







文末有福利领取哦~
👉一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
👉二、Python必备开发工具

👉三、Python视频合集
观看零基础学习视频,看视频学习是最快捷也是最有效果的方式,跟着视频中老师的思路,从基础到深入,还是很容易入门的。

👉 四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。(文末领读者福利)

👉五、Python练习题
检查学习结果。

👉六、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


👉因篇幅有限,仅展示部分资料,这份完整版的Python全套学习资料已经上传
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
| | worksheet.write(0, 1, ‘颜色’, style) |
| | |
| | # 写入日期 |
| | style = xlwt.XFStyle() |
| | # Other options: D-MMM-YY, D-MMM, MMM-YY, h:mm, h:mm:ss, h:mm, h:mm:ss, M/D/YY h:mm, mm:ss, [h]:mm:ss, mm:ss.0 |
| | style.num_format_str = ‘M/D/YY’ |
| | worksheet.write(0, 2, datetime.datetime.now(), style) |
| | |
| | # 写入公式 |
| | worksheet.write(0, 3, 5) # Outputs 5 |
| | worksheet.write(0, 4, 2) # Outputs 2 |
| | # Should output “10” (A1[5] * A2[2]) |
| | worksheet.write(1, 3, xlwt.Formula(‘D1*E1’)) |
| | # Should output “7” (A1[5] + A2[2]) |
| | worksheet.write(1, 4, xlwt.Formula(‘SUM(D1,E1)’)) |
| | |
| | # 写入超链接 |
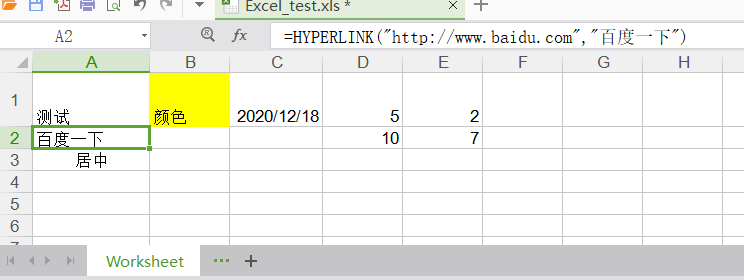
| | worksheet.write(1, 0, xlwt.Formula(‘HYPERLINK(“http://www.baidu.com”;“百度一下”)’)) |
| | # 保存 |
| | workbook.save(‘Excel_test.xls’) |
| | |
需要注意的是最好在当前路径下通过命令行执行,否则无法生成文件。
三、0openpyxl
openpyxl是一个Python库,用于读取/写入Excel 2010 xlsx/xlsm/xltx/xltm文件。
安装包
| pip install openpyx |
安装完成可以开始进行读取数据
| import openpyxl | |
| import os | |
| file_path = os.path.dirname(os.path.abspath(__file__)) | |
| base_path = os.path.join(file_path, ‘data.xlsx’) | |
| workbook = openpyxl.load_workbook(base_path) | |
| worksheet = workbook.get_sheet_by_name(‘Sheet1’) | |
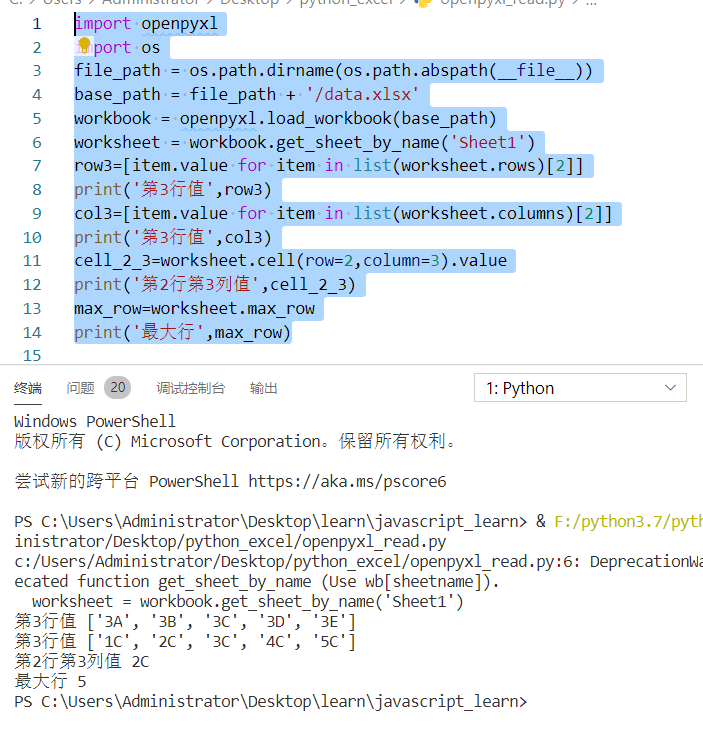
| row3=[item.value for item in list(worksheet.rows)[2]] | |
| print(‘第3行值’,row3) | |
| col3=[item.value for item in list(worksheet.columns)[2]] | |
| print(‘第3行值’,col3) | |
| cell_2_3=worksheet.cell(row=2,column=3).value | |
| print(‘第2行第3列值’,cell_2_3) | |
| max_row=worksheet.max_row | |
| print(‘最大行’,max_row) |
现在我们来开始写入数据
| import openpyxl | |
| import datetime | |
| from openpyxl.styles import Font, colors, Alignment | |
| #实例化 | |
| workbook = openpyxl.Workbook() | |
| # 激活 worksheet | |
| sheet=workbook.active | |
| #写入数据 | |
| sheet[‘A1’]=‘python’ | |
| sheet[‘B1’]=‘javascript’ | |
| #写入时间 | |
| sheet[‘A2’] = datetime.datetime.now().strftime(“%Y-%m-%d”) | |
| # 第2行行高 | |
| sheet.row_dimensions[2].height = 40 | |
| # B列列宽 | |
| sheet.column_dimensions[‘B’].width = 30 | |
| # 设置A1中的数据垂直居中和水平居中 | |
| sheet[‘A1’].alignment = Alignment(horizontal=‘center’, vertical=‘center’) | |
| # 下面的代码指定了等线24号,加粗斜体,字体颜色黄色。直接使用cell的font属性,将Font对象赋值给它。 | |
| bold_itatic_24_font = Font(name=‘等线’, size=24, italic=True, color=‘00FFBB00’, bold=True) | |
| sheet[‘B1’].font = bold_itatic_24_font | |
| # 合并单元格, 往左上角写入数据即可 | |
| sheet.merge_cells(‘A2:B2’) # 合并一行中的几个单元格 | |
| # 拆分单元格 | |
| # sheet.unmerge_cells(‘A2:B2’) | |
| #保存 | |
| workbook.save(‘new.xlsx’) | |
四、0pandas
pandas支持xls, xlsx, xlsm, xlsb, odf, ods和odt文件扩展名从本地文件系统或URL读取。支持读取单个工作表或工作表列表的选项。
首先依然是安装包
| pip install pandas |
语法:
pd.read_excel(io, sheet_name=0, header=0, names=None, index_col=None, usecols=None, squeeze=False,dtype=None, engine=None, converters=None, true_values=None, false_values=None, skiprows=None, nrows=None, na_values=None, parse_dates=False, date_parser=None, thousands=None, comment=None, skipfooter=0, convert_float=True, **kwds)
- io,Excel的存储路径
- sheet_name,要读取的工作表名称
- header, 用哪一行作列名
- names, 自定义最终的列名
- index_col, 用作索引的列
- usecols,需要读取哪些列
- squeeze,当数据仅包含一列
- converters ,强制规定列数据类型
- skiprows,跳过特定行
- nrows ,需要读取的行数
- skipfooter , 跳过末尾n行
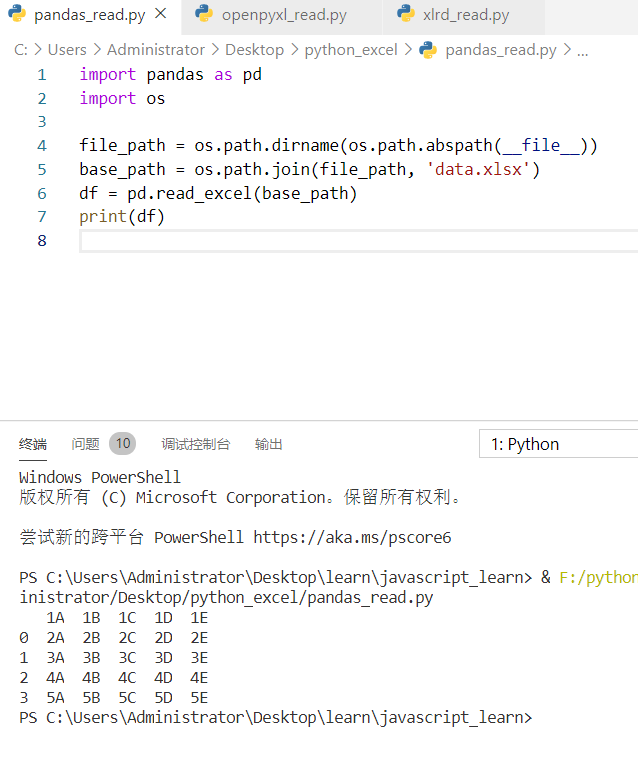
| import pandas as pd | |
| import os | |
| file_path = os.path.dirname(os.path.abspath(__file__)) | |
| base_path = os.path.join(file_path, ‘data.xlsx’) | |
| df = pd.read_excel(base_path) | |
| print(df) |
写入数据
语法:
DataFrame.to_excel(excel_writer, sheet_name=‘Sheet1’, na_rep=‘’, float_format=None, columns=None, header=True, index=True, index_label=None, startrow=0, startcol=0, engine=None, merge_cells=True, encoding=None, inf_rep=‘inf’, verbose=True, freeze_panes=None)
参数说明:
- excel_writer:文件路径或现有的ExcelWriter
- sheet_name:将包含数据文件的工作表的名称
- na_rep:缺失的数据表示
- float_format:格式化浮点数的字符串。例如float_format = " %。2f"格式为0.1234到0.12。
- columns:列
- header:写出列名。如果给定一个字符串列表,则假定它是列名的别名。
- index:写入行名称(索引)
- index_label:如果需要,索引列的列标签。如果未指定,并且标头和索引为真,则使用索引名。如果DataFrame使用多索引,应该给出一个序列。
- startrow:左上角的单元格行转储数据帧。
- startcol:左上角单元格列转储数据帧。
- engine:编写要使用的引擎“ openpyxl”或“ xlsxwriter”。 您还可以通过选项io.excel.xlsx.writer,io.excel.xls.writer和io.excel.xlsm.writer进行设置。
- merge_cells:将多索引和层次结构行写入合并单元格。
- encoding:对生成的excel文件进行编码。仅对xlwt有必要,其他编写器本身支持unicode。
- inf_rep:表示无穷大。
- verbose:在错误日志中显示更多信息。
- freeze_panes:指定要冻结的最底部的行和最右边的列
| from pandas import DataFrame | |
| data = {‘name’: [‘张三’, ‘李四’, ‘王五’],‘age’: [11, 12, 13],‘sex’: [‘男’, ‘女’, ‘男’]} | |
| df = DataFrame(data) | |
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









