
num = 10/0
输出结果:

**注意:**上面所说的\_\_exit\_\_()方法返回值(真值测试结果)为True则表示异常已经被处理,指的是with代码块中出现的异常。它对于with关键字之后的代码中出现的异常是不起作用的,因为还没有进入上下文管理器就已经发生异常了。因此,无论如何,还是建议在必要的时候在with语句外面套上一层try...except来捕获和处理异常。
有关“上下文管理器”这个强大且高级的特性的更多信息,请参看Python参考手册中的上下文管理器部分。或者可以在Python库参考中查看上下文管理器和contextlib部分。
### 五、Python文件读取相关方法
我们知道,对文件的读取操作需要将文件中的数据加载到内存中,而上面所用到的read()方法会一次性把文件中所有的内容全部加载到内存中。这明显是不合理的,当遇到一个几个G的的文件时,必然会耗光机器的内存。这里我们来介绍下Python中读取文件的相关方法:
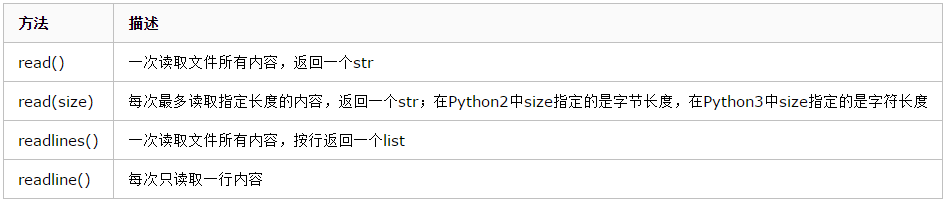
此外,还要两个与文件指针位置相关的方法

下面来看下操作实例
#### 1. 读取指定长度的内容
Python2
with open(‘song.txt’, ‘r’) as f:
print(f.read(12).decode(‘utf-8’))
输出结果:
匆匆那年
结果说明:Python2中read(size)方法的size参数指定的要读取的字节数,而song.txt文件是UTF-8编码的内容,一个汉字占3个字节,因此12个字节刚好是4个汉字。
Python3

输出结果:
匆匆那年我们 究竟说
结果说明:Python3中read(size)方法的size参数指定的要读取的字符数,这与文件的字符编码无关,就是返回12个字符。
#### 2. 读取文件中的一行内容
Python2
with open(‘song.txt’, ‘r’, encoding=‘utf-8’) as f:
print(f.readline()
Python3
with open(‘song.txt’, ‘r’) as f:
print(f.readline(.decode(‘utf-8’))
输出结果都一样:
匆匆那年我们 究竟说了几遍 再见之后再拖延
#### 3. 遍历打印一个文件中的每一行
这里我们只以Python3来进行实例操作,Python2仅仅是需要在读取到内容后进行手动解码而已,上面已经有示例。
方式一:先一次性读取所有行到内存,然后再遍历打印
with open(‘song.txt’, ‘r’, encoding=‘utf-8’) as f:
for line in f.readlines():
print(line)
输出结果:

这种方式的缺点与read()方法是一样的,都是会消耗大量的内存空间。
方式二:通过迭代器一行一行的读取并打印
#更多Python相关视频、资料加群857662006免费获取
with open(‘song.txt’, ‘r’, encoding=‘utf-8’, newline=‘’) as f:
for line in f:
print(line)
输出结果:

另外,发现上面的输出结果中行与行之间多了一个空行。这是因为文件每一行的默认都有换行符,而print()方法也会输出换行,因此就多了一个空行。去掉空行也比较简单:可以用line.rstrip()去除字符串右边的换行符,也可以通过print(line, end='')避免print方法造成的换行。
file类的其他方法:
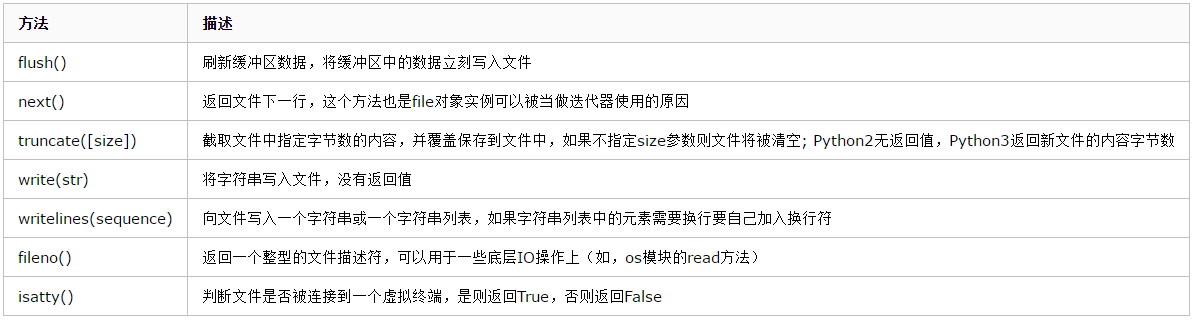
### 六、文件读写与字符编码
前面已经写过一篇介绍Python中字符编码的相关文件[<<再谈Python中的字符串与字符编码>>]( )里面花了很大的篇幅介绍Python中字符串与字符编码的关系以及转换过程。其中谈到过两个指定的字符编码的地方,及其作用:
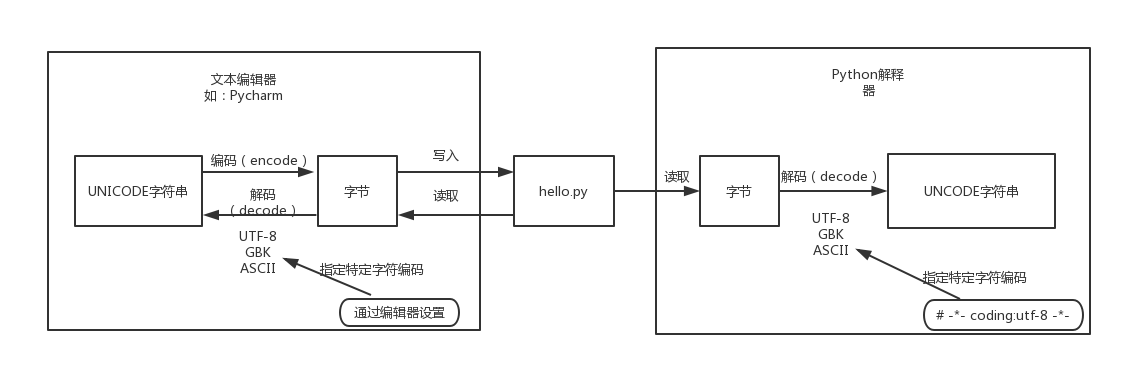
***PyCharm等IDE开发工具指定的项目工程和文件的字符编码:***它的主要作用是告诉Pycharm等IDE开发工具保存文件时应该将字符转换为怎样的字节表示形式,以及打开并展示文件内容时应该以什么字符编码将字节码转换为人类可识别的字符。
***Python源代码文件头部指定的字符编码,如\*-\* coding:utf-8 -\*-:***它的主要作用是告诉Python解释器当前python代码文件保存时所使用的字符编码,Python解释器在执行代码之前,需要先从磁盘读取该代码文件中的字节然后通过这里指定的字符编码将其解码为unicode字符。Python解释器执行Python代码的过程与IDE开发工具是没有什么关联性的。
**那么这里为什么又要谈起字符编码的问题呢?**
或者换个问法,既然从上面已经指定了字符编码,为什么对文件进行读写时还要指定字符编码呢?从前面的描述可以看出:上面两个地方指定的是Python代码文件的字符编码,是给Python解释器和Pycharm等程序软件用的;而被读写文件的字符编码与Python代码文件的字符编码没有必然联系,读写文件时指定的字符编码是给我们写的程序软件用的。这是不同的主体和过程,希望我说明白了。
**读写文件时怎样指定字符编码呢?**
上面解释了读写文件为什么要指定字符编码,这里要说下怎样指定字符编码(其实这里主要讨论是读取外部数据时的情形)。这个问题其实在上面的文件读取示例中已经使用过了,这里我们再详细的说一下。
首先,再次看一下Python2和Python3中open函数的定义:
Python2
open(name[, mode[, buffering]])
#Python3
open(file, mode= ‘r’, buffering=-1,encoding=None,errors=None,newline=None, closefd=True,opener=None)
可以看到,Python3的open函数中多了几个参数,其中包括一个encoding参数。是的,这个encoding就是用来指定被操作文件的字符编码的。
#读操作
with open(‘song.txt’, ‘r’, encoding=‘utf-8’) as f:
print(f.read())
#写操作
with open(‘song.txt’, ‘w’, encoding=‘utf-8’) as f:
print(f.write(‘你好’))
那么Python2中怎样指定呢?Python2中的对文件的read和write操作都是字节,也就说Python2中文件的read相关方法读取的是字节串(如果包含中文字符,会发现len()方法的结果不等于读取到的字符个数,而是字节数)。如果我们要得到 正确的字符串,需要手动将读取到的结果decode(解码)为字符串;相反,要以特定的字符编码保存要写入的数据时,需要手动encode(编码)为字节串。这个encode()和decode()函数可以接收一个字符编码参数。Python3中read和write操作的都是字符串,实际上是Python解释器帮我们自动完成了写入时的encode(编码)和读取时的decode(解码)操作,因此我们只需要在打开文件(open函数)时指定字符编码就可以了。
#读操作
with open(‘song.txt’, ‘r’) as f:
print(f.read().decode(‘utf-8’))
#写操作
with open(‘song2.txt’, “w’) as f:
#f.write(u’你好”.encode(“utf-8”))
#f.write(‘你好’.decode(‘utf-8’).encode(“utf-8”))
f.write('你好")
文件读写时有没有默认编码呢?
Python3中open函数的encoding参数显然是可以不指定的,这时候就会用一个“默认字符编码”。
### 最后
不知道你们用的什么环境,我一般都是用的Python3.6环境和pycharm解释器,没有软件,或者没有资料,没人解答问题,都可以免费领取(包括今天的代码),过几天我还会做个视频教程出来,有需要也可以领取~
给大家准备的学习资料包括但不限于:
Python 环境、pycharm编辑器/永久激活/翻译插件
python 零基础视频教程
Python 界面开发实战教程
Python 爬虫实战教程
Python 数据分析实战教程
python 游戏开发实战教程
Python 电子书100本
Python 学习路线规划

**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**如果你需要这些资料,可以添加V无偿获取:hxbc188 (备注666)**

**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
pe_ZmFuZ3poZW5naGVpdGk,shadow_10,text_aHR0cHM6Ly9ibG9nLmNzZG4ubmV0L2ZlaTM0Nzc5NTc5MA==,size_16,color_FFFFFF,t_70)
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**如果你需要这些资料,可以添加V无偿获取:hxbc188 (备注666)**
[外链图片转存中...(img-viJEHXi2-1713819808243)]
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









