







最后
不知道你们用的什么环境,我一般都是用的Python3.6环境和pycharm解释器,没有软件,或者没有资料,没人解答问题,都可以免费领取(包括今天的代码),过几天我还会做个视频教程出来,有需要也可以领取~
给大家准备的学习资料包括但不限于:
Python 环境、pycharm编辑器/永久激活/翻译插件
python 零基础视频教程
Python 界面开发实战教程
Python 爬虫实战教程
Python 数据分析实战教程
python 游戏开发实战教程
Python 电子书100本
Python 学习路线规划

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
今天目标地址:https://travel.qunar.com/place/
开发环境:
windows10
python3.6
开发工具:
pycharm
库:
tkinter、re、os、lxml、threading、xlwt、xlrd
1.首先先将全国所有的城市名称和id拿到
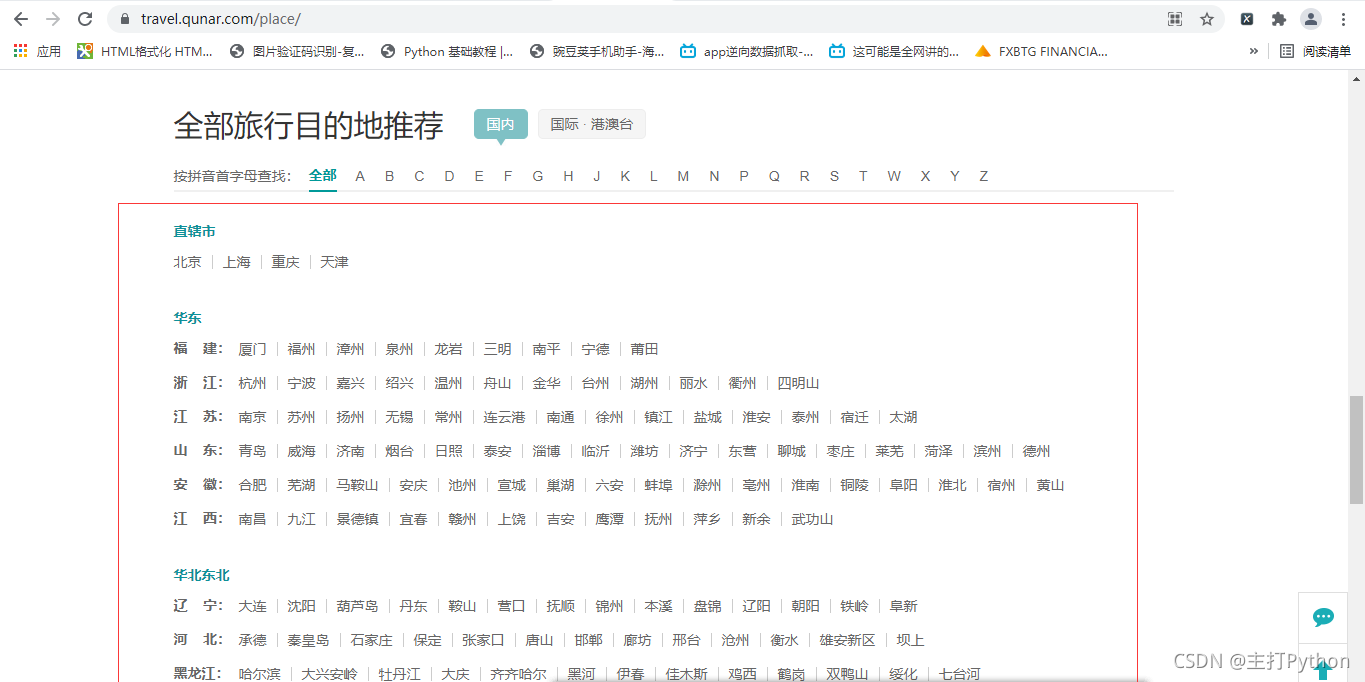
2.右击检查,进行抓包,找到数据所在的包
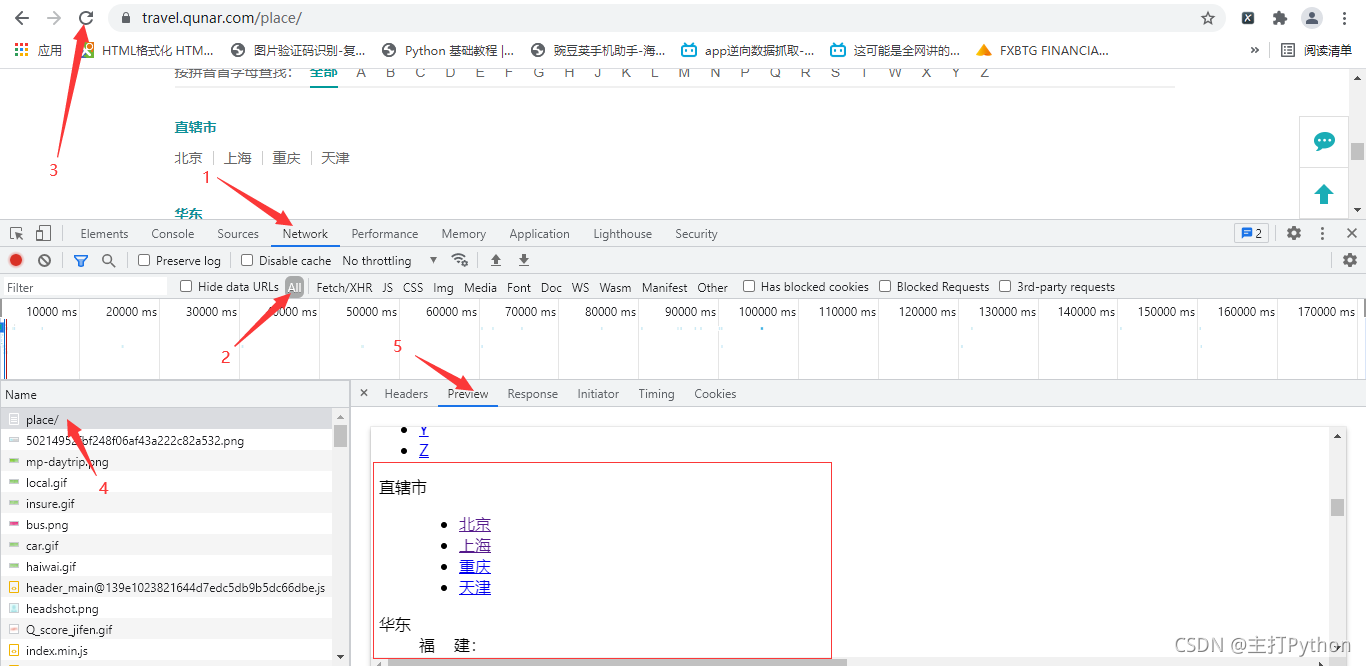
3.发送请求,获取响应,解析响应
发送请求,获取响应,解析响应
response = session.get(self.start_url, headers=self.headers).html
提取所有目的地(城市)的url
city_url_list = response.xpath(
‘//*[@id=“js_destination_recommend”]/div[2]/div[1]/div[2]/dl/dd/div/ul/li/a/@href’)
city_id_list = [‘’.join(re.findall(r’-cs(.*?)-', i)) for i in city_url_list]
提取所有的城市名称
city_name_list = response.xpath(
‘//*[@id=“js_destination_recommend”]/div[2]/div[1]/div[2]/dl/dd/div/ul/li/a/text()’)
4.随机点一个城市,进入该城市,查看游记攻略,本文选的是上海
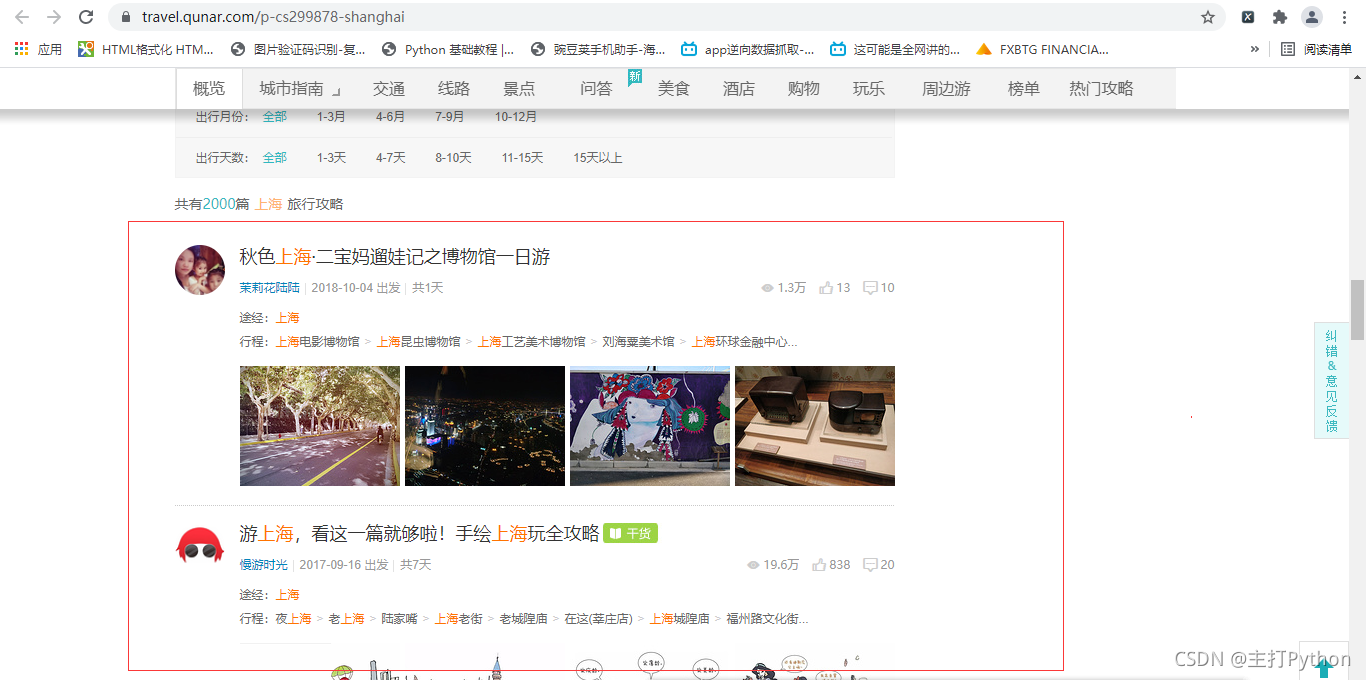
5.进行抓包,查找需要的信息
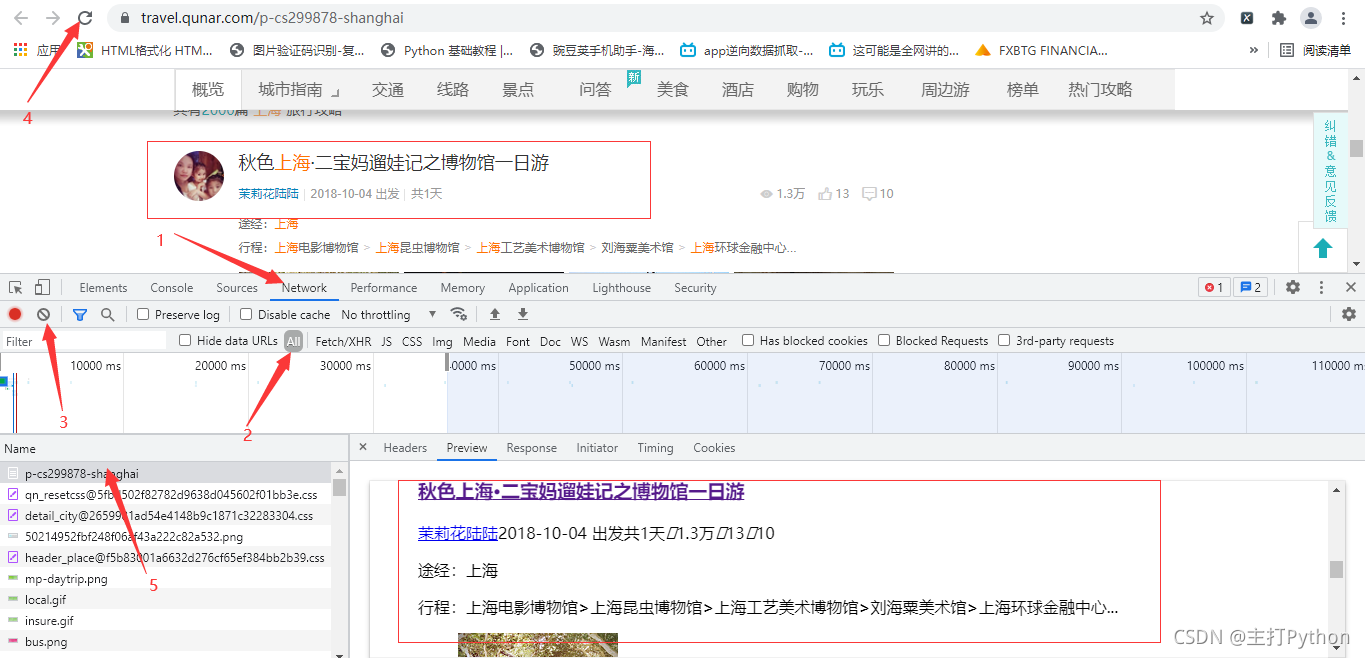
提取游记作者
author_list = html.xpath(‘//span[@class=“user_name”]/a/text()’)
出发时间
date_list = html.xpath(‘//span[@class=“date”]/text()’)
游玩时间
days_list = html.xpath(‘//span[@class=“days”]/text()’)
阅读量
read_list = html.xpath(‘//span[@class=“icon_view”]/span/text()’)
点赞量
like_count_list = html.xpath(‘//span[@class=“icon_love”]/span/text()’)
评论量
icon_list = html.xpath(‘//span[@class=“icon_comment”]/span/text()’)
游记地址
text_url_list = html.xpath(‘//h3[@class=“tit”]/a/@href’)
6.进行翻页抓包,第二页为异步加载
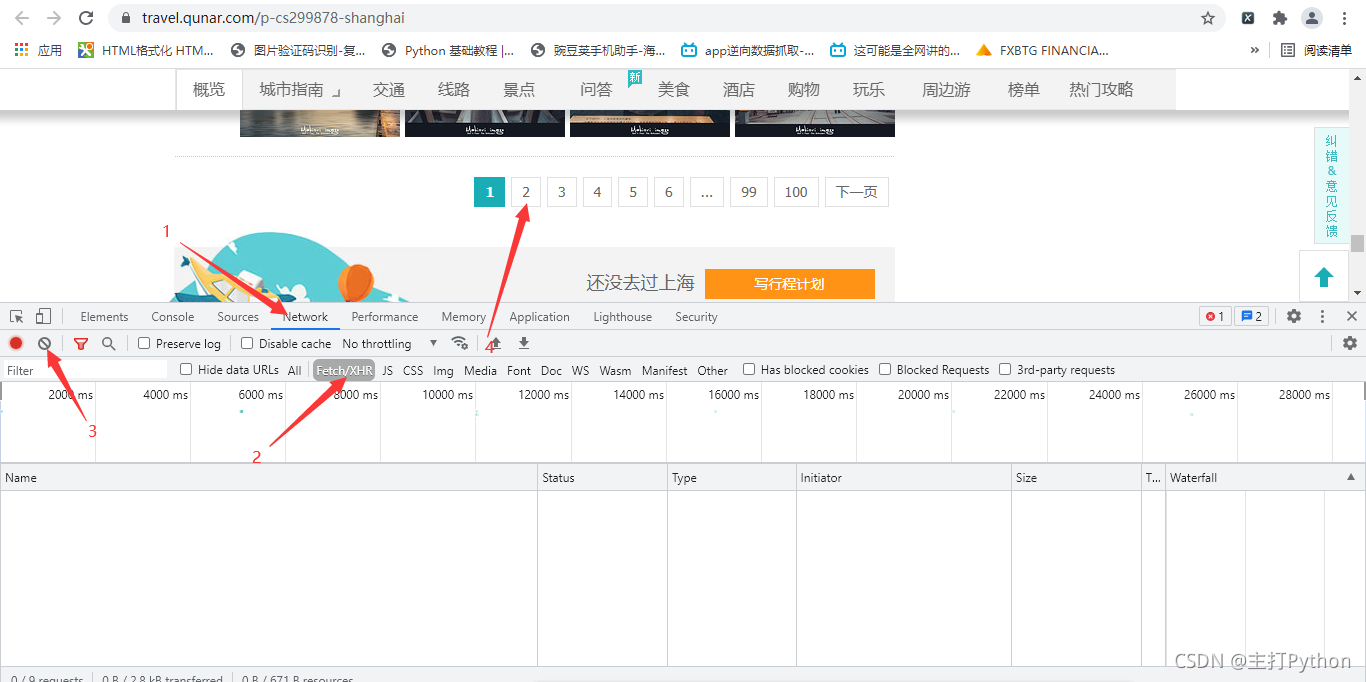
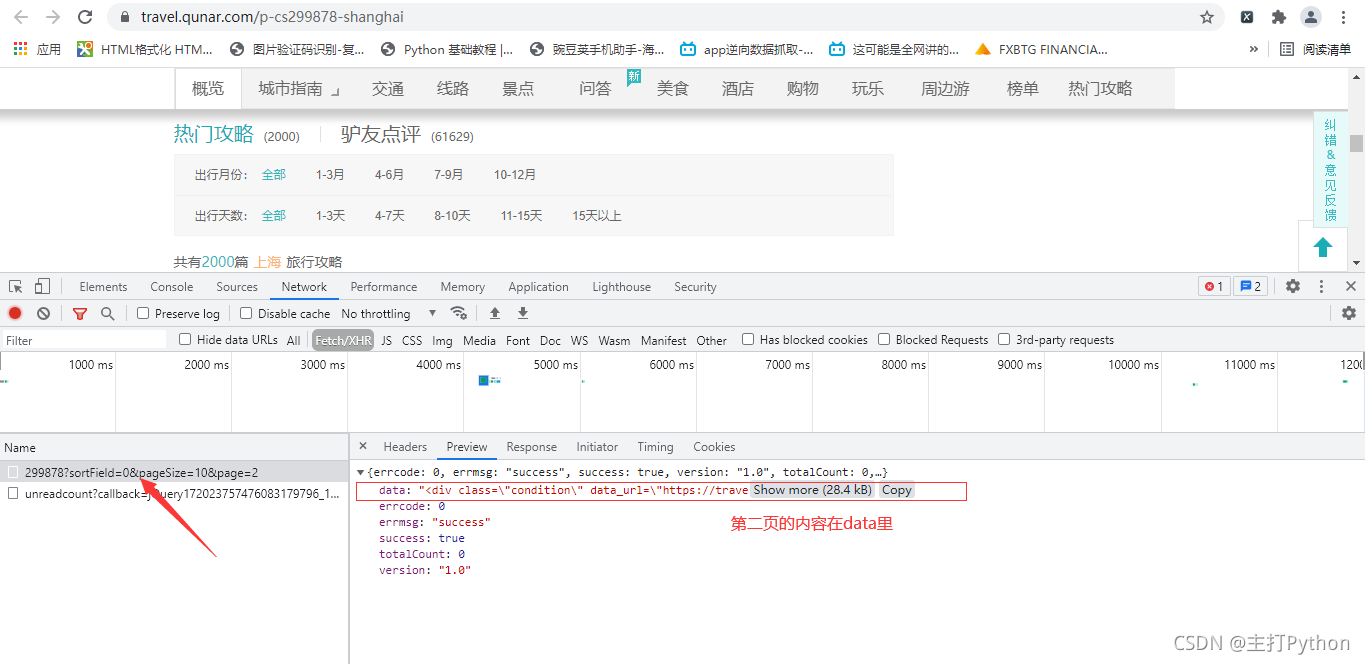
7.在上一张图中点击Headers,获取游记攻略的请求地址
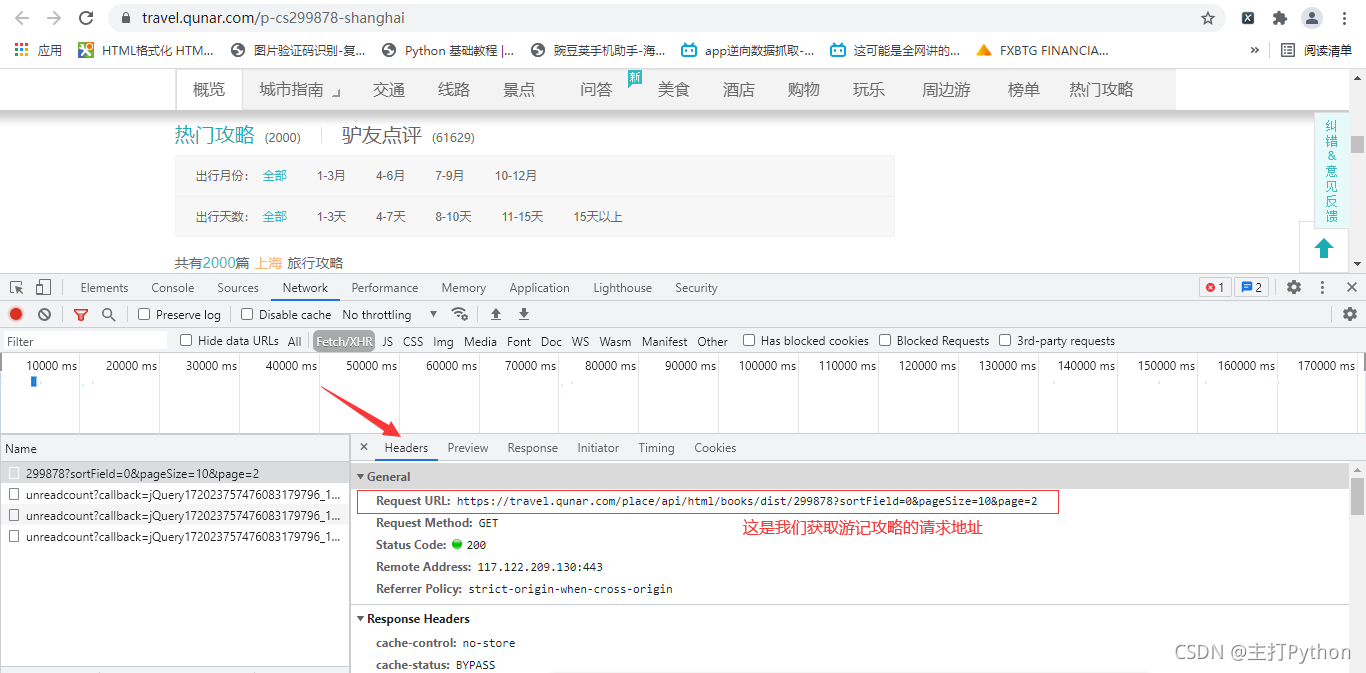
**这样思路是不是清晰一点,来观察一下请求地址https://travel.qunar.com/place/api/html/books/dist/299878?sortField=0&pageSize=10&page=2
其中299878是上海城市的id page是页数**
!/usr/bin/nev python
--coding:utf8--
import tkinter as tk
import re
from lxml import etree
import tkinter.messagebox as msgbox
from requests_html import HTMLSession
from threading import Thread
import os, xlwt, xlrd
from xlutils.copy import copy
session = HTMLSession()
class TKSpider(object):
def init(self):
定义循环条件
self.is_running = True
定义起始的页码
self.start_page = 1
“”“定义可视化窗口,并设置窗口和主题大小布局”“”
self.window = tk.Tk()
self.window.title(‘爬虫数据采集’)
self.window.geometry(‘1000x800’)
“”“创建label_user按钮,与说明书”“”
self.label_user = tk.Label(self.window, text=‘请选择城市输入序号:’, font=(‘Arial’, 12), width=30, height=2)
self.label_user.pack()
“”“创建label_user关联输入”“”
self.entry_user = tk.Entry(self.window, show=None, font=(‘Arial’, 14))
self.entry_user.pack(after=self.label_user)
“”“创建Text富文本框,用于按钮操作结果的展示”“”
定义富文本框滑动条
scroll = tk.Scrollbar()
放到窗口的右侧, 填充Y竖直方向
scroll.pack(side=tk.RIGHT, fill=tk.Y)
self.text1 = tk.Text(self.window, font=(‘Arial’, 12), width=75, height=20)
self.text1.pack()
两个控件关联
scroll.config(command=self.text1.yview)
self.text1.config(yscrollcommand=scroll.set)
“”“定义按钮1,绑定触发事件方法”“”
self.button_1 = tk.Button(self.window, text=‘下载游记’, font=(‘Arial’, 12), width=10, height=1, command=self.parse_hit_click_1)
self.button_1.pack(before=self.text1)
“”“定义按钮2,绑定触发事件方法”“”
self.button_2 = tk.Button(self.window, text=‘清除’, font=(‘Arial’, 12), width=10, height=1, command=self.parse_hit_click_2)
self.button_2.pack(anchor=“e”)
“”“定义富文本文字的显示”“”
self.start_url = ‘https://travel.qunar.com/place/’
self.headers = {
‘user-agent’: ‘Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.159 Safari/537.36’
}
发送请求,获取响应,解析响应
response = session.get(self.start_url, headers=self.headers).html
提取所有目的地(城市)的url
city_url_list = response.xpath(
‘//*[@id=“js_destination_recommend”]/div[2]/div[1]/div[2]/dl/dd/div/ul/li/a/@href’)
city_id_list = [‘’.join(re.findall(r’-cs(.*?)-', i)) for i in city_url_list]
提取所有的城市名称
city_name_list = response.xpath(
‘//*[@id=“js_destination_recommend”]/div[2]/div[1]/div[2]/dl/dd/div/ul/li/a/text()’)
self.dict_data = dict(zip(city_id_list, city_name_list))
text_info = ‘’
for city_id, city_name in zip(city_id_list, city_name_list):
text_info += city_id + “:” + city_name + ‘\t\t’
self.text1.insert(“insert”, text_info)
def parse_hit_click_1(self):
“”“线程关联:定义触发事件1, 将执行结果显示在文本框中”“”
Thread(target=self.parse_start_url_job).start()
def parse_city_id_name_info(self):
“”"
富文本内容展示:
:return:
“”"
发送请求,获取响应,解析响应
response = session.get(self.start_url, headers=self.headers).html
提取所有目的地(城市)的url
city_url_list = response.xpath(
‘//*[@id=“js_destination_recommend”]/div[2]/div[1]/div[2]/dl/dd/div/ul/li/a/@href’)
city_id_list = [‘’.join(re.findall(r’-cs(.*?)-', i)) for i in city_url_list]
提取所有的城市名称
city_name_list = response.xpath(
‘//*[@id=“js_destination_recommend”]/div[2]/div[1]/div[2]/dl/dd/div/ul/li/a/text()’)
self.dict_data = dict(zip(city_id_list, city_name_list))
text_info = ‘’
for city_id, city_name in zip(city_id_list, city_name_list):
text_info += city_id + “:” + city_name + ‘\t\t****’
self.text1.insert(“insert”, text_info)
def parse_start_url_job(self):
从输入窗口获取输入
city_id = self.entry_user.get()
self.text1.delete(“1.0”, “end”)
异常捕捉,是否存在key值
try:
city_name = self.dict_data[city_id]
self.parse_request_yj(city_id, city_name)
except:
报错提示
msgbox.showerror(title=‘错误’, message=‘检测到瞎搞,请重新输入!’)
def parse_request_yj(self, city_id, city_name):
“”"
拼接游记地址,进行翻页
:param city_id: 城市的id
:param city_name: 城市的名称
:return:
“”"
while self.is_running:
yj_url = f’https://travel.qunar.com/place/api/html/books/dist/{city_id}?sortField=0&pageSize=10&page={self.start_page}’
response = session.get(yj_url, headers=self.headers).json()[‘data’].replace(‘\’, ‘’)
html = etree.HTML(response)
提取游记的标题:
title_list = html.xpath(‘//h3[@class=“tit”]/a/text()’)
死循环的终止条件
if not title_list:
print(“该城市已经采集到最后一页----------城市切换中---------logging!!!”)
break
else:
提取游记作者
author_list = html.xpath(‘//span[@class=“user_name”]/a/text()’)
出发时间
date_list = html.xpath(‘//span[@class=“date”]/text()’)
游玩时间
days_list = html.xpath(‘//span[@class=“days”]/text()’)
最后
🍅 硬核资料:关注即可领取PPT模板、简历模板、行业经典书籍PDF。
🍅 技术互助:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。
🍅 面试题库:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。
🍅 知识体系:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









