






网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
- 一个多维数据模型,其中包含通过度量标准名称和键/值对标识的时间序列数据
- PromQL,一种灵活的查询语言 ,可利用此维度
- 不依赖分布式存储;单服务器节点是自治的
- 时间序列收集通过HTTP上的拉模型进行
- 通过中间网关支持推送时间序列
- 通过服务发现或静态配置发现目标
- 多种图形和仪表板支持模式
02、组件
Prometheus生态系统包含多个组件,其中许多是可选的:
- Prometheus主服务器,它会刮取并存储时间序列数据
- 客户端库,用于检测应用程序代码
- 一个支持短期工作的 推送网关
- 诸如HAProxy,StatsD,Graphite等服务的专用 出口商
- 一个 alertmanager处理警报
- 各种支持工具
大多数Prometheus组件都是用 Go编写的,因此易于构建和部署为静态二进制文件。
03、架构
下图说明了Prometheus的体系结构及其某些生态系统组件:
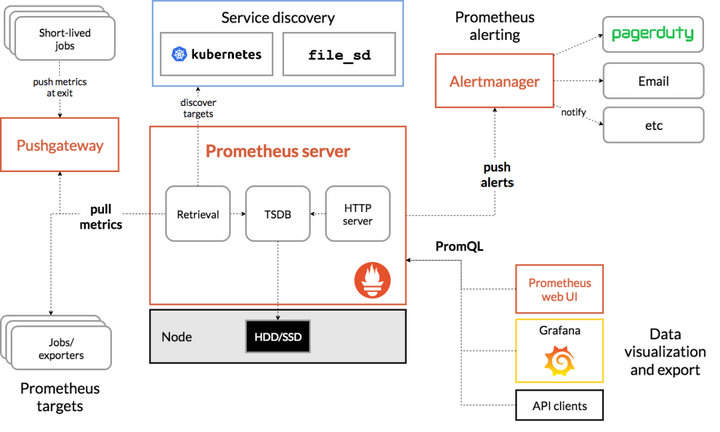
Prometheus直接或通过中介推送网关从已检测作业中删除指标,以用于短期作业。它在本地存储所有报废的样本,并对这些数据运行规则,以汇总和记录现有数据中的新时间序列,或生成警报。 Grafana或其他API使用者可以用来可视化收集的数据。
现在我也找了很多测试的朋友,做了一个分享技术的交流群,共享了很多我们收集的技术文档和视频教程。
如果你不想再体验自学时找不到资源,没人解答问题,坚持几天便放弃的感受
可以加入我们一起交流。而且还有很多在自动化,性能,安全,测试开发等等方面有一定建树的技术大牛
分享他们的经验,还会分享很多直播讲座和技术沙龙
可以免费学习!划重点!开源的!!!
qq群号:110685036

04、安装
前提需要有helm环境:



安装成功,查看pod状态会发现有两个处于pending状态,是因为需要请求pv

这里使用hostPath来创建pv
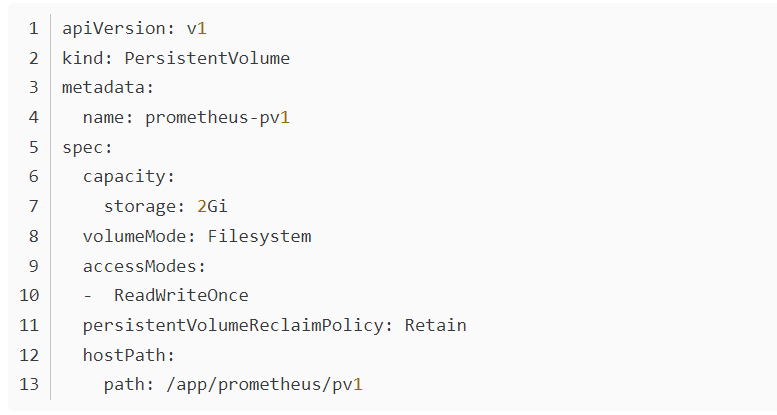

查看pod状态会发现有个pod会报错,并查看日志是报错是容器名不同

真正的原因是因为使用的hoatPath,pvc请求的权限不够,到worker节点给对应的hostpath加777的权限即可,这是我通过rancher查看到的报错

05、访问web界面
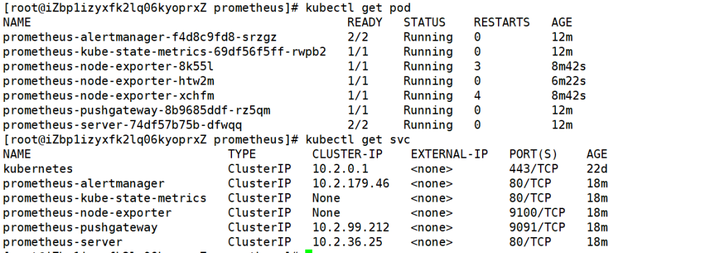
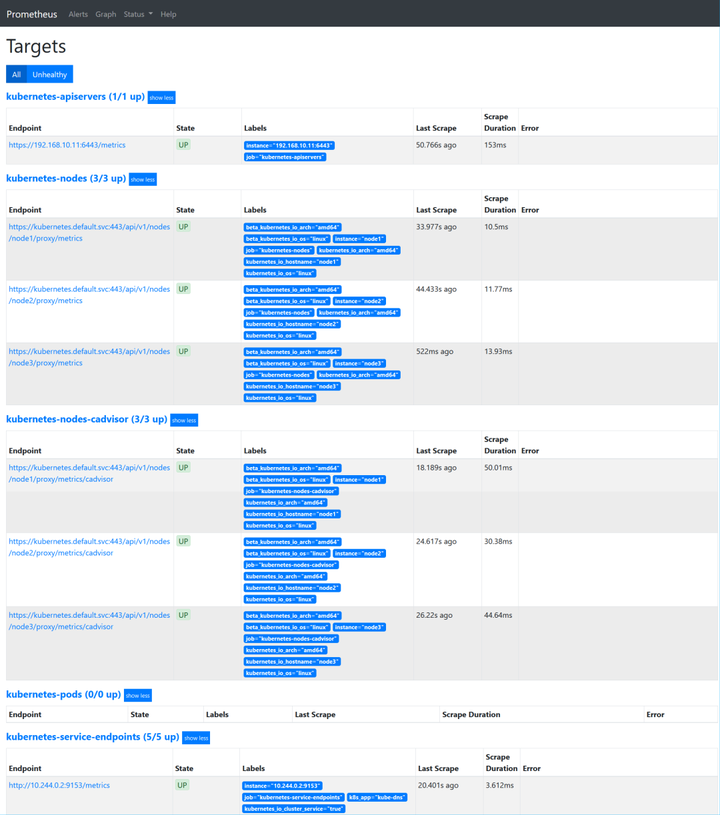
这里还需要修改Prometheus-server的Port类型为NodePort。
06、安装grafana



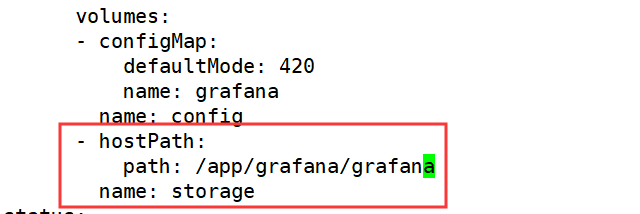
由于grafana没有使用持久存储,根据需求修改为hostpath持久存储,需要注意的是,宿主机目录也需要777的权限
还需要需改grafana的svc类型为NodePort

访问web界面,用户admin,密码:admin123

07、导入Prometheus
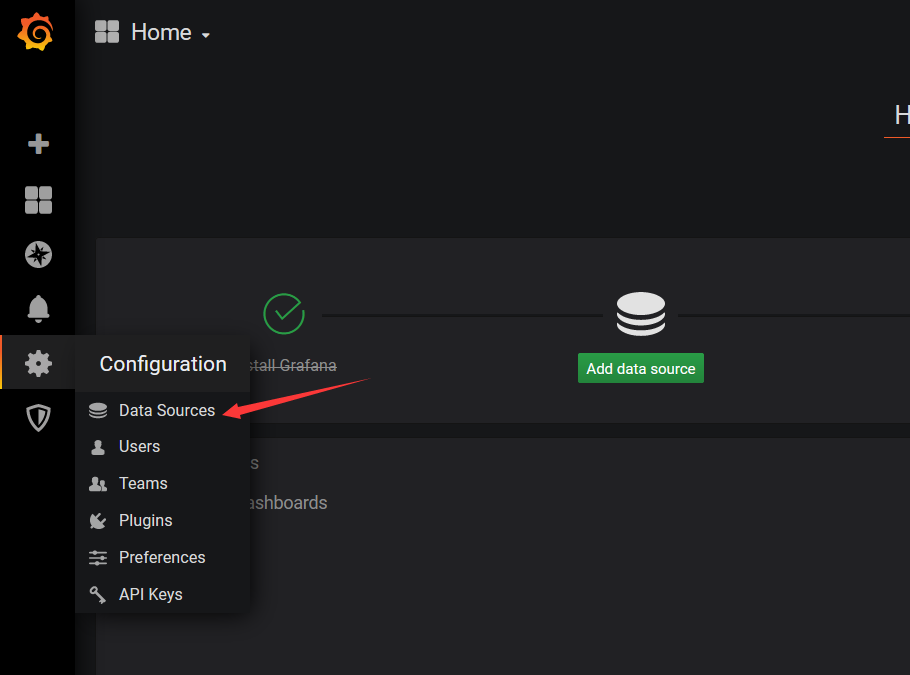
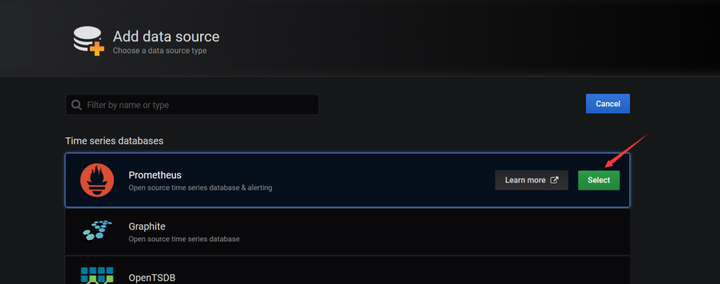
填入Prometheus的地址
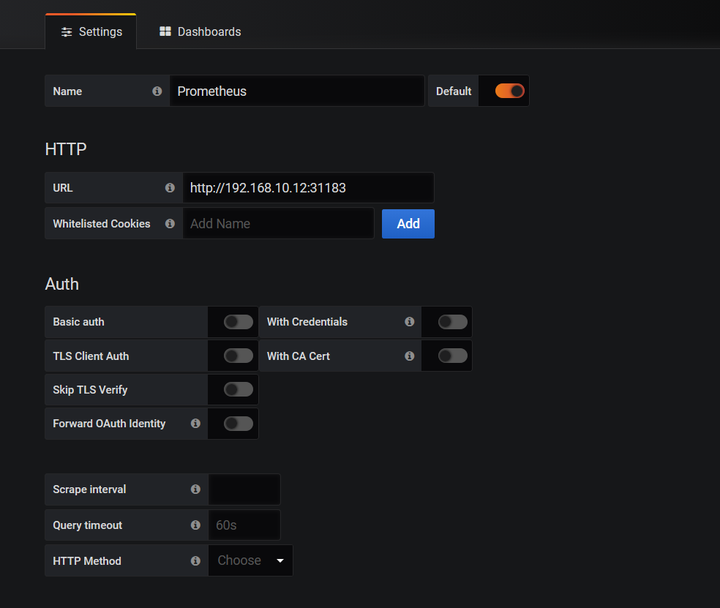
则表示验证通过
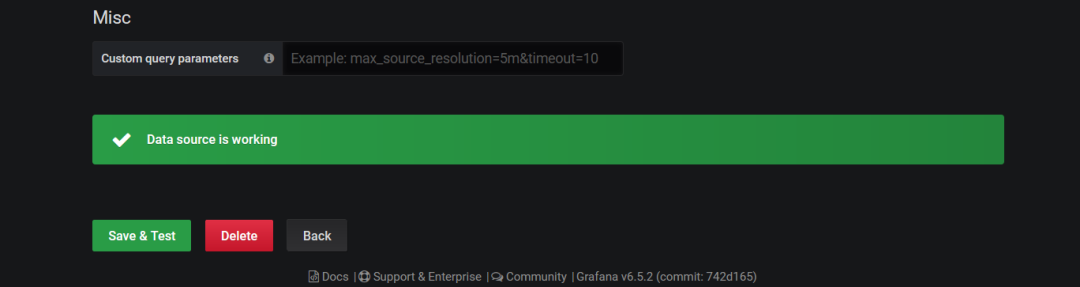
导入grafana的模板

这里选择Prometheus

即可看到灰常华丽的仪表盘了
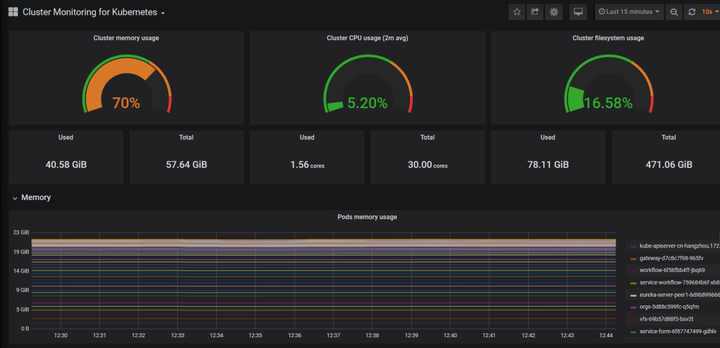
这里提供几个模板的编号:

08、配置alertmanager告警
1、关联alertmanager和prometheus
添加alertmanager的服务名称

添加告警规则
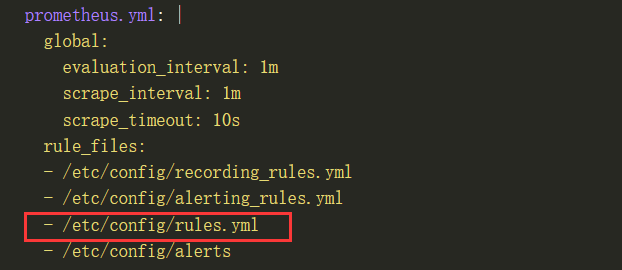
rules.yml:|
groups:
- name: Host
rules:
- alert: HostMemory Usage
expr: sum(kube_pod_container_resource_requests_memory_bytes) / sum(kube_node_status_allocatable_memory_bytes) * 100 > 80
for: 1m
labels:
name: Memory
team: wechat
severity: Warning
annotations:
summary: " {{ $labels.appname }} "
description: "宿主机内存使用率超过80%."
value: "{{ $value }}"
- alert: HostCPU Usage
expr: sum(kube_pod_container_resource_requests_cpu_cores) / sum(kube_node_status_allocatable_cpu_cores) * 100 > 60
for: 1m
labels:
name: CPU
team: wechat
severity: Warning
annotations:
summary: " {{ $labels.appname }} "
description: "宿主机CPU使用率超过60%."
value: "{{ $value }}"
- alert: HostFilesystem Usage
expr: (sum(node_filesystem_size_bytes{device!="rootfs"}) - sum(node_filesystem_free_bytes{device!="rootfs"})) / sum(node_filesystem_size_bytes{device!="rootfs"}) > 0.8
for: 1m
labels:
name: Disk
team: wechat
severity: Warning
annotations:
summary: " {{ $labels.appname }} "
description: " 宿主机 [ {{ $labels.mountpoint }} ]分区使用超过80%."
value: "{{ $value }}%"
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
.(img-jt41tZ9K-1715820151495)]
[外链图片转存中…(img-VCjpcflL-1715820151496)]
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!















 1358
1358

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









