







先自我介绍一下,小编浙江大学毕业,去过华为、字节跳动等大厂,目前阿里P7
深知大多数程序员,想要提升技能,往往是自己摸索成长,但自己不成体系的自学效果低效又漫长,而且极易碰到天花板技术停滞不前!
因此收集整理了一份《2024年最新Python全套学习资料》,初衷也很简单,就是希望能够帮助到想自学提升又不知道该从何学起的朋友。





既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上Python知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
如果你需要这些资料,可以添加V获取:vip1024c (备注Python)

正文
load the input image, resize it, and convert it to grayscale
image = cv2.imread(args[“image”])
image = imutils.resize(image, width=300)
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
加载了包含信用卡照片的命令行参数图像。 然后,我们将其调整为 width=300 ,保持纵横比,然后将其转换为灰度。 让我们看看我们的输入图像:

接下来是我们的调整大小和灰度操作:

现在我们的图像已经灰度化并且大小一致,让我们进行形态学操作:
apply a tophat (whitehat) morphological operator to find light
regions against a dark background (i.e., the credit card numbers)
tophat = cv2.morphologyEx(gray, cv2.MORPH_TOPHAT, rectKernel)
使用我们的 rectKernel 和我们的灰度图像,我们执行 Top-hat 形态学操作,将结果存储为 tophat。
Top-hat操作在深色背景(即信用卡号)下显示浅色区域,如下图所示:

给定我们的高帽图像,让我们计算沿 x 方向的梯度:
compute the Scharr gradient of the tophat image, then scale
the rest back into the range [0, 255]
gradX = cv2.Sobel(tophat, ddepth=cv2.CV_32F, dx=1, dy=0,
ksize=-1)
gradX = np.absolute(gradX)
(minVal, maxVal) = (np.min(gradX), np.max(gradX))
gradX = (255 * ((gradX - minVal) / (maxVal - minVal)))
gradX = gradX.astype(“uint8”)
我们努力隔离数字的下一步是计算 x 方向上高帽图像的 Scharr 梯度。完成计算,将结果存储为 gradX 。
在计算 gradX 数组中每个元素的绝对值后,我们采取一些步骤将值缩放到 [0-255] 范围内(因为图像当前是浮点数据类型)。 为此,我们计算 gradX 的 minVal 和 maxVal,然后计算第 73 行所示的缩放方程(即最小/最大归一化)。 最后一步是将 gradX 转换为范围为 [0-255] 的 uint8。 结果如下图所示:

让我们继续改进信用卡数字查找算法:
apply a closing operation using the rectangular kernel to help
cloes gaps in between credit card number digits, then apply
Otsu’s thresholding method to binarize the image
gradX = cv2.morphologyEx(gradX, cv2.MORPH_CLOSE, rectKernel)
thresh = cv2.threshold(gradX, 0, 255,
cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
apply a second closing operation to the binary image, again
to help close gaps between credit card number regions
thresh = cv2.morphologyEx(thresh, cv2.MORPH_CLOSE, sqKernel)
为了缩小差距,我们执行了一个关闭操作。请注意,我们再次使用了 rectKernel。 随后我们对 gradX 图像执行 Otsu 和二进制阈值,然后是另一个关闭操作。 这些步骤的结果如下所示:

接下来让我们找到轮廓并初始化数字分组位置列表。
find contours in the thresholded image, then initialize the
list of digit locations
cnts = cv2.findContours(thresh.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
cnts = imutils.grab_contours(cnts)
locs = []
我们找到了轮廓并将它们存储在一个列表 cnts 中 。 然后,我们初始化一个列表来保存数字组位置。
现在让我们遍历轮廓,同时根据每个轮廓的纵横比进行过滤,允许我们从信用卡的其他不相关区域中修剪数字组位置:
loop over the contours
for (i, c) in enumerate(cnts):
compute the bounding box of the contour, then use the
bounding box coordinates to derive the aspect ratio
(x, y, w, h) = cv2.boundingRect©
ar = w / float(h)
since credit cards used a fixed size fonts with 4 groups
of 4 digits, we can prune potential contours based on the
aspect ratio
if ar > 2.5 and ar < 4.0:
contours can further be pruned on minimum/maximum width
and height
if (w > 40 and w < 55) and (h > 10 and h < 20):
append the bounding box region of the digits group
to our locations list
locs.append((x, y, w, h))
我们以与参考图像相同的方式循环遍历轮廓。 在计算每个轮廓的边界矩形 c之后,我们通过将宽度除以高度来计算纵横比 ar 。 使用纵横比,我们分析每个轮廓的形状。 如果 ar 介于 2.5 和 4.0 之间(宽大于高),以及 40 到 55 像素之间的 w 和 10 到 20 像素之间的 h,我们将一个方便的元组中的边界矩形参数附加到 locs。
下图显示了我们找到的分组——出于演示目的,我让 OpenCV 在每个组周围绘制了一个边界框:

接下来,我们将从左到右对分组进行排序并初始化信用卡数字列表:
sort the digit locations from left-to-right, then initialize the
list of classified digits
locs = sorted(locs, key=lambda x:x[0])
output = []
我们根据 x 值对 locs 进行排序,因此它们将从左到右排序。 我们初始化一个列表 output ,它将保存图像的信用卡号。 现在我们知道每组四位数字的位置,让我们循环遍历四个排序的组并确定其中的数字。
这个循环相当长,分为三个代码块——这是第一个块:
loop over the 4 groupings of 4 digits
for (i, (gX, gY, gW, gH)) in enumerate(locs):
initialize the list of group digits
groupOutput = []
extract the group ROI of 4 digits from the grayscale image,
then apply thresholding to segment the digits from the
background of the credit card
group = gray[gY - 5:gY + gH + 5, gX - 5:gX + gW + 5]
group = cv2.threshold(group, 0, 255,
cv2.THRESH_BINARY | cv2.THRESH_OTSU)[1]
detect the contours of each individual digit in the group,
then sort the digit contours from left to right
digitCnts = cv2.findContours(group.copy(), cv2.RETR_EXTERNAL,
cv2.CHAIN_APPROX_SIMPLE)
digitCnts = imutils.grab_contours(digitCnts)
digitCnts = contours.sort_contours(digitCnts,
method=“left-to-right”)[0]
在此循环的第一个块中,我们提取并在每侧填充组 5 个像素,应用阈值处理,并查找和排序轮廓。 详情请务必参考代码。 下面显示的是已提取的单个组:

让我们用嵌套循环继续循环以进行模板匹配和相似度得分提取:
loop over the digit contours
for c in digitCnts:
compute the bounding box of the individual digit, extract
the digit, and resize it to have the same fixed size as
the reference OCR-A images
(x, y, w, h) = cv2.boundingRect©
roi = group[y:y + h, x:x + w]
roi = cv2.resize(roi, (57, 88))
initialize a list of template matching scores
scores = []
loop over the reference digit name and digit ROI
for (digit, digitROI) in digits.items():
apply correlation-based template matching, take the
score, and update the scores list
result = cv2.matchTemplate(roi, digitROI,
cv2.TM_CCOEFF)
(_, score, _, _) = cv2.minMaxLoc(result)
scores.append(score)
the classification for the digit ROI will be the reference
digit name with the largest template matching score
groupOutput.append(str(np.argmax(scores)))
使用 cv2.boundingRect 我们获得提取包含每个数字的 ROI 所需的参数。为了使模板匹配以某种程度的精度工作,我们将 roi 的大小调整为与我们在第 144 行上的参考 OCR-A 字体数字图像(57×88 像素)相同的大小。
我们初始化了一个分数列表。将其视为我们的置信度分数——它越高,它就越有可能是正确的模板。
现在,让我们通过每个参考数字循环(第三个嵌套循环)并执行模板匹配。这是为这个脚本完成繁重工作的地方。
OpenCV 有一个名为 cv2.matchTemplate 的方便函数,您可以在其中提供两个图像:一个是模板,另一个是输入图像。将 cv2.matchTemplate 应用于这两个图像的目的是确定它们的相似程度。
在这种情况下,我们提供参考 digitROI 图像和包含候选数字的信用卡的 roi。使用这两个图像,我们调用模板匹配函数并存储结果。 接下来,我们从结果中提取分数并将其附加到我们的分数列表中。这样就完成了最内部的循环。
使用分数(每个数字 0-9 一个),我们取最大分数——最大分数应该是我们正确识别的数字。我们找到得分最高的数字,通过 np.argmax 获取特定索引。该索引的整数名称表示基于与每个模板的比较最可能的数字(再次记住,索引已经预先排序为 0-9)。
最后,让我们在每组周围画一个矩形,并以红色文本查看图像上的信用卡号:
draw the digit classifications around the group
cv2.rectangle(image, (gX - 5, gY - 5),
(gX + gW + 5, gY + gH + 5), (0, 0, 255), 2)
cv2.putText(image, “”.join(groupOutput), (gX, gY - 15),
cv2.FONT_HERSHEY_SIMPLEX, 0.65, (0, 0, 255), 2)
update the output digits list
output.extend(groupOutput)
对于此循环的第三个也是最后一个块,我们在组周围绘制一个 5 像素的填充矩形,然后在屏幕上绘制文本。
最后一步是将数字附加到输出列表中。 Pythonic 方法是使用扩展函数将可迭代对象(在本例中为列表)的每个元素附加到列表的末尾。
要查看脚本的执行情况,让我们将结果输出到终端并在屏幕上显示我们的图像。
display the output credit card information to the screen
print(“Credit Card Type: {}”.format(FIRST_NUMBER[output[0]]))
print(“Credit Card #: {}”.format(“”.join(output)))
cv2.imshow(“Image”, image)
cv2.waitKey(0)
将信用卡类型打印到控制台,然后在随后的第 173 行打印信用卡号。
在最后几行,我们在屏幕上显示图像并等待任何键被按下,然后退出脚本第 174 和 175 行。
花点时间祝贺自己——你做到了。 回顾一下(在高层次上),这个脚本:
-
将信用卡类型存储在字典中。
-
获取参考图像并提取数字。
-
将数字模板存储在字典中。
-
本地化四个信用卡号码组,每个组包含四位数字(总共 16 位数字)。
-
提取要“匹配”的数字。
-
对每个数字执行模板匹配,将每个单独的 ROI 与每个数字模板 0-9 进行比较,同时存储每个尝试匹配的分数。
-
找到每个候选数字的最高分,并构建一个名为 output 的列表,其中包含信用卡号。
-
将信用卡号和信用卡类型输出到我们的终端,并将输出图像显示到我们的屏幕上。
现在是时候查看运行中的脚本并检查我们的结果了。
=====================================================================
现在我们已经对信用卡 OCR 系统进行了编码,让我们试一试。
我们显然不能在这个例子中使用真实的信用卡号,所以我使用谷歌收集了一些信用卡示例图像。
这些信用卡显然是假的,仅用于演示目的。 但是,您可以应用此博客文章中的相同技术来识别实际信用卡上的数字。
要查看我们的信用卡 OCR 系统的运行情况,请打开一个终端并执行以下命令:
$ python ocr_template_match.py --reference ocr_a_reference.png \
–image images/credit_card_05.png
Credit Card Type: MasterCard
Credit Card #: 5476767898765432
我们的第一个结果图像,100% 正确:
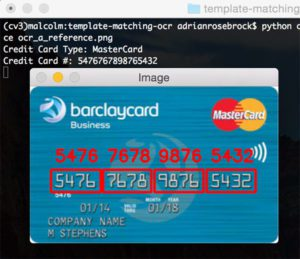
请注意我们如何能够正确地将信用卡标记为万事达卡,只需检查信用卡号中的第一位数字即可。 让我们尝试第二张图片,这次是一张签证:
$ python ocr_template_match.py --reference ocr_a_reference.png \
–image images/credit_card_01.png
Credit Card Type: Visa
Credit Card #: 4000123456789010
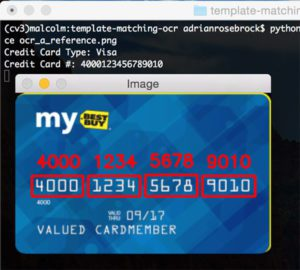
再一次,我们能够使用模板匹配正确地对信用卡进行 OCR。
$ python ocr_template_match.py --reference ocr_a_reference.png \
–image images/credit_card_02.png
Credit Card Type: Visa
如果你也是看准了Python,想自学Python,在这里为大家准备了丰厚的免费学习大礼包,带大家一起学习,给大家剖析Python兼职、就业行情前景的这些事儿。
一、Python所有方向的学习路线
Python所有方向路线就是把Python常用的技术点做整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、学习软件
工欲善其必先利其器。学习Python常用的开发软件都在这里了,给大家节省了很多时间。

三、全套PDF电子书
书籍的好处就在于权威和体系健全,刚开始学习的时候你可以只看视频或者听某个人讲课,但等你学完之后,你觉得你掌握了,这时候建议还是得去看一下书籍,看权威技术书籍也是每个程序员必经之路。

四、入门学习视频
我们在看视频学习的时候,不能光动眼动脑不动手,比较科学的学习方法是在理解之后运用它们,这时候练手项目就很适合了。


四、实战案例
光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。
五、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。
成为一个Python程序员专家或许需要花费数年时间,但是打下坚实的基础只要几周就可以,如果你按照我提供的学习路线以及资料有意识地去实践,你就有很大可能成功!
最后祝你好运!!!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注python)

一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
五、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。
成为一个Python程序员专家或许需要花费数年时间,但是打下坚实的基础只要几周就可以,如果你按照我提供的学习路线以及资料有意识地去实践,你就有很大可能成功!
最后祝你好运!!!
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
需要这份系统化的资料的朋友,可以添加V获取:vip1024c (备注python)
[外链图片转存中…(img-wh6QF1NN-1713231803347)]
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









