







做了那么多年开发,自学了很多门编程语言,我很明白学习资源对于学一门新语言的重要性,这些年也收藏了不少的Python干货,对我来说这些东西确实已经用不到了,但对于准备自学Python的人来说,或许它就是一个宝藏,可以给你省去很多的时间和精力。
别在网上瞎学了,我最近也做了一些资源的更新,只要你是我的粉丝,这期福利你都可拿走。
我先来介绍一下这些东西怎么用,文末抱走。
(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

(4)200多本电子书
这些年我也收藏了很多电子书,大概200多本,有时候带实体书不方便的话,我就会去打开电子书看看,书籍可不一定比视频教程差,尤其是权威的技术书籍。
基本上主流的和经典的都有,这里我就不放图了,版权问题,个人看看是没有问题的。
(5)Python知识点汇总
知识点汇总有点像学习路线,但与学习路线不同的点就在于,知识点汇总更为细致,里面包含了对具体知识点的简单说明,而我们的学习路线则更为抽象和简单,只是为了方便大家只是某个领域你应该学习哪些技术栈。

(6)其他资料
还有其他的一些东西,比如说我自己出的Python入门图文类教程,没有电脑的时候用手机也可以学习知识,学会了理论之后再去敲代码实践验证,还有Python中文版的库资料、MySQL和HTML标签大全等等,这些都是可以送给粉丝们的东西。

这些都不是什么非常值钱的东西,但对于没有资源或者资源不是很好的学习者来说确实很不错,你要是用得到的话都可以直接抱走,关注过我的人都知道,这些都是可以拿到的。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
else:
reply_with_voice("抱歉,我没有理解你的意思。")
except sr.UnknownValueError:
print("无法识别语音")
except sr.RequestError as e:
print("请求语音识别服务出错:", str(e))
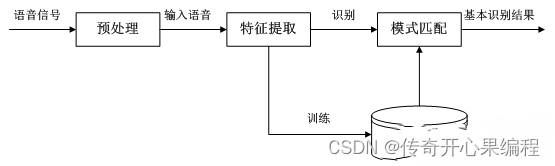
在上述示例代码中,我们首先初始化了语音识别引擎和语音合成引擎。然后,通过`sr.Microphone()`创建一个麦克风对象,用于录制用户的语音输入。接着,我们使用Sphinx进行语音识别,将识别结果存储在`text`变量中。
根据识别结果,我们通过调用`reply_with_voice`函数生成相应的语音回复。在这个示例中,如果识别结果是"你好",则回复"你好,很高兴与你交流。",否则回复"抱歉,我没有理解你的意思。"。
请注意,示例代码中使用的是`speech_recognition`库进行语音识别,你也可以选择其他的语音识别库,如Google Cloud Speech-to-Text、Microsoft Azure Speech等,具体的实现方式会依赖于你选择的库。同样地,你可以根据需要进行适当的定制和配置,如选择合适的声音、调整语速、音量等。
这个示例代码只是一个简单的演示,你可以根据你的具体需求进行更多的定制和扩展。
### 五、Sphinx语音识别前自然语言预处理示例代码

要在Sphinx语音识别之前使用NLP技术进行预处理,你可以使用自然语言处理库(如NLTK、SpaCy、Transformers等)来构建意图识别和槽填充模型。以下是一个示例代码,展示了如何使用NLTK库进行简单的意图识别和槽填充:
import speech_recognition as sr
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
初始化语音识别引擎
r = sr.Recognizer()
初始化NLTK
nltk.download(‘punkt’)
nltk.download(‘stopwords’)
定义意图识别和槽填充函数
def process_input(input_text):
# 分词
tokens = word_tokenize(input_text)
# 去除停用词
stop_words = set(stopwords.words('english'))
filtered_tokens = [token for token in tokens if token.lower() not in stop_words]
# 意图识别
intent = None
if 'weather' in filtered_tokens:
intent = 'weather'
elif 'news' in filtered_tokens:
intent = 'news'
# 槽填充
slots = {}
if 'city' in filtered_tokens:
city_index = filtered_tokens.index('city')
if city_index + 1 < len(filtered_tokens):
slots['city'] = filtered_tokens[city_index + 1]
return intent, slots
录音并进行语音识别
with sr.Microphone() as source:
print(“请说话…”)
audio = r.listen(source)
try:
# 使用Sphinx进行语音识别
text = r.recognize_sphinx(audio)
print("识别结果:", text)
# 进行意图识别和槽填充
intent, slots = process_input(text)
print("意图:", intent)
print("槽:", slots)
# 根据意图和槽生成回复
if intent == 'weather':
if 'city' in slots:
city = slots['city']
reply = f"查询天气:{city}"
else:
reply = "请提供城市名称。"
elif intent == 'news':
reply = "正在获取最新新闻。"
else:
reply = "抱歉,我没有理解你的意思。"
print("回复:", reply)
except sr.UnknownValueError:
print("无法识别语音")
except sr.RequestError as e:
print("请求语音识别服务出错:", str(e))
在上述示例代码中,我们首先初始化了语音识别引擎和NLTK库。然后,定义了一个`process_input`函数,用于对输入文本进行意图识别和槽填充。在这个示例中,我们使用NLTK库进行简单的分词和停用词去除,并根据关键词来判断意图和提取槽信息。
在录音并进行语音识别后,我们调用`process_input`函数对识别结果进行意图识别和槽填充。根据意图和槽信息,我们生成相应的回复。
请注意,这只是一个简单的示例,你可以根据你的具体需求使用更复杂的NLP技术和模型。例如,你可以使用更强大的NLP库(如SpaCy、Transformers等),使用预训练的语言模型进行意图识别和槽填充。你还可以根据需要进行适当的定制和扩展,以满足你的系统需求。
另外,你可以将这个NLP预处理过程与语音识别和语音合成的代码进行集成,以构建一个完整的语音交互系统。
### 六、Sphinx语音识别自动电话系统多级菜单示例代码在这里插入图片描述
以下是一个示例代码,展示了如何使用Sphinx语音识别和槽填充来实现一个多级菜单的自动电话系统:
import speech_recognition as sr
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
初始化语音识别引擎
r = sr.Recognizer()
初始化NLTK
nltk.download(‘punkt’)
nltk.download(‘stopwords’)
定义意图识别和槽填充函数
def process_input(input_text):
# 分词
tokens = word_tokenize(input_text)
# 去除停用词
stop_words = set(stopwords.words('english'))
filtered_tokens = [token for token in tokens if token.lower() not in stop_words]
# 意图识别
intent = None
if 'main' in filtered_tokens:
intent = 'main\_menu'
elif 'products' in filtered_tokens:
intent = 'products\_menu'
elif 'support' in filtered_tokens:
intent = 'support\_menu'
elif 'exit' in filtered_tokens:
intent = 'exit\_menu'
# 槽填充
slots = {}
if 'option' in filtered_tokens:
option_index = filtered_tokens.index('option')
if option_index + 1 < len(filtered_tokens):
slots['option'] = filtered_tokens[option_index + 1]
return intent, slots
定义菜单处理函数
def process_menu(intent, slots):
if intent == ‘main_menu’:
return “欢迎来到主菜单,请选择您想要的操作:产品菜单、支持菜单或退出。”
elif intent == ‘products_menu’:
return “这是产品菜单,请选择您想要的产品:产品A、产品B或返回主菜单。”
elif intent == ‘support_menu’:
return “这是支持菜单,请选择您需要的支持:技术支持、售后服务或返回主菜单。”
elif intent == ‘exit_menu’:
return “感谢您的使用,再见!”
else:
return “抱歉,我没有理解您的意思。”
录音并进行语音识别
with sr.Microphone() as source:
print(“请说话…”)
audio = r.listen(source)
try:
# 使用Sphinx进行语音识别
text = r.recognize_sphinx(audio)
print("识别结果:", text)
# 进行意图识别和槽填充
intent, slots = process_input(text)
print("意图:", intent)
print("槽:", slots)
# 处理菜单
menu_response = process_menu(intent, slots)
print("回复:", menu_response)
except sr.UnknownValueError:
print("无法识别语音")
except sr.RequestError as e:
print("请求语音识别服务出错:", str(e))
在上述示例代码中,我们定义了一个`process_input`函数来进行意图识别和槽填充,根据关键词来判断用户的意图,并提取相关的槽信息。然后,我们定义了一个`process_menu`函数来根据意图和槽信息生成相应的菜单回复。
在录音并进行语音识别后,我们调用`process_input`函数对识别结果进行意图识别和槽填充。然后,我们调用`process_menu`函数来处理菜单,并生成相应的回复。
在这个示例中,我们假设用户可以说出关键词(如"main"、“products”、“support”、“exit”)来选择菜单选项,并使用"option"关键词后面跟随具体选项来选择子菜单选项。你可以根据你的实际需求进行适当的定制和扩展。
请注意,这只是一个简单的示例,你可以根据你的具体需求使用更复杂的NLP技术和模型进行意图识别和槽填充。你还可以根据需要进行适当的定制和扩展,以满足你的自动电话系统的需求。
### 七、Sphinx语音识别自动电话系统个性化交互示例代码
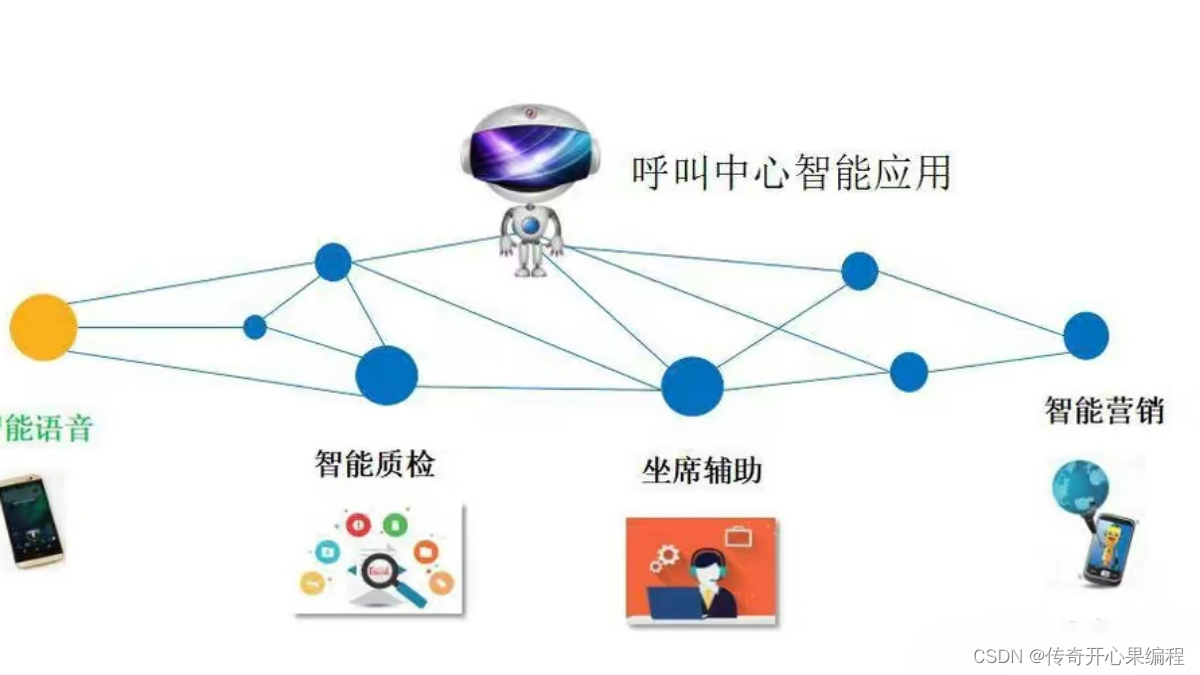
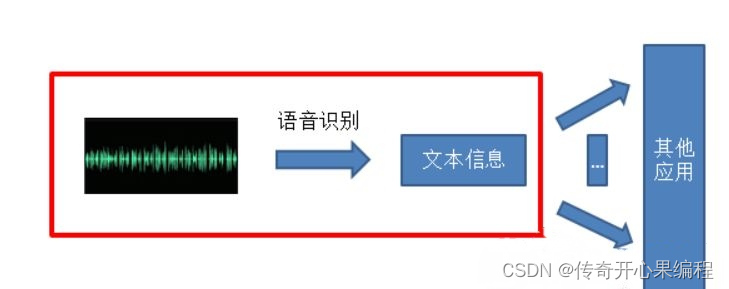要实现一个能够根据用户个人信息和历史记录提供个性化服务和建议的自动电话系统,你需要将个人信息和历史记录与意图识别和槽填充的过程进行集成。以下是一个示例代码,展示了如何使用Sphinx语音识别和NLTK库来实现这个功能:
import speech_recognition as sr
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
初始化语音识别引擎
r = sr.Recognizer()
初始化NLTK
nltk.download(‘punkt’)
nltk.download(‘stopwords’)
用户个人信息和历史记录
user_profile = {
‘name’: ‘John’,
‘age’: 30,
‘preferences’: [‘product A’, ‘service B’],
‘history’: [‘product A’, ‘product C’, ‘service B’]
}
定义意图识别和槽填充函数
def process_input(input_text):
# 分词
tokens = word_tokenize(input_text)
# 去除停用词
stop_words = set(stopwords.words('english'))
filtered_tokens = [token for token in tokens if token.lower() not in stop_words]
# 意图识别
intent = None
if 'recommend' in filtered_tokens:
intent = 'recommendation'
elif 'history' in filtered_tokens:
intent = 'history'
elif 'preferences' in filtered_tokens:
intent = 'preferences'
# 槽填充
slots = {}
if 'product' in filtered_tokens:
product_index = filtered_tokens.index('product')
if product_index + 1 < len(filtered_tokens):
slots['product'] = filtered_tokens[product_index + 1]
return intent, slots
定义个性化处理函数
def process_personalized(intent, slots):
if intent == ‘recommendation’:
if ‘product’ in slots:
product = slots[‘product’]
if product in user_profile[‘preferences’]:
return f"根据您的偏好,我推荐您尝试{product}。"
else:
return f"很抱歉,根据您的偏好,我无法为您推荐{product}。"
else:
return “请提供产品名称。”
elif intent == ‘history’:
return f"您的历史记录包括:{', ‘.join(user_profile[‘history’])}。"
elif intent == ‘preferences’:
return f"您的偏好包括:{’, '.join(user_profile[‘preferences’])}。"
else:
return “抱歉,我没有理解您的意思。”
录音并进行语音识别
with sr.Microphone() as source:
print(“请说话…”)
audio = r.listen(source)
try:
# 使用Sphinx进行语音识别
text = r.recognize_sphinx(audio)
print("识别结果:", text)
# 进行意图识别和槽填充
intent, slots = process_input(text)
print("意图:", intent)
print("槽:", slots)
# 处理个性化请求
personalized_response = process_personalized(intent, slots)
print("回复:", personalized_response)
except sr.UnknownValueError:
print("无法识别语音")
except sr.RequestError as e:
print("请求语音识别服务出错:", str(e))
在上述示例代码中,我们首先定义了一个`user_profile`字典,包含了用户的个人信息和历史记录。然后,我们定义了一个`process_input`函数来进行意图识别和槽填充,根据关键词来判断用户的意图,并提取相关的槽信息。接下来,我们定义了一个`process_personalized`函数来根据用户个人信息和意图槽信息生成个性化的回复。
在录音并进行语音识别后,我们调用`process_input`函数对识别结果进行意图识别和槽填充。然后,我们调用`process_personalized`函数来处理个性化请求,并生成相应的回复。
在这个示例中,我们假设用户可以说出关键词(如"recommend"、“history”、“preferences”)来请求个性化的服务和建议,并使用"product"关键词后面跟随具体产品来指定相关操作。根据用户的个人信息和历史记录,我们可以根据用户的偏好和历史记录来推荐相关的产品或服务,或者展示用户的历史记录和偏好。
请注意,这只是一个简单的示例,你可以根据你的具体需求使用更复杂的NLP技术和模型进行意图识别和槽填充。你还可以根据需要进行适当的定制和扩展,以满足你的自动电话系统的个性化交互需求。
### 八、Sphinx语音识别自动电话系统错误处理和重试机制示例代码

要实现Sphinx语音识别自动电话系统的错误处理和重试机制,你可以在识别错误或无法理解用户语音输入时,提示用户重新输入或提供备选选项。以下是一个示例代码,展示了如何实现这个功能:
import speech_recognition as sr
import nltk
from nltk.tokenize import word_tokenize
from nltk.corpus import stopwords
初始化语音识别引擎
r = sr.Recognizer()
初始化NLTK
nltk.download(‘punkt’)
nltk.download(‘stopwords’)
定义意图识别和槽填充函数
def process_input(input_text):
# 分词
tokens = word_tokenize(input_text)
# 去除停用词
stop_words = set(stopwords.words('english'))
filtered_tokens = [token for token in tokens if token.lower() not in stop_words]
# 意图识别
intent = None
if 'recommend' in filtered_tokens:
intent = 'recommendation'
elif 'retry' in filtered_tokens:
intent = 'retry'
elif 'exit' in filtered_tokens:
intent = 'exit'
# 槽填充
slots = {}
if 'product' in filtered_tokens:
product_index = filtered_tokens.index('product')
if product_index + 1 < len(filtered_tokens):
slots['product'] = filtered_tokens[product_index + 1]
return intent, slots
录音并进行语音识别
def recognize_speech():
with sr.Microphone() as source:
print(“请说话…”)
audio = r.listen(source)
try:
# 使用Sphinx进行语音识别
text = r.recognize_sphinx(audio)
print("识别结果:", text)
# 进行意图识别和槽填充
intent, slots = process_input(text)
print("意图:", intent)
print("槽:", slots)
return intent, slots
except sr.UnknownValueError:
print("无法识别语音")
return 'retry', {}
except sr.RequestError as e:
print("请求语音识别服务出错:", str(e))
return 'retry', {}
定义错误处理和重试机制
def handle_error(intent, slots):
if intent == ‘retry’:
print(“抱歉,我没有理解您的意思,请重新说话。”)
return recognize_speech()
elif intent == ‘exit’:
print(“感谢您的使用,再见!”)
return intent, slots
else:
print(“抱歉,我没有理解您的意思。”)
return recognize_speech()
主循环
def main_loop():
while True:
intent, slots = recognize_speech()
if intent == ‘exit’:
break
intent, slots = handle_error(intent, slots)
# 处理其他意图
# ...
启动主循环
main_loop()
在上述示例代码中,我们定义了一个`recognize_speech`函数,用于录音并进行语音识别。在识别错误或无法理解用户语音输入时,我们返回一个特定的意图(“retry”)来触发错误处理和重试机制。
在`handle_error`函数中,我们根据意图来处理错误情况。如果意图是"retry",我们会提示用户重新说话,并调用`recognize_speech`函数再次进行语音识别。如果意图是"exit",表示用户选择退出,我们会结束循环。对于其他意图,你可以根据实际需求进行相应的处理。
在主循环中,我们不断调用`recognize_speech`函数来进行语音识别,并根据返回的意图和槽信息进行处理。如果用户选择退出,则结束循环。
请注意,这只是一个简单的示例,你可以根据你的具体需求和业务逻辑进行适当的定制和扩展。你可以根据需要添加其他意图的处理逻辑,并进一步改进错误处理和重试机制,以提高系统的容错性和用户体验。
### 九、Sphinx语音识别自动电话系统与客户关系管理(CRM)系统的集成示例代码
要实现Sphinx语音识别自动电话系统与客户关系管理(CRM)系统的集成,你可以使用适当的CRM API来获取用户的身份和历史记录,并根据这些信息提供个性化的服务。以下是一个示例代码,展示了如何实现这个功能:
import speech_recognition as sr
import requests
初始化语音识别引擎
r = sr.Recognizer()
CRM系统的API地址
crm_api_url = “https://your-crm-api-url.com”
录音并进行语音识别
def recognize_speech():
with sr.Microphone() as source:
print(“请说话…”)
audio = r.listen(source)
try:
# 使用Sphinx进行语音识别
text = r.recognize_sphinx(audio)
print("识别结果:", text)
# 调用CRM API获取用户信息
user_info = get_user_info(text)
print("用户信息:", user_info)
# 根据用户信息提供个性化服务
provide_personalized_service(user_info)
except sr.UnknownValueError:
print("无法识别语音")
except sr.RequestError as e:
print("请求语音识别服务出错:", str(e))
调用CRM API获取用户信息
def get_user_info(text):
# 发送请求到CRM系统的API
response = requests.get(crm_api_url + “/user”, params={“text”: text})
# 解析API响应
if response.status_code == 200:
user_info = response.json()
return user_info
else:
print("获取用户信息失败:", response.text)
return {}
根据用户信息提供个性化服务
def provide_personalized_service(user_info):
if “name” in user_info:
print(“欢迎您,”, user_info[“name”])
# 提供个性化服务
# …
主循环
def main_loop():
while True:
recognize_speech()
启动主循环
main_loop()
在上述示例代码中,我们定义了一个`recognize_speech`函数,用于录音并进行语音识别。在识别完成后,我们调用`get_user_info`函数来获取用户信息。该函数会发送一个HTTP GET请求到CRM系统的API,并传递识别结果作为参数。CRM系统的API会返回与用户相关的信息,例如用户的姓名、历史记录等。
然后,我们调用`provide_personalized_service`函数来提供个性化的服务。在这个函数中,你可以根据用户的信息和历史记录来实现相应的个性化逻辑。例如,根据用户的姓名进行欢迎,或者根据用户的历史记录提供相关的推荐或建议。
在主循环中,我们不断调用`recognize_speech`函数来进行语音识别和CRM集成。你可以根据实际需求和业务逻辑进行适当的定制和扩展。请确保在使用CRM API时,提供正确的API地址和参数,并处理API响应的错误情况。
需要注意的是,上述示例代码仅展示了与CRM系统的集成部分,你可能还需要根据具体需求实现其他功能,例如语音合成来提供回复或提示信息,或者与其他系统进行集成以获取更多的功能和信息。
### 十、Sphinx语音识别自动电话系统的实时语音分析示例代码
要实现Sphinx语音识别自动电话系统的实时语音分析,你可以结合使用Sphinx和其他语音处理库,如pyAudioAnalysis,来提取用户的语音特征。以下是一个示例代码,演示了如何实现实时语音分析:
import speech_recognition as sr
from pyAudioAnalysis import audioBasicIO
from pyAudioAnalysis import audioFeatureExtraction
初始化语音识别引擎
r = sr.Recognizer()
录音并进行实时语音分析
def analyze_speech():
with sr.Microphone() as source:
print(“请说话…”)
audio = r.listen(source)
try:
# 使用Sphinx进行语音识别
text = r.recognize_sphinx(audio)
print("识别结果:", text)
# 提取语音特征
features = extract_audio_features(audio)
# 分析语音特征
analyze_audio_features(features)
except sr.UnknownValueError:
print("无法识别语音")
except sr.RequestError as e:
print("请求语音识别服务出错:", str(e))
提取语音特征
def extract_audio_features(audio):
# 将语音转换为numpy数组
audio_data = audio.get_array_of_samples()
audio_data = audio_data.astype(float)
# 提取语音特征
[features, feature_names] = audioFeatureExtraction.stFeatureExtraction(
audio_data, audio.sample_rate, 0.050 \* audio.sample_rate, 0.025 \* audio.sample_rate
)
return features
分析语音特征
def analyze_audio_features(features):
# 在这里根据特征进行分析
# 可以使用机器学习模型、规则引擎等方法进行情感、语调和语速分析
# 根据分析结果提供相应的回应和支持
# 示例:打印语音特征
print("语音特征:")
for i, feature in enumerate(features):
print(f"{i+1}. {feature}")
主循环
def main_loop():
while True:
analyze_speech()
启动主循环
main_loop()
在上述示例代码中,我们定义了一个`analyze_speech`函数,用于录音并进行实时语音分析。在函数中,我们使用Sphinx进行语音识别,并获取识别结果。然后,我们调用`extract_audio_features`函数来提取语音特征。该函数使用pyAudioAnalysis库来将语音转换为numpy数组,并提取特征。你可以根据需要选择适合的特征提取方法。
接下来,我们调用`analyze_audio_features`函数来分析语音特征。在这个函数中,你可以使用机器学习模型、规则引擎或其他方法来进行情感、语调和语速分析。根据分析结果,你可以提供相应的回应和支持,例如调整回答的语气、提供更好的服务或转接到专门的支持人员。
在主循环中,我们不断调用`analyze_speech`函数来进行实时语音分析。你可以根据实际需求和业务逻辑进行适当的定制和扩展。请确保在使用pyAudioAnalysis库时,按照库的文档提供正确的参数和处理方式。
需要注意的是,上述示例代码仅展示了实时语音分析的部分,你可能还需要根据具体需求实现其他功能,例如与CRM系统的集成、语音合成等。同时,实时语音分析可能需要较高的计算资源,你可能需要考虑优化和扩展的问题。
### 十一、Sphinx语音识别自动电话系统呼叫路由和排队示例代码在这里插入图片描述
要实现Sphinx语音识别自动电话系统的呼叫路由和排队机制,你可以使用一些队列数据结构和多线程编程来管理呼叫和服务的顺序。以下是一个示例代码,演示了如何实现呼叫路由和排队机制:
import threading
import queue
import time
定义呼叫队列
call_queue = queue.Queue()
定义服务线程
class ServiceThread(threading.Thread):
def __init__(self, name):
threading.Thread.init(self)
self.name = name
def run(self):
while True:
# 从呼叫队列获取呼叫
call = call_queue.get()
# 处理呼叫
process_call(call)
# 标记呼叫完成
call_queue.task_done()
处理呼叫
def process_call(call):
# 在这里实现呼叫的具体处理逻辑
# 可以调用语音识别、语音分析、回答问题等功能
# 根据呼叫的特点和需求提供相应的服务
# 示例:打印呼叫信息
print(f"正在处理呼叫 {call}...")
初始化服务线程
service_thread = ServiceThread(“ServiceThread”)
service_thread.start()
模拟呼叫
def simulate_call():
while True:
# 模拟呼叫,生成一个随机的呼叫号码
call = “Call-” + str(time.time())
# 将呼叫加入队列
call_queue.put(call)
# 打印呼叫信息
print(f"收到呼叫 {call}")
# 模拟呼叫间隔
time.sleep(2)
启动模拟呼叫
simulate_call()
在上述示例代码中,我们定义了一个`call_queue`队列,用于存储呼叫。然后,我们定义了一个`ServiceThread`类,继承自`threading.Thread`,用于处理呼叫。在`ServiceThread`的`run`方法中,我们使用一个无限循环来不断从呼叫队列中获取呼叫,并调用`process_call`函数来处理呼叫。
在`process_call`函数中,你可以实现具体的呼叫处理逻辑。例如,你可以调用语音识别、语音分析等功能来处理呼叫,并根据呼叫的特点和需求提供相应的服务。在示例中,我们只是简单地打印呼叫信息。
然后,我们初始化一个`ServiceThread`实例,并启动服务线程。接下来,我们定义了一个`simulate_call`函数,用于模拟呼叫。在函数中,我们使用一个无限循环来模拟不断收到呼叫,并将呼叫加入到呼叫队列中。在这里,你可以根据实际需求来生成呼叫号码和设置呼叫间隔。
最后,我们调用`simulate_call`函数来启动模拟呼叫。
需要注意的是,上述示例代码仅展示了呼叫路由和排队机制的部分,你可能还需要根据具体需求实现其他功能,例如呼叫转接、呼叫优先级等。同时,多线程编程需要考虑线程安全和同步的问题,你可能需要使用适当的锁或信号量来保证数据的一致性和线程的安全性。
要实现呼叫转接和呼叫优先级功能,并确保多线程编程的线程安全和同步,你可以使用适当的锁或信号量来保证数据的一致性和线程的安全性。以下是一个示例代码,演示了如何实现呼叫转接、呼叫优先级和线程安全:
import threading
import queue
import time
定义呼叫队列
call_queue = queue.PriorityQueue()
定义呼叫转接队列
transfer_queue = queue.Queue()
定义锁
lock = threading.Lock()
定义服务线程
class ServiceThread(threading.Thread):
def __init__(self, name):
threading.Thread.init(self)
self.name = name
def run(self):
现在能在网上找到很多很多的学习资源,有免费的也有收费的,当我拿到1套比较全的学习资源之前,我并没着急去看第1节,我而是去审视这套资源是否值得学习,有时候也会去问一些学长的意见,如果可以之后,我会对这套学习资源做1个学习计划,我的学习计划主要包括规划图和学习进度表。
分享给大家这份我薅到的免费视频资料,质量还不错,大家可以跟着学习

网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









