







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Python全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Python知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024c (备注Python)

正文
DecryptLogin模块;
pyecharts模块;
以及一些Python自带的模块。
既然说了是模拟登录相关的爬虫小案例,首先自然是要实现一下淘宝的模拟登录啦。这里还是利用我们开源的DecryptLogin库来实现,只需三行代码即可:
‘’‘模拟登录淘宝’‘’
@staticmethod
def login():
lg = login.Login()
infos_return, session = lg.taobao()
return session
另外,顺便提一句,经常有人想让我在DecryptLogin库里加入cookies持久化功能。其实你自己多写两行代码就能实现了:
if os.path.isfile(‘session.pkl’):
self.session = pickle.load(open(‘session.pkl’, ‘rb’))
else:
self.session = TBGoodsCrawler.login()
f = open(‘session.pkl’, ‘wb’)
pickle.dump(self.session, f)
f.close()
我真不想在这个库里添加这个功能,后面我倒是想添加一些其他爬虫相关的功能,这个之后再说吧。好的,偏题了,言归正传吧。接着,我们去网页版的淘宝抓一波包吧。比如F12打开开发者工具后,在淘宝的商品搜索栏里随便输入点东西,就像这样:
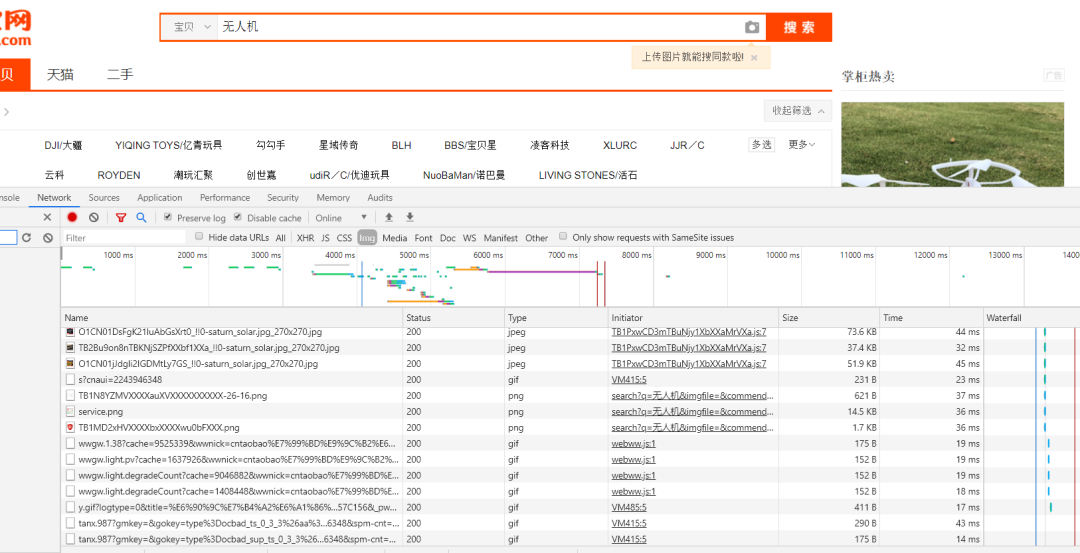

全局搜索一下诸如search这样的关键词,可以发现如下链接:
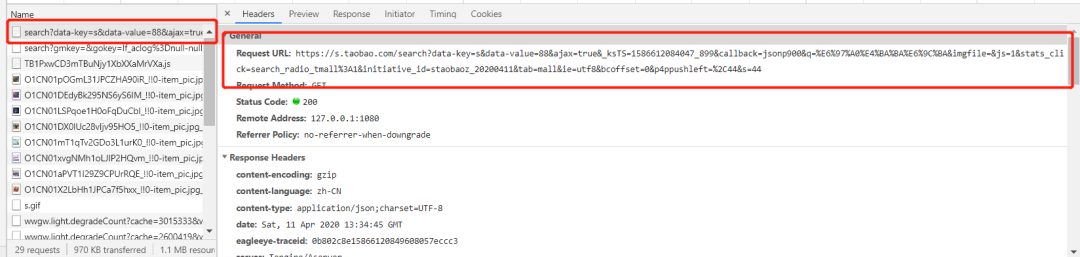

看看它返回的数据是啥:
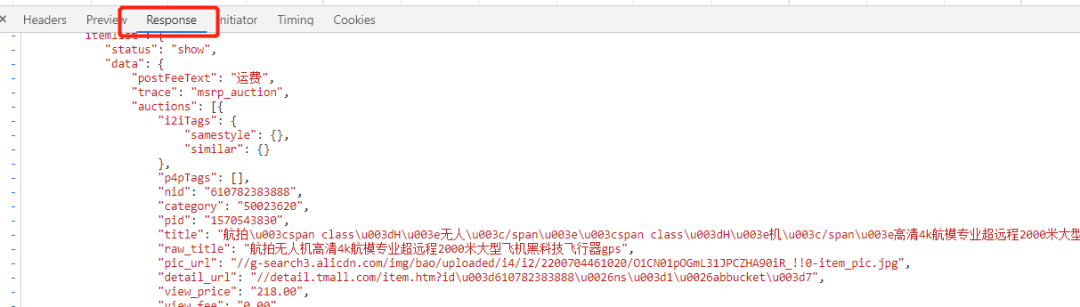

看来应该没错了。另外,如果小伙伴们自己实战的时候没有找到这个接口api,可以尝试再点击一下右上角的下一页商品按钮:
这样就肯定能抓到这个请求接口啦。简单测试一下,可以发现尽管请求这个接口所需携带的参数看上去很多,但实际上必须要提交的参数只有两个,即:
q: 商品名称 s: 当前页码的偏移量
好啦,根据这个接口,以及我们的测试结果,现在就可以愉快地开始实现淘宝商品数据的抓取啦。具体而言,主代码实现如下:
‘’‘外部调用’‘’
def run(self):
search_url = ‘https://s.taobao.com/search?’
while True:
goods_name = input('请输入想要抓取的商品信息名称: ')
offset = 0
page_size = 44
goods_infos_dict = {}
page_interval = random.randint(1, 5)
page_pointer = 0
while True:
params = {
‘q’: goods_name,
‘ajax’: ‘true’,
‘ie’: ‘utf8’,
‘s’: str(offset)
}
response = self.session.get(search_url, params=params)
if (response.status_code != 200):
break
response_json = response.json()
all_items = response_json.get(‘mods’, {}).get(‘itemlist’, {}).get(‘data’, {}).get(‘auctions’, [])
if len(all_items) == 0:
break
for item in all_items:
if not item[‘category’]:
continue
goods_infos_dict.update({len(goods_infos_dict)+1:
{
‘shope_name’: item.get(‘nick’, ‘’),
‘title’: item.get(‘raw_title’, ‘’),
‘pic_url’: item.get(‘pic_url’, ‘’),
‘detail_url’: item.get(‘detail_url’, ‘’),
‘price’: item.get(‘view_price’, ‘’),
‘location’: item.get(‘item_loc’, ‘’),
‘fee’: item.get(‘view_fee’, ‘’),
‘num_comments’: item.get(‘comment_count’, ‘’),
‘num_sells’: item.get(‘view_sales’, ‘’)
}
})
print(goods_infos_dict)
做了那么多年开发,自学了很多门编程语言,我很明白学习资源对于学一门新语言的重要性,这些年也收藏了不少的Python干货,对我来说这些东西确实已经用不到了,但对于准备自学Python的人来说,或许它就是一个宝藏,可以给你省去很多的时间和精力。
别在网上瞎学了,我最近也做了一些资源的更新,只要你是我的粉丝,这期福利你都可拿走。
我先来介绍一下这些东西怎么用,文末抱走。
(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

(4)200多本电子书
这些年我也收藏了很多电子书,大概200多本,有时候带实体书不方便的话,我就会去打开电子书看看,书籍可不一定比视频教程差,尤其是权威的技术书籍。
基本上主流的和经典的都有,这里我就不放图了,版权问题,个人看看是没有问题的。
(5)Python知识点汇总
知识点汇总有点像学习路线,但与学习路线不同的点就在于,知识点汇总更为细致,里面包含了对具体知识点的简单说明,而我们的学习路线则更为抽象和简单,只是为了方便大家只是某个领域你应该学习哪些技术栈。

(6)其他资料
还有其他的一些东西,比如说我自己出的Python入门图文类教程,没有电脑的时候用手机也可以学习知识,学会了理论之后再去敲代码实践验证,还有Python中文版的库资料、MySQL和HTML标签大全等等,这些都是可以送给粉丝们的东西。

这些都不是什么非常值钱的东西,但对于没有资源或者资源不是很好的学习者来说确实很不错,你要是用得到的话都可以直接抱走,关注过我的人都知道,这些都是可以拿到的。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注python)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
对于没有资源或者资源不是很好的学习者来说确实很不错,你要是用得到的话都可以直接抱走,关注过我的人都知道,这些都是可以拿到的。**
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注python)
[外链图片转存中…(img-GBzIPrXc-1713454795788)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









