







最后
🍅 硬核资料:关注即可领取PPT模板、简历模板、行业经典书籍PDF。
🍅 技术互助:技术群大佬指点迷津,你的问题可能不是问题,求资源在群里喊一声。
🍅 面试题库:由技术群里的小伙伴们共同投稿,热乎的大厂面试真题,持续更新中。
🍅 知识体系:含编程语言、算法、大数据生态圈组件(Mysql、Hive、Spark、Flink)、数据仓库、Python、前端等等。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
内建函数open, 能够打开一个指定路径下的文件, 返回一个文件对象.
open最常用的有两个参数, 第一个参数是文件名(绝对路径或者相对路径), 第二个是打开方式
- ‘r’/‘w’/‘a’/‘b’,表示读(默认)/写/追加写/二进制.
- 注意:打开文件一定要记得关闭
a = open('Z:/test.txt','r') #注意不是反斜杠,Z盘要大写
a.close() #关闭文件
关于内建函数:
我们反复遇到了 “内建函数” 这个词. 内建函数其实是包含在 __builtins__ 这个模块中的一些函数.
而 _builtins_ 这个模块Python解释器会自动包含.
使用 dir(_builtins_) 可以看到Python中一共有哪些内建函数
print(dir(__builtins__))
#执行结果:
['ArithmeticError', 'AssertionError', 'AttributeError', 'BaseException', 'BlockingIOError', 'BrokenPipeError', 'BufferError', 'BytesWarning', 'ChildProcessError', 'ConnectionAbortedError', 'ConnectionError', 'ConnectionRefusedError', 'ConnectionResetError', 'DeprecationWarning', 'EOFError', 'Ellipsis', 'EnvironmentError', 'Exception', 'False', 'FileExistsError', 'FileNotFoundError', 'FloatingPointError', 'FutureWarning', 'GeneratorExit', 'IOError', 'ImportError', 'ImportWarning', 'IndentationError', 'IndexError', 'InterruptedError', 'IsADirectoryError', 'KeyError', 'KeyboardInterrupt', 'LookupError', 'MemoryError', 'ModuleNotFoundError', 'NameError', 'None', 'NotADirectoryError', 'NotImplemented', 'NotImplementedError', 'OSError', 'OverflowError', 'PendingDeprecationWarning', 'PermissionError', 'ProcessLookupError', 'RecursionError', 'ReferenceError', 'ResourceWarning', 'RuntimeError', 'RuntimeWarning', 'StopAsyncIteration', 'StopIteration', 'SyntaxError', 'SyntaxWarning', 'SystemError', 'SystemExit', 'TabError', 'TimeoutError', 'True', 'TypeError', 'UnboundLocalError', 'UnicodeDecodeError', 'UnicodeEncodeError', 'UnicodeError', 'UnicodeTranslateError', 'UnicodeWarning', 'UserWarning', 'ValueError', 'Warning', 'WindowsError', 'ZeroDivisionError', '\_\_build\_class\_\_', '\_\_debug\_\_', '\_\_doc\_\_', '\_\_import\_\_', '\_\_loader\_\_', '\_\_name\_\_', '\_\_package\_\_', '\_\_spec\_\_', 'abs', 'all', 'any', 'ascii', 'bin', 'bool', 'breakpoint', 'bytearray', 'bytes', 'callable', 'chr', 'classmethod', 'compile', 'complex', 'copyright', 'credits', 'delattr', 'dict', 'dir', 'divmod', 'enumerate', 'eval', 'exec', 'exit', 'filter', 'float', 'format', 'frozenset', 'getattr', 'globals', 'hasattr', 'hash', 'help', 'hex', 'id', 'input', 'int', 'isinstance', 'issubclass', 'iter', 'len', 'license', 'list', 'locals', 'map', 'max', 'memoryview', 'min', 'next', 'object', 'oct', 'open', 'ord', 'pow', 'print', 'property', 'quit', 'range', 'repr', 'reversed', 'round', 'set', 'setattr', 'slice', 'sorted', 'staticmethod', 'str', 'sum', 'super', 'tuple', 'type', 'vars', 'zip']
关于文件对象:
我们学习C语言知道 FILE* , 通过 FILE* 进行文件读写操作.
我们学习Linux时又知道, FILE 结构中其实包含了文件描述符*, 操作系统是通过文件描述符来对文件操作
的
Python的文件对象, 其实也包含了文件描述符, 同时也包含了这个文件的一些其他属性. 本质上也是通过文件描述符完成对文件的读写操作.
既然文件对象包含了文件描述符, 我们知道, 一个进程可操作的文件描述符的数目是有上限的. 因此对于用
完了的文件描述符要及时关闭.
当文件对象被垃圾回收器销毁时, 也会同时释放文件描述符.
如果文件打开失败(例如文件不存在), 就会执行出错
a = open('Z:\XXX','r')
#执行结果:
FileNotFoundError: [Errno 2] No such file or directory: 'Z:\\XXX'
读文件
read: 读指定长度字节数的数据, 返回一个字符串.
a = open('Z:/test.txt','r')
print(a.read())
#执行结果:
hello world
hello python
readline: 读取一行数据, 返回一个字符串 本文作者链接:https://blog.csdn.net/chuxinchangcun?spm=1019.2139.3001.5343 (反爬)
a = open('Z:/test.txt','r')
print(a.readline()) #hello world
readlines: 读取整个文件, 返回一个列表. 列表中的每一项是一个字符串, 代表了一行的内容
a = open('Z:/test.txt','r')
print(a.readlines()) #['hello world\n', 'hello python']
直接使用for line in f的方式循环遍历每一行, 功能和readline类似. 一次只读一行,
相比于readlines占用内存少, 但是访问IO设备的次数会增多, 速度较慢
a = open('Z:/test.txt','r')
for line in a:
print(line)
#执行结果:
hello world
hello python
注意, readline或者readlines这些函数仍然会保留换行符. 所以我们往往需要写这样的代码来去掉换行符.
a = open('Z:/test.txt','r')
# for line in f 的方式循环遍历每一行, 功能和readline类似,返回的line是字符串,所以可以使用字符串的成员函数
for line in a:
print(line.strip())
#执行结果:
hello world
hello python
#或者:使用列表解析语法
a = open('Z:/test.txt','r')
data = [line.strip() for line in a.readlines()]
print(data) #['hello world', 'hello python']
readlines和for line in f: 的区别:
第一种方法是全部读取->只读取一次 时间快,但是占空间。第二种方式是隔行读取 ->读取多次,时间慢,但是省空间。读取大文件选方式2
写文件
write: 向文件中写一段字符串
本文作者链接:https://blog.csdn.net/chuxinchangcun?spm=1019.2139.3001.5343 (反爬)
- 如需写文件, 必须要按照 ‘w’ 或者 ‘a’ 的方式打开文件. 否则会写失败.
a = open('Z:/test.txt','r')
a.write("hello Mango") #io.UnsupportedOperation: not writable
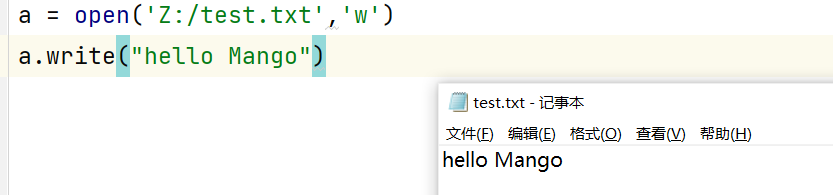
a = open('Z:/test.txt','w')
a.write("hello Mango") #用w方式打开,原文件的内容被删除
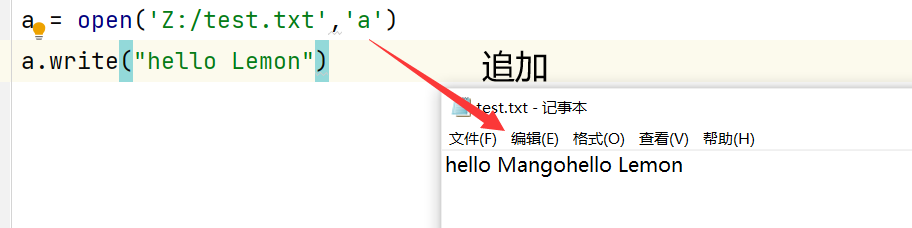
a = open('Z:/test.txt','a')
a.write("hello Lemon") #以a的方式打开->追加
writelines: 参数是一个列表, 列表中的每一个元素是一个字符串.
a = open('Z:/test.txt','w')
w = ['Mango\n','hello\n',' world\n']
a.writelines(w)#把列表的内容写入到文件中

并没有一个 writeline 这样的函数. 因为这个动作等价于 write 时在字符串后面加上 ‘\n’. 同理, 使用
writelines的时候, 也需要保证每一个元素的末尾, 都带有 ‘\n’
关于读写缓冲区
学习Linux我们知道, C语言库函数中的fread, fwrite和系统调用read, write相比, 功能是类似的. 但是
fread/fwrite是带有缓冲区的
Python的文件读写操作, 既可以支持带缓冲区, 也可以选择不带缓冲区.
在使用open函数打开一个文件的时候, 其实还有第三个参数, 可以指定是否使用缓冲区, 以及缓冲区的大小是多少 (查看 help(open) 以及 print(_doc_) ).
a = open('Z:/test.txt','r')
print(a.__doc__)
print(help(open))
本文作者链接:https://blog.csdn.net/chuxinchangcun?spm=1019.2139.3001.5343 (反爬)
使用flush方法可以立即刷新缓冲区
操作文件指针
文件具备随机访问能力. 这个过程是通过操作文件指针完成的.
seek: 将文件指针移动到从文件开头算起的第几个字节上. 有两个参数.
第一个参数offset表示偏移的字节数.
第二个参数whence表示偏移量的起始位置在哪. 值为0, 表示从开头计算, 值为1, 表示从当前位置, 值为2, 表示从文件结尾位置.
tell: 获取当前文件指针指向的位置. 返回当前位置到文件开头的偏移量.
文件对象内建属性

with语句和上下文管理器
本文作者链接:https://blog.csdn.net/chuxinchangcun?spm=1019.2139.3001.5343 (反爬)
我们刚才说了, 用完的文件对象, 要及时关闭, 否则可能会引起句柄泄露.
但是如果逻辑比较繁琐, 或者我们忘记了手动调用close怎么办?
def func():
f = open('Z:/test.txt','r')
x =10
if x==10:
return
#执行文件操作
f.close() #上面提前return,导致内存泄漏
解决:在每一个return前先关闭文件
def func():
f = open('Z:/test.txt','r')
x =10
if x==10:
f.close()
return
#执行文件操作
f.close()
但是如果抛出异常也会导致文件没有关闭:
def func():
f = open('Z:/test.txt','r')
x =10
a = [1,2,3]
print(a[100]) #越界:IndexError: list index out of range
if x==10:
f.close()
return
#执行文件操作
f.close()
func()
C++中使用 “智能指针” 这样的方式来管理内存/句柄的释放, 借助对象的构造函数和析构函数, 自动完成释
放过程.
但是Python中对象的回收取决于GC机制, 并不像C++中时效性那么强.
Python中引入了上下文管理器来解决这类问题.
def func():
with open('Z:/test.txt','r') as f: #上下文管理器
#文件操作
pass #空语句
可以更改编码格式:
with open('Z:/test.txt', 'r',encoding='utf-8') as f:
print(f.readline())
with open('Z:/test.txt', 'r',encoding='utf-8') as f:
for line in f:
print(line.strip())
#执行结果:
Mango
hello
world
在with语句块内进行文件操作. 当文件操作完毕之后, 出了with语句之外. 就会自动执行f的关闭操作.
一个支持上下文协议的对象才能被应用于with语句中. 我们将这种对象称为上下文管理器. Python中很多
内置对象都是上下文管理器, 例如文件对象, 线程锁对象等.
文件系统的基础操作
文件路径操作
os.path这个模块中, 包含了一些实用的路径操作的函数
basename:去掉目录路径,返回文件名
dirname:去掉文件名,返回目录路径
import os.path
p = '/aaa/bbb/ccc.txt'
print(os.path.dirname(p)) # /aaa/bbb
print(os.path.basename(p)) #ccc.txt
split:返回(dirname(),basename())的元组
本文作者链接:https://blog.csdn.net/chuxinchangcun?spm=1019.2139.3001.5343 (反爬)
import os.path as path
p = '/aaa/bbb/ccc.txt'
print(path.split(p)) #('/aaa/bbb', 'ccc.txt')
splitext:返回(filename,extension)元组 extension:文件的后缀名
import os.path as path
p = '/aaa/bbb/ccc.txt'
print(path.splitext(p))#('/aaa/bbb/ccc', '.txt')
做了那么多年开发,自学了很多门编程语言,我很明白学习资源对于学一门新语言的重要性,这些年也收藏了不少的Python干货,对我来说这些东西确实已经用不到了,但对于准备自学Python的人来说,或许它就是一个宝藏,可以给你省去很多的时间和精力。
别在网上瞎学了,我最近也做了一些资源的更新,只要你是我的粉丝,这期福利你都可拿走。
我先来介绍一下这些东西怎么用,文末抱走。
(1)Python所有方向的学习路线(新版)
这是我花了几天的时间去把Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
最近我才对这些路线做了一下新的更新,知识体系更全面了。

(2)Python学习视频
包含了Python入门、爬虫、数据分析和web开发的学习视频,总共100多个,虽然没有那么全面,但是对于入门来说是没问题的,学完这些之后,你可以按照我上面的学习路线去网上找其他的知识资源进行进阶。

(3)100多个练手项目
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了,只是里面的项目比较多,水平也是参差不齐,大家可以挑自己能做的项目去练练。

(4)200多本电子书
这些年我也收藏了很多电子书,大概200多本,有时候带实体书不方便的话,我就会去打开电子书看看,书籍可不一定比视频教程差,尤其是权威的技术书籍。
基本上主流的和经典的都有,这里我就不放图了,版权问题,个人看看是没有问题的。
(5)Python知识点汇总
知识点汇总有点像学习路线,但与学习路线不同的点就在于,知识点汇总更为细致,里面包含了对具体知识点的简单说明,而我们的学习路线则更为抽象和简单,只是为了方便大家只是某个领域你应该学习哪些技术栈。

(6)其他资料
还有其他的一些东西,比如说我自己出的Python入门图文类教程,没有电脑的时候用手机也可以学习知识,学会了理论之后再去敲代码实践验证,还有Python中文版的库资料、MySQL和HTML标签大全等等,这些都是可以送给粉丝们的东西。

这些都不是什么非常值钱的东西,但对于没有资源或者资源不是很好的学习者来说确实很不错,你要是用得到的话都可以直接抱走,关注过我的人都知道,这些都是可以拿到的。
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









