







一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。

二、学习软件
工欲善其事必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
女儿:有没有房子?母亲:有。
女儿:长的帅不帅?母亲:挺帅的。
女儿:收入高不? 母亲:不算很高,中等情况。
女儿:是公务员不?母亲:是,在税务局上班呢。
女儿:那好,我去见见。
这个女孩的决策过程就是典型的分类树决策。相当于通过是否有房、长相、收入和是否公务员对将男人分为两个类别:见和不见。下面我们通过流程图把女儿的决策树判断过程展现出来:
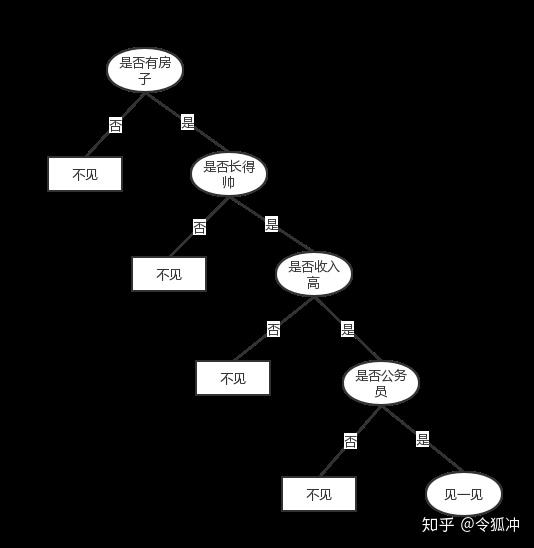
通过这个例子,大家已经对决策树算法有个基本了解了吧,这也是决策树算法的一大优势——数据形式非常容易理解。
2.用python构造决策树基本流程
下图是西瓜书中的决策树学习基本算法,接下来我们将根据这个算法流程用python代码自己写一棵决策树。

在构造决策树时,要解决的第一个问题就是,当前数据集哪个特征在划分数据分类时起决定性作用。在前面相亲的例子中,女孩为何第一个问题是“是否有房子”呢,因为是否有房子这个特征能够提供的“信息量”很大,划分选择就是找提供“信息量”最大的特征,学术上叫信息增益。
3.划分选择(按照信息增益)
什么是信息增益呢,官方介绍请参考西瓜书哈,个人认为就是一个信息提纯的过程,比如一堆黄豆和一堆红豆混在一起,这时候信息的纯度是很低的,如果我们把红豆挑出来了分成两堆,那这时候纯度就高了。这就是一个信息增益的过程,衡量信息纯度的标准,就是信息熵。
信息熵是度量样本集合纯度最常用的一种指标,我的个人理解是对一个事件进行编码,所需要的平均码长就是信息熵,纯度越高,需要的平均代码就越短,信息熵越低。
当前样本集合D中第k类样本所占的比例为pk(k=1,2,…,n),则D的信息熵定义为 
Ent(D)的值越小,则D的纯度越高。
3.1计算信息熵Ent
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
%matplotlib inline
#计算给定数据集的香浓熵
from math import log
def Ent(dataset):
n = len(dataset)
label_counts = {}
for item in dataset:
label_current = item[-1]
if label_current not in label_counts.keys():
label_counts[label_current] = 0
label_counts[label_current] += 1
ent = 0.0
for key in label_counts:
prob = label_counts[key]/n
ent -= prob * log(prob,2)
return ent
#测试我们编写的香浓熵计算函数
data = pd.read_csv('datalab/2891/xigua.csv', encoding='gbk')
Ent(data.iloc[:,-1])
[out]0.9975025463691153
3.2计算信息增益Gain
假定离散属性a有V个可能取值,则会产生V个分支节点,考虑样本数的不同赋予权重|D^v|/|D|,则可以计算出属性a对样本集D进行划分所获得的信息增益为

#按照权重计算各分支的信息熵
def sum_weight(grouped,total_len):
weight = len(grouped)/total_len
return weight * Ent(grouped.iloc[:,-1])
#根据公式计算信息增益
def Gain(column, data):
lenth = len(data)
ent_sum = data.groupby(column).apply(lambda x:sum_weight(x,lenth)).sum()
ent_D = Ent(data.iloc[:,-1])
return ent_D - ent_sum
#计算按照属性'色泽'的信息增益
Gain('色泽', data)
[out]0.10812516526536531
4.使用递归构造决策树
这里我们使用字典存储决策树的结构,如相亲例子中的决策树为(就做两层)
{'是否有房子':{'是':{'是否长得帅':{'是':'见一见'},'否':'不见'},'否':'不见'}}
因为我工作中pandas用得比较多,所以表格数据处理部分用的是pandas
# 计算获取最大的信息增益的feature,输入data是一个dataframe,返回是一个字符串
def get_max_gain(data):
max_gain = 0
cols = data.columns[:-1]
for col in cols:
gain = Gain(col,data)
if gain > max_gain:
max_gain = gain
max_label = col
return max_label
#获取data中最多的类别作为节点分类,输入一个series,返回一个索引值,为字符串
def get_most_label(label_list):
return label_list.value_counts().idxmax()
# 创建决策树,传入的是一个dataframe,最后一列为label
def TreeGenerate(data):
feature = data.columns[:-1]
label_list = data.iloc[:, -1]
#如果样本全属于同一类别C,将此节点标记为C类叶节点
if len(pd.unique(label_list)) == 1:
return label_list.values[0]
#如果待划分的属性集A为空,或者样本在属性A上取值相同,则把该节点作为叶节点,并标记为样本数最多的分类
elif len(feature)==0 or len(data.loc[:,feature].drop_duplicates())==1:
return get_most_label(label_list)
#从A中选择最优划分属性
best_attr = get_max_gain(data)
tree = {best_attr: {}}
#对于最优划分属性的每个属性值,生成一个分支
for attr,gb_data in data.groupby(by=best_attr):
if len(gb_data) == 0:
tree[best_attr][attr] = get_most_label(label_list)
else:
#在data中去掉已划分的属性
new_data = gb_data.drop(best_attr,axis=1)
#递归构造决策树
tree[best_attr][attr] = TreeGenerate(new_data)
return tree
#得到经过训练后的决策树
mytree = TreeGenerate(data)
mytree
[out]{'纹理': {'模糊': '否',
'清晰': {'根蒂': {'硬挺': '否',
'稍蜷': {'色泽': {'乌黑': {'触感': {'硬滑': '是', '软粘': '否'}}, '青绿': '是'}},
'蜷缩': '是'}},
'稍糊': {'触感': {'硬滑': '否', '软粘': '是'}}}}
5.使用matplotlib绘制树形图
这里我们参考《机器学习实战》书中代码
#为了matplotlib中文正常显示,指定字体为SimHei
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['font.family']='sans-serif'
# 获取树的叶子节点数目
def get_num_leafs(decision_tree):
num_leafs = 0
first_str = next(iter(decision_tree))
second_dict = decision_tree[first_str]
for k in second_dict.keys():
if isinstance(second_dict[k], dict):
num_leafs += get_num_leafs(second_dict[k])
else:
num_leafs += 1
return num_leafs
# 获取树的深度
def get_tree_depth(decision_tree):
max_depth = 0
first_str = next(iter(decision_tree))
second_dict = decision_tree[first_str]
**(1)Python所有方向的学习路线(新版)**
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

**(2)Python学习视频**
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

**(3)100多个练手项目**
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化学习资料的朋友,可以戳这里获取](https://bbs.csdn.net/forums/4304bb5a486d4c3ab8389e65ecb71ac0)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
#pic_center)
**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化学习资料的朋友,可以戳这里获取](https://bbs.csdn.net/forums/4304bb5a486d4c3ab8389e65ecb71ac0)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









